
Python笔记:pandas之数据清洗
删除重复的数据
#DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复的行
data.duplicated()
#此方法会返回一个DataFrame,重复的数组会标为False
data.drop_duplicated()
#以上两个方法默认会判断全部列,也可以指定部分列进行重复项判断
#默认保留的是第一个出现的值组合,传入keep='last'则保留最后一个
数据联结
#使用map方法可以通过相同的列名进行两个DataFrame的联结操作 data.map()
替换值
#replace有两个参数 #第一个参数,是需要替换的对象,可以是常量、列表 #第二个参数,是替换的值,可以是常量、列表 data.replace()
重命名轴索引
#传入index=字典可以实现对部分轴标签的更新 #传入columns=字典可以实现对部分列标签的更新 #传入inplace=True可以实现原地修改 data.rename()
离散化和面元划分
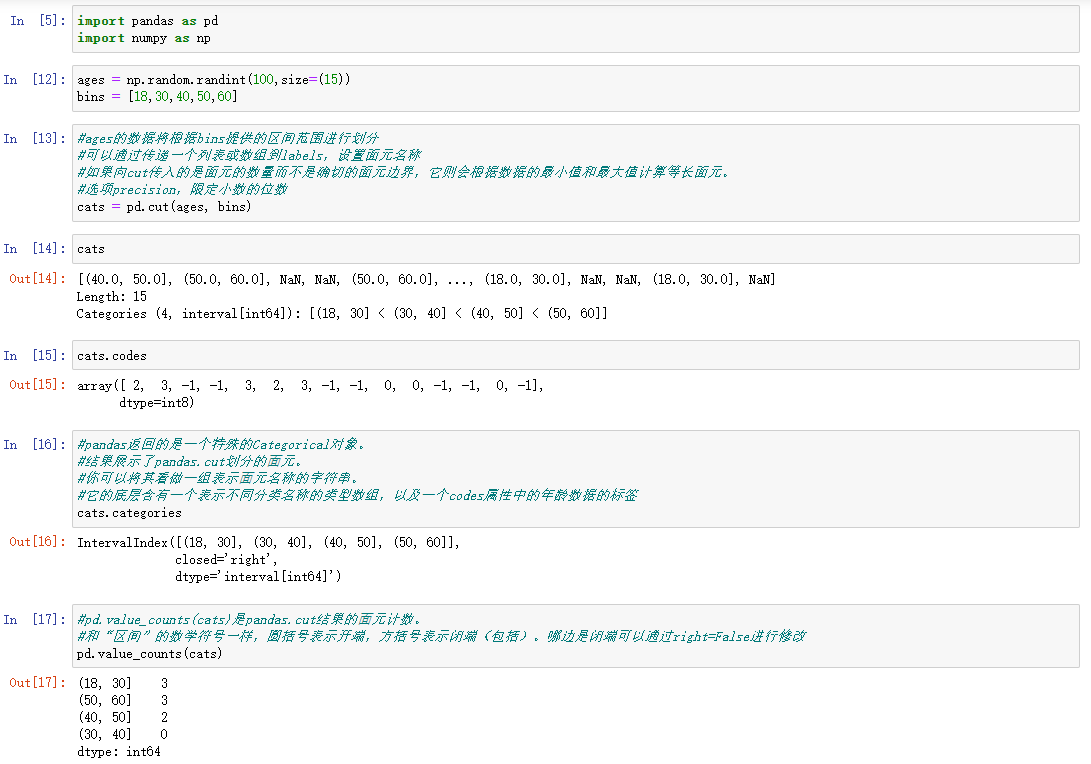
与之相似的是qcut函数,它可以根据样本分位数对数据进行面元划拨。根据数据的分布情况,cut可能无法使各个面元中含有相同数量的数据点。而qcut由于使用的是样本分位数,因此可以得到大小基本相等的面元。
排列和随机采样
利用numpy.random.permutation函数可以轻松实现对Series或DataFrame的列的排列工作(permuting,随机重排序)。
通过需要排列的轴的长度调用permutation,可产生一个表示新顺序的整数数组。
然后就可以在基于iloc的索引操作或take函数中使用该数组了。
如果不想用替换的方式选取随机子集,可以在Series和DataFrame上使用sample方法。
要通过替换的方式产生样本(允许重复选择),可以传递replace=True到sample。
计算指标/哑变量
#将分类变量转换为“哑变量”或“指标矩阵” #如果DataFrame的某一列中含有K个不同的值,则可以派生出一个K列矩阵或DataFrame(其值全为1和0) #pandas有一个get_dummies函数可以实现该功能 #get_dummies的prefix参数可以给指标DataFrame的列加上一个前缀,以便能够和其他数据进行合并 pd.get_dummies()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号