
介绍一个python神级别黑科技装饰器,能在控制台显示代码运行精确轨迹可点击跳转,可以统计实际代码运行行数。
首先是放代码,主要是接续上一篇,用真实力来解释上一篇的测试对比结论。
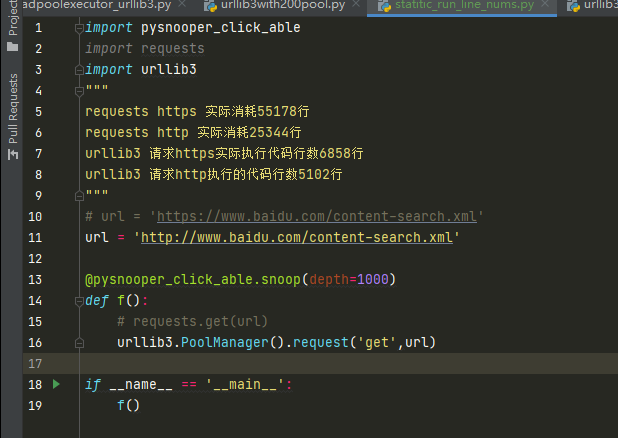
import pysnooper_click_able import requests import urllib3 """ requests https 实际消耗55178行 requests http 实际消耗25344行 urllib3 请求https实际执行代码行数6858行 urllib3 请求http执行的代码行数5102行 """ # url = 'https://www.baidu.com/content-search.xml' url = 'http://www.baidu.com/content-search.xml' @pysnooper_click_able.snoop(depth=1000) def f(): # requests.get(url) urllib3.PoolManager().request('get',url) if __name__ == '__main__': f()
上一篇是
python的各种网络请求库 urllib3 requests aiohttp 分别请求http和https 的效率对比,多线程、gevent、asyncio对比,超大线程池、2n + 1 线程池对比
里面的结论其中的两点包括有
请求http比https快很多
urllib3 比requests快很多。
其实实践测试已近很有说服力了,但有没有一种更牛逼的手段来精确量化出原因呢?
其中之一的办法是打断点一行一行的在pycahrm中跳转一行行数执行了多少行。那么requests请求http大哥断点可能要从周一早晨数到周二晚上,再用requests请求https,从周三早晨一行一行打断点跳转数到周五晚上10点。
一周就这么过了,时间白浪费了,这种统计代码实际运行了多少行的效率怎么行。
下面介绍一种黑科技神级别装饰器来完成这件事情。
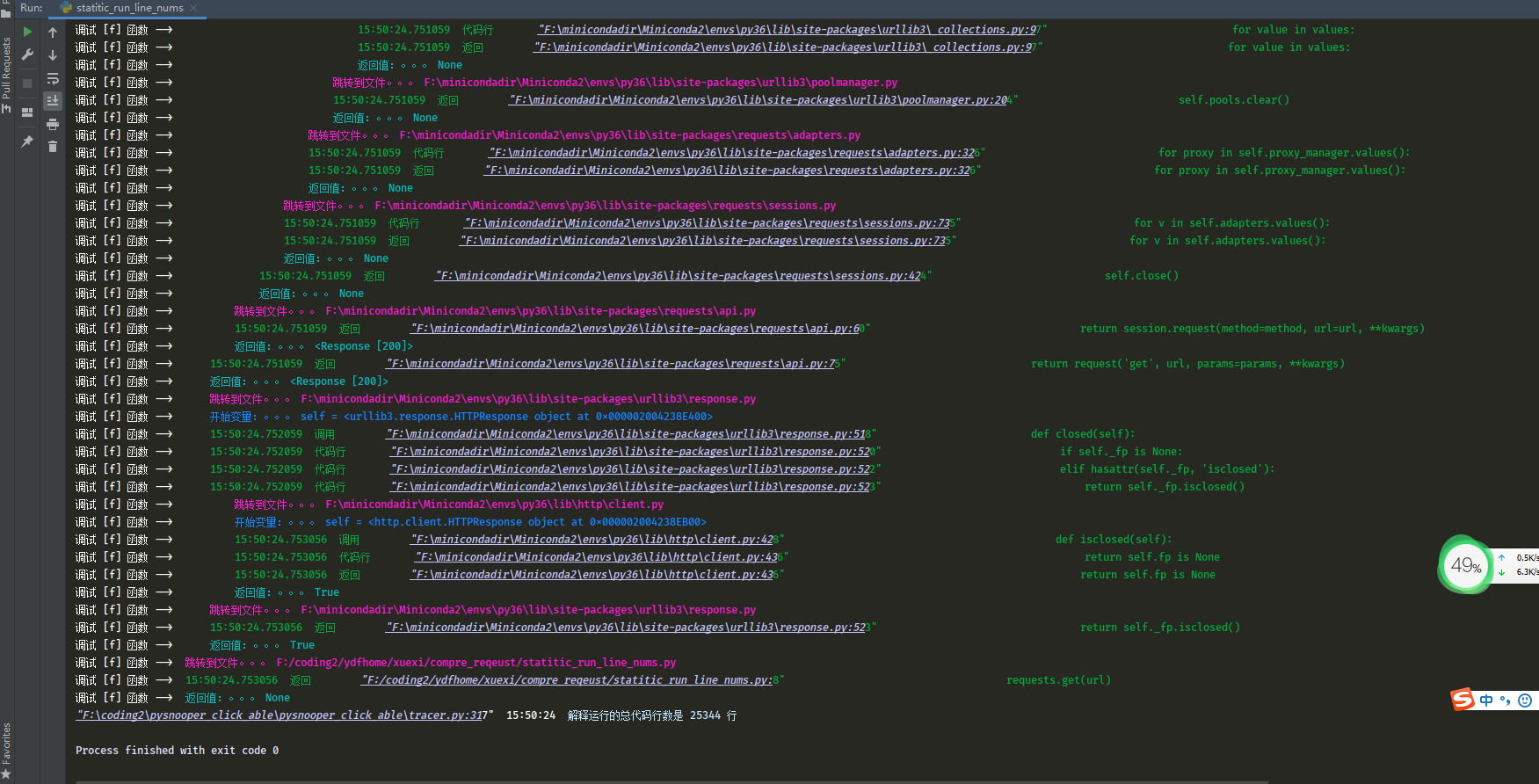
这是requests请求http的代码运行行数,25344行
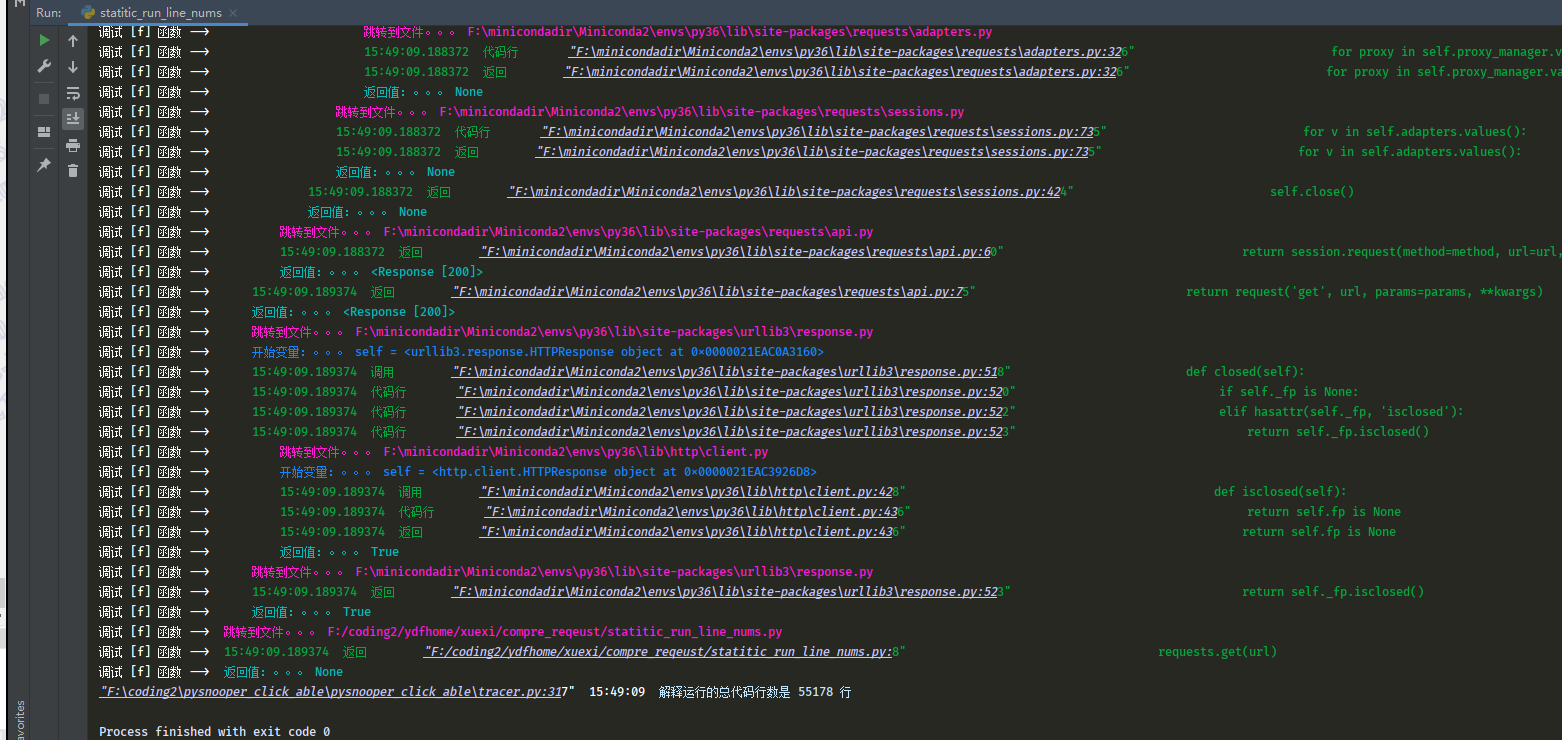
这是requests 请求 http的代码运行行数是55178行
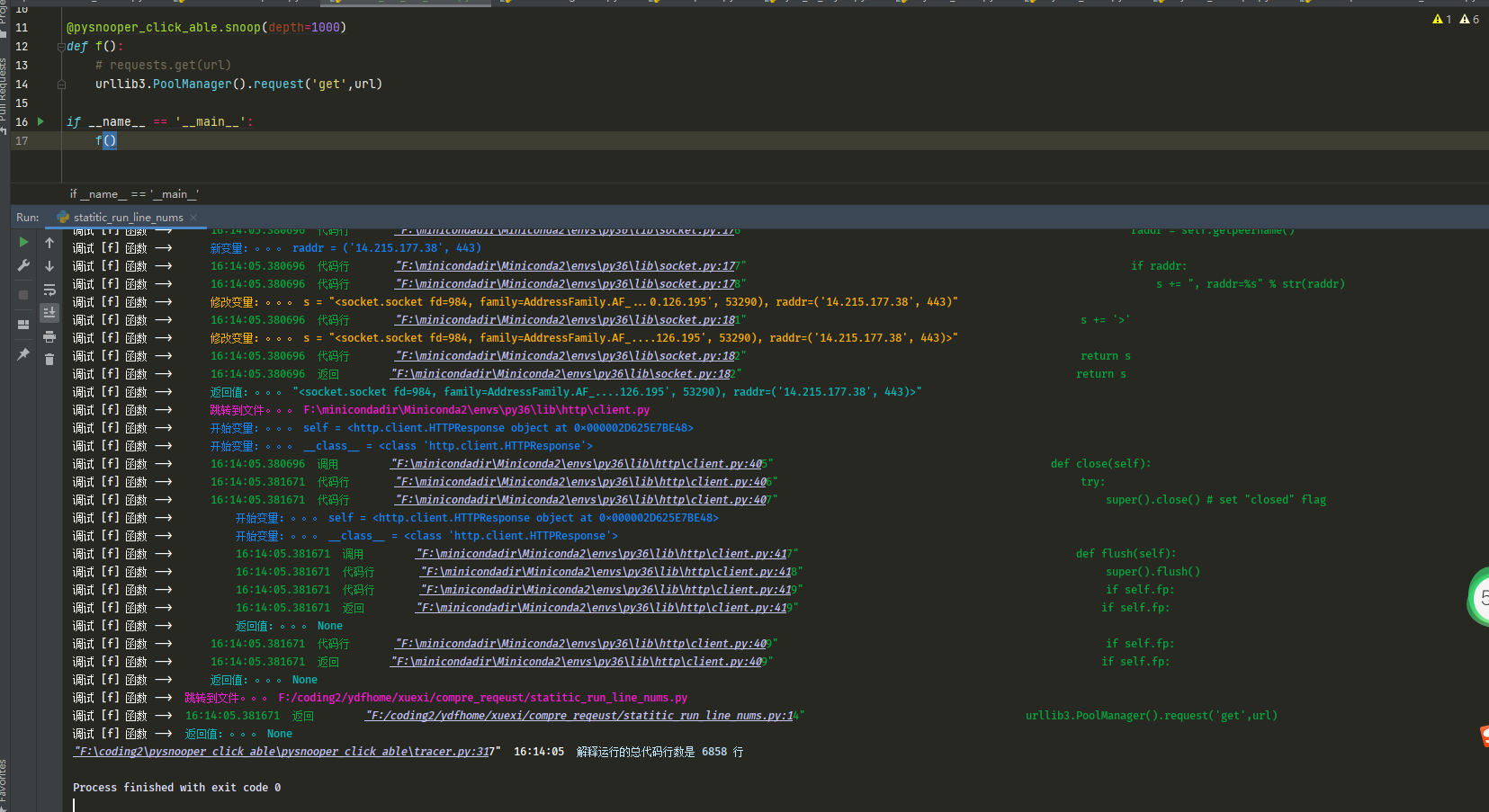
这是urllib3 请求https实际执行代码行数6858行
这是urllib3 请求http执行的代码行数5102行
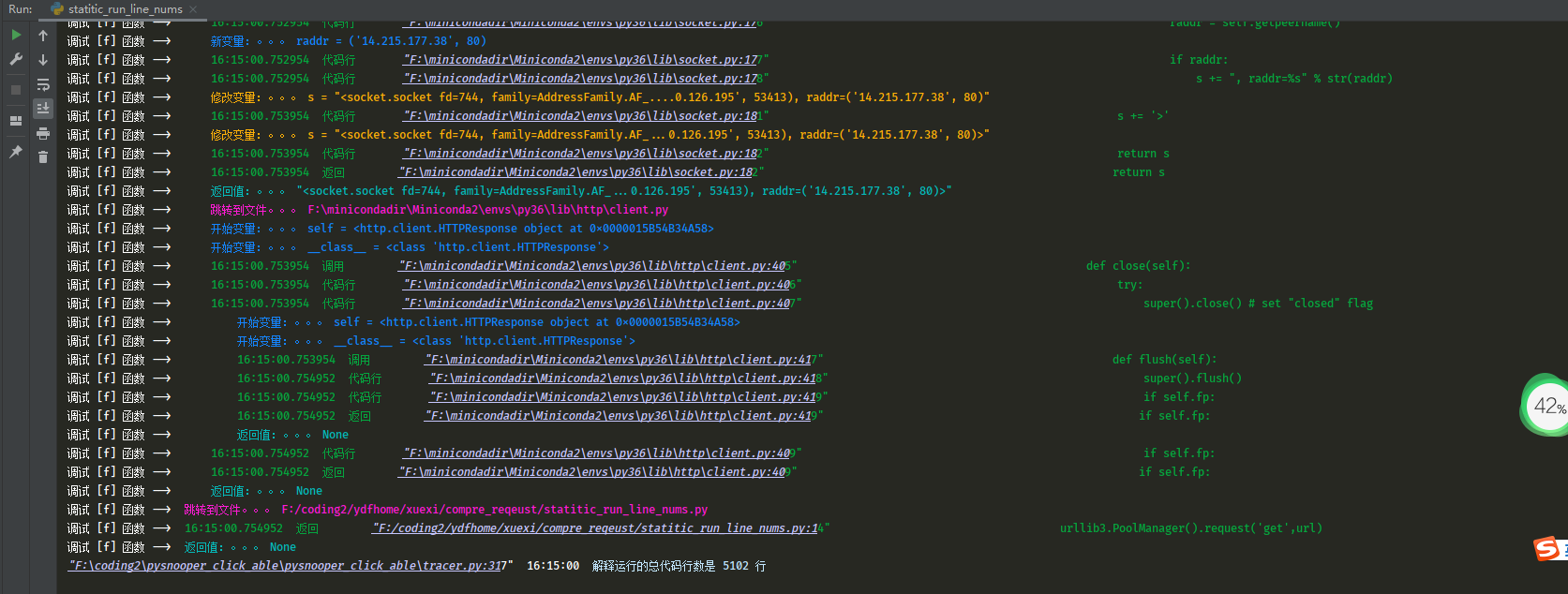
通过这种精确的统计实际运行代码行数的装饰器,可以精确地量化出来,各种测试对比方案的耗时得出的结论和装饰器精确量化手段分析原因,是完全一致的。
这个神级别黑科技装饰器可以统计python真实的代码运行行数,让你对一个函数的性能有精确的量化手段。所以有些吹牛逼的说单进程requests或者aiohttp一秒钟可以请求完成100万次url,完全是吹牛不打草稿,脱离现实3个数量级以上了。
这个测试很容易做,在自己本机安装个nginx,让代码请求nginx就能测试。
用脑袋想想1秒钟执行1百万次requests请求https什么概念,一秒钟执行 五百亿行python代码了,别说python做不到,java都完全不可能。
只有使用这种神级别黑科技装饰器才可以做到胸有成竹。推荐安装 pip install pysnooper_click_able
这个包是精确统计实际运行代码流程过程中的代码行数,不是open(file).readlines() 基于一个静态文本文件的统计,实现难度大了100倍不止。
反对极端面向过程编程思维方式,喜欢面向对象和设计模式的解读,喜欢对比极端面向过程编程和oop编程消耗代码代码行数的区别和原因。致力于使用oop和36种设计模式写出最高可复用的框架级代码和使用最少的代码行数完成任务,致力于使用oop和设计模式来使部分代码减少90%行,使绝大部分py文件最低减少50%-80%行的写法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号