
自学Zabbix3.12.6-动作Action-Escalations配置
3.12.6 自学Zabbix3.12.6-动作Action-Escalations配置
1. 概述
Escalation 的意思是“增大,扩大”,在Zabbix中,它指的意思是一个报警在一定条件下,会执行一些额外 的操作,比个比方,一台服务器磁盘满了,可能马上需要通知的是一线的运维工程师。如果6小时后都没人处理,这个故障且还没恢复,那么可能就要汇报给经理了。 或者,PHP进程挂了,可能首先是重启PHP进程,那么如果过了一段时间这个故障还没有恢复(即PHP进程没有重启成功),那么就要通知攻城师来进行恢复了。 这是一个报警扩散的过程,即Escalation 。
Zabbix中,支持的Escalation有以下几种:
-
发生问题后,第一时间通知用户。
-
在解决问题前,每隔一段时间就向用户报警。
-
延迟报警。
-
报警可以升级,发送给更多的用户。
-
Remote command可以在时间发生后马上执行,也可以在一定时间没有解决后才执行。
-
可以向用户发送恢复通知。
可以定义一个“Escalation Step”,意为“扩散步骤”,定义何时扩散报警,以及如何扩散。
每一个步骤可以定义一个Action和持续时间。步骤要在报警后马上发出,步骤个数没有限制,Zabbix只会从第一个开始逐个执行。
Escalation是一个比较复杂的机制,特别是跟其他东西结合起来后,下面看一些常见情况:
-
出问题的Host在发出第一个报警后进入了Maintainence状态:这个Action剩余的Escalation Step都会被执行。Maintainence状态不会停止Operation,只会对Action有关系简单的说,一旦这个Action被执行,那么其中的每一步都会执行。
-
在Time period中定义的时间在发出第一个报警后就结束了:同(A)中的情形,Time period也只会影响Action执行与否,而不会影响Action中的Operation执行与否。
-
在Maintainence状态时发生了问题,并且在Maintainence状态结束后依然没有恢复:所有Escalation Step都是从Host(或者其他)结束Maintainence状态后开始。
-
当Host在no-data Maintainence状态时发生问题,在结束no-date Maintainence状态时,这个问题还没有恢复:Trigger 的触发,一定是先于Escalation Step的开始。
-
不同的Escalation Step非常接近相互有重叠的部分:没一个Escalation都会接替之前的Escalation,但是由于步骤(A)是在问题发生后马上执行的,所以“之前的Escalation”至少会执行一个动作。这些行为跟Evnet 和 Action相关。
-
在Escalation执行过程中,Action被禁用了:正在发送过程中的信息和之后的那一条信息会被发送。其中后面的那条信息会在发送的信息之前加上“NOTE:Escalation cancelled:action‘<Action name>’ disabled”。这样,用户就会知道Action已经被禁用了,之后也不会受到关于这个Action的消息了。
2. 几个示例
示例1:
要求每隔30分钟向“MySQL Administration”的User group发送一次报警,一共发送5次。
-
在Action的Operation标签中,将“Default operation step duration”(默认操作时间间隔)设置为1800秒,即要求中的30分钟。
-
在Steps的地方设置为“From 1 to 5”,表示Escalation Step的第一步到第五步都是执行这个操作。
-
选择“MySQL Administration”组作为发送报警的收件人。
通过这样的设置,假设Action是0点0分触发的,那么在0点30分,1点,1:30,2:00 都会将报警发送给“MySQL Administration”用户组中的所有用户,当然,如果在这个过程中,Trigger 恢复了,那么就会打断这些事件。
示例2:
如果示例1中的问题一直没有解决,我们希望吧这个问题通知到更加资深的DBA,可以进行下面的设置。
-
在Operation标签中,将默认时间设置为36000秒,即10个小时。
-
将escalation steps设置为“From 2 to 2”,意思就是只在第(2)步中执行。
在问题发生后,如果10个小时还没恢复,那么这个问题就会通知到资深DBA,可以在发送消息的内容中加上类似“这个问题已经10个小时没有处理”之类的话,提醒收到告警的工程师去解决。
示例3:
当出现问题时,先通知MySQL Administration,如果问题持续10个小时,将这个问题发送给DBA经理,如果还解决不了,会尝试重启数据库。 如果依然解决不了,那么只能邮件通知用户,最后使用IPMI命令,重启MySQL服务器。

示例4:
最后看一个自定义Duration的例子,先看是如何设置Action的。
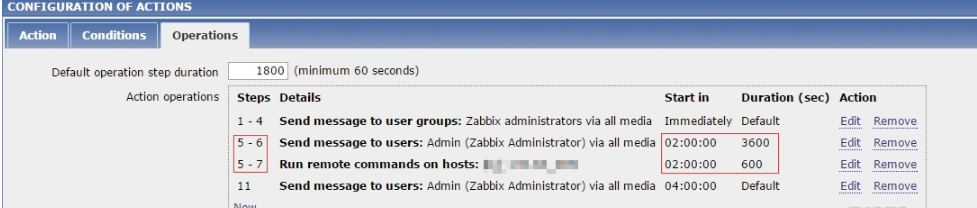
假设问题是在00:00发生的,那么它的执行顺序如下。
-
在00:00、00:30、01:00、01:30 会向Zabbix administrators用户组发送邮件,这是由于我们设置了默认的时间间隔是1800秒,即30分钟。
-
在02:00 和 02:10向Admin发送邮件。
-
在02:00 、02:10 和 02:20 执行远程命令。
-
在04:00 向Admin 发送邮件。
这里有几个理解起来比较麻烦的地方,一个是在图中,只有02:00 和 02:10 时才会向 Admin发送邮件,而不会在03:00,这是因为在图中 5-6和5-7都设置了Operation,那么5-7中设置的600秒就会覆盖5-6中设置的3600秒。在条目3中,因为设置的600秒生效,所以每隔10分钟向Admin发送一次邮件。 在条目4中,由于经过了8、9、10、11则这4个Step,所以是默认的30分钟的4倍,即2个小时,到04:00,向Admin发送报警。
作者:CARLOS_CHIANG
出处:http://www.cnblogs.com/yaoyaojcy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
posted on 2018-01-09 16:27 CARLOS_KONG 阅读(3980) 评论(0) 编辑 收藏 举报

