
7.逻辑回归实践
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
利用正则化可以有效的防止过拟合。过拟合是因为在某一位置函数导数变化大,系数的值也很大因此利用正则化可以约束范数不让其太大,有效防止过拟合出现的情况。
2.用logiftic回归来进行实践操作,数据不限。
用逻辑回归预测彩票的注数与中奖率的关系。
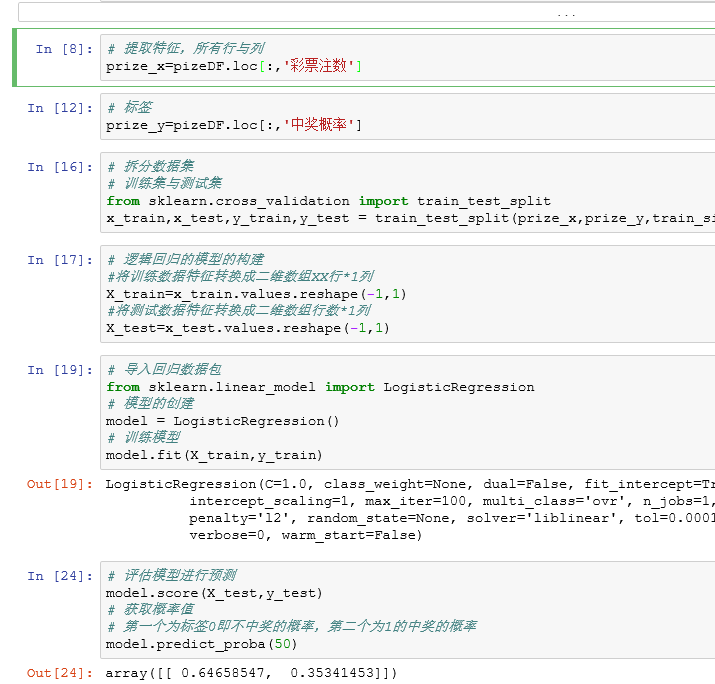
1 # 导入数据包 2 from collections import OrderedDict 3 import pandas as pd 4 # 数据集 5 prizeData ={ 6 '彩票注数':[10,15,20,25,32,65,78,85,99,102,109,115,124,138,145,158,162,169,172,188], 7 '中奖概率':[0,0,0,0,0,0,0,1,0,1,1,0,0,1,1,1,1,1,1,1] 8 } 9 # 调用有序字典 10 prizeDatadict = OrderedDict(prizeData) 11 pizeDF = pd.DataFrame(prizeDatadict) 12 pizeDF.head(20) 13 14 # 提取特征,所有行与列 15 prize_x=pizeDF.loc[:,'彩票注数'] 16 # 标签 17 prize_y=pizeDF.loc[:,'中奖概率'] 18 # 拆分数据集 19 # 训练集与测试集 20 from sklearn.cross_validation import train_test_split 21 x_train,x_test,y_train,y_test = train_test_split(prize_x,prize_y,train_size=0.8) 22 # 逻辑回归的模型的构建 23 #将训练数据特征转换成二维数组XX行*1列 24 X_train=x_train.values.reshape(-1,1) 25 #将测试数据特征转换成二维数组行数*1列 26 X_test=x_test.values.reshape(-1,1) 27 # 导入回归数据包 28 from sklearn.linear_model import LogisticRegression 29 # 模型的创建 30 model = LogisticRegression() 31 # 训练模型 32 model.fit(X_train,y_train) 33 # 评估模型进行预测 34 model.score(X_test,y_test) 35 # 获取概率值 36 # 第一个为标签0即不中奖的概率,第二个为1的中奖的概率 37 model.predict_proba(50)
输入注数为50注后预测概率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号