
kubernetes 部署 Fluentd 服务
部署 Fluentd
Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少,另外一个工具Fluent-bit更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛,所以我们这里也同样使用 Fluentd 来作为日志收集工具
工作原理
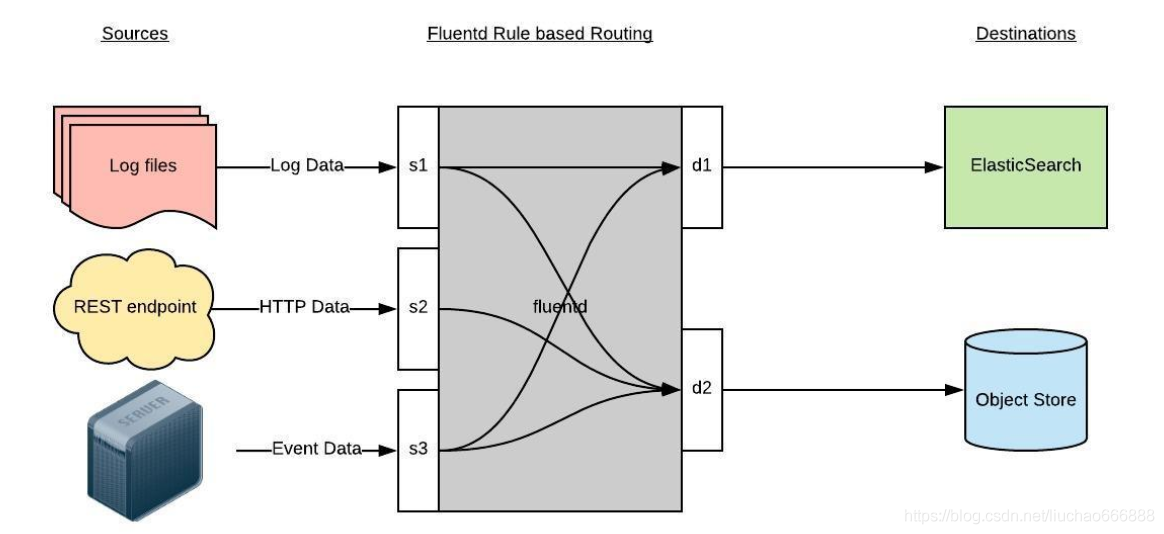
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等
1、首先 Fluentd 从多个日志源获取数据
2、结构化并且标记这些数据
3、然后根据匹配的标签将数据发送到多个目标服务去
配置
日志源配置
比如我们这里为了收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置
<source> @id fluentd-containers.log @type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。 path /var/log/containers/*.log # 挂载的服务器Docker容器日志地址 pos_file /var/log/es-containers.log.pos tag raw.kubernetes.* # 设置日志标签 read_from_head true <parse> # 多行格式化成JSON @type multi_format # 使用 multi-format-parser 解析器插件 <pattern> format json # JSON 解析器 time_key time # 指定事件时间的时间字段 time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式 </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse> </source>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号