
数据采集与融合技术实验三
作业1
·要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
·输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
{一}单线程爬取
完整代码
(1)解析网页,找到对应翻页信息

(2)构建函数,获取网页源代码
`
def getPage_Text(url): #构造爬取网页信息的函数
try:
headers = {
"user-agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
}
response = urllib.request.Request(url=url,headers=headers)
page = urllib.request.urlopen(response)
page_text = page.read()
text = UnicodeDammit(page_text, ["utf-8", "gbk"])
data=text.unicode_markup
return data
except Exception as err:
print(err)
`
(3)找到页面跳转链接
`
def pagelinks(html_text):
soup = BeautifulSoup(html_text, 'html.parser')
link = soup.select('a') # 找到页面链接
p_link = re.compile('href="(.*?)"')
link = str(link)
links = re.findall(p_link, link)
`
(4)保存图片至本地
`
def save(detail_url,path):
i=1
for img in detail_url:
img_url = img
new_path = path + str(i) + ".jpg"
urllib.request.urlretrieve(img_url, new_path) #定义存取本地图片路径
i += 1
`
(5)运行结果

{二}多线程爬取
完整代码
(1)对比单线程要创建线程
`
response=urllib.request.Request(start_url,headers=headers)
#requests方法爬取淘宝网页
page=urllib.request.urlopen(response)
page_text=page.read()
#获取网页文本内容
DT=UnicodeDammit(page_text,["utf-8","gbk"])
data=DT.unicode_markup
pic_urls = parseDATA(data,num) # 得到图片链接pic_url的列表
for pic_url in pic_urls: # 线程池下载图片
try:
count = count + 1
T = threading.Thread(target=download, args=(pic_url, count))
T.setDaemon(False);T.start();threads.append(T)
except Exception as err:
print(err)
`
(2)运行结果
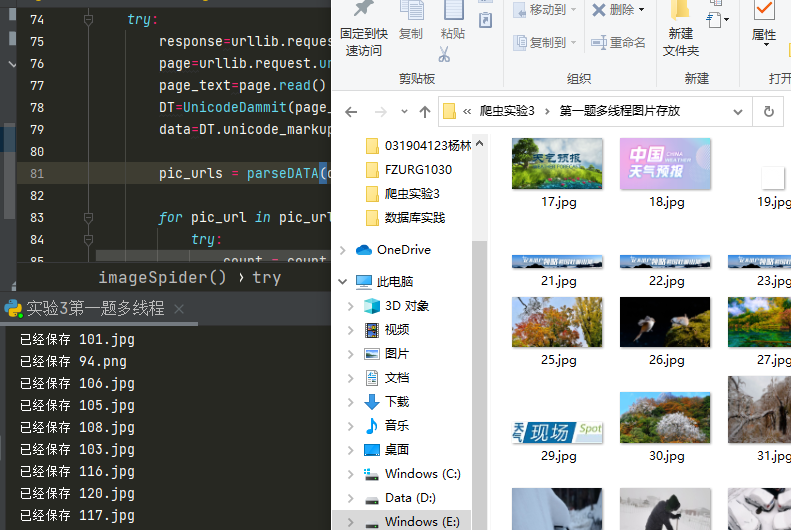
心得体会:
理解了多线程爬虫与单线程爬虫的异同,对数据爬取的方法更加掌握
作业2
·要求:使用scrapy框架复现作业1
·输出信息:同作业1
完整代码
(1)实现思路
将实验1中的url以及界面跳转的工作交给spider完成,让piplines进行信息输出以及图片下载
items.py部分
`
import scrapy
class T3(scrapy.Item):
picture_list = scrapy.Field()
n = scrapy.Field()
`
pipelines.py部分
`
def save_file(img_url_list,path):
i=1
for img in img_url_list:
img_url = img
new_path = path + str(i) + ".jpg"
urllib.request.urlretrieve(img_url, new_path) #定义存取本地图片路径
i += 1
class T3PIP:
def process_item(self, item, spider):
tply = "{0:4}\t{1:30}"
print(tply.format("序号", "图片链接", chr(12288)))
for i in range(123):
print(tply.format(i+1,item['picture_list'][i] , chr(12288)))
path = r"E:/爬虫实验3/scrapy/weatherPicture/pictures"
save_file(item['picture_list'], path)
return item
`
编写setting.py文件
`
ITEM_PIPELINES = {
'T3.pipelines.T3PIP': 300,
}
`
编写运行爬虫的程序run.py
`
from scrapy import cmdline
cmdline.execute("scrapy crawl exe2 -s LOG_ENABLED=False".split())
`
(2)输出与结果展示
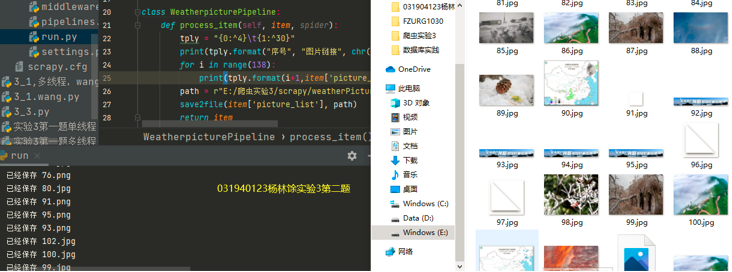
心得体会:
学会了运用scrapy框架进行数据的爬取与运用,为以后的学习奠定了基础
作业3
•要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
候选网站: https://movie.douban.com/top250。
•输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 帝姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xjk/.jpg |
| 2 |
gitee链接
完整代码
(1)思路分析
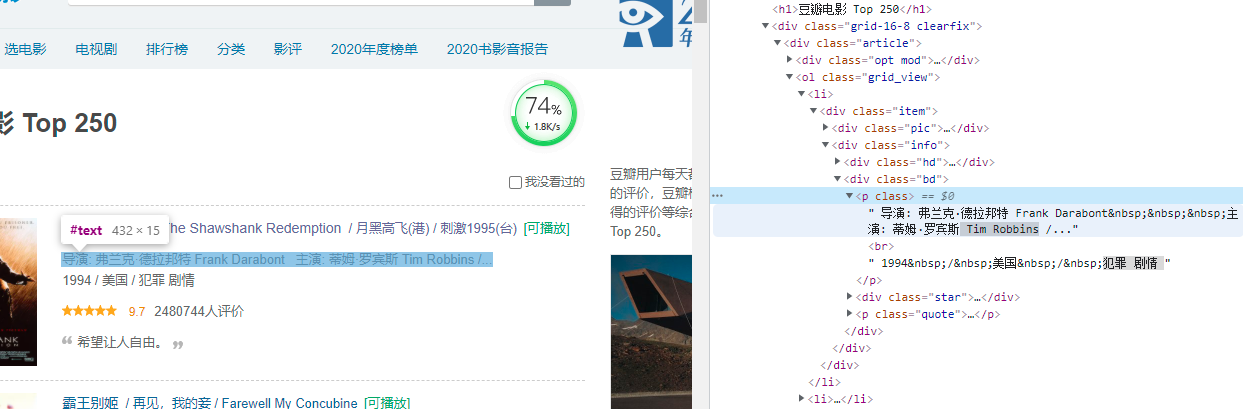
发现导演和演员的位置连在一起,所以用XPATH语句将这两个字段切开
1.修改settings部分
`
BOT_NAME = 'doubanTOP250'
SPIDER_MODULES = ['doubanTOP250.spiders']
NEWSPIDER_MODULE = 'doubanTOP250.spiders'
LOG_LEVEL = 'ERROR'
`
2.编写items文件,爬取6个属性
`
calss doubaiItem(scrapy.Item):
name = scrapy.Field() # 电影名称
director = scrapy.Field() # 导演
actor = scrapy.Field() # 演员
info = scrapy.Field() # 简介
rank = scrapy.Field() # 评分
page = scrapy.Field() # 电影封面
movies = scrapy.Field()
`
3.使用xPath解析页面
`
movies = response.xpath('//div[@class="info"]')
for movie in movies:
name = movie.xpath('div[@class="hd"]/a/span/text()').extract_first() # 名称
director_actors = movie.xpath('div[@class="bd"]/p[1]/text()[1]').extract_first().strip().replace('\xa0', '') # 导演和主演
# 分离导演和主演
director = re.findall(p_director,str(director_actors))[0] # 导演
actor = re.findall(p_actor, str(director_actors)) # 主演
info = movie.xpath('div[@class="bd"]/p[@class="quote"]/span/text()[1]').extract_first() # 简介
if info != None: # 简介可能为空
state = info.replace("。", "") # 去掉句号
else:
state= " "
score = movie.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract_first() # 评分
movielist.append([name,director,actor,info,score,page[i]])
i += 1
item['movies'] = movielist
4.编写pipelines文件
`
def openDB(self):
self.con = sqlite3.connect("M.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table movies(rank varchar(10),name
varchar(10),director varchar(10),actor varchar(10),state varchar(20),score
varchar(10),surface varchar(50))")
except:
self.cursor.execute("delete from movies")
def closeDB(self):
self.con.commit()
self.con.close()
结果展示
数据库中查看

保存本地查看
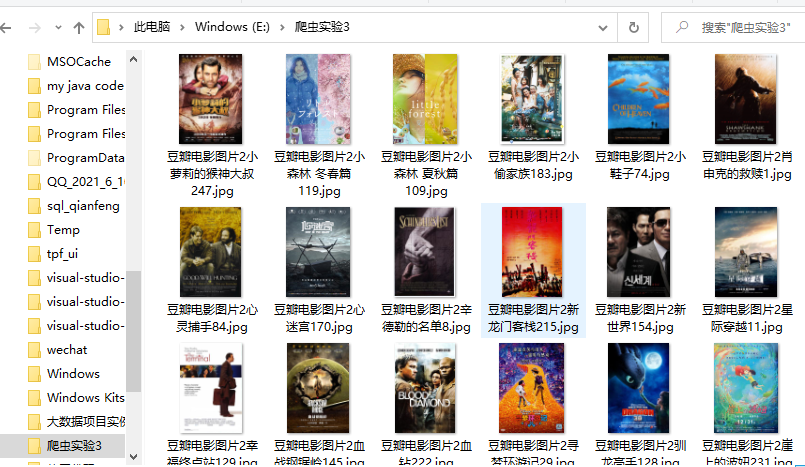
心得体会:
对scrapy框架的运用更加了解,对页面跳转爬取的掌握与运用更加熟练
`
`

