


transformers库本地部署大语言模型
Hugging Face Transformers
Hugging Face Transformers 是一个强大的开源库,它提供了标准化的接口来加载和使用数以万计的预训练模型。
选择模型
为了让大多数个人电脑上顺利运行,选择了一个小规模但功能强大的模型:Qwen/Qwen1.5-0.5B-Chat。这是一个由阿里巴巴达摩院开源的拥有约 5 亿参数的对话模型,它体积小、性能优异,非常适合入门学习和本地部署。
配置环境
执行nvidia-smi,查看右上角。验证显卡驱动已安装最高支持的版本。
nvidia-smi
#在调试时,为了实时观察GPU利用率,一般新开一个命令窗口,执行以下命令,一秒刷新一次。
watch -n 1 nvidia-smi
执行nvcc -V验证cuda
nvcc -V
执行conda --version验证conda版本
conda --version
#列出所有已创建的Conda 环境:
conda env list 或 conda info --envs
#若存在,先删除已存在环境
conda env remove -n conda_transformers_qwen_05b
#创建新环境
conda create -n conda_transformers_qwen_05b python=3.10
#激活环境
conda activate conda_transformers_qwen_05b
根据CUDA版本安装PyTorch:
CUDA 12.1:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
CUDA 12.2:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu122
#验证Torch是否能正确识别GPU
python3 -c "import torch; print('PyTorch版本:', torch.__version__); print('CUDA可用:', torch.cuda.is_available()); print('CUDA版本:', torch.version.cuda); print('GPU设备:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'None'); print('GPU数量:', torch.cuda.device_count());"
#依赖库安装 transformers
pip install transformers -i https://mirrors.aliyun.com/pypi/simple/
#验证transformers库是否安装成功
python3 -c "import transformers; print('transformers导入成功,版本:', transformers.__version__)"
# 由于官网源https://huggingface.co国内访问卡慢。可以使用国内镜像站hf-mirror.com
# 设置环境变量,临时设置(仅当前终端有效)
export HF_ENDPOINT="https://hf-mirror.com"
加载模型测试
CUDA_VISIBLE_DEVICES=4 python3 -c " from transformers import AutoModelForCausalLM, AutoTokenizer import torch import os # 指定模型ID model_id = 'Qwen/Qwen1.5-0.5B-Chat' # 设置设备,优先使用GPU device = 'cuda' if torch.cuda.is_available() else 'cpu' print(f'Using device: {device}') # 加载分词器 tokenizer = AutoTokenizer.from_pretrained(model_id) # 加载模型,并将其移动到指定设备 model = AutoModelForCausalLM.from_pretrained(model_id).to(device) print('模型和分词器加载完成!') # 可选:添加简单的交互测试 print('模型测试:输入一段文本测试生成(输入quit退出)') while True: user_input = input('请输入: ') if user_input.lower() == 'quit': break inputs = tokenizer(user_input, return_tensors='pt').to(device) generated_ids = model.generate(**inputs, max_new_tokens=50) response = tokenizer.decode(generated_ids[0], skip_special_tokens=True) print(f'模型回复: {response}') "
测试截图
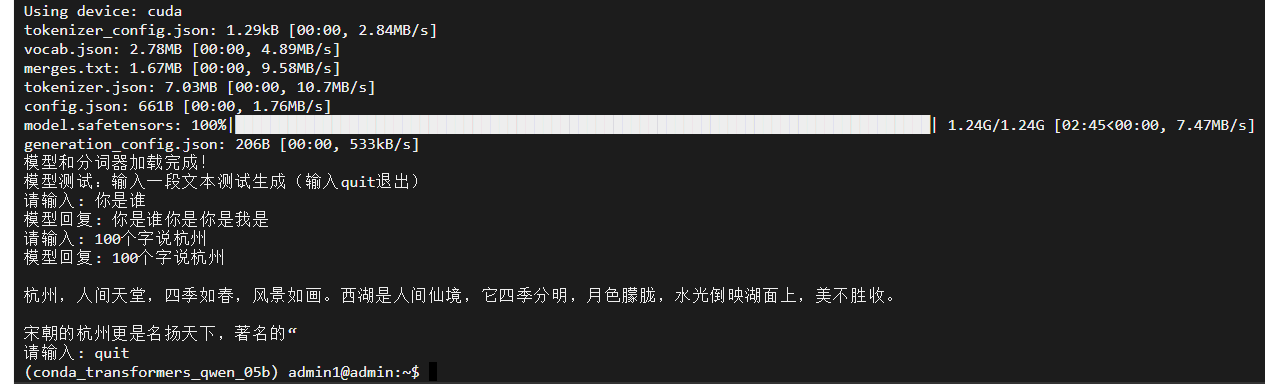
加载模型,并将文本提示转换为模型能够理解的数字 ID(即 Token ID)。
CUDA_VISIBLE_DEVICES=4 python3 -c " from transformers import AutoModelForCausalLM, AutoTokenizer import torch import os # 指定模型ID model_id = 'Qwen/Qwen1.5-0.5B-Chat' # 设置设备,优先使用GPU device = 'cuda' if torch.cuda.is_available() else 'cpu' print(f'Using device: {device}') # 加载分词器 tokenizer = AutoTokenizer.from_pretrained(model_id) # 加载模型,并将其移动到指定设备 model = AutoModelForCausalLM.from_pretrained(model_id).to(device) print('模型和分词器加载完成!') # 准备对话输入 messages = [ {'role': 'system', 'content': 'You are a helpful assistant.'}, {'role': 'user', 'content': '你好,请介绍你自己。'} ] # 使用分词器的模板格式化输入 text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) # 编码输入文本 model_inputs = tokenizer([text], return_tensors='pt').to(device) print('编码后的输入文本:') print(model_inputs) "
输出:
Using device: cuda 模型和分词器加载完成! 编码后的输入文本: {'input_ids': tensor([[151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 108386, 37945, 100157, 107828, 1773, 151645, 198, 151644, 77091, 198]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], device='cuda:0')} (conda_transformers_qwen_05b) admin1@admin:~$
调用模型的 generate() 方法来生成回答。模型会输出一系列 Token ID,这代表了它的回答。
最后,我们需要使用分词器的 decode() 方法,将这些数字 ID 翻译回人类可以阅读的文本。
CUDA_VISIBLE_DEVICES=4 python3 -c " from transformers import AutoModelForCausalLM, AutoTokenizer import torch import os # 指定模型ID model_id = 'Qwen/Qwen1.5-0.5B-Chat' # 设置设备,优先使用GPU device = 'cuda' if torch.cuda.is_available() else 'cpu' print(f'Using device: {device}') # 加载分词器 tokenizer = AutoTokenizer.from_pretrained(model_id) # 加载模型,并将其移动到指定设备 model = AutoModelForCausalLM.from_pretrained(model_id).to(device) print('模型和分词器加载完成!') # 准备对话输入 messages = [ {'role': 'system', 'content': 'You are a helpful assistant.'}, {'role': 'user', 'content': '你好,请介绍你自己。'} ] # 使用分词器的模板格式化输入 text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) # 编码输入文本 model_inputs = tokenizer([text], return_tensors='pt').to(device) print('编码后的输入文本:') print(model_inputs) # 使用模型生成回答 # max_new_tokens 控制了模型最多能生成多少个新的Token generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=512 ) # 将生成的 Token ID 截取掉输入部分 # 这样我们只解码模型新生成的部分 generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] # 解码生成的 Token ID response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] print('\n模型的回答:') print(response) "
输出截图:
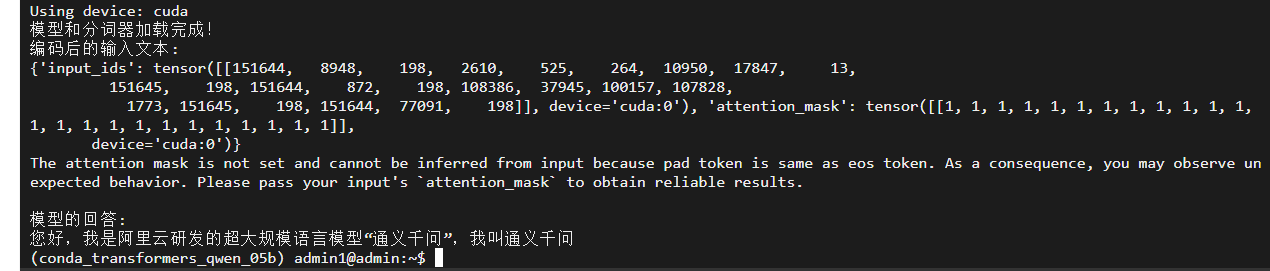

 浙公网安备 33010602011771号
浙公网安备 33010602011771号