
Hbase-2.0.0_04_Hbase原理
参考博客:Hadoop HBase概念学习系列
参考博客:Hadoop HBase概念学习系列之HBase里的Zookeeper(二十一)
参考博客:Hadoop HBase概念学习系列之HBase里的客户端和HBase集群建立连接(详细)(十四)
参考博客:Hadoop HBase概念学习系列之META表和ROOT表(六)
参考博客:Hadoop HBase概念学习系列之HBase里的HRegion(五)
参考博客:Hadoop HBase概念学习系列之HLog(二)
参考博客:Hadoop HBase概念学习系列之HRegion服务器(三)
参考博客:Hadoop HBase概念学习系列之HMaster服务器(四)
参考博客:ZooKeeper 原理及其在 Hadoop 和 HBase 中的应用
参考博客:HBase介绍和工作原理
参考博客:深入了解HBASE架构(转)
1. 体系结构图
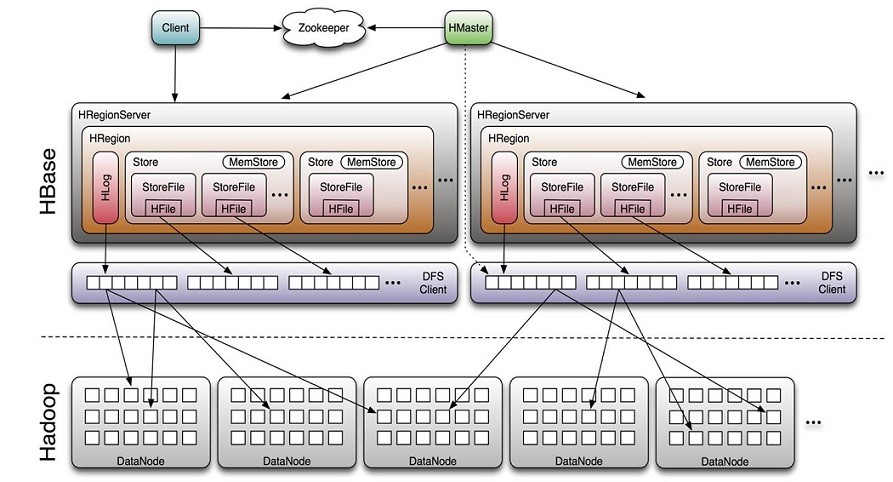
1.1. Hbase特性:
- 强烈一致的读写:HBase不是“最终一致”的数据存储。这使得它非常适合于高速计数器聚合之类的任务。
- 自动分片:HBase表通过区域分布在集群上,随着数据的增长,区域会自动分割和重新分布。
- RegionServer自动故障转移
- Hadoop/HDFS集成:HBase支持HDFS开箱即用的分布式文件系统。
- MapReduce: HBase支持通过MapReduce进行大规模并行处理,将HBase用作source和sink。
- Java客户端API: HBase支持易于使用的Java API进行编程访问。
- Thrift/REST API: HBase还支持非java前端的Thrift 和REST。
- Block Cache和Bloom Filters:HBase支持Block缓存和Bloom过滤器,用于高容量查询优化。
- 操作管理:HBase提供了内置的web页面,用于操作洞察以及JMX度量
2. Zookeeper在HBase中的应用
HMaster选举与主备切换
HMaster选举与主备切换的原理和HDFS中NameNode及YARN中ResourceManager的HA原理相同。
系统容错
当HBase启动时,每个RegionServer都会到ZooKeeper的/hbase/rs节点下创建一个信息节点(下文中,我们称该节点为”rs状态节点”),例如/hbase/rs/[Hostname],同时,HMaster会对这个节点注册监听。当某个 RegionServer 挂掉的时候,ZooKeeper会因为在一段时间内无法接受其心跳(即 Session 失效),而删除掉该 RegionServer 服务器对应的 rs 状态节点。与此同时,HMaster 则会接收到 ZooKeeper 的 NodeDelete 通知,从而感知到某个节点断开,并立即开始容错工作。
HBase为什么不直接让HMaster来负责RegionServer的监控呢?如果HMaster直接通过心跳机制等来管理RegionServer的状态,随着集群越来越大,HMaster的管理负担会越来越重,另外它自身也有挂掉的可能,因此数据还需要持久化。在这种情况下,ZooKeeper就成了理想的选择。
RootRegion管理
对应HBase集群来说,数据存储的位置信息是记录在元数据region,也就是RootRegion上的。每次客户端发起新的请求,需要知道数据的位置,就会去查询RootRegion,而RootRegion自身位置则是记录在ZooKeeper上的(默认情况下,是记录在ZooKeeper的/hbase/meta-region-server节点中)。当RootRegion发生变化,比如Region的手工移动、重新负载均衡或RootRegion所在服务器发生了故障等是,就能够通过ZooKeeper来感知到这一变化并做出一系列相应的容灾措施,从而保证客户端总是能够拿到正确的RootRegion信息。
Region状态管理
HBase里的Region会经常发生变更,这些变更的原因来自于系统故障、负载均衡、配置修改、Region分裂与合并等。一旦Region发生移动,它就会经历下线(offline)和重新上线(online)的过程。
分布式SplitWAL任务管理
当某台RegionServer服务器挂掉时,由于总有一部分新写入的数据还没有持久化到HFile中,因此在迁移该RegionServer的服务时,一个重要的工作就是从WAL中恢复这部分还在内存中的数据,而这部分工作最关键的一步就是SplitWAL,即HMaster需要遍历该RegionServer服务器的WAL,并按Region切分成小块移动到新的地址下,并进行日志的回放(replay)。
由于单个RegionServer的日志量相对庞大(可能有上千个Region,上GB的日志),而用户又往往希望系统能够快速完成日志的恢复工作。因此一个可行的方案是将这个处理WAL的任务分给多台RegionServer服务器来共同处理,而这就又需要一个持久化组件来辅助HMaster完成任务的分配。当前的做法是,HMaster会在ZooKeeper上创建一个splitWAL节点(默认情况下,是/hbase/splitWAL节点),将“哪个RegionServer处理哪个Region”这样的信息以列表的形式存放到该节点上,然后由各个RegionServer服务器自行到该节点上去领取任务并在任务执行成功或失败后再更新该节点的信息,以通知HMaster继续进行后面的步骤。ZooKeeper在这里担负起了分布式集群中相互通知和信息持久化的角色。
3. Catalog Tables
目录表hbase:meta以hbase表的形式存在,并从hbase shell的列表命令中过滤出来,但实际上它和其他表一样是一个表。
hbase:meta表(以前称为.META.)保存了系统中所有的regions列表,hbase:meta的位置存储在ZooKeeper中。
4. 写流程
1、client向Hregionserver发送写请求。
2、Hregionserver将数据写到Hlog(write ahead log)。为了数据的持久化和恢复。
3、hregionserver将数据写到内存(memstore)
4、反馈client写成功。
5. 数据flush过程
1、当memstore数据达到阈值(默认是128M),将数据刷到硬盘【数据存储到hdfs中】,将内存中的数据删除,同时删除Hlog中的历史数据。
2、在hlog中做标记点。
6. Hbase的读流程
1、通过zookeeper和-ROOT- .META.表定位hregionserver。
2、数据从内存和硬盘合并后返回给client
3、数据块会缓存
7. Hmaster的职责
1、管理用户对Table表的增、删、改、查操作;
2、管理HRegion服务器的负载均衡,调整HRegion分布;
3、在HRegion分裂后,负责新HRegion的分配;
4、在HRegion服务器停机后,负责失效HRegion服务器上的HRegion迁移。
Master负责监视集群中的所有RegionServer实例,是所有元数据更改的接口。在分布式集群中,主机通常在NameNode上运行。
一个常见的列表问题涉及到Master宕机时HBase集群发生了什么。因为Hbase客户端直接与regionserver通信,所以集群仍然可以在“稳定状态”运行。此外,根据目录表,hbase:meta作为hbase表存在,并不驻留在Master中。但是,主服务器控制关键功能,如区RegionServer故障转移和完成区域分割。因此,虽然集群在没有Master的情况下仍然可以运行很短的时间,但是主服务器应该尽快重启。
在分布式集群中,主机通常在NameNode上运行。
8. Hregionserver的职责
1、HRegion Server主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBASE中最核心的模块。
2、HRegion Server管理了很多table的分区,也就是region。
9. Client请求
HBase客户端找到服务于特定行范围的RegionServers。它通过查询hbase:meta表来实现这一点。在定位所需的区域之后,客户端联系服务于该region(s)的RegionServer,而不是通过master,并发出读或写请求。这些信息缓存在客户端中,以便后续请求不需要经过查找过程。如果某个区域被主负载均衡器重新分配,或者因为某个RegionServer已死亡,客户端将重新请求目录表以确定用户region的新位置。


