

实验四 决策树算法及应用
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/ahgc/machinelearning |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/ahgc/machinelearning/homework/12086 |
| 这个作业的目标 | <理解和实现决策树算法> |
| 学号 | <3180701330> |
实验四 决策树算法及应用
【实验目的】
理解决策树算法原理,掌握决策树算法框架;
理解决策树学习算法的特征选择、树的生成和树的剪枝;
能根据不同的数据类型,选择不同的决策树算法;
针对特定应用场景及数据,能应用决策树算法解决实际问题。
【实验内容】
设计算法实现熵、经验条件熵、信息增益等方法。
实现ID3算法。
熟悉sklearn库中的决策树算法;
针对iris数据集,应用sklearn的决策树算法进行类别预测。
针对iris数据集,利用自编决策树算法进行类别预测。
【实验报告要求】
对照实验内容,撰写实验过程、算法及测试结果;
代码规范化:命名规则、注释;
分析核心算法的复杂度;
查阅文献,讨论ID3、5算法的应用场景;
查询文献,分析决策树剪枝策略。
【实验过程及步骤】
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
from math import log
import pprint
datasets, labels = create_data()
train_data = pd.DataFrame(datasets, columns=labels)
train_data
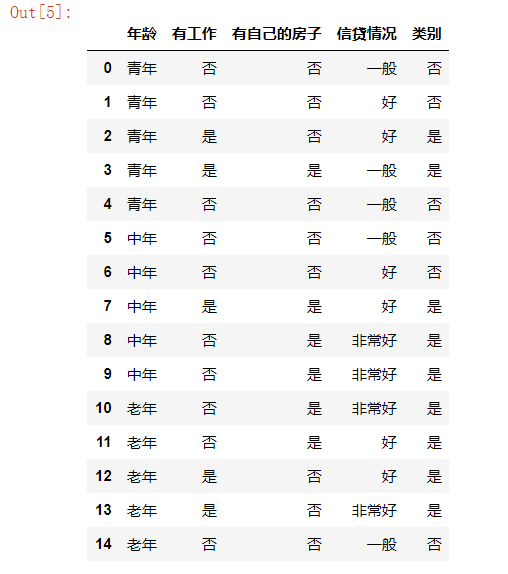
# 熵
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p / data_length) * log(p / data_length, 2)
for p in label_count.values()])
return ent
# def entropy(y):
# """
# Entropy of a label sequence
# """
# hist = np.bincount(y)
# ps = hist / np.sum(hist)
# return -np.sum([p * np.log2(p) for p in ps if p > 0])
# 经验条件熵
def cond_ent(datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum(
[(len(p) / data_length) * calc_ent(p) for p in feature_sets.values()])
return cond_ent
# 信息增益
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(datasets):
count = len(datasets[0]) - 1
ent = calc_ent(datasets)
# ent = entropy(datasets)
best_feature = []
for c in range(count):
c_info_gain = info_gain(ent, cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
print('特征({}) - info_gain - {:.3f}'.format(labels[c], c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return '特征({})的信息增益最大,选择为根节点特征'.format(labels[best_[0]])
info_gain_train(np.array(datasets))

# 定义节点类 二叉树
class Node:
def __init__(self, root=True, label=None, feature_name=None, feature=None):
self.root = root
self.label = label
self.feature_name = feature_name
self.feature = feature
self.tree = {}
self.result = {
'label:': self.label,
'feature': self.feature,
'tree': self.tree
}
def __repr__(self):
return '{}'.format(self.result)
def add_node(self, val, node):
self.tree[val] = node
def predict(self, features):
if self.root is True:
return self.label
return self.tree[features[self.feature]].predict(features)
class DTree:
def __init__(self, epsilon=0.1):
self.epsilon = epsilon
self._tree = {}
# 熵
@staticmethod
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p / data_length) * log(p / data_length, 2)
for p in label_count.values()])
return ent
# 经验条件熵
def cond_ent(self, datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p) / data_length) * self.calc_ent(p)
for p in feature_sets.values()])
return cond_ent
# 信息增益
@staticmethod
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(self, datasets):
count = len(datasets[0]) - 1
ent = self.calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = self.info_gain(ent, self.cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return best_
def train(self, train_data):
"""
input:数据集D(DataFrame格式),特征集A,阈值eta
output:决策树T
"""
_, y_train, features = train_data.iloc[:, :
-1], train_data.iloc[:,
-1], train_data.columns[:
-1]
# 1,若D中实例属于同一类Ck,则T为单节点树,并将类Ck作为结点的类标记,返回T
if len(y_train.value_counts()) == 1:
return Node(root=True, label=y_train.iloc[0])
# 2, 若A为空,则T为单节点树,将D中实例树最大的类Ck作为该节点的类标记,返回T
if len(features) == 0:
return Node(
root=True,
label=y_train.value_counts().sort_values(
ascending=False).index[0])
# 3,计算最大信息增益 同5.1,Ag为信息增益最大的特征
max_feature, max_info_gain = self.info_gain_train(np.array(train_data))
max_feature_name = features[max_feature]
# 4,Ag的信息增益小于阈值eta,则置T为单节点树,并将D中是实例数最大的类Ck作为该节点的类标记,返
if max_info_gain < self.epsilon:
return Node(
root=True,
label=y_train.value_counts().sort_values(
ascending=False).index[0])
# 5,构建Ag子集
node_tree = Node(
root=False, feature_name=max_feature_name, feature=max_feature)
feature_list = train_data[max_feature_name].value_counts().index
for f in feature_list:
sub_train_df = train_data.loc[train_data[max_feature_name] ==
f].drop([max_feature_name], axis=1)
# 6, 递归生成树
sub_tree = self.train(sub_train_df)
node_tree.add_node(f, sub_tree)
# pprint.pprint(node_tree.tree)
return node_tree
def fit(self, train_data):
self._tree = self.train(train_data)
return self._tree
def predict(self, X_test):
return self._tree.predict(X_test)
【实验小结】
决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
决策树会因为样本发生一点点的改动(特别是在节点的末梢),导致树结构的剧烈改变。可以通过集成学习之类的方法解决。

