
数据采集与融合技术实验4
作业①
·要求:熟练掌握 scrapy 中Item、Pipeline 数据的序列化输出方法,使用Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
·候选网站:http://www.dangdang.com/
·关键词:学生自由选择
| id | title | author | publisher | data | price | detail |
|---|---|---|---|---|---|---|
| 1 | Python算法图解 | 何韬 | 清华大学出版社 | 2021-04-01 | ¥34.50 | 用到算法。数据结构是算法的基础,数组、字典、堆、栈、链表... |
1、数据解析

每本书的数据存放在li标签当中
2、开启piplines通道

3、item创建对象
`
class DangdangItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
publisher = scrapy.Field()
date = scrapy.Field()
price = scrapy.Field()
detail = scrapy.Field()
datalist = scrapy.Field()
`
4、创建数据库
`
def init_db(dbpath):
try:
sql = '''
create table dangdangbooks
(
bTitle varchar(512) primary key,
bAuthor varchar(256),
bPublisher varchar(256),
bDate varchar(32),
bPrice varchar(16),
bDetail text
);
'''
# sql = 'drop table dangdangbooks;'
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
`
5、解析数据并存储
`
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first()
publisher = li.xpath(
"./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
`
6、结果展示
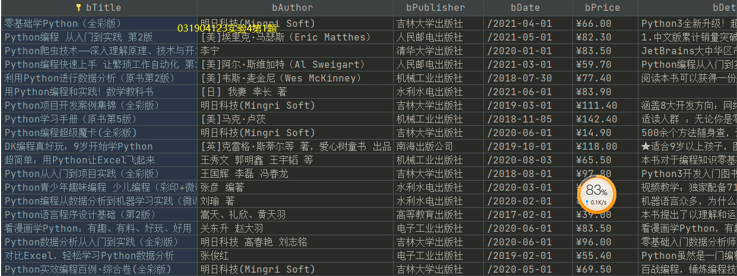
7、心得体会
通过此次作业我对scrapy框架中利用item与pipeline存储数据有了更大的了解,并且可以更为熟练地运用xpath进行数据解析,并且链接数据库进行存储
第一题链接
作业②
1.要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
2.候选网站:招商银行网:http://fx.cmbchina.com/hq/
3.输出信息:MySQL数据库存储和输出格式

1、网页查看
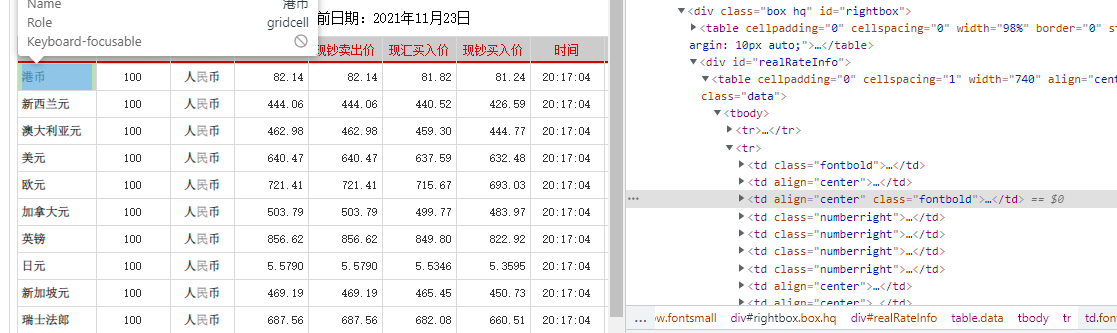
每行信息存在td标签里
2、修改seting文件

3、item创建对象

4、爬虫文件标签解析
`
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
trs = selector.xpath('//*[@id="realRateInfo"]/table/tr')
for tr in trs[1:]:
Currency = tr.xpath("./td[1]/text()").extract_first()
TSP = tr.xpath("./td[4]/text()").extract_first()
CSP = tr.xpath("./td[5]/text()").extract_first()
TBP = tr.xpath("./td[6]/text()").extract_first()
CBP = tr.xpath("./td[7]/text()").extract_first()
Time = tr.xpath("./td[8]/text()").extract_first()
`
5、数据库创建并保存
`
def init_db(dbpath):
try:
sql = '''
create table bankinfo
(
Currency text primary key,
TSP varchar(20),
CSP varchar(20),
TBP varchar(20),
CBP varchar(20),
Time text
);
'''
# sql = 'drop table dangdangbooks;'
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
`
6、结果展示
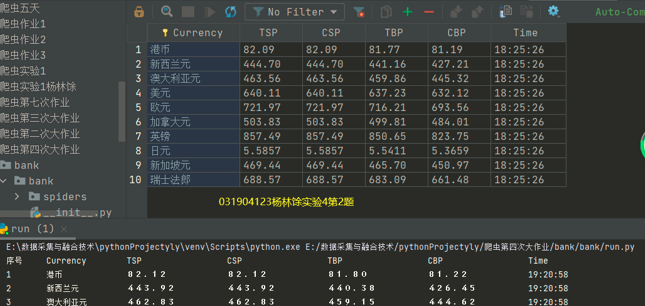
7、心得体会
通过此次实验我熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。在这个过程中虽然遇到一些困难,但都通过查阅资料得到解决了
第二题链接
作业3
1.要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。 2.候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board 3.输出信息:MySQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头
实验过程
1、检查网页结构
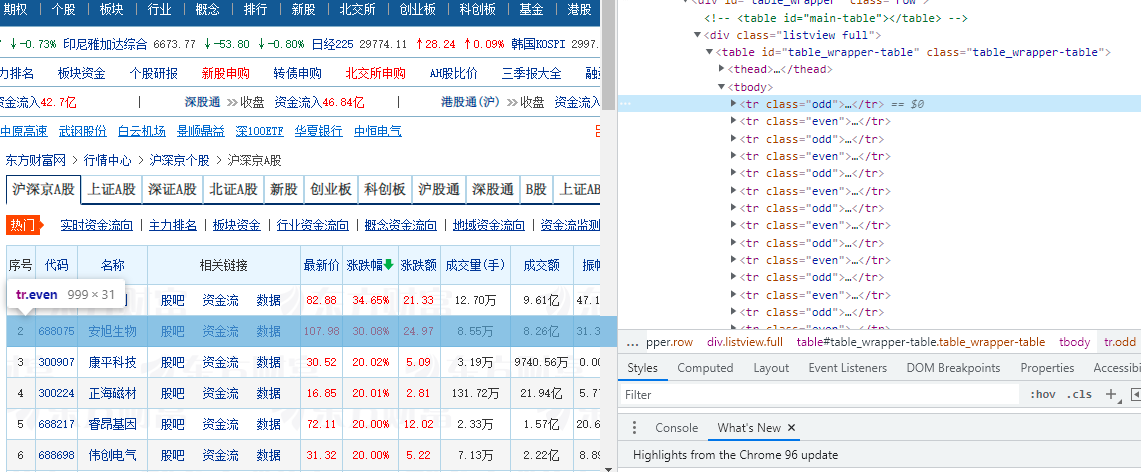
2、解析页面数据
`
for tr in trs:
id = tr.find_element(By.XPATH,'.//td[1]').text
num = tr.find_element(By.XPATH,'.//td[2]/a').text
name = tr.find_element(By.XPATH,'.//td[3]/a').text
new = tr.find_element(By.XPATH,'.//td[5]/span').text
up = tr.find_element(By.XPATH,'.//td[6]/span').text
upprice = tr.find_element(By.XPATH,'.//td[7]/span').text
com = tr.find_element(By.XPATH,'.//td[8]').text
comprice = tr.find_element(By.XPATH,'.//td[9]').text
f = tr.find_element(By.XPATH,'.//td[10]').text
max = tr.find_element(By.XPATH,'.//td[11]/span').text
min = tr.find_element(By.XPATH,'.//td[12]/span').text
today = tr.find_element(By.XPATH,'.//td[13]/span').text
yes = tr.find_element(By.XPATH,'.//td[14]').text
`
3、寻找“沪深A股”、“上证A股”、“深证A股”3个板块并寻找跳转链接
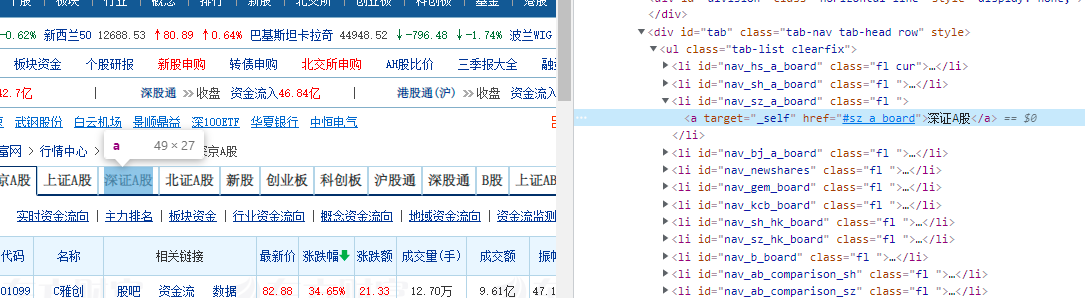
4、编写代码使得驱动程序跳转页面
`
lis = driver.find_elements(By.XPATH,'//div[@id="tab"]/ul/li')
for i in range(3):
time.sleep(3)
lis = driver.find_elements(By.XPATH, '//div[@id="tab"]/ul/li')
TZ = lis[i].find_element(By.XPATH,'.//a')
print(TZ.text)
text = TZ.text
TZ.click()
`
5、结果展示
数据库截图
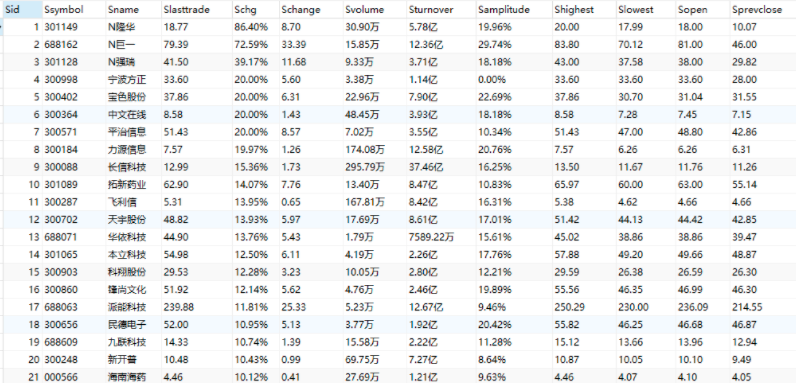
6、心得体会
通过此次实验我熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取,实现了驱动程序自动操作网页并爬取网页,存取到数据库的过程。

