with open('./files/data3.txt',encoding='utf-8',mode='r') as f:
lines=f.readlines()
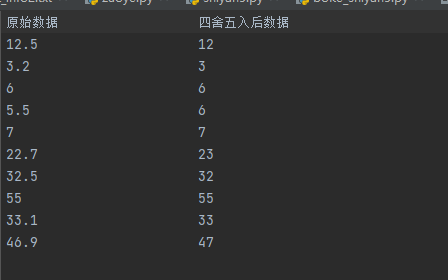
result=['四舍五入后数据']
for i in range(len(lines)):
lines[i]=lines[i].strip('\n')
for i in range(1,len(lines)):
result.append(str(round(float(lines[i]))))
print(f'原始数据\n{lines[1:]}')
print(f'四舍五入后数据\n{result[1:]}')
tplt = "{:<20}\t{:<20}\n"
with open('./files/data3_processed.txt',encoding='utf-8',mode='w') as f:
for i in range(len(result)):
f.write(tplt.format(lines[i],result[i]))
with open('./files/data4.txt',encoding='utf-8',mode='r') as f:
lines=f.readlines()
xinxi=[]
for i in range(1,len(lines)):
shuzu=lines[i].strip('\n').split('\t')
xinxi.append({'xuehao':shuzu[0],'xingming':shuzu[1],'zhuanye':shuzu[2],'fenshu':shuzu[3]})
for i in range(len(xinxi)):
for j in range(i,len(xinxi)):
if xinxi[i]['zhuanye']>xinxi[j]['zhuanye']:
temp=xinxi[i]
xinxi[i]=xinxi[j]
xinxi[j]=temp
elif xinxi[i]['zhuanye']==xinxi[j]['zhuanye']:
if xinxi[i]['fenshu']<xinxi[j]['fenshu']:
temp = xinxi[i]
xinxi[i] = xinxi[j]
xinxi[j] = temp
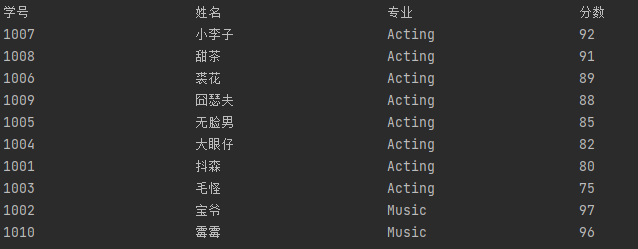
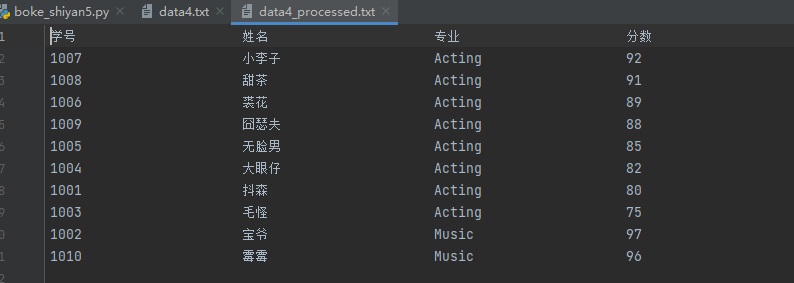
tplt = "{:<20}\t{:<20}\t{:<20}\t{:<20}\n"
with open('./files/data4_processed.txt',encoding='utf-8',mode='w') as f:
f.write(tplt.format('学号','姓名','专业','分数'))
print(tplt.format('学号','姓名','专业','分数'),end='')
for value in xinxi:
f.write(tplt.format(value['xuehao'],value['xingming'],value['zhuanye'],value['fenshu']))
print(tplt.format(value['xuehao'],value['xingming'],value['zhuanye'],value['fenshu']),end='')
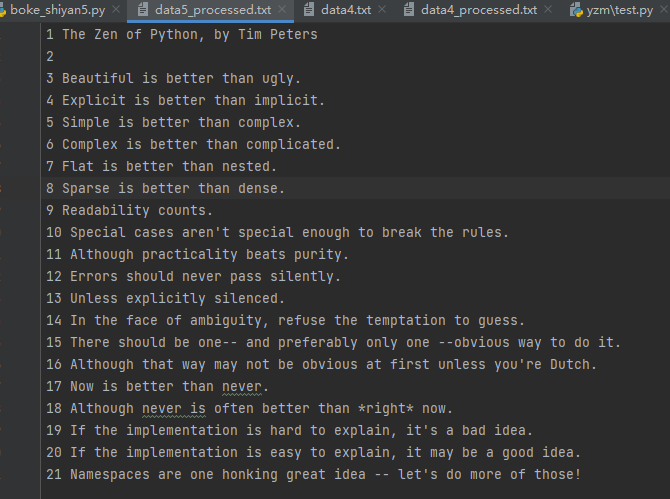
with open('./files/data5.txt',encoding='utf-8',mode='r') as f:
lines=f.readlines()
print('行数: ',len(lines))
word=0
blank=0
zifu=0
with open('./files/data5_processed.txt',encoding='utf-8',mode='w') as f:
for i in range(len(lines)):
tplt="{} {}"
f.write(tplt.format(str(i+1),lines[i]))
zifu+=len(lines[i])
words=lines[i].split(' ')
blank+=len(words)-1
word+=len(words)
print('单词数: ',word)
print('空格数: ',blank)
print('字符数: ',zifu)