
4.K均值算法--应用
1. 应用K-means算法进行图片压缩
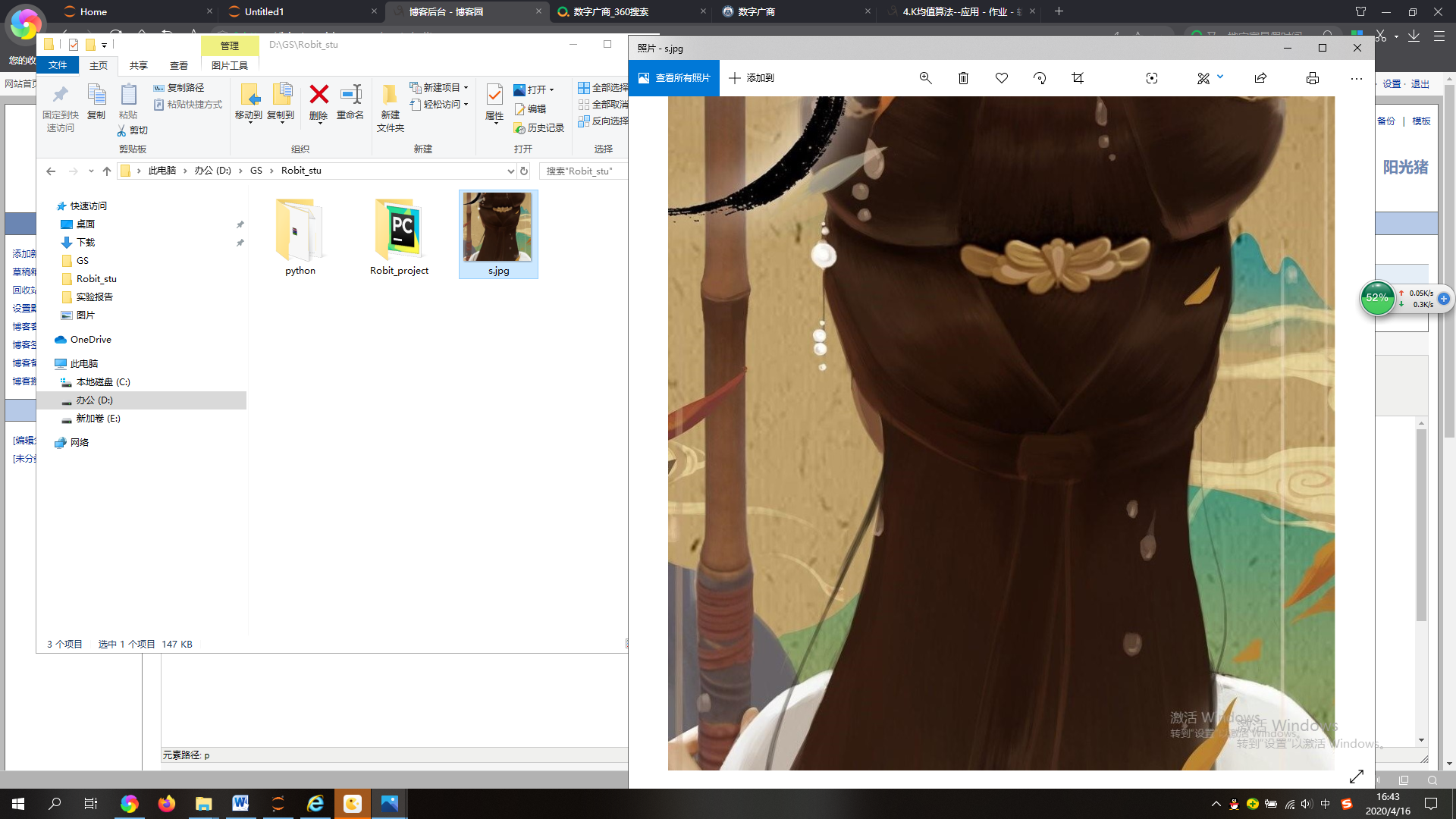
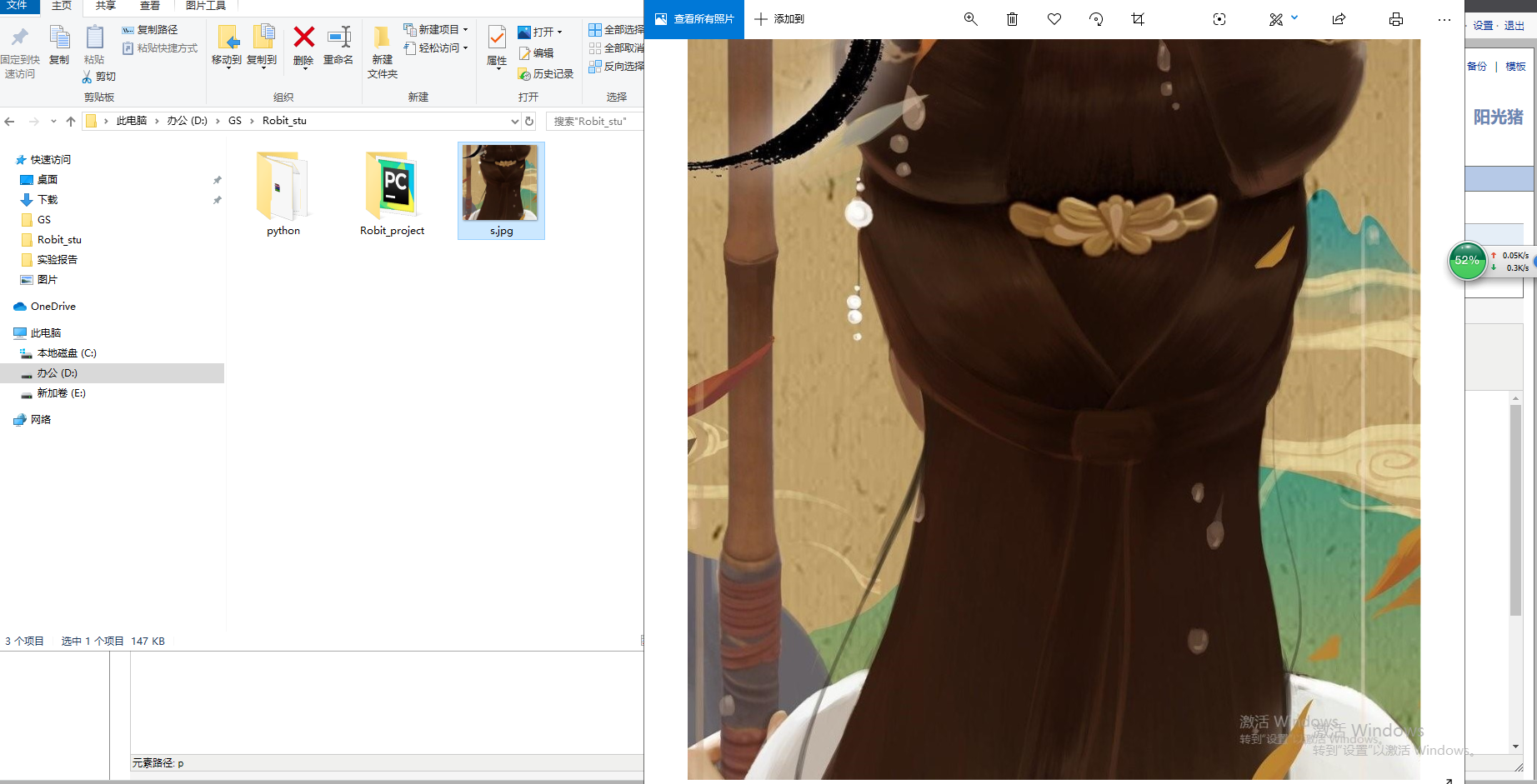
读取一张图片
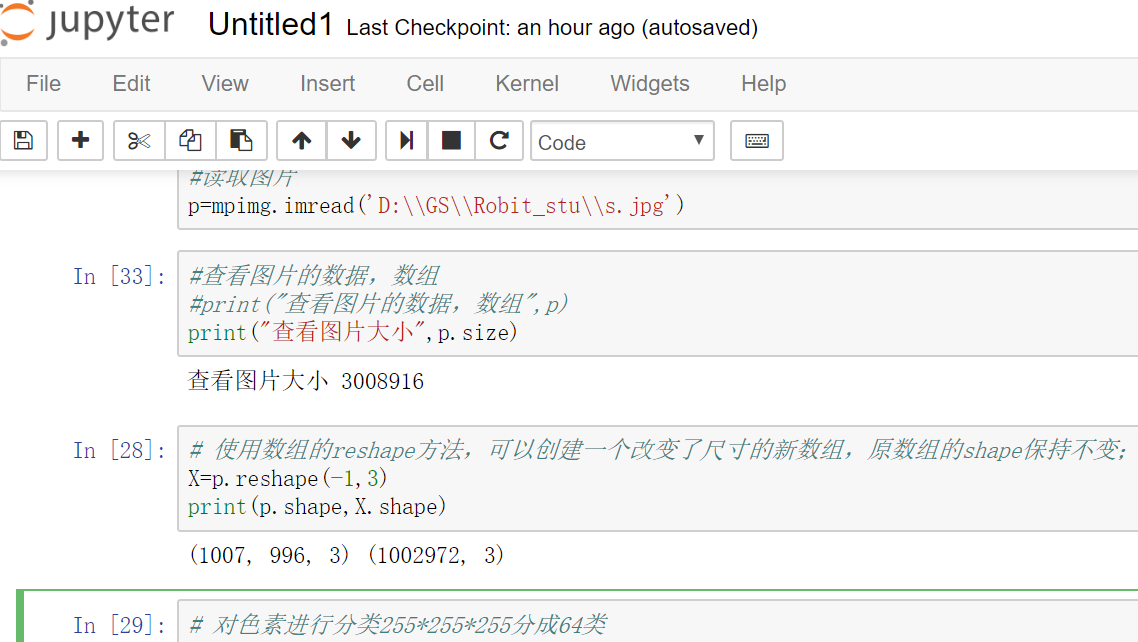
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
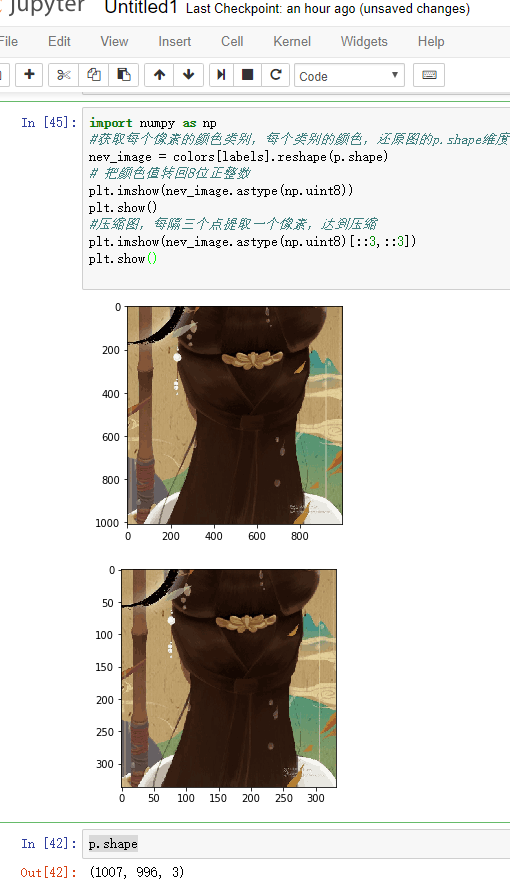
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
1.1从路径中读入原图:
1.2实验结果

1.3实验代码:
1 from sklearn.cluster import KMeans 2 import matplotlib.pyplot as plt 3 from PIL import Image 4 import matplotlib.image as mpimg 5 #读取图片 6 p=mpimg.imread('D:\\GS\\Robit_stu\\s.jpg') 7 #查看图片的数据,数组 8 #print("查看图片的数据,数组",p) 9 print("查看图片大小",p.size) 10 11 # 对色素进行分类255*255*255分成64类 12 n_colors = 64 13 # 模型,对图片像素颜色进行聚类 14 model =KMeans(n_colors) 15 # 训练X喂食,数据线性化,即一维数组像素的类别 16 labels = model.fit_predict(X) 17 # 二维(64,3)聚类中心,用于颜色分类,作为每个颜色的分类 18 colors = model.cluster_centers_ 19 20 import numpy as np 21 #获取每个像素的颜色类别,每个类别的颜色,还原图的p.shape维度 22 nev_image = colors[labels].reshape(p.shape) 23 plt.imshow(p); 24 plt.show() 25 # 把颜色值转回8位正整数 26 plt.imshow(nev_image.astype(np.uint8)) 27 plt.show() 28 #压缩图,每隔三个点提取一个像素,达到压缩 29 plt.imshow(nev_image.astype(np.uint8)[::3,::3]) 30 plt.show()
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
爬取100条数据对电影的人次、上座率、票价、名次进行KMeans均值算法分成四类,可以得出引人喜欢胡电影
实验代码如下:
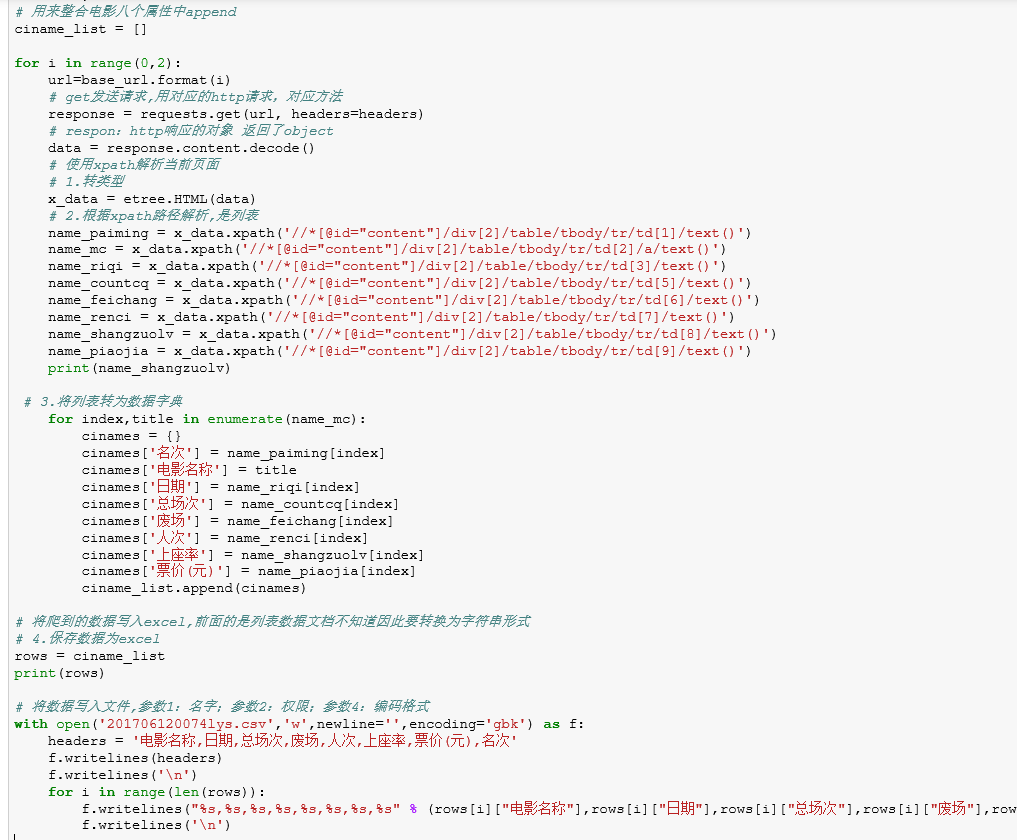
# 导入框架,获取爬虫网站的url import requests from lxml import etree # python爬取回来多数是bytes类型:但是你写入需要字符串decode("utf-8") # 如果爬取过来的str类型:但你要写入bytes类型,encode转换utf-8 # 定义目标链接 base_url = 'http://58921.com/daily/wangpiao?page={}' headers = { "User-Agent": 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1' } # 用来整合电影八个属性中append ciname_list = [] for i in range(0,2): url=base_url.format(i) # get发送请求,用对应的http请求,对应方法 response = requests.get(url, headers=headers) # respon:http响应的对象 返回了object data = response.content.decode() # 使用xpath解析当前页面 # 1.转类型 x_data = etree.HTML(data) # 2.根据xpath路径解析,是列表 name_paiming = x_data.xpath('//*[@id="content"]/div[2]/table/tbody/tr/td[1]/text()') name_mc = x_data.xpath('//*[@id="content"]/div[2]/table/tbody/tr/td[2]/a/text()') name_riqi = x_data.xpath('//*[@id="content"]/div[2]/table/tbody/tr/td[3]/text()') name_countcq = x_data.xpath('//*[@id="content"]/div[2]/table/tbody/tr/td[5]/text()') name_feichang = x_data.xpath('//*[@id="content"]/div[2]/table/tbody/tr/td[6]/text()') name_renci = x_data.xpath('//*[@id="content"]/div[2]/table/tbody/tr/td[7]/text()') name_shangzuolv = x_data.xpath('//*[@id="content"]/div[2]/table/tbody/tr/td[8]/text()') name_piaojia = x_data.xpath('//*[@id="content"]/div[2]/table/tbody/tr/td[9]/text()') print(name_shangzuolv) # 3.将列表转为数据字典 for index,title in enumerate(name_mc): cinames = {} cinames['名次'] = name_paiming[index] cinames['电影名称'] = title cinames['日期'] = name_riqi[index] cinames['总场次'] = name_countcq[index] cinames['废场'] = name_feichang[index] cinames['人次'] = name_renci[index] cinames['上座率'] = name_shangzuolv[index] cinames['票价(元)'] = name_piaojia[index] ciname_list.append(cinames) # 将爬到的数据写入excel,前面的是列表数据文档不知道因此要转换为字符串形式 # 4.保存数据为excel rows = ciname_list print(rows) # 将数据写入文件,参数1:名字;参数2:权限;参数4:编码格式 with open('201706120074lys.csv','w',newline='',encoding='gbk') as f: headers = '电影名称,日期,总场次,废场,人次,上座率,票价(元),名次' f.writelines(headers) f.writelines('\n') for i in range(len(rows)): f.writelines("%s,%s,%s,%s,%s,%s,%s,%s" % (rows[i]["电影名称"],rows[i]["日期"],rows[i]["总场次"],rows[i]["废场"],rows[i]["人次"],rows[i]["上座率"],rows[i]["票价(元)"],rows[i]["名次"])) f.writelines('\n') import pandas as pd import numpy as np from sklearn.cluster import KMeans df = pd.read_csv("D:\\GS\\Robit_stu\\python\\201706120074lys.csv",encoding='gbk') df # 取出变量为训练做准备 like = np.array(df.iloc[:,4:8].fillna(value=0).astype(int)) like。shape # 构建模型,分成4类 model=KMeans(n_clusters=4) # 训练数据集 model.fit(like) # 喂食训练好的数据 y=model.predict(like) y lys=np.array(df[y==0]['电影名称']) lys # lys.shape
实验结果
1.获取网页数据,用xpath路径对网页解析,爬取到的数据进行类型转为字典存进列表中,然后写入CSV
2.把处理过的数据读取、切片,然后用于训练
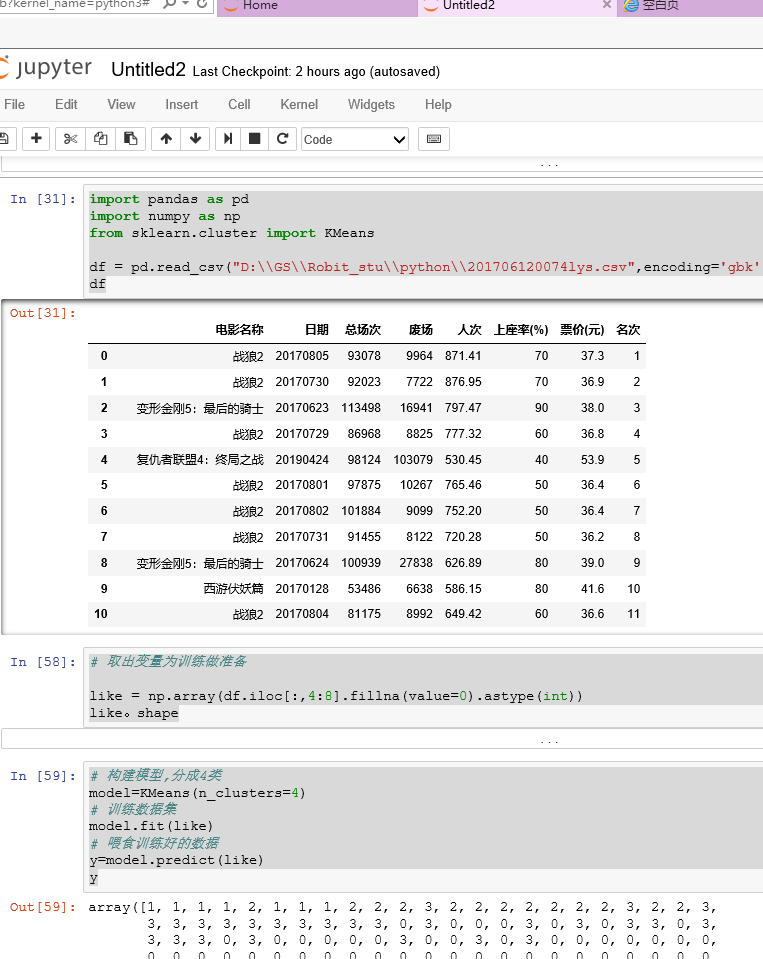
3.电影分成4类,从中可以挑选热度大的自己再观看


 浙公网安备 33010602011771号
浙公网安备 33010602011771号