
第四次大作业
-
作业一
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
-
候选网站:http://search.dangdang.com/?key=python&act=input
关键词:学生可自由选择
-
输出信息:MySQL的输出信息如下

-
解题步骤(代码复现)
-
STEP1
-
创建完ddbook project 后编写item文件,观察输出结果可知我们需要获取书籍的标题、作者、出版社、出版日期、简述以及价格,故item文件如下:
import scrapy
class DdbookItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
- STEP2
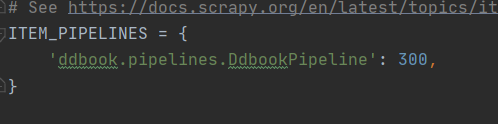
- 修改settings文件(常规必要修改)


- STEP3
- 编写spider程序,待爬取属性对应的xpath路径如下
for li in lis:
title=li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date =li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()# detail有时没有,结果None
item = DdbookItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
- 翻页处理以及控制爬取数量
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if page < 4 and pic_num <= 129:
print("爬取第{}页".format(page))
url = response.urljoin(link)
page += 1
yield scrapy.Request(url=url, callback=self.parse)
- 编写pipeline文件将存储于mysql中
注:需要连接mysql并事先在mysql创建books表
class DdbookPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",passwd = "031904129", db = "MyDB", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values(%s,%s,%s,%s,%s,%s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count += 1
if(self.count > 129):
self.con.commit()
self.con.close()
print("closed")
print("总共爬取", self.count-1, "本书籍")
except Exception as err:
print(err)
return item
-
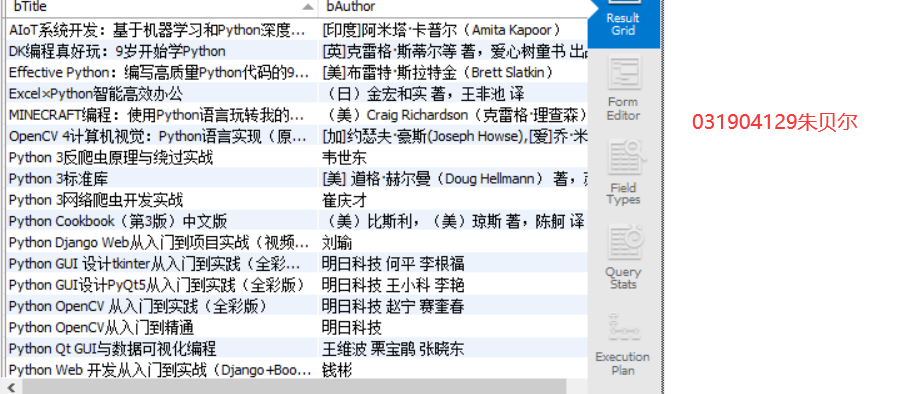
运行结果
-
心得体会:
-
1)第一次使用pymysql,连接mysql,熟悉了相关操作
-
2)熟悉了编写scrapy程序的基本流程
-
3)翻页处理的url可以借助xpath路径进行定位爬取
-
代码地址:https://gitee.com/zhubeier/zhebeier/blob/master/第四次大作业/第一题
-
作业②:
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:招商银行网:http://fx.cmbchina.com/hq/

-
解题步骤
-
STEP1
-
观察输出要求知我们需要爬取的数据项,进而编写items文件
-

-
STEP2
-
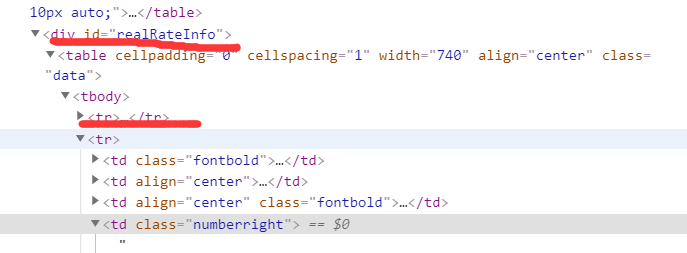
编写spider文件,观察网页编写xpath语句定位
-
-
观察知我们所需的数据项均在这个div[@id='realRateInfo']/table//tr下,需要注意的是这里的第一个tr标签下内容是none,所以需要剔除
-

-
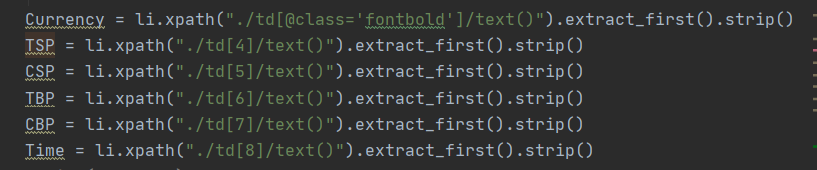
然后编写所需数据项的xpath路径
-
-
STEP3
-
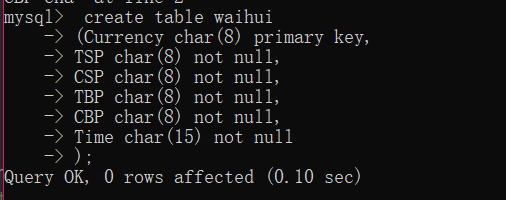
按照需求,我们需将爬取的数据存入mysql中,故在pipeline文件里要连接mysql,并事先在mysql下创建对应的数据库、表
-
-
运行结果
-

-
心得体会
-
基本同作业一
-
代码地址:https://gitee.com/zhubeier/zhebeier/blob/master/第四次大作业/第二题
-
作业③
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board*
-
输出信息:MySQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2...... |
- 解题步骤
- STEP1 连接mysql,创建mysql表
db = pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="031904129",db="stock",charset="utf8")
- STEP2 模拟chrome浏览器
from selenium import webdriver
driver = webdriver.Chrome()
-
STEP3 利用xpath定位找到翻页以及所需数据项的位置
page = driver.find_elements_by_xpath("//*[@id=\"main-table_paginate\"]/span[1]//a")[-1].get_attribute("data-index")
trlist = driver.find_elements_by_xpath("//table[@id=\"table_wrapper-table\"]/tbody/tr")
driver.find_element_by_xpath("//*[@id=\"main-table_paginate\"]/a[2]").click()#点击翻页 -
STEP4 利用多线程爬取,并发执行三个页面,加快速度,共爬取129(学号后三位条数据)
if(num<=130):
cursor.execute("insert into " + tablename + " values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", td)
for stype in stockType:
T = threading.Thread(target=getStock,args=(url+stype,None))#须有两个参数,只有一个会报错。
T.start()
- 运行结果




- 心得体会
- 1)selenium模仿浏览器工作使爬取过程更加的直观
- 2)采取多线程可以加快这种多个页面爬取的速度
- 3)相比requests、scrapy,selenium爬取速度比较慢,因为要等待浏览器的加载完成。
- 代码地址:https://gitee.com/zhubeier/zhebeier/blob/master/第四次大作业/第三题

