
机器学习——对天气进行简单分类
(一)选题背景
机器学习是人工智能领域一个重要的研究课题,在课堂上学习完机器学习中的猫狗识别案例后,想找个简单的数据集做个机器学习期末设计,同时借助本次作业去了解机器学习的代码原理以及其操作。
选择天气分类的主要原因:1本人手机的天气预报一直不是很准确所以就想试着做一个和天气有关的主题,2通过机器学习对天气进行识别,可以便于用户在不便的情况下对室外气候有一定了解,3该数据集较为简单适合我初步学习了解机器学习。
(二)机器学习案例设计方案
数据来源:
本案例中涉及的数据集来源于 kaggle 网站 Kaggle: Your Home for Data Science
本案例用keras框架对天气图片进行简单的识别分类
代码参考,python书中猫狗大战案例,kaggle网站 猫狗识别案例
(三)机器学习的实现步骤
这是我下载的数据集
我们先对数据进行处理编号
1 import os 2 3 image_dir = "D:/weather/kaggle_original_data/" 4 i = 0 5 for dir_name in os.listdir(image_dir): 6 for image_name in os.listdir(os.path.join(image_dir, dir_name)): 7 old_name = os.path.join(image_dir, dir_name, image_name) 8 new_name = os.path.join(image_dir, dir_name, (dir_name + str(i) + ".jpg")) 9 print("new image name :", new_name) 10 print("old image name:", old_name) 11 os.rename(old_name, new_name) 12 i = i + 1 13 i=0
我们再创建test、train、validation三个数据集文件夹
1 import os 2 import shutil #导入os,shutil库用来创建新的数据集 3 #创建数据集 4 from os import mkdir 5 or_data_dir='D:\weather\kaggle_original_data' 6 base_dir='D:\weather\sunny_or_cloudy' 7 os.mkdir(base_dir) 8 9 train_dir=os.path.join(base_dir,'train') 10 os,mkdir(train_dir) #创建训练集目录 11 12 validation_dir=os.path.join(base_dir,'validation') 13 os.mkdir(validation_dir) #创建验证集目录 14 15 test_dir=os.path.join(base_dir,'test') 16 os.mkdir(test_dir) #创建测试集目录 17 18 train_sunny_dir=os.path.join(train_dir,'sunny') 19 os.mkdir(train_sunny_dir) #创建sunny的训练集目录 20 21 train_cloudy_dir=os.path.join(train_dir,'cloudy') 22 os.mkdir(train_cloudy_dir) #创建cloudy的训练集目录 23 24 validation_sunny_dir=os.path.join(validation_dir,'sunny') 25 os.mkdir(validation_sunny_dir) #创建sunny验证集目录 26 27 validation_cloudy_dir=os.path.join(validation_dir,'cloudy') 28 os.mkdir(validation_cloudy_dir) #创建cloudy验证集目录 29 30 test_sunny_dir=os.path.join(test_dir,'sunny') 31 os.mkdir(test_sunny_dir) #创建sunny的测试集目录 32 33 test_cloudy_dir=os.path.join(test_dir,'cloudy') 34 os.mkdir(test_cloudy_dir) #创建cloudy的测试集目录 35 36 #将前1000个cloudy图像复制到train_dir文件夹 37 fnames = ['cl{}.jpg'.format(i) for i in range(0,1000)] 38 for fname in fnames: 39 src = os.path.join(or_data_dir + '/cl', fname) 40 dst = os.path.join(train_cloudy_dir, fname) 41 shutil.copyfile(src, dst) 42 43 #将以下500个cloudy图像复制到train_dir文件夹中 44 fnames = ['cl{}.jpg'.format(i) for i in range(1000, 1500)] 45 for fname in fnames: 46 src = os.path.join(or_data_dir + '/cl', fname) 47 dst = os.path.join(validation_cloudy_dir, fname) 48 shutil.copyfile(src, dst) 49 50 #将以下500个cloudy图像复制到test_dir文件夹 51 fnames = ['cl{}.jpg'.format(i) for i in range(1500, 2000)] 52 for fname in fnames: 53 src = os.path.join(or_data_dir + '/cl', fname) 54 dst = os.path.join(test_cloudy_dir, fname) 55 shutil.copyfile(src, dst) 56 57 58 #将前1000张sunny图片复制到train_dir文件夹中 59 fnames = ['su{}.jpg'.format(i) for i in range(0,1000)] 60 for fname in fnames: 61 src = os.path.join(or_data_dir + '/su', fname) 62 dst = os.path.join(train_sunny_dir, fname) 63 shutil.copyfile(src, dst) 64 65 #将以下500张sunny图片复制到train_dir文件夹中 66 fnames = ['su{}.jpg'.format(i) for i in range(1000, 1500)] 67 for fname in fnames: 68 src = os.path.join(or_data_dir + '/su', fname) 69 dst = os.path.join(validation_sunny_dir, fname) 70 shutil.copyfile(src, dst) 71 72 #将以下500个sunny图片复制到文件夹test_dir 73 fnames = ['su{}.jpg'.format(i) for i in range(1500, 2000)] 74 for fname in fnames: 75 src = os.path.join(or_data_dir + '/su', fname) 76 dst = os.path.join(test_sunny_dir, fname) 77 shutil.copyfile(src, dst)
这是我分类后的数据集,分为测试集、训练集、验证集
数据处理好后,再进行构建网络
1 #构建网络 2 import keras 3 from keras import layers 4 from keras import models 5 model = models.Sequential()#利用keras中的sequential完成网络的构建 6 model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3))) 7 model.add(layers.MaxPooling2D((2, 2))) 8 9 model.add(layers.Conv2D(64, (3, 3), activation='relu')) 10 model.add(layers.MaxPooling2D((2, 2))) 11 12 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 13 model.add(layers.MaxPooling2D((2, 2))) 14 15 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 16 model.add(layers.MaxPooling2D((2, 2))) 17 18 model.add(layers.Flatten()) 19 model.add(layers.Dense(512, activation='relu')) 20 model.add(layers.Dense(1, activation='sigmoid')) 21 model.summary

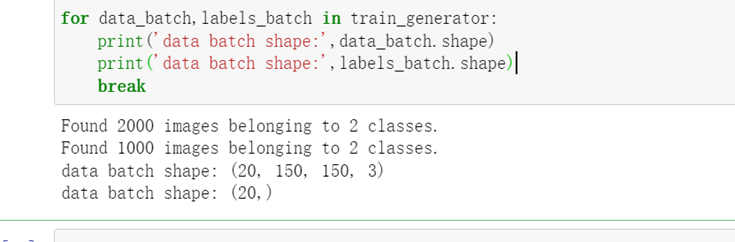
图像在输入网络之前先进行数据预处理
1 #图像在输入网络之前进行数据预处理 2 import keras 3 from keras.preprocessing.image import ImageDataGenerator 4 5 train_datagen=ImageDataGenerator(rescale=1./255) #数据归一化 6 test_datagen=ImageDataGenerator(rescale=1./255) 7 8 #指向训练集图片目录路径 9 train_dir='D:/weather/sunny_or_cloudy/train' 10 train_generator=train_datagen.flow_from_directory( 11 train_dir, 12 target_size=(150,150), #设置图片大小 13 batch_size=20, 14 class_mode='binary') 15 16 #指向验证集图片目录路径 17 validation_dir='D:/weather/sunny_or_cloudy/validation' 18 validation_generator=test_datagen.flow_from_directory( 19 validation_dir, 20 target_size=(150,150), 21 batch_size=20, 22 class_mode='binary') 23 24 for data_batch,labels_batch in train_generator: 25 print('data batch shape:',data_batch.shape) 26 print('data batch shape:',labels_batch.shape) 27 break
接下来进行模型编译和训练
我先进行了10轮的训练
1 #模型编译 2 from keras import optimizers 3 model.compile(loss='binary_crossentropy', 4 optimizer=optimizers.RMSprop(lr=1e-4), 5 metrics=['acc']) 6 7 #利用批量生成器训练模拟 8 history=model.fit_generator(train_generator, 9 steps_per_epoch=100, 10 epochs=10, 11 validation_data=validation_generator, 12 validation_steps=50)

再进行20轮的训练
1 #利用批量生成器训练模拟 2 history=model.fit_generator(train_generator, 3 steps_per_epoch=100, 4 epochs=20, 5 validation_data=validation_generator, 6 validation_steps=50)
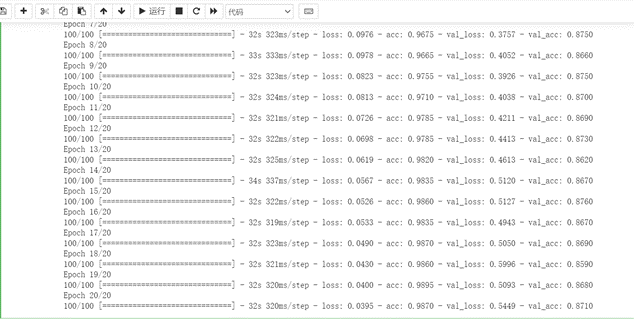
根据训练的数据进行绘图
1 #绘制损失曲线和精度曲线 2 import matplotlib.pyplot as plt 3 acc = history.history['acc'] 4 val_acc=history.history['val_acc'] 5 loss = history.history['loss'] 6 val_loss=history.history['val_loss'] 7 epochs=range(len(acc)) 8 9 plt.plot(epochs, acc,'o',label='Training acc') 10 plt.plot(epochs, val_acc, 'b', label='validation acc') 11 plt.title('Training and validation accuracy') 12 plt.xlabel('Epochs') 13 plt.ylabel('Accuracy') 14 plt.legend() 15 16 plt.figure() 17 18 plt.plot(epochs, loss, 'o', label='Training loss') 19 plt.plot(epochs, val_loss, 'b', label='Validation loss') 20 plt.title('Train and validation loss') 21 plt.xlabel('Epochs') 22 plt.ylabel('Loss') 23 plt.legend() 24 25 plt.show()

为了尽可能的减小过拟合的影响,进行数据加强
1 #为了尽可能的消除过拟合,我打算进行数据增强 2 #定义ImageDataGenerator参数 3 train_datagen = ImageDataGenerator(rescale=1./255, 4 rotation_range=40, #将图像随机旋转40度 5 width_shift_range=0.2, #在水平方向上平移比例为0.2 6 height_shift_range=0.2, #在垂直方向上平移比例为0.2 7 shear_range=0.2, #随机错切变换的角度为0.2 8 zoom_range=0.2, #图片随机缩放的范围为0.2 9 horizontal_flip=True, #随机将一半图像水平翻转 10 fill_mode='nearest') #填充创建像素 11 12 test_datagen = ImageDataGenerator(rescale=1./255) 13 14 train_generator = train_datagen.flow_from_directory( 15 train_dir, 16 target_size=(150,150), 17 batch_size=32, 18 class_mode='binary' 19 ) 20 21 validation_generator = test_datagen.flow_from_directory( 22 validation_dir, 23 target_size=(150,150), 24 batch_size=32, 25 class_mode='binary'
1 #为了更好的消除过拟合,我打算在模型中添加一个Dropout层,添加密集连接分类器前 2 model = models.Sequential() 3 model.add(layers.Conv2D(32, (3,3), activation='relu', 4 input_shape=(150,150, 3))) 5 model.add(layers.MaxPool2D((2,2))) 6 model.add(layers.Conv2D(64, (3,3), activation='relu')) 7 model.add(layers.MaxPool2D((2,2))) 8 model.add(layers.Conv2D(128, (3,3), activation='relu')) 9 model.add(layers.MaxPool2D((2,2))) 10 model.add(layers.Conv2D(128, (3,3), activation='relu')) 11 model.add(layers.MaxPool2D((2,2))) 12 13 model.add(layers.Flatten()) 14 model.add(layers.Dropout(0.5)) 15 model.add(layers.Dense(512, activation='relu')) 16 model.add(layers.Dense(1, activation='sigmoid')) 17 18 model.compile(optimizer=optimizers.RMSprop(lr=1e-4), 19 loss='binary_crossentropy', 20 metrics=['accuracy'])
重新启动后再次运行20轮次
1 #模型编译 2 from keras import optimizers 3 model.compile(loss='binary_crossentropy', 4 optimizer=optimizers.RMSprop(lr=1e-4), 5 metrics=['acc']) 6 7 #利用批量生成器训练模拟 8 history=model.fit_generator(train_generator, 9 steps_per_epoch=100, 10 epochs=20, 11 validation_data=validation_generator, 12 validation_steps=50)

画出增强后的图片
1 #绘制损失曲线和精度曲线 2 import matplotlib.pyplot as plt 3 acc = history.history['acc'] 4 val_acc=history.history['val_acc'] 5 loss = history.history['loss'] 6 val_loss=history.history['val_loss'] 7 epochs=range(len(acc)) 8 9 plt.plot(epochs, acc,'o',label='Training acc') 10 plt.plot(epochs, val_acc, 'b', label='validation acc') 11 plt.title('Training and validation accuracy') 12 plt.xlabel('Epochs') 13 plt.ylabel('Accuracy') 14 plt.legend() 15 16 plt.figure() 17 18 plt.plot(epochs, loss, 'o', label='Training loss') 19 plt.plot(epochs, val_loss, 'b', label='Validation loss') 20 plt.title('Train and validation loss') 21 plt.xlabel('Epochs') 22 plt.ylabel('Loss') 23 plt.legend() 24 plt.show()
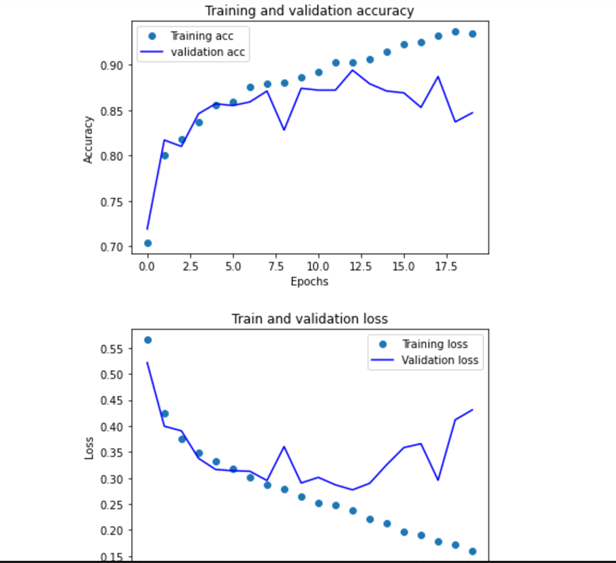
对比之前的图片可以看出有所改善
现自定义图片,将自定义的图片导入到模型当中,查看测试识别结果
1 #读取用户自定义的图像文件,修改尺寸后保存 2 import matplotlib.pyplot as plt 3 from PIL import Image 4 import os.path 5 6 #自定义函数,将图片缩小到(150,150)的大小 7 def convertjpg(jpgfile,outdir,width=150,height=150): 8 img=Image.open(jpgfile ) 9 new_img=img.resize((width,height),Image.BILINEAR) 10 new_img.save(os.path.join(outdir,os.path.basename(jpgfile))) 11 #读取用户自定义图片 12 jpgfile='D:/weather/sunny_or_cloudy/sample/cl3.jpg' 13 convertjpg(jpgfile,'D:/weather/sunny_or_cloudy') 14 img_scale=plt.imread('D:/weather/sunny_or_cloudy/cl3.jpg') 15 plt.imshow(img_scale) #显示改变图像大小后的图片(150x150)

导入测试
1 #导入模型 2 from keras.models import load_model 3 #导入训练模型文件 4 model=load_model('weather.h6') 5 #model.summary 6 7 img_scale=img_scale.reshape(1,150,150,3).astype('float32') 8 img_scale=img_scale/255 #归一化到0——1之间 9 10 result=model.predict(img_scale)#读取图片信息 11 #根据result的值进行判定 12 if result>0.5: 13 print('该图片是多云的概率为:',result) 14 else: 15 print('该图片是晴天的概率为:',1-result)

全代码
1 #对数据图片进行重命名编号 2 import os 3 image_dir = "D:/weather/kaggle_original_data/" 4 i = 0 5 for dir_name in os.listdir(image_dir): 6 for image_name in os.listdir(os.path.join(image_dir, dir_name)): 7 old_name = os.path.join(image_dir, dir_name, image_name) 8 new_name = os.path.join(image_dir, dir_name, (dir_name + str(i) + ".jpg")) 9 print("new image name :", new_name) 10 print("old image name:", old_name) 11 os.rename(old_name, new_name) 12 i = i + 1 13 i = 0 14 15 16 import shutil #导入os,shutil库用来创建新的数据集 17 #创建数据集 18 from os import mkdir 19 or_data_dir='D:\weather\kaggle_original_data' 20 base_dir='D:\weather\sunny_or_cloudy' 21 os.mkdir(base_dir) 22 #创建训练集目录 23 train_dir=os.path.join(base_dir,'train') 24 os,mkdir(train_dir) 25 #创建验证集目录 26 validation_dir=os.path.join(base_dir,'validation') 27 os.mkdir(validation_dir) 28 #创建测试集目录 29 test_dir=os.path.join(base_dir,'test') 30 os.mkdir(test_dir) 31 #创建sunny的训练集目录 32 train_sunny_dir=os.path.join(train_dir,'sunny') 33 os.mkdir(train_sunny_dir) 34 #创建cloudy的训练集目录 35 train_cloudy_dir=os.path.join(train_dir,'cloudy') 36 os.mkdir(train_cloudy_dir) 37 #创建sunny验证集目录 38 validation_sunny_dir=os.path.join(validation_dir,'sunny') 39 os.mkdir(validation_sunny_dir) 40 #创建cloudy验证集目录 41 validation_cloudy_dir=os.path.join(validation_dir,'cloudy') 42 os.mkdir(validation_cloudy_dir) 43 #创建sunny的测试集目录 44 test_sunny_dir=os.path.join(test_dir,'sunny') 45 os.mkdir(test_sunny_dir) 46 #创建cloudy的测试集目录 47 test_cloudy_dir=os.path.join(test_dir,'cloudy') 48 os.mkdir(test_cloudy_dir) 49 50 #将前1000个cloudy图像复制到train_dir文件夹 51 fnames = ['cl{}.jpg'.format(i) for i in range(0,1000)] 52 for fname in fnames: 53 src = os.path.join(or_data_dir + '/cl', fname) 54 dst = os.path.join(train_cloudy_dir, fname) 55 shutil.copyfile(src, dst) 56 #将以下500个cloudy图像复制到train_dir文件夹中 57 fnames = ['cl{}.jpg'.format(i) for i in range(1000, 1500)] 58 for fname in fnames: 59 src = os.path.join(or_data_dir + '/cl', fname) 60 dst = os.path.join(validation_cloudy_dir, fname) 61 shutil.copyfile(src, dst) 62 #将以下500个cloudy图像复制到test_dir文件夹 63 fnames = ['cl{}.jpg'.format(i) for i in range(1500, 2000)] 64 for fname in fnames: 65 src = os.path.join(or_data_dir + '/cl', fname) 66 dst = os.path.join(test_cloudy_dir, fname) 67 shutil.copyfile(src, dst) 68 #将前1000张sunny图片复制到train_dir文件夹中 69 fnames = ['su{}.jpg'.format(i) for i in range(0,1000)] 70 for fname in fnames: 71 src = os.path.join(or_data_dir + '/su', fname) 72 dst = os.path.join(train_sunny_dir, fname) 73 shutil.copyfile(src, dst) 74 #将以下500张sunny图片复制到train_dir文件夹中 75 fnames = ['su{}.jpg'.format(i) for i in range(1000, 1500)] 76 for fname in fnames: 77 src = os.path.join(or_data_dir + '/su', fname) 78 dst = os.path.join(validation_sunny_dir, fname) 79 shutil.copyfile(src, dst) 80 #将以下500个sunny图片复制到文件夹test_dir 81 fnames = ['su{}.jpg'.format(i) for i in range(1500, 2000)] 82 for fname in fnames: 83 src = os.path.join(or_data_dir + '/su', fname) 84 dst = os.path.join(test_sunny_dir, fname) 85 shutil.copyfile(src, dst) 86 87 #构建网络 88 import keras 89 from keras import layers 90 from keras import models 91 model = models.Sequential()#利用keras中的sequential完成网络的构建 92 model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3))) 93 model.add(layers.MaxPooling2D((2, 2))) 94 95 model.add(layers.Conv2D(64, (3, 3), activation='relu')) 96 model.add(layers.MaxPooling2D((2, 2))) 97 98 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 99 model.add(layers.MaxPooling2D((2, 2))) 100 101 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 102 model.add(layers.MaxPooling2D((2, 2))) 103 104 model.add(layers.Flatten()) 105 model.add(layers.Dense(512, activation='relu')) 106 model.add(layers.Dense(1, activation='sigmoid')) 107 model.summary 108 109 #图像在输入网络之前进行数据预处理 110 from keras.preprocessing.image import ImageDataGenerator 111 112 train_datagen=ImageDataGenerator(rescale=1./255) #数据归一化 113 test_datagen=ImageDataGenerator(rescale=1./255) 114 115 #指向训练集图片目录路径 116 train_dir='D:/weather/sunny_or_cloudy/train' 117 train_generator=train_datagen.flow_from_directory( 118 train_dir, 119 target_size=(150,150), #设置图片大小 120 batch_size=20, 121 class_mode='binary') 122 123 #指向验证集图片目录路径 124 validation_dir='D:/weather/sunny_or_cloudy/validation' 125 validation_generator=test_datagen.flow_from_directory( 126 validation_dir, 127 target_size=(150,150), 128 batch_size=20, 129 class_mode='binary') 130 131 for data_batch,labels_batch in train_generator: 132 print('data batch shape:',data_batch.shape) 133 print('data batch shape:',labels_batch.shape) 134 break 135 136 #模型编译 137 from keras import optimizers 138 model.compile(loss='binary_crossentropy', 139 optimizer=optimizers.RMSprop(lr=1e-4), 140 metrics=['acc']) 141 142 #利用批量生成器训练模拟 143 history=model.fit_generator(train_generator, 144 steps_per_epoch=100, 145 epochs=10, 146 validation_data=validation_generator, 147 validation_steps=50) 148 #利用批量生成器训练模拟 149 history=model.fit_generator(train_generator, 150 steps_per_epoch=100, 151 epochs=20, 152 validation_data=validation_generator, 153 validation_steps=50) 154 #绘制损失曲线和精度曲线 155 import matplotlib.pyplot as plt 156 acc = history.history['acc'] 157 val_acc=history.history['val_acc'] 158 loss = history.history['loss'] 159 val_loss=history.history['val_loss'] 160 epochs=range(len(acc)) 161 162 plt.plot(epochs, acc,'o',label='Training acc') 163 plt.plot(epochs, val_acc, 'b', label='validation acc') 164 plt.title('Training and validation accuracy') 165 plt.xlabel('Epochs') 166 plt.ylabel('Accuracy') 167 plt.legend() 168 169 plt.figure() 170 171 plt.plot(epochs, loss, 'o', label='Training loss') 172 plt.plot(epochs, val_loss, 'b', label='Validation loss') 173 plt.title('Train and validation loss') 174 plt.xlabel('Epochs') 175 plt.ylabel('Loss') 176 plt.legend() 177 178 plt.show() 179 180 #为了尽可能的消除过拟合,我打算进行数据增强 181 #定义ImageDataGenerator参数 182 train_datagen = ImageDataGenerator(rescale=1./255, 183 rotation_range=40, #将图像随机旋转40度 184 width_shift_range=0.2, #在水平方向上平移比例为0.2 185 height_shift_range=0.2, #在垂直方向上平移比例为0.2 186 shear_range=0.2, #随机错切变换的角度为0.2 187 zoom_range=0.2, #图片随机缩放的范围为0.2 188 horizontal_flip=True, #随机将一半图像水平翻转 189 fill_mode='nearest') #填充创建像素 190 191 test_datagen = ImageDataGenerator(rescale=1./255) 192 193 train_generator = train_datagen.flow_from_directory( 194 train_dir, 195 target_size=(150,150), 196 batch_size=32, 197 class_mode='binary' 198 ) 199 200 validation_generator = test_datagen.flow_from_directory( 201 validation_dir, 202 target_size=(150,150), 203 batch_size=32, 204 class_mode='binary' 205 206 #为了更好的消除过拟合,我打算在模型中添加一个Dropout层,添加密集连接分类器前 207 model = models.Sequential() 208 model.add(layers.Conv2D(32, (3,3), activation='relu', 209 input_shape=(150,150, 3))) 210 model.add(layers.MaxPool2D((2,2))) 211 model.add(layers.Conv2D(64, (3,3), activation='relu')) 212 model.add(layers.MaxPool2D((2,2))) 213 model.add(layers.Conv2D(128, (3,3), activation='relu')) 214 model.add(layers.MaxPool2D((2,2))) 215 model.add(layers.Conv2D(128, (3,3), activation='relu')) 216 model.add(layers.MaxPool2D((2,2))) 217 218 model.add(layers.Flatten()) 219 model.add(layers.Dropout(0.5)) 220 model.add(layers.Dense(512, activation='relu')) 221 model.add(layers.Dense(1, activation='sigmoid')) 222 223 model.compile(optimizer=optimizers.RMSprop(lr=1e-4), 224 loss='binary_crossentropy', 225 metrics=['accuracy']) 226 227 #重新启动后再次运行20轮次 228 #模型编译 229 from keras import optimizers 230 model.compile(loss='binary_crossentropy', 231 optimizer=optimizers.RMSprop(lr=1e-4), 232 metrics=['acc']) 233 234 #利用批量生成器训练模拟 235 history=model.fit_generator(train_generator, 236 steps_per_epoch=100, 237 epochs=20, 238 validation_data=validation_generator, 239 validation_steps=50) 240 241 #将训练模型数据文件保存在文件h6中 242 model.save('weather.h6') 243 #绘制损失曲线和精度曲线 244 import matplotlib.pyplot as plt 245 acc = history.history['acc'] 246 val_acc=history.history['val_acc'] 247 loss = history.history['loss'] 248 val_loss=history.history['val_loss'] 249 epochs=range(len(acc)) 250 251 plt.plot(epochs, acc,'o',label='Training acc') 252 plt.plot(epochs, val_acc, 'b', label='validation acc') 253 plt.title('Training and validation accuracy') 254 plt.xlabel('Epochs') 255 plt.ylabel('Accuracy') 256 plt.legend() 257 258 plt.figure() 259 260 plt.plot(epochs, loss, 'o', label='Training loss') 261 plt.plot(epochs, val_loss, 'b', label='Validation loss') 262 plt.title('Train and validation loss') 263 plt.xlabel('Epochs') 264 plt.ylabel('Loss') 265 plt.legend() 266 plt.show() 267 268 #读取用户自定义的图像文件,修改尺寸后保存 269 import matplotlib.pyplot as plt 270 from PIL import Image 271 import os.path 272 273 #自定义函数,将图片缩小到(150,150)的大小 274 def convertjpg(jpgfile,outdir,width=150,height=150): 275 img=Image.open(jpgfile ) 276 new_img=img.resize((width,height),Image.BILINEAR) 277 new_img.save(os.path.join(outdir,os.path.basename(jpgfile))) 278 #读取用户自定义图片 279 jpgfile='D:/weather/sunny_or_cloudy/sample/cl3.jpg' 280 convertjpg(jpgfile,'D:/weather/sunny_or_cloudy') 281 img_scale=plt.imread('D:/weather/sunny_or_cloudy/cl3.jpg') 282 plt.imshow(img_scale) #显示改变图像大小后的图片(150x150) 283 284 285 #导入模型 286 from keras.models import load_model 287 #导入训练模型文件 288 model=load_model('weather.h7') 289 #model.summary 290 291 img_scale=img_scale.reshape(1,150,150,3).astype('float32') 292 img_scale=img_scale/255 #归一化到0——1之间 293 294 result=model.predict(img_scale)#读取图片信息 295 #根据result的值进行判定 296 if result>0.5: 297 print('该图片是多云的概率为:',result) 298 else: 299 print('该图片是晴天的概率为:',1-result)
(四)总结
1.在进行本次作业设计的过程中,对机器学习有了进一步的了解,但还不是完全了解,有些地方还是依葫芦画瓢,数据处理不太好,自定义图片判定的准确度较低
2.收获:在此次设计中,我切身感受到,要学会代码就要亲自去操作去编写,碰到问题,去上网查和朋友讨论,在实践中掌握代码。
不足之处:在本设计中对于自定义的图片识别度较低,在使用数据增强和dropout后过拟合情况较前略有改善,但效果还是不好,应该在防止过拟合机制方面多做尝试。

