
adda-pytorch对于代码我的理解
机器学习模型训练五大步骤;第一是数据,第二是模型,第三是损失函数,第四是优化器,第五个是迭代训练过程。
这里主要学习数据模块当中的数据读取,数据模块通常还会分为四个子模块,数据收集、数据划分、数据读取、数据预处理。
有了原始数据之后,需要对数据集进行划分,把数据集划分为训练集、验证集和测试集;训练集用于训练模型,验证集用于验证模型是否过拟合,也可以理解为用验证集挑选模型的超参数,测试集用于测试模型的性能,测试模型的泛化能力
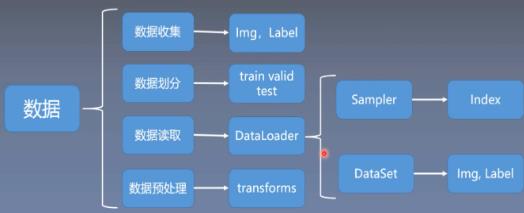
第三个子模块是数据读取,也就是这里要学习的DataLoader,pytorch中数据读取的核心是DataLoader;
第四个子模块是数据预处理,把数据读取进来往往还需要对数据进行一系列的图像预处理,比如说数据的中心化,标准化,旋转或者翻转等等。pytorch中数据预处理是通过transforms进行处理的;
第三个子模块DataLoader还会细分为两个子模块,Sampler和DataSet;Sample的功能是生成索引,也就是样本的序号;Dataset是根据索引去读取图片以及对应的标签;
这里主要学习第三个子模块中的Dataloader和Dataset
1
if __name__ == '__main__':
这句话的意思就是,当这句话所在的py模块被直接运行时,以下代码块将被运行,当这句话所在的py模块是被导入时,代码块不被运行。
2
init_random_seed(params.manual_seed)
这句话的意思就是,初始化随机种子,减少算法随机性,接近原始作者的结果
init_random_seed()位于utils.py中,
def init_random_seed(manual_seed):#manual_seed初始值在param.py中,默认为none
"""Init random seed."""
seed = None
if manual_seed is None:
seed = random.randint(1, 10000)#生成随机数在1和10000之间
else:
seed = manual_seed
print("use random seed: {}".format(seed))
random.seed(seed)#seed一样,生成的随机数一样
torch.manual_seed(seed)#为CPU设置随机种子
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)#为所有GPU设置种子
由于在模型训练的过程中存在大量的随机操作,使得对于同一份代码,重复运行后得到的结果不一致。因此,为了得到可重复的实验结果,我们需要对随机数生成器设置一个固定的种子。
seed固定,生成的结果也是固定的。如果我们设置的随机数与原作者相同,理论上我们的结果应该一致i,不知道我理解的对不对?
解释一下为啥seed固定,生成的随机数固定
真正意义上的随机数(或者随机事件)在某次产生过程中是按照实验过程中表现的分布概率随机产生的,其结果是不可预测的,是不可见的。而计算机中的随机函数是按照一定算法模拟产生的,其结果是确定的,是可见的。我们可以这样认为这个可预见的结果其出现的概率是100%。所以用计算机随机函数所产生的“随机数”并不随机,是伪随机数。
由上面我们就知道了,所谓随机数其实是伪随机数,所谓的‘伪’,意思是这些数其实是有规律的,只不过因为算法规律太复杂,很难看出来而已。
但是,再厉害的算法,如果没有一个初始值,它也不可能凭空造出一系列随机数来,我们说的种子就是这个初始值。
random随机数是这样生成的:我们将这套复杂的算法(是叫随机数生成器吧)看成一个黑盒,把我们准备好的种子扔进去,它会返给你两个东西,一个是你想要的随机数,另一个是保证能生成下一个随机数的新的种子,把新的种子放进黑盒,又得到一个新的随机数和一个新的种子,从此在生成随机数的路上越走越远。
深度学习网络模型中初始的权值参数通常都是初始化成随机数,而使用梯度下降法最终得到的局部最优解对于初始位置点的选择很敏感,为了能够完全复现作者的开源深度学习代码,随机种子的选择能够减少一定程度上,算法结果的随机性,也就是更接近于原始作者的结果,即产生随机种子意味着每次运行实验,产生的随机数都是相同的
但是,在大多数情况下,即使设定了随机种子,仍然没有办法完全复现paper中所给出的模型性能,这是因为深度学习代码中除了产生随机数中带有随机性,其训练的过程中使用 mini-batch SGD或者优化算法进行训练时,本身就带有了随机性。
因为每次更新都是从训练数据集中随机采样出batch size个训练样本计算的平均梯度,作为当前step对于网络权值的更新值,所以即使提供了原始代码和随机种子,想要复现作者paper中的性能也是非常困难的
3数据加载
src_data_loader = get_data_loader(params.src_dataset)#加载MNIST数据集
src_data_loader_eval = get_data_loader(params.src_dataset, train=False)
tgt_data_loader = get_data_loader(params.tgt_dataset)#加载Usps数据集,如果pycharm因为http访问问题不能正常下载,则可以手动从官网上下载
tgt_data_loader_eval = get_data_loader(params.tgt_dataset, train=False)
以get_mnist.py为例
def get_mnist(train):
"""Get MNIST dataset loader."""
# image pre-processing
#Compose看成一种容器,他能对多种数据变换进行组合
pre_process = transforms.Compose([transforms.ToTensor(),#灰度范围从0-255变成0-1
transforms.Normalize(
(0.5,),(0.5,))])##R,G,B每层的归一化用到的均值和方差(0-1)变成(-1-1),两个0.5可以根据数据集重新计算
# 数据集下载
mnist_dataset = datasets.MNIST(root=params.data_root,# root表示存放dataset的位置,本例就是' ./data'
train=train,# train,如果为True,就创建的是训练集,测试集为false
transform=pre_process,#与前面命名保持一致即可
download=True)# download,如果为True,就从网上下载
mnist_data_loader = torch.utils.data.DataLoader(
dataset=mnist_dataset,#数据集来源
batch_size=params.batch_size,# batch_size:每批次进入多少数据,这里代表50
shuffle=True)# shuffle:如果为真,就打乱数据的顺序
return mnist_data_loader
5模型加载
# 单独定义一个weights_init函数,输入参数是m(torch.nn.module或者自己定义的继承nn.module的子类)
# 然后使用net.apply()进行参数初始化
# m.__class__.__name__ 获得nn.module的名字
#权重初始化
def init_model(net, restore):
"""Init models with cuda and weights."""
# init weights of model
net.apply(init_weights)##apply函数会递归地搜索网络内的所有module并把参数表示的函数应用到所有的module上。
#对所有的Conv层都初始化权重.
# 存储权重到指定路径,参考文献[https://blog.csdn.net/qq_39852676/article/details/99617262]()
if restore is not None and os.path.exists(restore):
net.load_state_dict(torch.load(restore))
net.restored = True
print("Restore model from: {}".format(os.path.abspath(restore)))
# check if cuda is available
if torch.cuda.is_available():
cudnn.benchmark = True
net.cuda()
return net
#对权值进行初始化
def init_weights(layer):
layer_name = layer.__class__.__name__
if layer_name.find("Conv") != -1:#find的结果是-1表示没找到关键字。合起来就是当find在字符串layer_name中没找到conv就执行后面的初始化语句
layer.weight.data.normal_(0.0, 0.02)#均值和方差 m.weight.data卷积核参数
elif layer_name.find("BatchNorm") != -1:
layer.weight.data.normal_(1.0, 0.02)
layer.bias.data.fill_(0)#全填充0 m.bias.data偏置项参数
6判别模型
class Discriminator(nn.Module):
"""Discriminator model for source domain."""
def __init__(self, input_dims, hidden_dims, output_dims):#以上这段代码创建了一个”人“的类,这个类的实例(也就是创建的人)具有姓名,性别和年龄这三个属性
"""Init discriminator."""
super(Discriminator, self).__init__()
self.restored = False
self.layer = nn.Sequential(#使用torch.nn.Module,我们可以根据自己的需求改变传播过程,如RNN等,如果你需要快速构建或者不需要过多的过程,直接使用torch.nn.Sequential即可。
nn.Linear(input_dims, hidden_dims),#500 500
nn.ReLU(),
nn.Linear(hidden_dims, hidden_dims),#500 500
nn.ReLU(),
nn.Linear(hidden_dims, output_dims),#500 2
nn.LogSoftmax()#解决上溢出和下溢出问题
)
def forward(self, input):
"""Forward the discriminator."""
out = self.layer(input)
return out
7 为源域训练分类器
def train_src(encoder, classifier, data_loader):
"""Train classifier for source domain."""
####################
# 1. setup network #
####################
# set train state for Dropout and BN layers
encoder.train()
classifier.train()
# setup criterion and optimizer
optimizer = optim.Adam(
list(encoder.parameters()) + list(classifier.parameters()),
lr=params.c_learning_rate,#学习率
betas=(params.beta1, params.beta2))#用于计算梯度运行平均值及其平方的系数
criterion = nn.CrossEntropyLoss()
#参考文献[https://www.cnblogs.com/jfdwd/archive/2004/01/13/11239564.html]()
####################
# 2. train network #
####################
for epoch in range(params.num_epochs_pre):#100
for step, (images, labels) in enumerate(data_loader):
# make images and labels variable
images = make_variable(images)
labels = make_variable(labels.squeeze_())
# zero gradients for optimizer
optimizer.zero_grad()
# compute loss for critic
preds = classifier(encoder(images))
loss = criterion(preds, labels)
# optimize source classifier
loss.backward()
optimizer.step()
# print step info
if ((step + 1) % params.log_step_pre == 0):
print("Epoch [{}/{}] Step [{}/{}]: loss={}"
.format(epoch + 1,
params.num_epochs_pre,
step + 1,
len(data_loader),
loss.item()))
# eval model on test set
if ((epoch + 1) % params.eval_step_pre == 0):
eval_src(encoder, classifier, data_loader)
# save model parameters
if ((epoch + 1) % params.save_step_pre == 0):
save_model(encoder, "ADDA-source-encoder-{}.pt".format(epoch + 1))
save_model(
classifier, "ADDA-source-classifier-{}.pt".format(epoch + 1))
# # save final model
save_model(encoder, "ADDA-source-encoder-final.pt")
save_model(classifier, "ADDA-source-classifier-final.pt")
return encoder, classifier
参考文献https://blog.csdn.net/tsq292978891/article/details/79382306
参考文献
https://blog.csdn.net/qq_41375609/article/details/99327074
https://blog.csdn.net/heqiang525/article/details/89879056
https://blog.csdn.net/qq_37388085/article/details/102663166
posted on 2020-11-03 10:12 doubleqing 阅读(672) 评论(0) 编辑 收藏 举报


