
python网络爬虫——爬取哔哩哔哩网站的番剧排行榜和其中各番剧详情页信息
(一)、选题的背景
因为我是个动漫爱好者,所以很喜欢看动漫剧,又叫做番剧,所以我都特别关注哔哩哔哩的动漫番剧排行榜的各番剧排名,评分,观看次数等等。
但是我不知道这几个数量值有什么关联。
所以我选择爬取bilibili的番剧综合排行榜的排名,番剧名,番剧链接,播放量,收藏量,评分,介绍。
并分析其中的排名,播放量,收藏量,评分几个数量之间是否有明显的联系。
(二)、主题式网络爬虫设计方案
1.主题式网络爬虫名称
python爬取哔哩哔哩网站的番剧排行榜和其中各番剧详情页信息
2.主题式网络爬虫爬取的内容与数据特征分析
番剧综合排行榜的排名,番剧名,番剧链接,介绍为文本类型。
播放量,收藏量,评分为数值类型。
3.主题式网络爬虫设计方案概述
先设计好爬取代码,然后处理好数据后将其记录在表格和数据表中,保存并进行数据分析。
(三)、主题页面的结构特征分析
1.主题页面的结构与特征分析
我的目的是要爬取bilibili的番剧综合排行榜的排名,番剧名,番剧链接,播放量,收藏量,评分,介绍。
而排行榜网页中只包含:排名,番剧名,番剧链接,播放量,收藏量。

若想要知道它们的评分与番剧介绍需要进入详情页面查找。
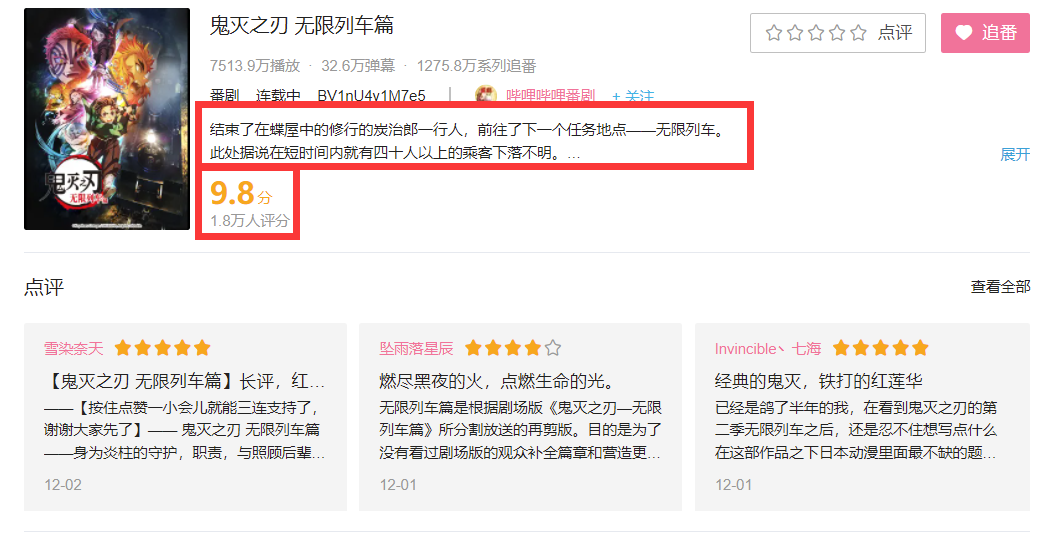
2.Htmls 页面解析
排行榜里的各条信息都包含在这个li标签中

详情页面中的评分和介绍都包含在这个div标签中
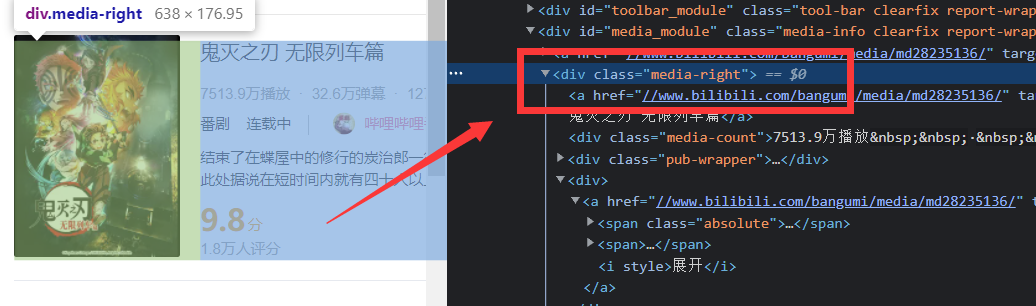
3.节点(标签)查找方法与遍历方法
经过分析,我打算先从第一个页面(排行榜页面)查找出每条符合条件的li标签,再逐个分析,从中提取想要的信息,比如说番剧名称,播放量,收藏数,番剧链接。
再通过爬取上一步提取的每条番剧链接,从第二个页面查找出每条符合条件的div标签,再逐个分析,从中提取想要的信息。
(四)、网络爬虫程序设计
数据爬取与
首先开始编写获取网页信息的函数(因为我们需要用到该代码两次,所以写为函数比较方便):
1 def get(url):#获取网页信息函数 2 head = { 3 "User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome / 96.0.4664.110 Safari / 537.36" 4 } 5 #模拟浏览器头部信息 6 request = urllib.request.Request(url, headers=head) 7 #携带着这个包含着我的设备型号的头部信息去访问这个网址 8 html = "" 9 #用字符串对它进行存储 10 time.sleep(0.1) 11 #添加延时,防止错误 12 13 try: 14 #处理可能会发生的错误,比如说网络问题等,并输出错误代码,如404 15 response = urllib.request.urlopen(request) 16 html = response.read().decode("utf-8") 17 18 except urllib.error.URLError as e: 19 20 if hasattr(e, "code"): 21 print(e.code) 22 23 if hasattr(e, "reason"): 24 print(e.reason) 25 26 soup = BeautifulSoup(html,"html.parser") 27 #解析数据 28 return soup
测试输出获取的信息,分析信息内容得知该网页可以用这种方式爬取我们想要的数据。
通过网页检查工具得知,排名里的番剧信息都分别包含于一个class="rank-item"的标签li之中,所以
1 for item1 in soup.find_all('li',class_="rank-item"): 2 # 查找符合条件的li标签,逐一分析即遍历(在输出的标签li列表中,逐一进行查找标签li中我们需要的信息,并保存于新的列表datalist中)
测试输出了一条符合条件的li标签,分析其中的内容:得到想要的信息位置特征。
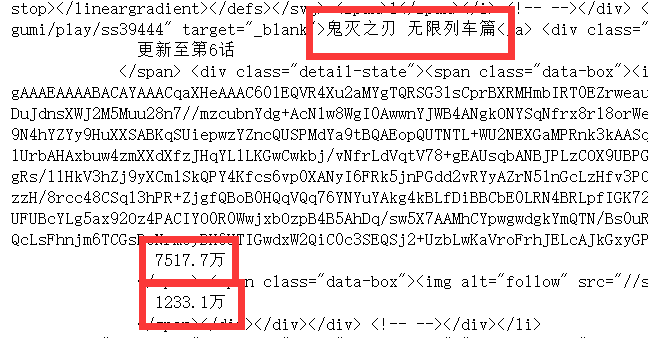
比如说包含番剧链接信息的文本的前面有“<a href="文本,后面有"" target"文本
用re库正则表达式提取想要的信息,例如:
1 f_link = re.compile(r'(.*?)" target') 2 # 查找番剧链接 3 f_title = re.compile(r'<a class="title".*target="_blank">(.*?)</a>') 4 # 查找番剧标题 5 f_watchtext = re.compile(r'<img alt="play".*/>(.*?)</span> <span class="data-box">',re.S) 6 # 查找番剧播放量 7 f_liketext = re.compile(r'<img alt="follow".*/>(.*?)</span>',re.S) 8 # 查找番剧收藏数
想要获取番剧的评分和介绍,需要点击进入番剧详情页面获取。并不能在排行榜页面直接获取。
所以要再分别爬取排名中各个番剧详情链接,以得到评分和介绍数据。
所以要在li标签的遍历中用获取到的详情页面链接link作为目标,再进行爬取,用于获取评分和番剧介绍数据:
1 soup_1= get(link) 2 #用获取到的链接link作为目标,用于获取评分和番剧介绍数据
并且,如果某些详情页面没有评分信息,为防止报错,将没有介绍信息的番剧,介绍栏写上“暂无”,将没有评分信息的番剧的评分以总体评分的平均分来记录,方便后期数据分析。
1 if re.findall(f_score,item2) == []: 2 #如果找不到番剧评分 3 list2.append(f_no) 4 #记录无评分信息的番剧的排名 5 score = "暂无" 6 scorelist2.append("暂无") 7 #在评分列表2中占一个位 8 else: 9 score = re.findall(f_score,item2)[0] 10 scorelist1.append(float(score)) 11 #记录在评分列表1中,用于求平均分 12 scorelist2.append(score) 13 #记录下评分列表2中,用于最终输出
1 score = round(mean(scorelist1),1) 2 #求番剧评分的平均值,保留一位小数 3 for i in list2: 4 scorelist2[i-1] = str(score) 5 #将没有评分信息的项替换为评分平均值
总的爬取部分见完整代码,太长了就不单独放进来,最终爬取结果:
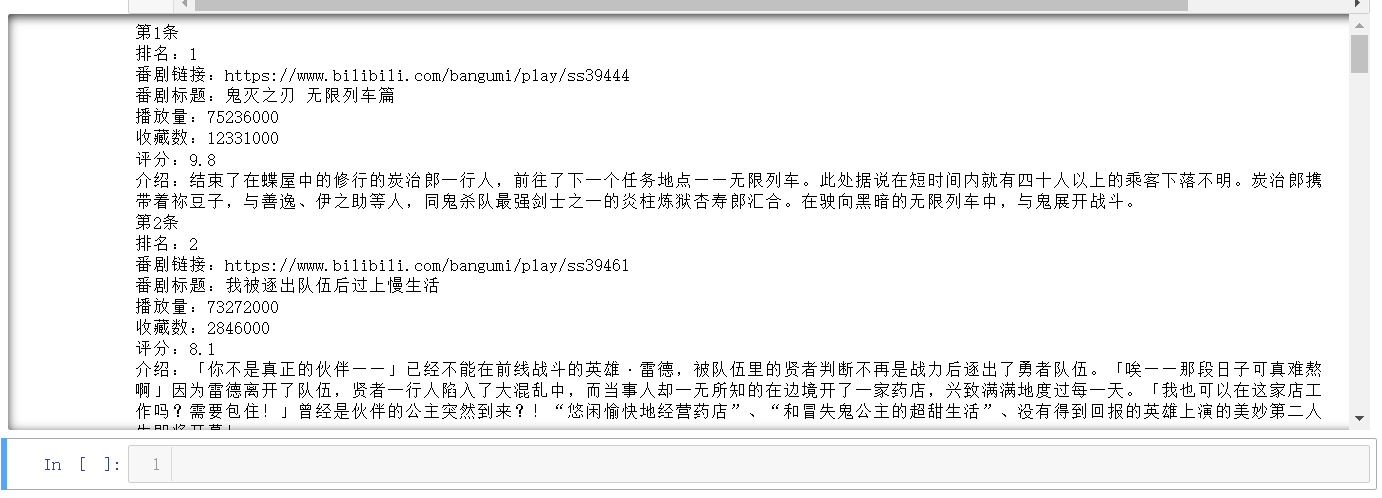
对数据进行清洗和处理:
去掉查找的结果中的换行符和空格,分析结果,发现播放量和收藏数中有“亿”“万”等单位,而非纯数字,所以编写函数进行

1 def num_zh(num):#将含"万"和"亿"的数据转为纯数字 2 num = str(num) 3 numYi = num.find('亿') 4 numWan = num.find('万') 5 6 if numYi != -1 and numWan != -1: 7 return int(float(num[:numYi])*1e8 + float(num[numYi+1:numWan])*1e4) 8 9 elif numYi != -1 and numWan == -1: 10 return int(float(num[:numYi])*1e8) 11 12 elif numYi == -1 and numWan != -1: 13 return int(float(num[numYi+1:numWan])*1e4) 14 15 elif numYi == -1 and numWan == -1: 16 return float(num)
转换后:

数据持久化:
将表格保存在本地,以便数据分析。为防止错误,用的是相对保存路径。并且在保存时检查文件是否已存在,防止多次运行时因为文件已存在而发生错误。
1 #判断文件是否已存在,防止错误 2 my_file = "哔站番剧综合排行榜top50.xls" # 文件路径 3 if os.path.exists(my_file): 4 # 如果文件已存在 5 print('文件已存在,正在覆盖!') 6 os.remove(my_file) 7 # 删除
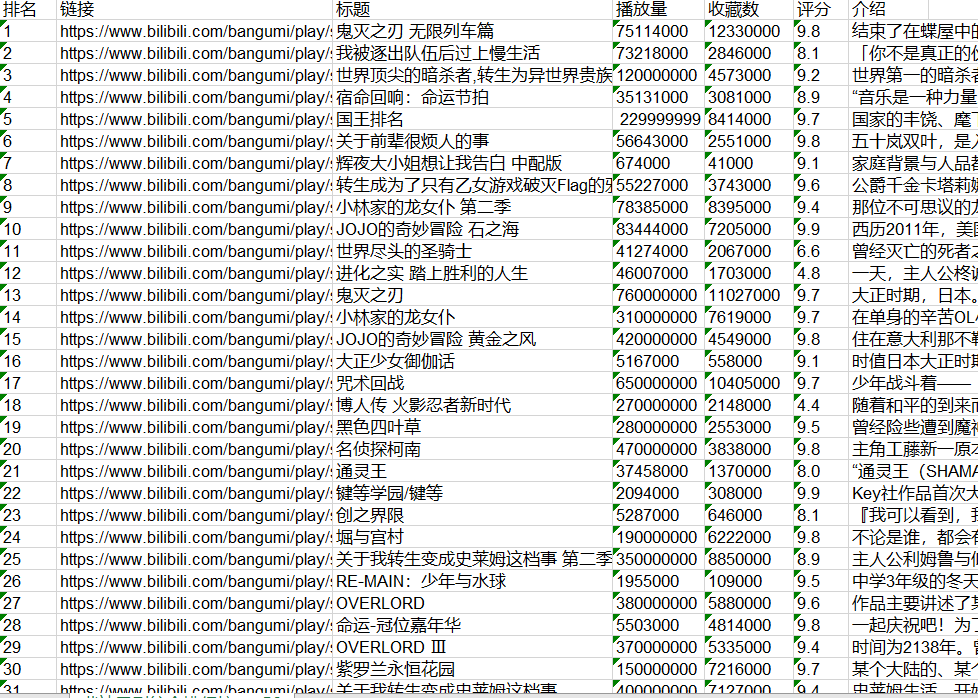
1 book = xlwt.Workbook(encoding="utf-8",style_compression=0) 2 #创建workbook对象 3 sheet = book.add_sheet('哔站番剧综合排行榜top50',cell_overwrite_ok=True) 4 #创建工作表 5 col = ("排名","链接","标题","播放量","收藏数","评分","介绍") 6 for i in range(0,7): 7 sheet.write(0,i,col[i]) 8 #列名 9 for i in range(0,50): 10 data = datalist[i] 11 for j in range(0,7): 12 sheet.write(i+1,j,data[j]) 13 #数据 14 savepath = ".\\哔站番剧综合排行榜top50.xls" 15 book.save(savepath) 16 print('已保存表格!')
输出结果:
并且输出一个数据表db文件,进一步保存数据。为防止错误,用的是相对保存路径。
在保存输出数据表数据的过程中,需要对数据进行特别处理,比如在每个字符串类型的数据前后加上双引号。
1 my_file = "top50.db" # 文件路径 2 if os.path.exists(my_file): 3 # 如果文件已存在 4 print('文件已存在,正在覆盖!') 5 os.remove(my_file) 6 # 删除
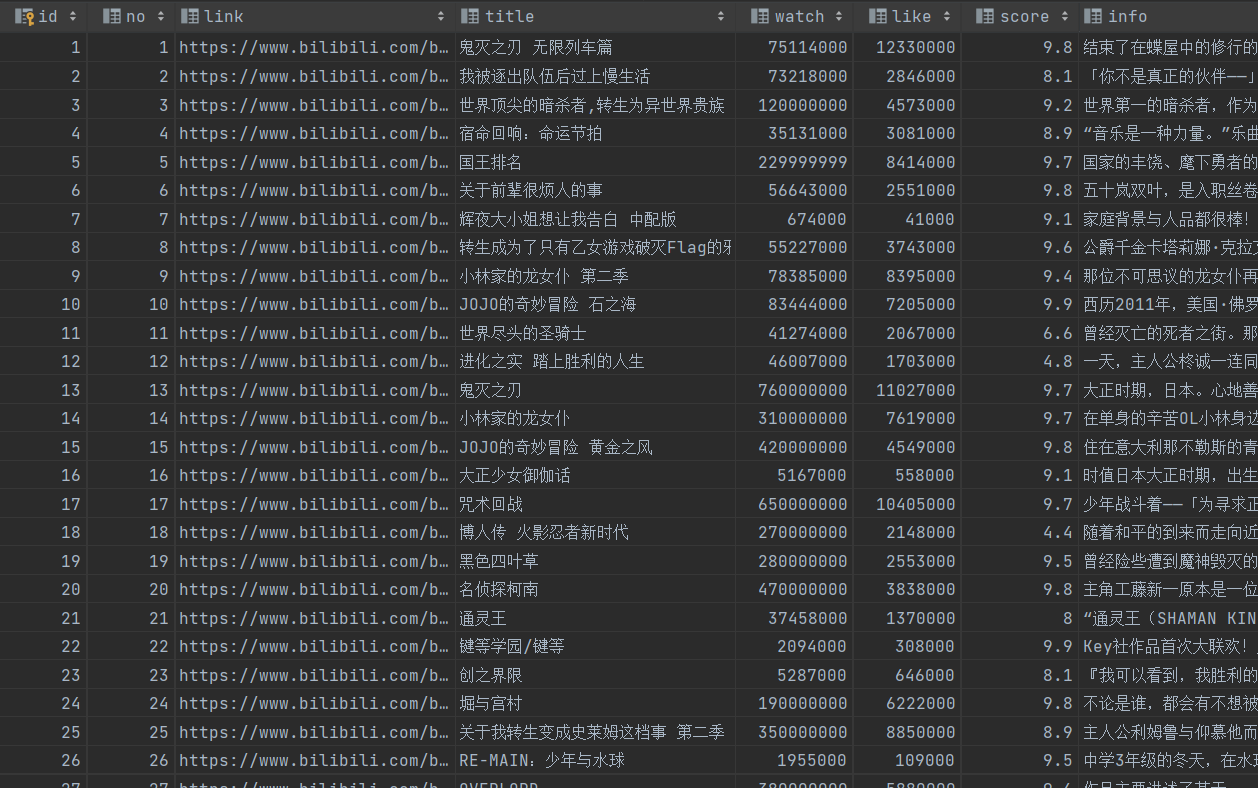
1 sql = ''' 2 create table top50 3 ( 4 id integer primary key autoincrement, 5 no numeric, 6 link text, 7 title varchar, 8 watch numeric, 9 like numeric, 10 score numeric, 11 info varchar 12 ) 13 ''' # 创建数据表,以上分别是"排名"类型为数字,"链接"类型为文本,"标题"类型为字符串,"播放量"类型为数字,"收藏数"类型为数字,"评分"类型为数字,"介绍"类型为文本 14 dbpath = "top50.db" 15 conn = sqlite3.connect(dbpath) 16 cursor = conn.cursor() 17 cursor.execute(sql) 18 conn.commit() 19 conn.close() 20 21 conn = sqlite3.connect(dbpath) 22 cur = conn.cursor() 23 for data in datalist: 24 #将所有字符串类型的数据的前后都加上双引号 25 for index in range(len(data)): 26 27 #跳过不需要加双引号的数据 28 if index == 0 or index == 3 or index == 4 or index == 5: 29 continue 30 data[index] = '"'+data[index]+'"' 31 sql = ''' 32 insert into top50 ( 33 no,link,title,watch,like,score,info) 34 values(%s)'''%",".join(data) 35 print(sql) 36 cur.execute(sql) 37 conn.commit() 38 39 cur.close() 40 conn.close() 41 print('已保存数据表!')
输出结果:
进一步数据清洗:
1 #读取表格信息 2 df=pd.read_excel(r'哔站番剧综合排行榜top50.xls') 3 R=pd.DataFrame(df)
1 #检查是否有重复值 2 print(R.duplicated()) 3 #检查是否有空值 4 print(R['排名'].isnull().value_counts()) 5 print(R['链接'].isnull().value_counts()) 6 print(R['标题'].isnull().value_counts()) 7 print(R['播放量'].isnull().value_counts()) 8 print(R['收藏数'].isnull().value_counts()) 9 print(R['评分'].isnull().value_counts()) 10 print(R['介绍'].isnull().value_counts())
输出结果:
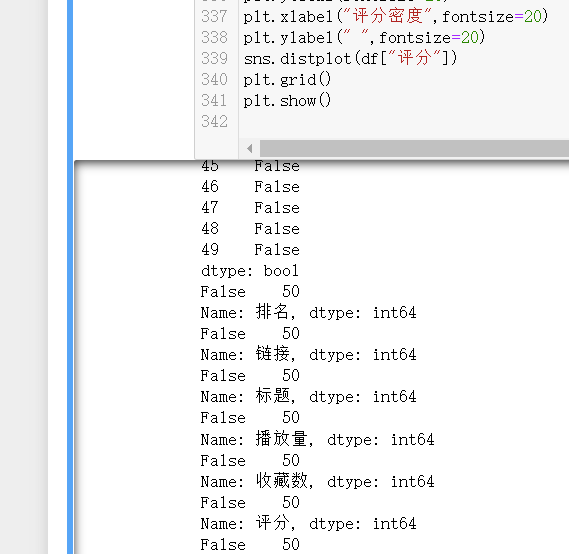
说明数据没有相关问题。
数据分析与可视化:
1 ############排名和各类数量关系柱状图############ 2 plt.xticks(fontsize=8) 3 plt.yticks(fontsize=12) 4 plt.rcParams['font.sans-serif']=['SimHei'] 5 s = pd.Series(df.播放量,df.排名) 6 s.plot(kind="bar",title="排名和播放量") 7 8 #x标签 9 plt.xlabel("排名") 10 #y标签 11 plt.ylabel("播放量") 12 plt.show() 13 14 s = pd.Series(df.收藏数,df.排名) 15 s.plot(kind="bar",title="排名和收藏数") 16 plt.xticks(fontsize=8) 17 plt.yticks(fontsize=12) 18 #x标签 19 plt.xlabel("排名") 20 #y标签 21 plt.ylabel("收藏数") 22 plt.show() 23 24 s = pd.Series(df.评分,df.排名) 25 s.plot(kind="bar",title="排名和评分") 26 plt.xticks(fontsize=8) 27 plt.yticks(fontsize=12) 28 #x标签 29 plt.xlabel("排名") 30 #y标签 31 plt.ylabel("评分") 32 plt.show()

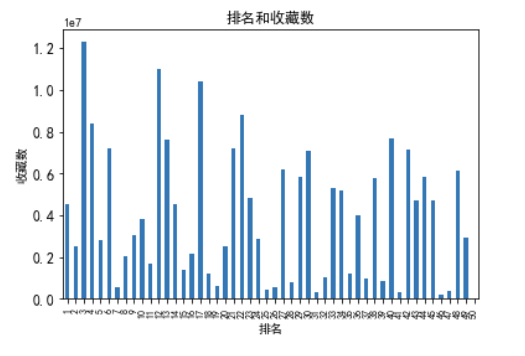
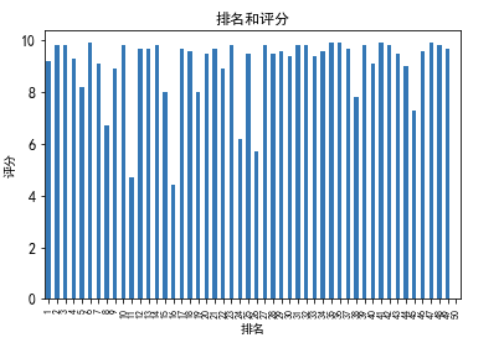
从排名和播放量和排名和收藏数两个表可以看推测,排名前几的番剧都是新出的番剧,所以即使热度很高,播放量和收藏数不会有旧的优秀番剧那么高。
相信随时间的过去,这些排名前几的新番剧都积累比现在高很多的播放量和收藏数,同时被新出的番剧挤下前几名,而位于中上位置。
根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变
量之间的回归方程:
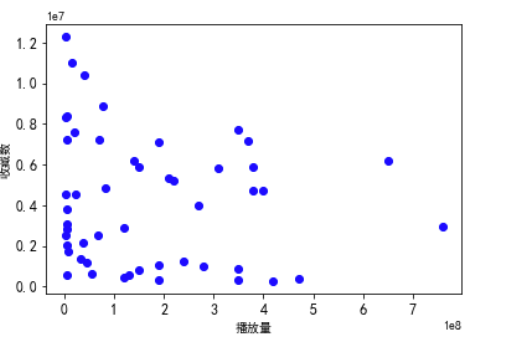
1 ############播放量和收藏数散点图############ 2 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 3 plt.rcParams['axes.unicode_minus']=False 4 plt.xticks(fontsize=12) 5 plt.yticks(fontsize=12) 6 #散点 7 plt.scatter(df_1.播放量,df.收藏数, color='b') 8 plt.rcParams['font.sans-serif']=['SimHei'] 9 #x标签 10 plt.xlabel('播放量') 11 #y标签 12 plt.ylabel('收藏数') 13 plt.show()
1 ############排名和收藏数散点图############ 2 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 3 plt.rcParams['axes.unicode_minus']=False 4 plt.xticks(fontsize=12) 5 plt.yticks(fontsize=12) 6 #散点 7 plt.scatter(df.排名,df.收藏数, color='r') 8 plt.rcParams['font.sans-serif']=['SimHei'] 9 #x标签 10 plt.xlabel('排名') 11 #y标签 12 plt.ylabel('收藏数') 13 plt.show()

1 ############播放量和收藏数线性回归############ 2 predict_model=LinearRegression() 3 x=df_1[["播放量"]] 4 y=df["收藏数"] 5 predict_model.fit(x,y) 6 print("回归方程系数为{}".format( predict_model.coef_)) 7 print("回归方程截距:{0:2f}".format( predict_model.intercept_)) 8 9 x0=np.array(df_1['播放量']) 10 y0=np.array(df['收藏数']) 11 def func(x,c0): 12 a,b,c=c0 13 return a*x**2+b*x+c 14 def errfc(c0,x,y): 15 return y-func(x,c0) 16 c0=[0,2,3] 17 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 18 a,b,c=c1 19 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 20 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 21 plt.plot(x0,y0,"ob",label="样本数据") 22 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 23 #x标签 24 plt.xlabel("播放量") 25 #y标签 26 plt.ylabel("收藏数") 27 plt.legend(loc=3,prop=chinese) 28 plt.show()
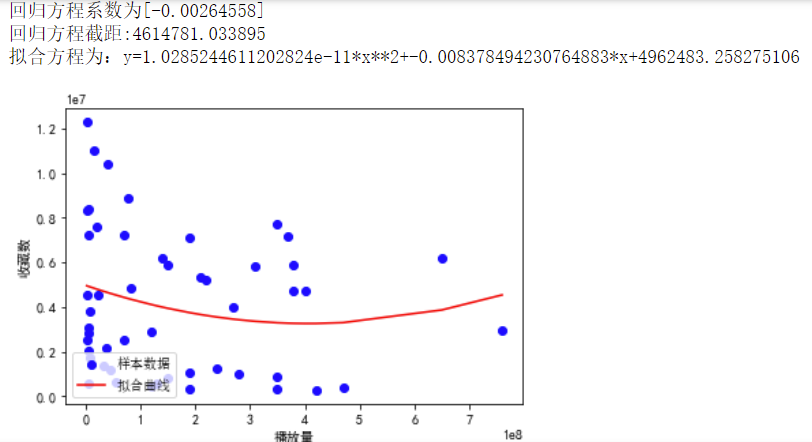
1 ############排名和收藏数线性回归############ 2 predict_model=LinearRegression() 3 x=df[["排名"]] 4 y=df["收藏数"] 5 predict_model.fit(x,y) 6 print("回归方程系数为{}".format( predict_model.coef_)) 7 print("回归方程截距:{0:2f}".format( predict_model.intercept_)) 8 9 x0=np.array(df['排名']) 10 y0=np.array(df['收藏数']) 11 def func(x,c0): 12 a,b,c=c0 13 return a*x**2+b*x+c 14 def errfc(c0,x,y): 15 return y-func(x,c0) 16 c0=[0,2,3] 17 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 18 a,b,c=c1 19 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 20 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 21 plt.plot(x0,y0,"or",label="样本数据") 22 plt.plot(x0,func(x0,c1),"b",label="拟合曲线") 23 #x标签 24 plt.xlabel("排名") 25 #y标签 26 plt.ylabel("收藏数") 27 plt.legend(loc=3,prop=chinese) 28 plt.show()

1 ############评分密度直方图############ 2 plt.figure(figsize=(6,6)) 3 plt.suptitle('评分密度直方图',fontsize=20) 4 plt.xticks(fontsize=20) 5 plt.yticks(fontsize=20) 6 plt.xlabel("评分密度",fontsize=20) 7 plt.ylabel(" ",fontsize=20) 8 sns.distplot(df["评分"]) 9 plt.grid() 10 plt.show()

1 ############评分分布饼图############ 2 matplotlib.rcParams['font.sans-serif'] = ['SimHei'] 3 matplotlib.rcParams['axes.unicode_minus'] = False 4 # 设置字体 5 pf = [0, 0, 0, 0, 0, 0, 0] #用来记录特定条件出现的次数 6 #开始逐个分析评分 7 for i in range(len(df.评分)): 8 if df.评分[i] > 9.5: 9 pf[0] = pf[0] + 1 10 if df.评分[i] > 9.0 and df.评分[i] <= 9.5: 11 pf[1] = pf[1] + 1 12 if df.评分[i] > 8.5 and df.评分[i] <= 9.0: 13 pf[2] = pf[2] + 1 14 if df.评分[i] > 8.0 and df.评分[i] <= 8.5: 15 pf[3] = pf[3] + 1 16 if df.评分[i] > 7.5 and df.评分[i] <= 8.0: 17 pf[4] = pf[4] + 1 18 if df.评分[i] > 7.0 and df.评分[i] <= 7.5: 19 pf[5] = pf[5] + 1 20 if df.评分[i] <= 7.0: 21 pf[6] = pf[6] + 1 22 #print(pf) 23 label = '>9.5', '9.0-9.5', '8.5-9.0', '8.0-8.5', '7.5-8.0', '7.0-7.5', '<7.0'#标题 24 color = 'red', 'orange', 'yellow', 'pink', 'green', 'blue' #颜色 25 cs = [0, 0, 0, 0, 0, 0, 0] 26 #用来显示百分比占比 27 explode = [0, 0, 0, 0, 0, 0, 0] 28 #每块离中心的距离; 29 for i in range(0,7): # 计算 30 #print(i) 31 cs[i] = pf[i] * 2 32 explode[i] = pf[i] / 500 33 #print(cs) 34 #开始配置图形 35 pie = plt.pie(cs, colors=color, explode=explode, labels=label, shadow=True, autopct='%1.1f%%') 36 for font in pie[1]: 37 font.set_size(12) 38 for digit in pie[2]: 39 digit.set_size(8) 40 plt.axis('equal') 41 #配置标题,字号大小等: 42 plt.title(u'各个评分占比', fontsize=18) 43 plt.legend(loc=0, bbox_to_anchor=(0.8, 1)) 44 leg = plt.gca().get_legend() 45 ltext = leg.get_texts() 46 plt.setp(ltext, fontsize=8) 47 #显示视图 48 plt.show()
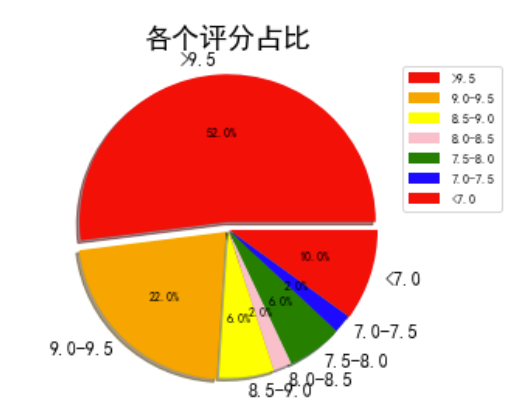
经过观察以上输出视图,我发现其中只有排名和收藏数有明显的联系,排名越前收藏数越高。排行榜前50名的评分都集中在比较高的位置。
完整代码:
1 import os 2 #包含判断文件存在性功能的的库 3 from bs4 import BeautifulSoup 4 #导入网页解析相关的库 5 import re 6 #导入进行文字匹配相关的库 7 import time 8 #导入延时操作相关的库 9 import urllib.request,urllib.error 10 #导入制定URL获取网页数据相关的库 11 import xlwt 12 #导入excel操作相关的库 13 import sqlite3 14 #导入SQLite数据库操作相关的库 15 from numpy import * 16 #用于求列表的平均值 17 import xlrd 18 import pandas as pd 19 import pandas as np 20 import matplotlib.pyplot as plt 21 import matplotlib 22 import scipy.optimize as opt 23 import seaborn as sns 24 from sklearn.linear_model import LinearRegression 25 #导入数据清洗和分析相关的库 26 27 28 ############爬取信息############ 29 def get(url):#获取网页信息函数 30 head = { 31 "User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome / 96.0.4664.110 Safari / 537.36" 32 } 33 #模拟浏览器头部信息 34 request = urllib.request.Request(url, headers=head) 35 #携带着这个包含着我的设备型号的头部信息去访问这个网址 36 html = "" 37 #用字符串对它进行存储 38 time.sleep(0.1) 39 #添加延时,防止错误 40 41 try: 42 #处理可能会发生的错误,比如说网络问题等,并输出错误代码,如404 43 response = urllib.request.urlopen(request) 44 html = response.read().decode("utf-8") 45 46 except urllib.error.URLError as e: 47 48 if hasattr(e, "code"): 49 print(e.code) 50 51 if hasattr(e, "reason"): 52 print(e.reason) 53 54 soup = BeautifulSoup(html,"html.parser") 55 #解析数据 56 return soup 57 58 def num_zh(num):#将含"万"和"亿"的数据转为纯数字 59 num = str(num) 60 numYi = num.find('亿') 61 numWan = num.find('万') 62 63 if numYi != -1 and numWan != -1: 64 return int(float(num[:numYi])*1e8 + float(num[numYi+1:numWan])*1e4) 65 66 elif numYi != -1 and numWan == -1: 67 return int(float(num[:numYi])*1e8) 68 69 elif numYi == -1 and numWan != -1: 70 return int(float(num[numYi+1:numWan])*1e4) 71 72 elif numYi == -1 and numWan == -1: 73 return float(num) 74 75 baseurl = "https://www.bilibili.com/v/popular/rank/bangumi" 76 soup = get(baseurl) 77 # 测试输出html信息,print(soup) 78 datalist = [] 79 # 创建列表用来保持数据 80 f_no = 0#排名编号 81 list1 = [] 82 list2=[] 83 scorelist1=[] 84 scorelist2=[] 85 #建立列表用于存放数据 86 87 for item1 in soup.find_all('li',class_="rank-item"): 88 #查找符合条件的li标签,逐一分析即遍历(在输出的标签li列表中,逐一进行查找标签li中我们需要的信息,并保存于新的列表datalist中) 89 item1 = str(item1) 90 f_no = f_no+1 91 # 编写排名编号 92 print('第'+str(f_no)+'条') 93 f_link = re.compile(r'<a href="(.*?)" target') 94 # 查找番剧链接 95 f_title = re.compile(r'<a class="title".*target="_blank">(.*?)</a>') 96 # 查找番剧标题 97 f_watchtext = re.compile(r'<img alt="play".*/>(.*?)</span> <span class="data-box">',re.S) 98 # 查找番剧播放量 99 f_liketext = re.compile(r'<img alt="follow".*/>(.*?)</span>',re.S) 100 # 查找番剧收藏数 101 102 print('排名:'+str(f_no)) 103 list1.append(str(f_no)) 104 link = 'https:'+re.findall(f_link,item1)[0]#补充链接头部缺少的https: 105 print('番剧链接:'+link) 106 list1.append(link) 107 title = re.findall(f_title,item1)[0] 108 print('番剧标题:'+title) 109 list1.append(title) 110 watchtext = re.findall(f_watchtext,item1)[0].replace("\n","").strip()#去除内容中的空格与换行符 111 watch = str(num_zh(watchtext)) 112 print('播放量:'+watch) 113 list1.append(watch) 114 liketext = re.findall(f_liketext,item1)[0].replace("\n","").strip()#去除内容中的空格与换行符 115 like = str(num_zh(liketext)) 116 print('收藏数:'+like) 117 list1.append(like) 118 119 soup_1= get(link) 120 #用获取到的链接link作为目标,爬取番剧的详情页面,用于获取评分和番剧介绍数据 121 #测试输出 print(soup_1) 122 123 item2 = soup_1.find_all('div',class_="media-right") 124 item2 = str(item2) 125 126 f_info = re.compile(r'<span class="absolute">(.*?)</span>',re.S) 127 # 查找番剧介绍 128 f_score = re.compile(r'<h4 class="score">(.*?)</h4>') 129 # 查找番剧评分 130 131 if re.findall(f_info,item2) == []: 132 #如果找不到番剧介绍 133 info = '暂无' 134 else: 135 info = re.findall(f_info,item2)[0].replace("\n","") 136 137 list1.append(info) 138 139 if re.findall(f_score,item2) == []: 140 #如果找不到番剧评分 141 list2.append(f_no) 142 #记录无评分信息的番剧的排名 143 score = "暂无" 144 scorelist2.append("暂无") 145 #在评分列表2中占一个位 146 else: 147 score = re.findall(f_score,item2)[0] 148 scorelist1.append(float(score)) 149 #记录在评分列表1中,用于求平均分 150 scorelist2.append(score) 151 #记录下评分列表2中,用于最终输出 152 print('评分:'+score) 153 print('介绍:'+info) 154 score = round(mean(scorelist1),1) 155 #求番剧评分的平均值,保留一位小数 156 for i in list2: 157 scorelist2[i-1] = str(score) 158 #将没有评分信息的项替换为评分平均值 159 160 for i in range(0,50): 161 #将记录的数据,按一定格式记录于最终的表datalist中 162 data=[] 163 data.append(list1[i*6]) 164 data.append(list1[i*6+1]) 165 data.append(list1[i*6+2]) 166 data.append(list1[i*6+3]) 167 data.append(list1[i*6+4]) 168 data.append(scorelist2[i]) 169 data.append(list1[i*6+5]) 170 datalist.append(data) 171 #测试输出 print(datalist) 172 173 174 ############将数据保存在表格中############ 175 book = xlwt.Workbook(encoding="utf-8",style_compression=0) 176 #创建workbook对象 177 sheet = book.add_sheet('哔站番剧综合排行榜top50',cell_overwrite_ok=True) 178 #创建工作表 179 col = ("排名","链接","标题","播放量","收藏数","评分","介绍") 180 for i in range(0,7): 181 sheet.write(0,i,col[i]) 182 #列名 183 for i in range(0,50): 184 data = datalist[i] 185 for j in range(0,7): 186 sheet.write(i+1,j,data[j]) 187 #数据 188 savepath = ".\\哔站番剧综合排行榜top50.xls"# 文件路径 189 190 #判断文件是否已存在,防止错误 191 my_file = "哔站番剧综合排行榜top50.xls" # 文件路径 192 if os.path.exists(my_file): 193 # 如果文件已存在 194 print('文件已存在,正在覆盖!') 195 os.remove(my_file) 196 # 删除 197 198 book.save(savepath) 199 print('已保存表格!') 200 201 202 ############将数据保存在数据表中############ 203 sql = ''' 204 create table top50 205 ( 206 id integer primary key autoincrement, 207 no numeric, 208 link text, 209 title varchar, 210 watch numeric, 211 like numeric, 212 score numeric, 213 info varchar 214 ) 215 ''' # 创建数据表,以上分别是"排名"类型为数字,"链接"类型为文本,"标题"类型为字符串,"播放量"类型为数字,"收藏数"类型为数字,"评分"类型为数字,"介绍"类型为文本 216 dbpath = "top50.db"# 文件路径 217 218 #判断文件是否已存在,防止错误 219 my_file = "top50.db" # 文件路径 220 if os.path.exists(my_file): 221 # 如果文件已存在 222 print('文件已存在,正在覆盖!') 223 os.remove(my_file) 224 # 删除 225 226 conn = sqlite3.connect(dbpath) 227 cursor = conn.cursor() 228 cursor.execute(sql) 229 conn.commit() 230 conn.close() 231 232 conn = sqlite3.connect(dbpath) 233 cur = conn.cursor() 234 for data in datalist: 235 #将所有字符串类型的数据的前后都加上双引号 236 for index in range(len(data)): 237 238 #跳过不需要加双引号的数据 239 if index == 0 or index == 3 or index == 4 or index == 5: 240 continue 241 data[index] = '"'+data[index]+'"' 242 sql = ''' 243 insert into top50 ( 244 no,link,title,watch,like,score,info) 245 values(%s)'''%",".join(data) 246 print(sql) 247 cur.execute(sql) 248 conn.commit() 249 250 cur.close() 251 conn.close() 252 print('已保存数据表!') 253 print("爬取完毕") 254 255 256 ############数据清洗############ 257 #读取表格信息 258 df=pd.read_excel(r'哔站番剧综合排行榜top50.xls') 259 R=pd.DataFrame(df) 260 261 #检查是否有重复值 262 print(R.duplicated()) 263 #检查是否有空值 264 print(R['排名'].isnull().value_counts()) 265 print(R['链接'].isnull().value_counts()) 266 print(R['标题'].isnull().value_counts()) 267 print(R['播放量'].isnull().value_counts()) 268 print(R['收藏数'].isnull().value_counts()) 269 print(R['评分'].isnull().value_counts()) 270 print(R['介绍'].isnull().value_counts()) 271 272 273 ############数据分析############ 274 df_1=df.sort_values('播放量',ascending=True) 275 #根据播放量升序排序 276 277 278 ############排名和各类数量关系柱状图############ 279 plt.xticks(fontsize=8) 280 plt.yticks(fontsize=12) 281 plt.rcParams['font.sans-serif']=['SimHei'] 282 s = pd.Series(df.播放量,df.排名) 283 s.plot(kind="bar",title="排名和播放量") 284 #x标签 285 plt.xlabel("排名") 286 #y标签 287 plt.ylabel("播放量") 288 #显示图形 289 plt.show() 290 291 s = pd.Series(df.收藏数,df.排名) 292 s.plot(kind="bar",title="排名和收藏数") 293 plt.xticks(fontsize=8) 294 plt.yticks(fontsize=12) 295 #x标签 296 plt.xlabel("排名") 297 #y标签 298 plt.ylabel("收藏数") 299 #显示图形 300 plt.show() 301 302 s = pd.Series(df.评分,df.排名) 303 s.plot(kind="bar",title="排名和评分") 304 plt.xticks(fontsize=8) 305 plt.yticks(fontsize=12) 306 #x标签 307 plt.xlabel("排名") 308 #y标签 309 plt.ylabel("评分") 310 #显示图形 311 plt.show() 312 313 314 ############播放量和收藏数散点图############ 315 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 316 plt.rcParams['axes.unicode_minus']=False 317 plt.xticks(fontsize=12) 318 plt.yticks(fontsize=12) 319 #散点 320 plt.scatter(df_1.播放量,df.收藏数, color='b') 321 plt.rcParams['font.sans-serif']=['SimHei'] 322 #x标签 323 plt.xlabel('播放量') 324 #y标签 325 plt.ylabel('收藏数') 326 #显示图形 327 plt.show() 328 329 330 ############排名和收藏数散点图############ 331 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] 332 plt.rcParams['axes.unicode_minus']=False 333 plt.xticks(fontsize=12) 334 plt.yticks(fontsize=12) 335 #散点 336 plt.scatter(df.排名,df.收藏数, color='r') 337 plt.rcParams['font.sans-serif']=['SimHei'] 338 #x标签 339 plt.xlabel('排名') 340 #y标签 341 plt.ylabel('收藏数') 342 #显示图形 343 plt.show() 344 345 346 ############播放量和收藏数线性回归############ 347 predict_model=LinearRegression() 348 x=df_1[["播放量"]] 349 y=df["收藏数"] 350 predict_model.fit(x,y) 351 print("回归方程系数为{}".format( predict_model.coef_)) 352 print("回归方程截距:{0:2f}".format( predict_model.intercept_)) 353 354 x0=np.array(df_1['播放量']) 355 y0=np.array(df['收藏数']) 356 def func(x,c0): 357 a,b,c=c0 358 return a*x**2+b*x+c 359 def errfc(c0,x,y): 360 return y-func(x,c0) 361 c0=[0,2,3] 362 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 363 a,b,c=c1 364 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 365 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 366 plt.plot(x0,y0,"ob",label="样本数据") 367 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 368 #x标签 369 plt.xlabel("播放量") 370 #y标签 371 plt.ylabel("收藏数") 372 plt.legend(loc=3,prop=chinese) 373 #显示图形 374 plt.show() 375 376 377 ############排名和收藏数线性回归############ 378 predict_model=LinearRegression() 379 x=df[["排名"]] 380 y=df["收藏数"] 381 predict_model.fit(x,y) 382 print("回归方程系数为{}".format( predict_model.coef_)) 383 print("回归方程截距:{0:2f}".format( predict_model.intercept_)) 384 385 x0=np.array(df['排名']) 386 y0=np.array(df['收藏数']) 387 def func(x,c0): 388 a,b,c=c0 389 return a*x**2+b*x+c 390 def errfc(c0,x,y): 391 return y-func(x,c0) 392 c0=[0,2,3] 393 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 394 a,b,c=c1 395 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 396 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 397 plt.plot(x0,y0,"or",label="样本数据") 398 plt.plot(x0,func(x0,c1),"b",label="拟合曲线") 399 #x标签 400 plt.xlabel("排名") 401 #y标签 402 plt.ylabel("收藏数") 403 plt.legend(loc=3,prop=chinese) 404 #显示图形 405 plt.show() 406 407 408 ############评分密度直方图############ 409 plt.figure(figsize=(6,6)) 410 plt.suptitle('评分密度直方图',fontsize=20) 411 plt.xticks(fontsize=20) 412 plt.yticks(fontsize=20) 413 plt.xlabel("评分密度",fontsize=20) 414 plt.ylabel(" ",fontsize=20) 415 sns.distplot(df["评分"]) 416 plt.grid() 417 #显示图形 418 plt.show() 419 420 421 ############评分分布饼图############ 422 matplotlib.rcParams['font.sans-serif'] = ['SimHei'] 423 matplotlib.rcParams['axes.unicode_minus'] = False 424 # 设置字体 425 pf = [0, 0, 0, 0, 0, 0, 0] #用来记录特定条件出现的次数 426 #开始逐个分析评分 427 for i in range(len(df.评分)): 428 if df.评分[i] > 9.5: 429 pf[0] = pf[0] + 1 430 if df.评分[i] > 9.0 and df.评分[i] <= 9.5: 431 pf[1] = pf[1] + 1 432 if df.评分[i] > 8.5 and df.评分[i] <= 9.0: 433 pf[2] = pf[2] + 1 434 if df.评分[i] > 8.0 and df.评分[i] <= 8.5: 435 pf[3] = pf[3] + 1 436 if df.评分[i] > 7.5 and df.评分[i] <= 8.0: 437 pf[4] = pf[4] + 1 438 if df.评分[i] > 7.0 and df.评分[i] <= 7.5: 439 pf[5] = pf[5] + 1 440 if df.评分[i] <= 7.0: 441 pf[6] = pf[6] + 1 442 #print(pf) 443 label = '>9.5', '9.0-9.5', '8.5-9.0', '8.0-8.5', '7.5-8.0', '7.0-7.5', '<7.0'#标题 444 color = 'red', 'orange', 'yellow', 'pink', 'green', 'blue' #颜色 445 cs = [0, 0, 0, 0, 0, 0, 0] 446 #用来显示百分比占比 447 explode = [0, 0, 0, 0, 0, 0, 0] 448 #每块离中心的距离; 449 for i in range(0,7): # 计算 450 #print(i) 451 cs[i] = pf[i] * 2 452 explode[i] = pf[i] / 500 453 #print(cs) 454 #开始配置图形 455 pie = plt.pie(cs, colors=color, explode=explode, labels=label, shadow=True, autopct='%1.1f%%') 456 for font in pie[1]: 457 font.set_size(12) 458 for digit in pie[2]: 459 digit.set_size(8) 460 plt.axis('equal') 461 #配置标题,字号大小等: 462 plt.title(u'各个评分占比', fontsize=18) 463 plt.legend(loc=0, bbox_to_anchor=(0.8, 1)) 464 leg = plt.gca().get_legend() 465 ltext = leg.get_texts() 466 plt.setp(ltext, fontsize=8) 467 #显示视图 468 plt.show()
总结:
以上爬取了我感兴趣的网站信息,让我更加了解自己喜欢的东西,也验证了我的猜想,果然新兴的热门番剧,往往拥有非常高的热度却没有非常高的播放量,它们的播放量还需要时间积累,而积累的时间内会有新的热门番剧发行,从而导致排名前几的热度高却播放量一般,前几偏后几名的拥有非常高的播放量,却热度不再霸榜,再后面就是相对平平无奇的了。
在做这项爬取任务时,我体会到python的魅力所在,体会到编程的乐趣。
在编写时常常因为数据类型错误,网络响应没有代码运行的快,查找不到相关信息引发报错,文件已存在等等一系列问题导致运行失败,而我仔细寻找原因,一个个去修正。
如果数据类型错误,则一一对正。如果网络响应问题报错,则加入延时。通过查找不到相关信息引发报错,则相应对策,如输出“暂无”等等。这使我从中学到很多经验。

