
实验四
学号 2019-2020-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1843
姓名: 喻光乾
学号:20184319
实验教师:王志强
实验日期:2020年5月13日
必修/选修: 公选课
1.实验内容
1.解析想要爬取网站的html内容,分析出哪一部标签是想要的信息体部分。
2.将接受到的请求信息进行整理,将需要的正文部分提取出来并且保存到文件中。
2.实现爬取网页上的在线阅读小说,实现离线的阅读方式,拜托网上在线小说的离线下载的控制权限。
2. 实验过程及结果
实验代码:

运行结果:
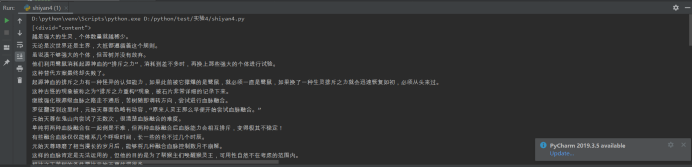
保存文档:

具体步骤及思路:
先将页面的链接赋值给一个变量url,然后使用requests的get方法发送请求,然后将接受到的返回信息转化为text的格式,最后用Beautifulsoup将返回信息解码,调用方法的参为自带的解析方法。

在浏览器中打开连接,在页面中用F12打开监视器,将页面的HTML都显示出来,之后找到小说正文内容保存的那部分标签。
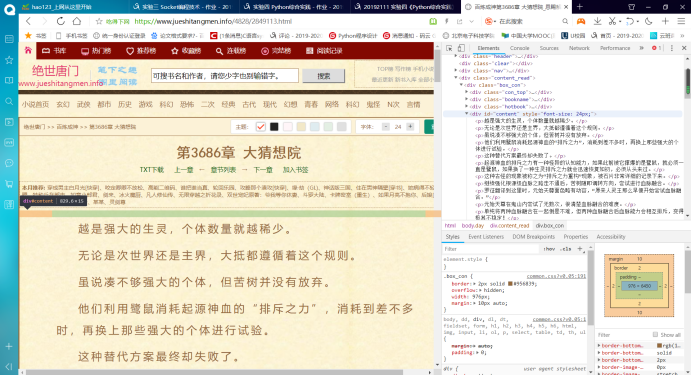
根据标签名,使用Beautifulsoup里面查找工具从返回的所有内容中找出保存正文的部分,然后将这部分赋值给变量div_tag。
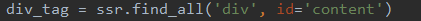
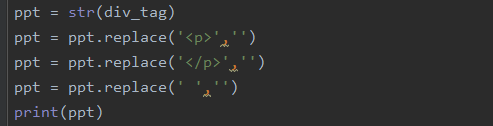
将变量div_tag的内容转换为字符串类型便于将内容筛选。然后使用字符串函数的方法replace,将
,<\p>的内容全部置换为空,同时也将空格置换为空。到了这步,网页上的小说内容全都保存到了变量ppt中。
最后再以写的方式新打开一个文档20184319,将小说的内容都写入文档中,再将文档关闭。

3. 实验过程中遇到的问题和解决过程
- 问题1:在部分的小说网页中,为了防止程序爬取信息,会在信息的前面或者后面加一些加密信息,导致在程序执行中输出的内容为乱码。
- 问题1解决方案:更换一个在传输内容时没有将消息加密的网站进行爬取。
- 问题2:在解析网站的HTML内容时,难以寻找内容的所在标签
- 问题2解决方案:将使用pycharm输出内容的解析网站数据的方式改成用浏览器自带的解析器去寻找小说内容所在的标签。
其他(感悟、思考等)
python编写的爬虫程序先比较其他的编程语言来说有很大的优势,也有许多功能强大库函数和方法可以调用,这是一个很好的编写爬虫程序的环境。
python相对于像C语言和JAVA语言来说,他的编写方式没有那么多的硬性的方式要求,比较开发。很适合新入门的编程人员学习。
并且我觉得python的很多可视化之类的库比较多,很适合新手在学习后马上可以看到自己的学习成果。
我对于课程的感觉就是在学习基本的语句和功能之后,我们应该自主的去学习这门语言的现成的功能库,将这些库的功能灵活运用才是将这门语言的力量发挥出来的最好办法。

