

PYTHON高级应用课程设计“淘宝茶叶商品信息爬取与数据分析”
(一)选题的背景
随着电商的迅速发展,越来越多的商家都会选择在电商网站销售农产品,其中在电商平台卖茶叶就是一个成功的案例。茶叶作为一种天然的健康饮品,具有悠久的消费历史和广大的消费群体。近年来,随着人们生活水平的不断提高,对健康的重视程度日益上升。饮茶作为一种健康的生活习惯,符合现阶段消费者对健康和高品质生活的追求。并且近年来,我国茶产业快速发展,一二三产业融合推进,呈现出良好的发展势头。中国是茶的故乡,也是茶叶生产大国。中国茶叶生产快速发展,茶叶种植面积扩大,茶叶产量不断增长,茶叶买卖前景一片光明。本文通过爬取淘宝茶叶的商品相关信息,并根据爬取到数据做数据分析,得出有效的结论,为消费者和商家的茶叶购买或销售提出可行的建议。
(二)主题式网络爬虫的设计方案
本文的主题式网络爬虫名称为“淘宝茶叶商品信息爬取与数据分析”,主要爬取的内容包括商品的标题、销售地、销售量、评论数量、销售价格、店铺名称、商品唯一标识ID以及详情页网址等信息。爬取方式选择selenium自动化采集的方法,使用到的Python包有time、selenium、base64和threading,pandas,requests和re,技术难点在于淘宝商品信息的分析和解析部分。爬取过程设计如下图:
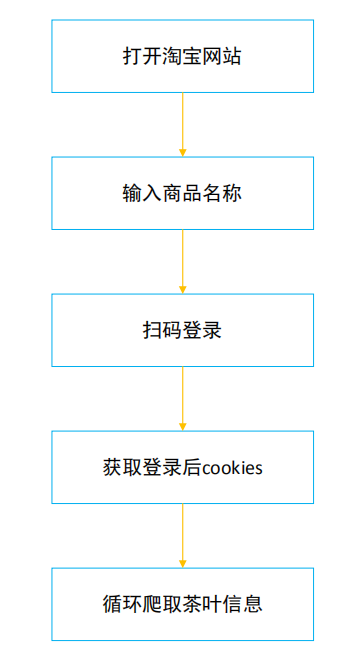
(三)数据页面的结构特征分析
打开淘宝网站,在搜索框输入“茶叶”,然后右键检查,可以看到如下的网页结构:

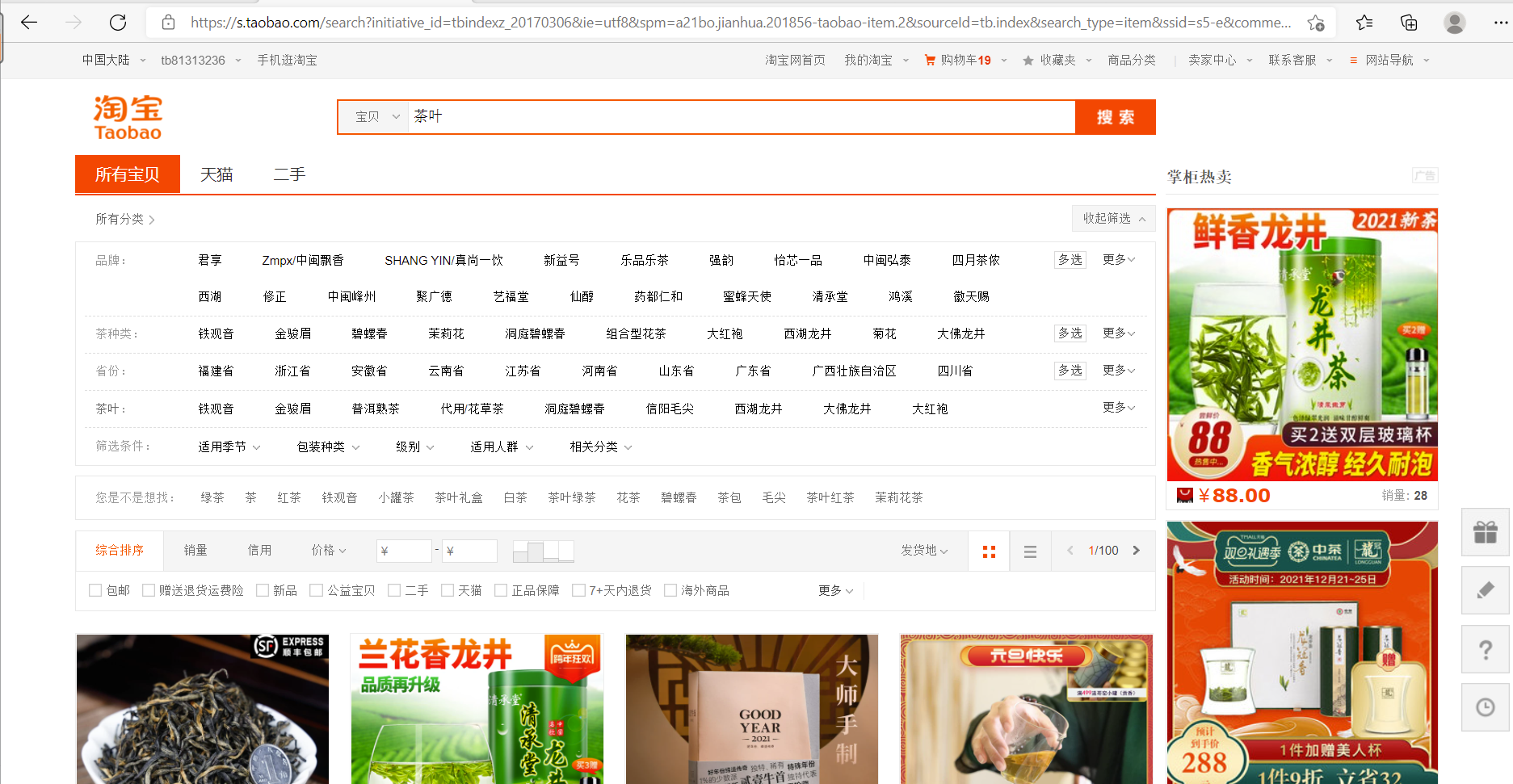

很明显,网页结构较为复杂,不适于用xpath解析,所以本文选择正则表达式re库来解析。方法是选用鼠标定位到需要的商品信息,可以直接复制element到代码中修改,得到需要的数据,如图:

(一)网络爬虫程序设计
- 数据爬取与采集
数据采集代码如下:
1 from selenium import webdriver 2 import time 3 from PIL import Image 4 import base64 5 import threading 6 import pandas as pd 7 import requests 8 import re 9 10 11 # 定义爬虫配置参数 12 headers = {'Host':'s.taobao.com', 13 'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0', 14 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 15 'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', 16 'Accept-Encoding':'gzip, deflate, br', 17 'Connection':'keep-alive'} 18 list_url = 'http://s.taobao.com/search?q=%(key)s&ie=utf8&s=%(page)d' # 对应页数 19 20 # 打开登录二维码图片 21 def open_img(img_location): 22 img=Image.open(img_location) 23 img.show() 24 25 # 登陆获取cookies 26 def login(): 27 driver = webdriver.Chrome() 28 driver.get('https://login.taobao.com/member/login.jhtml') 29 try: 30 driver.find_element_by_xpath('//*[@id="login"]/div[1]/i').click() 31 except: 32 pass 33 time.sleep(3) 34 # 执行JS获得canvas的二维码 35 JS = 'return document.getElementsByTagName("canvas")[0].toDataURL("image/png");' 36 im_info = driver.execute_script(JS) # 执行JS获取图片信息 37 im_base64 = im_info.split(',')[1] # 拿到base64编码的图片信息 38 im_bytes = base64.b64decode(im_base64) # 转为bytes类型 39 time.sleep(2) 40 with open('./login.png','wb') as f: 41 f.write(im_bytes) 42 f.close() 43 t = threading.Thread(target=open_img,args=('./login.png',)) 44 t.start() 45 print("正在转码中,请稍后!\n") 46 while(True): 47 c = driver.get_cookies() 48 if len(c) > 20: # 登陆成功获取到cookies 49 cookies = {} 50 for i in range(len(c)): 51 cookies[c[i]['name']] = c[i]['value'] 52 driver.close() 53 print("登录成功,正在开启爬虫!\n") 54 return cookies 55 time.sleep(1) 56 57 def run(): 58 # 正则匹配模式,获取所需数据 59 p_title = '"raw_title":"(.*?)"' # 标题 60 p_location = '"item_loc":"(.*?)"' # 销售地 61 p_sale = '"view_sales":"(.*?)人付款"' # 销售量 62 p_comment = '"comment_count":"(.*?)"' # 评论数 63 p_price = '"view_price":"(.*?)"' # 销售价格 64 p_nick = '"nick":"(.*?)"' # 店铺名称 65 p_nid = '"nid":"(.*?)"' # 商品id 66 p_url = '"pic_url":"(.*?)"' # 商品网址 67 68 # 数据爬取 69 key = input('请输入商品名称:') # 商品的关键词 70 N = 100 # 爬取的页数 71 data = [] 72 cookies = login() # 得到登录的cookies 73 for i in range(N): 74 try: 75 page = i*44 76 url = list_url%{'key':key,'page':page} 77 res = requests.get(url,headers=headers,cookies=cookies) 78 html = res.text 79 title = re.findall(p_title,html) 80 location = re.findall(p_location,html) 81 sale = re.findall(p_sale,html) 82 comment = re.findall(p_comment,html) 83 price = re.findall(p_price,html) 84 nick = re.findall(p_nick, html) 85 nid = str(re.findall(p_nid,html)) 86 ourl = re.findall(p_url, html) 87 for j in range(len(title)): 88 # 持久化数据 89 content = [title[j], location[j], sale[j], comment[j], price[j], nick[j], nid[j], ourl[j]] 90 print(content) 91 data.append(content) 92 print(f'=====已爬取完第{i+1}页=====') 93 time.sleep(3) 94 except: 95 pass 96 # 使用pandas保存数据,使数据持久化 97 data = pd.DataFrame(data, columns=['标题','发货地','销量','评论数','价格','店铺名称','商品ID', '详情页网址']) 98 data.to_csv(f'淘宝{key}信息.csv',encoding='utf-8-sig',index=False) 99 print('淘宝商品数据已完成爬取并保存') 100 101 102 if __name__ == '__main__': 103 run()
运行结果:
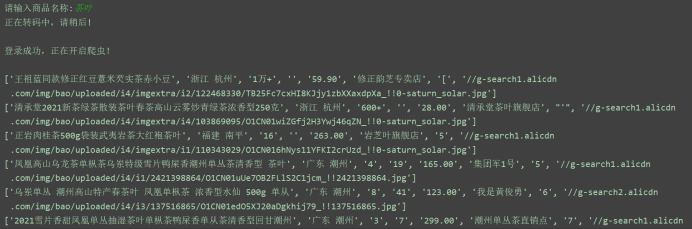
2.对数据进行清洗与处理
2.1 数据探索:
1 # 导入所需包 2 import pandas as pd 3 import pandas as pd 4 import numpy as np 5 import matplotlib.pyplot as plt 6 from sklearn.linear_model import LinearRegression 7 8 df = pd.read_csv('淘宝茶叶信息.csv') 9 df.head()
运行结果:
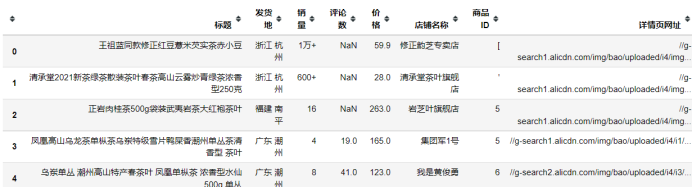
2.2 数据清洗:
1 df.dropna(inplace=True) 2 df.reset_index(drop=True, inplace=True) 3 4 # 删除脏数据后的数据信息 5 df.info()
运行结果:

2.3 销售量数据清洗:
1 sales = [] 2 for p in df['销量'].values: 3 if '万' in p: 4 sales.append(int(p.split('万')[0]) * 10000) 5 elif '+' in p: 6 sales.append(int(p[:-1])) 7 else: 8 sales.append(int(p)) 9 df['销量'] = sales 10 df['销量'] = df['销量'].astype(int)
运行结果:

3.数据分析与可视化
3.1 淘宝茶叶发货地条形图
1 plt.figure(figsize=(25, 10)) 2 address = df['发货地'].value_counts() 3 plt.bar(address.index[:15], address.values[:15], facecolor='yellow') 4 # 显示横轴标签 5 plt.xlabel('发货地', fontsize=18) 6 # 显示纵轴标签 7 plt.ylabel('数量', fontsize=18) 8 # 显示图标题 9 plt.xticks(fontsize=15) 10 plt.yticks(fontsize=15) 11 for i, j in zip(address.index[:15], address.values[:15]): 12 plt.text(i, j, j, va='bottom', ha='center', fontsize=15, color='red') 13 plt.title('淘宝茶叶发货地条形图', fontsize=25) 14 plt.savefig('淘宝茶叶发货地条形图.png') 15 plt.show()
运行结果:
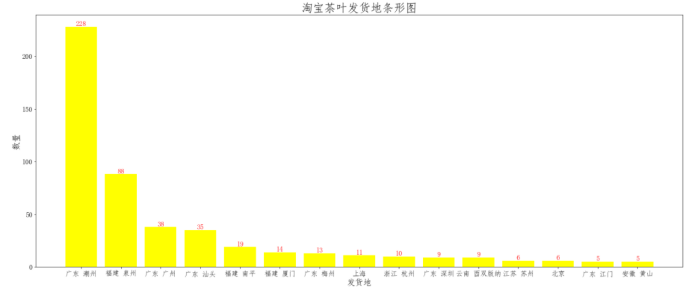
可以发现,发货地最多的是在广东,其中广告潮州居多,广州和汕头分别在第三和第四位。
3.2 淘宝茶叶销量直方图
1 plt.figure(figsize=(12, 8)) 2 plt.hist(df['销量'], bins=10, facecolor='red', edgecolor='black') 3 # 显示横轴标签 4 plt.xlabel('销量区间') 5 # 显示纵轴标签 6 plt.ylabel('频数/频率') 7 # 显示图标题 8 plt.title('淘宝茶叶销量频数/频率分布直方图') 9 plt.savefig('淘宝茶叶销量频数频率分布直方图.png') 10 plt.show()
运行结果:

销量集中在0-30000,其中15000以下居多。
3.3 淘宝茶叶评论数量直方图
plt.figure(figsize=(12, 8)) plt.hist(df['评论数'], bins=20, facecolor='red', edgecolor='black') # 显示横轴标签 plt.xlabel('评论数量区间') # 显示纵轴标签 plt.ylabel('频数/频率') # 显示图标题 plt.title('淘宝茶叶评论数量频数/频率分布直方图') plt.savefig('淘宝茶叶评论数量数频率分布直方图.png') plt.show()
运行结果:

淘宝茶叶评论数量集中在50000以下。
3.4 淘宝茶叶价格直方图
1 plt.figure(figsize=(12, 8)) 2 plt.hist(df['价格'], bins=20, facecolor='red', edgecolor='black') 3 # 显示横轴标签 4 plt.xlabel('评论数量区间') 5 # 显示纵轴标签 6 plt.ylabel('频数/频率') 7 # 显示图标题 8 plt.title('淘宝茶叶价格频数/频率分布直方图') 9 plt.savefig('淘宝茶叶价格数频率分布直方图.png') 10 plt.show()
运行结果:
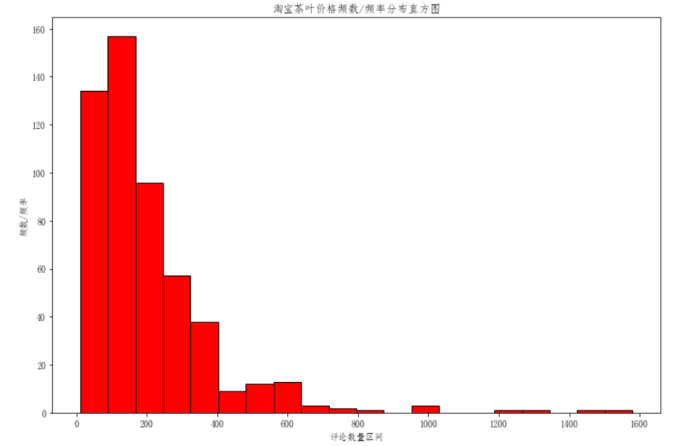
淘宝茶叶价格集中在0-400元之间。
4.淘宝茶叶销量与价格和评论数和之间的线性回归模型
4.1 淘宝茶叶销量与评论数量的散点图
1 plt.figure(figsize=(15, 8)) 2 plt.scatter(df['销量'], df['评论数'],facecolor='green', edgecolor='black') 3 # 显示横轴标签 4 plt.xlabel('销量', fontsize=18) 5 # 显示纵轴标签 6 plt.ylabel('评论数量', fontsize=18) 7 # 显示图标题 8 plt.xticks(fontsize=12) 9 plt.yticks(fontsize=15) 10 plt.title('淘宝茶叶销量与评论数量的散点图', fontsize=25) 11 plt.savefig('淘宝茶叶销量与评论数量的散点图.png') 12 plt.show()
运行结果:
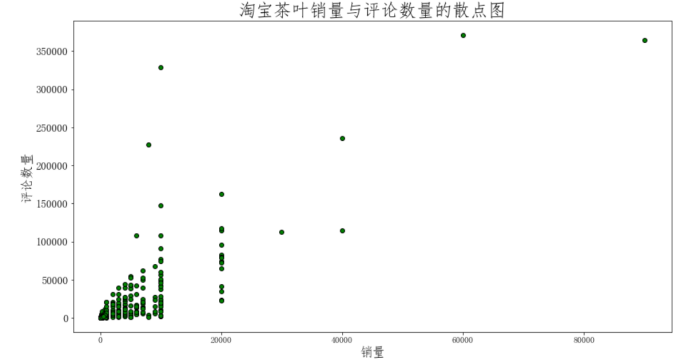
4.2 淘宝茶叶销量与价格的散点图
1 plt.figure(figsize=(15, 8)) 2 plt.scatter(df['销量'], df['价格'],facecolor='green', edgecolor='black') 3 # 显示横轴标签 4 plt.xlabel('销量', fontsize=18) 5 # 显示纵轴标签 6 plt.ylabel('价格', fontsize=18) 7 # 显示图标题 8 plt.xticks(fontsize=12) 9 plt.yticks(fontsize=15) 10 plt.title('淘宝茶叶销量与价格的散点图', fontsize=25) 11 plt.savefig('淘宝茶叶销量与价格价格的散点图.png') 12 plt.show()
运行结果:

由以上的两个散点图分析可知,淘宝茶叶的销量与价格是存在相关关系的,但销量与评论数不存在明显的相关关系,下面构建淘宝茶叶的销量与价格的一元线性回归方程。
1 model = LinearRegression() 2 model.fit(np.array(df['销量'].values).reshape(-1, 1), np.array(df['价格'].values).reshape(-1, 1))
运行结果:
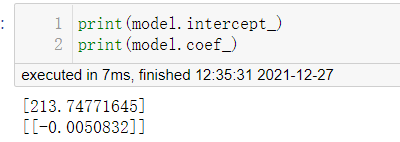
由此可以得到淘宝茶叶销量与价格之间的一线回归模型方程为:
y=213.74771645 - 0.0050832x
以上回国方程说明说明随着淘宝茶叶的价格的升高,销量就会趋于减少。
5.数据持久化
1 # 使用pandas保存数据,使数据持久化 2 data = pd.DataFrame(data, columns=['标题','发货地','销量','评论数','价格','店铺名称','商品ID', '详情页网址']) 3 data.to_csv(f'淘宝{key}信息.csv',encoding='utf-8-sig',index=False) 4 print('淘宝商品数据已完成爬取并保存') 5 6 7 if __name__ == '__main__': 8 run()
运行结果:

6.将以上各部分的代码汇总,附上完整程序代码
1 from selenium import webdriver 2 import time 3 from PIL import Image 4 import base64 5 import threading 6 import pandas as pd 7 import requests 8 import re 9 10 11 12 13 14 # 定义爬虫配置参数 15 16 17 headers = {'Host':'s.taobao.com', 18 'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0', 19 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 20 'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', 21 'Accept-Encoding':'gzip, deflate, br', 22 'Connection':'keep-alive'} 23 list_url = 'http://s.taobao.com/search?q=%(key)s&ie=utf8&s=%(page)d' # 对应页数 24 25 26 27 28 # 打开登录二维码图片 29 30 31 def open_img(img_location): 32 img=Image.open(img_location) 33 img.show() 34 35 36 37 38 39 # 登陆获取cookies 40 41 42 def login(): 43 driver = webdriver.Chrome() 44 driver.get('https://login.taobao.com/member/login.jhtml') 45 try: 46 driver.find_element_by_xpath('//*[@id="login"]/div[1]/i').click() 47 except: 48 pass 49 time.sleep(3) 50 51 # 执行JS获得canvas的二维码 52 53 54 JS = 'return document.getElementsByTagName("canvas")[0].toDataURL("image/png");' 55 56 im_info = driver.execute_script(JS) # 执行JS获取图片信息 57 58 im_base64 = im_info.split(',')[1] # 拿到base64编码的图片信息 59 60 im_bytes = base64.b64decode(im_base64) # 转为bytes类型 61 62 time.sleep(2) 63 with open('./login.png','wb') as f: 64 f.write(im_bytes) 65 f.close() 66 t = threading.Thread(target=open_img,args=('./login.png',)) 67 t.start() 68 print("正在转码中,请稍后!\n") 69 while(True): 70 c = driver.get_cookies() 71 72 if len(c) > 20: # 登陆成功获取到cookies 73 74 cookies = {} 75 for i in range(len(c)): 76 cookies[c[i]['name']] = c[i]['value'] 77 driver.close() 78 print("登录成功,正在开启爬虫!\n") 79 return cookies 80 time.sleep(1) 81 82 83 84 def run(): 85 86 # 正则匹配模式,获取所需数据 87 88 89 p_title = '"raw_title":"(.*?)"' # 标题 90 91 p_location = '"item_loc":"(.*?)"' # 销售地 92 93 p_sale = '"view_sales":"(.*?)人付款"' # 销售量 94 95 p_comment = '"comment_count":"(.*?)"' # 评论数 96 97 p_price = '"view_price":"(.*?)"' # 销售价格 98 99 p_nick = '"nick":"(.*?)"' # 店铺名称 100 101 p_nid = '"nid":"(.*?)"' # 商品id 102 103 p_url = '"pic_url":"(.*?)"' # 商品网址 104 105 106 # 数据爬取 107 108 109 key = input('请输入商品名称:') # 商品的关键词 110 111 N = 100 # 爬取的页数 112 113 data = [] 114 115 cookies = login() # 得到登录的cookies 116 117 for i in range(N): 118 try: 119 page = i*44 120 url = list_url%{'key':key,'page':page} 121 res = requests.get(url,headers=headers,cookies=cookies) 122 html = res.text 123 title = re.findall(p_title,html) 124 location = re.findall(p_location,html) 125 sale = re.findall(p_sale,html) 126 comment = re.findall(p_comment,html) 127 price = re.findall(p_price,html) 128 nick = re.findall(p_nick, html) 129 nid = str(re.findall(p_nid,html)) 130 ourl = re.findall(p_url, html) 131 for j in range(len(title)): 132 133 # 持久化数据 134 135 136 content = [title[j], location[j], sale[j], comment[j], price[j], nick[j], nid[j], ourl[j]] 137 print(content) 138 data.append(content) 139 print(f'=====已爬取完第{i+1}页=====') 140 time.sleep(3) 141 except: 142 pass 143 144 # 使用pandas保存数据,使数据持久化 145 146 147 data = pd.DataFrame(data, columns=['标题','发货地','销量','评论数','价格','店铺名称','商品ID', '详情页网址']) 148 data.to_csv(f'淘宝{key}信息.csv',encoding='utf-8-sig',index=False) 149 print('淘宝商品数据已完成爬取并保存') 150 151 152 if __name__ == '__main__': 153 run() 154 155 156 157 158 159 # 导入所需包 160 161 import pandas as pd 162 import pandas as pd 163 import numpy as np 164 import matplotlib.pyplot as plt 165 from sklearn.linear_model import LinearRegression 166 167 df = pd.read_csv('淘宝茶叶信息.csv') 168 df.head() 169 170 171 172 df.dropna(inplace=True) 173 df.reset_index(drop=True, inplace=True) 174 175 # 删除脏数据后的数据信息 176 177 178 df.info() 179 180 181 182 sales = [] 183 for p in df['销量'].values: 184 if '万' in p: 185 sales.append(int(p.split('万')[0]) * 10000) 186 elif '+' in p: 187 sales.append(int(p[:-1])) 188 else: 189 sales.append(int(p)) 190 df['销量'] = sales 191 df['销量'] = df['销量'].astype(int) 192 193 194 195 196 197 198 plt.figure(figsize=(25, 10)) 199 address = df['发货地'].value_counts() 200 plt.bar(address.index[:15], address.values[:15], facecolor='yellow') 201 202 # 显示横轴标签 203 204 205 plt.xlabel('发货地', fontsize=18) 206 207 # 显示纵轴标签 208 209 210 plt.ylabel('数量', fontsize=18) 211 212 # 显示图标题 213 214 215 plt.xticks(fontsize=15) 216 plt.yticks(fontsize=15) 217 for i, j in zip(address.index[:15], address.values[:15]): 218 plt.text(i, j, j, va='bottom', ha='center', fontsize=15, color='red') 219 plt.title('淘宝茶叶发货地条形图', fontsize=25) 220 plt.savefig('淘宝茶叶发货地条形图.png') 221 plt.show() 222 223 224 225 226 plt.figure(figsize=(12, 8)) 227 plt.hist(df['销量'], bins=10, facecolor='red', edgecolor='black') 228 229 # 显示横轴标签 230 231 232 plt.xlabel('销量区间') 233 234 # 显示纵轴标签 235 236 237 plt.ylabel('频数/频率') 238 239 # 显示图标题 240 241 242 plt.title('淘宝茶叶销量频数/频率分布直方图') 243 plt.savefig('淘宝茶叶销量频数频率分布直方图.png') 244 plt.show() 245 246 247 248 plt.figure(figsize=(12, 8)) 249 plt.hist(df['评论数'], bins=20, facecolor='red', edgecolor='black') 250 251 # 显示横轴标签 252 253 254 plt.xlabel('评论数量区间') 255 256 # 显示纵轴标签 257 258 259 plt.ylabel('频数/频率') 260 261 # 显示图标题 262 263 264 plt.title('淘宝茶叶评论数量频数/频率分布直方图') 265 plt.savefig('淘宝茶叶评论数量数频率分布直方图.png') 266 plt.show() 267 268 269 270 plt.figure(figsize=(12, 8)) 271 plt.hist(df['价格'], bins=20, facecolor='red', edgecolor='black') 272 273 # 显示横轴标签 274 275 276 plt.xlabel('评论数量区间') 277 278 # 显示纵轴标签 279 280 281 plt.ylabel('频数/频率') 282 283 # 显示图标题 284 285 286 plt.title('淘宝茶叶价格频数/频率分布直方图') 287 plt.savefig('淘宝茶叶价格数频率分布直方图.png') 288 plt.show() 289 290 291 292 293 294 295 plt.figure(figsize=(15, 8)) 296 plt.scatter(df['销量'], df['评论数'],facecolor='green', edgecolor='black') 297 298 # 显示横轴标签 299 300 301 plt.xlabel('销量', fontsize=18) 302 303 # 显示纵轴标签 304 305 306 plt.ylabel('评论数量', fontsize=18) 307 308 # 显示图标题 309 310 311 plt.xticks(fontsize=12) 312 plt.yticks(fontsize=15) 313 plt.title('淘宝茶叶销量与评论数量的散点图', fontsize=25) 314 plt.savefig('淘宝茶叶销量与评论数量的散点图.png') 315 plt.show() 316 317 318 319 plt.figure(figsize=(15, 8)) 320 plt.scatter(df['销量'], df['价格'],facecolor='green', edgecolor='black') 321 322 # 显示横轴标签 323 324 325 plt.xlabel('销量', fontsize=18) 326 327 # 显示纵轴标签 328 329 330 plt.ylabel('价格', fontsize=18) 331 332 # 显示图标题 333 334 335 plt.xticks(fontsize=12) 336 plt.yticks(fontsize=15) 337 plt.title('淘宝茶叶销量与价格的散点图', fontsize=25) 338 plt.savefig('淘宝茶叶销量与价格价格的散点图.png') 339 plt.show() 340 341 342 343 344 345 model = LinearRegression() 346 model.fit(np.array(df['销量'].values).reshape(-1, 1), np.array(df['价格'].values).reshape(-1, 1))
(五)总结
1.经过对主题数据的分析与可视化(对淘宝茶叶数据做的相关数据分析),可以得出以下结论:
- 淘宝茶叶发货地最多的是在广东,其中广告潮州居多,广州和汕头分别在第三和第四位。
- 淘宝茶叶销量集中在0-30000,其中15000以下居多。
- 淘宝茶叶评论数量集中在50000以下。
- 淘宝茶叶价格集中在0-400元之间。
- 随着茶叶价格的增加,销量会减少。
已达到预期的目标.
2.本次程序设计任务的各个部分都已完成,该程序通过对淘宝茶叶商品信息爬取与数据分析,主要爬取了商品的标题、销售地、销售量、评论数量、销售价格、店铺名称、商品唯一标识ID以及详情页网址等信息,先是获取到目标网页的内容,再通过库来实现对标签内容的提取;再进行数据清理处理,并且所爬取的目标数据存储到本地的excel文件,实现数据的持久化,最后通过matplotlib等对研究对象绘图分析,最后根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程。在此过程中从一个大框架再不断细分完成每一部分的内容,使自己在这个过程中不断完善进步。于此同时,也发现自己对数据清洗和数据可视化的不足及不熟练,还需多加学习,多加实践。

