Kafka
Kafka
Exactly Once语义 精准一次:
- 将服务器的ACK级别设置为-1,可以保证Producer到Server之间不会丢失数据,即At Least Once语义。相对的,将服务器ACK级别设置为0,可以保证生产者每条消息只会被发送一次,即At Most Once语义。
- At Least Once可以保证数据不丢失,但是不能保证数据不重复;相对的,At Most Once可以保证数据不重复,但是不能保证数据不丢失。
幂等性:
- 谓的幂等性就是指Producer不论向Server发送多少次重复数据,Server端都只会持久化一条。幂等性结合At Least Once语义,就构成了Kafka的Exactly Once语义。即:At Least Once + 幂等性 = Exactly Once。
- 启用幂等性,将Producer的参数中 enable.idempotence设置为true。开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。而Broker端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会持久化一条。但无法保证跨会话和分区的PID保持一致。
说明:如果要保证跨分区跨会话一致,需要开启事务。
Kafka事务:
事务可以保证Kafka在Exactly Once语义的基础上,生产和消费可以跨分区和会话,要么全部成功,要么全部失败。
- Producer事务:为了实现跨分区跨会话的事务,需要引入一个全局唯一的TransactionID,并将其和producer获得的PID进行绑定。这样当Producer重启后就可以通过正在进行的TransactionID获得原来的PID。
说明:Transaction Coordinator用来管理Transaction,Producer就是通过和Transaction Coordinator交互获得TransactionID 对应的任务状态。Transaction Coordinator还负责将事务所有写入Kafka的一个内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。
- Consumer事务(精准一次性消费):这是由于Consumer可以通过offset访问任意信息,而且不同的Segment File生命周期不同,同一事务的消息可能会出现重启后被删除的情况,导致无法保证Commit的信息被精确消费。想完成Consumer端的精准一次性消费,需要kafka消费端将消费过程和提交offset过程做原子绑定。此时需要将kafka的offset保存到支持事务的自定义介质
Kafka高效读写
-
分区:
分区支持kafka并发写入。
-
顺序写磁盘:
Kafka的官网声明顺序写磁盘的速率可能比内存中随机写的速度还要快,相同的磁盘顺序写能达到600M/s,而随机写只有100K/s。
顺序写值所以快是由于省掉了大量的磁头寻址时间,这与磁盘的机械结构有关。
-
应用页缓存 Pagecache:
Kafka数据的持久化是直接持久化到 Pagecache中的,I/O Scheduler 会将连续的小块写组装成物理写从而提高性能,并且IO调度器会尝试将一些写操作按照磁头的寻址方式进行重新排序,从而减少磁头的移动时间; Pagecache会充分利用所有的空闲内存,非JVM内存,如果使用应用层 Cache(即 JVM 堆内存),会增加 GC 负担;读操作可直接在 Page Cache 内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过 Page Cache)交换数据;如果进程重启,JVM 内的 Cache 会失效,但 Page Cache 仍然可用;
说明:尽管持久化到Pagecache上可能会造成宕机丢失数据的情况,但这可以被Kafka的Replication机制解决。如果为了保证这种情况下数据不丢失而强制将 Page Cache 中的数据 Flush 到磁盘,反而会降低性能。
-
零复制技术:
通常情况下实现文件的复制要先将文件加载到内核空间 Kernel Space 中的 Page Cache中,再将数据加载到用户空间 User Space 中的 Application Cacahe中,再将数据加载到内核空间Kernel Space 中的 Socket Cache中 最后加载到NIC,这个过程效率很低,而Kafka则选择将文件加载到内核空间 Kernel Space 中的 Page Cache中后直接将从内核空间 Kernel Space 中的 Page Cache加载到NIC。
KafkaProducer 发送消息流程
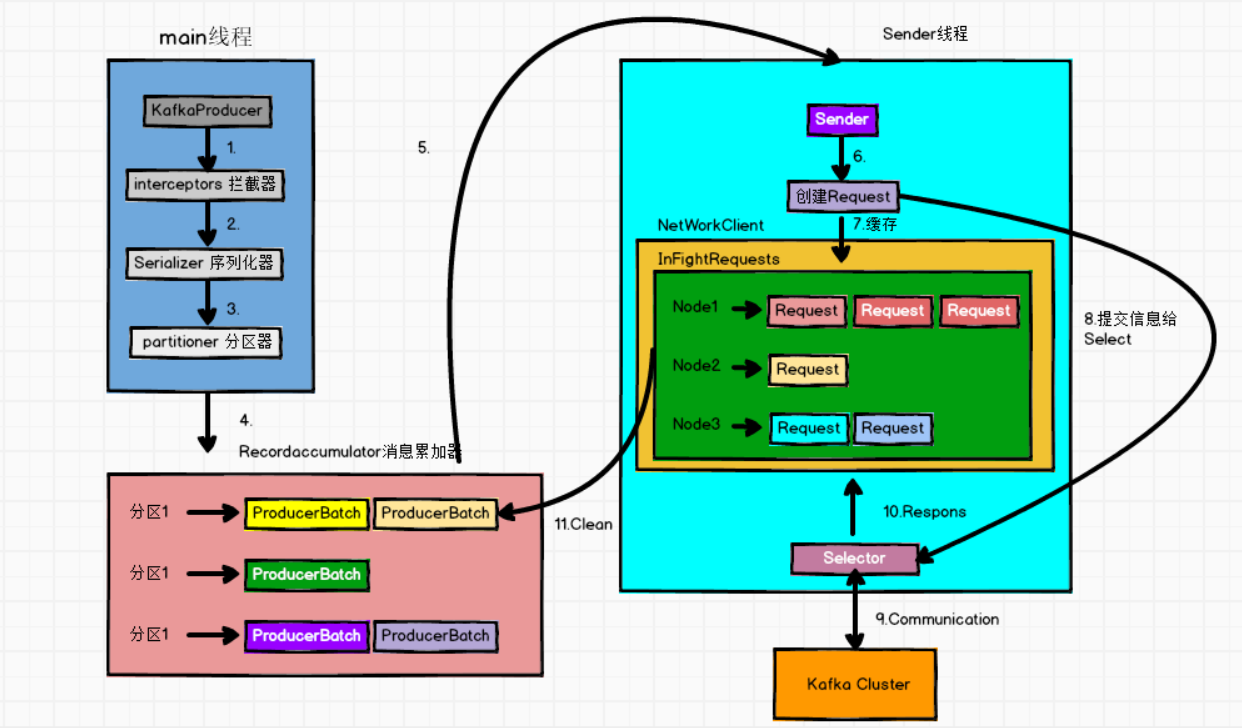
- afka的Producer发送消息采用的是异步发送的方式,共涉及两个线程Main线程和Sender线程,以及一个线程共享变量RecordAccumulator。Main线程:负责将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka集群的broker。Main线程中producer将生产的ProducerRecord对象发送给拦截器处理,然后序列化并分区,最后发送给RecordAccumulator。在RecordAccumulator中,消息对象都是以batch聚集,只有数据积累到batch.size(16384)之后,Sender线程才会发送数据,如果数据迟迟未达到batch.size,Sender会等待linger.ms(0) 时间之后发送数据。
说明:如果自定义生产者后不关闭生产者对象,会导致主线程直接结束,会使sender线程就无法继续工作,关闭对象的时候会flush内存,使batch数据发走。也可以使主线程阻塞,只要sender线程扛过主线程关闭前将资源发送出去即可。
Zookeeper在Kafka中的作用
-
Kafka集群各个broker之间的联系依赖于Zookeeper,启动Kafka后,所有的broker都会去Zookeeper中注册,然后会在所有的broker中选择一个Controller出来,它负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作,并且Controller的管理工作都是依赖于Zookeeper的。
-
Leader选举流程:Controller会监控Zookeeper中/brokers/ids/下的broker,并根据副本Repilcas顺序选出leader,当leader故障时,Zookeeper中/brokers/ids/下的broker会发生改变,Controller会监听到, 然后Controller会获取ISR,并根据副本Repilcas顺序重新新选举出leader,若该broker存在ISR中,该节点的副本就作为leader,否则重新选。然后更新leader以及ISR。
说明:副本时由broker维护的,如果broker不出现问题通常情况下副本也不会出现问题,当副本出现问题时,即代表broker本身出现了问题。
Offset的维护
- 由于consumer在消费过程中可能会出现断电宕机等故障,Consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。在Kafka 0.9 版本之前,默认将 Offset 保存在 Zookeeper中,从 0.9 版本之后,Consumer 默认将 Offset 保存在 Kafka中的一个内置topic,即consumer_offset。既然它为Kafka中的一个topic,就可以通过消费者进行消费。
Offset重置:
-
问题:启动一个新的消费者组去消费数据时,默认消费不到topic中已有的消息。
-
原因:Kafka会在两种情况下重置offset
- 参数:'auto.offset.reset'
- 参数值:
- earliest: automatically reset the offset to the earliest offset
- latest: automatically reset the offset to the latest offset
- ① When there is no initial offset in Kafka (新的组在kafka中没有消费记录)
- ② if the current dose not exist any more on the server (e.g. because the data has been deleted,只存七天。)
说明:重置后Kafka默认将offset重置为latest,可以通过'auto.offset.reset '使新添加的消费者组可以读取之前的消息,仅限新的消费者组。
手动提交offset的两种方法:
分别是commitSync(同步提交)和commitAsync(异步提交)。
- 相同点:都会将本次poll的一批数据最高的偏移量提交(latest)。
- 不同点:是commitSync 阻塞当前线程直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败),而commitAsync则不阻塞当前线程,没有失败重试机制,故有可能提交失败。
声明:如果不提交offset,则消费者在没有新数据的情况下,消费不到已经被之前消费者消费过的数据,因为之前消费过的数据提交了offset。但是重新生产的数据可以被消费到,只不过是没有提交offset而已,由于没有提交offset,Kafka并不知道当前消费消费到哪里了,当再次启动
当前消费者是会重新消费之前消费过没有提交offset的数据。当消费者消费一批数据没有提交offset后,再次生产消息,消费者不会再消费之前消费过的消息,而只会消费生产者发送的新消息,因为消费者自己会在内存中维护offset,不提交只是kafka不知道而已, 消费者会根据生产者生产的新消息继续消费,消费者自己清楚自己消费到哪里了,但是下次重启消费者会重新消费。不提交不影响消费者消费,消费者该消费消费。
问题:消费者重复消费、消费者漏消费
- 先消费后提交offset-> 重复消费
- 先提交后消费 -> 漏消费
- 精准一次性消费:需要将消费和提交做成事务,保证数据的一致性与完整性。
说明:自定义存储offset需要在分区分配前进行offset的提交,分区分配后从map中获取新的offset。原来不用设置这两个方法时Kafka帮我们存储了offset,Kafka知道当前已经消费到哪里了,Kafka帮我们做了。自定义之后kafk不再知道当前消费到哪里了,需要我们自己写着两个方法。每当有新的消费者加入消费者组,Kafka都会进行分区分配。用Map来存储当前分区的offset,用分区作为key。
Flume与 Kafka的对接:
-
涉及组件:
- Kafka Source (消费者)
- Kafka Channel (生产者、消费者、Channel)
- Kafka Sink (生产者)
-
Flume -> Kafka
xxxSource -> xxxChannel -> Kafka Sink
xxxSource -> KafkaChannel -
Kafka -> Flume
KafkaSource -> xxxChannel -> xxxSink
KafkaChannel -> xxxSink -
Flume -> Kafka -> Flume
xxxSource -> xxxChannel -> KafkaSink -> kafka -> KafkaSource -> xxxChannel -> xxxSink
xxxSource -> KafkaChannel -> kafka -> KafkaChannel -> xxxSink

