
图像Resize方式对深度学习模型效果的影响
在基于卷积神经网络的应用过程中,图像Resize是必不可少的一个步骤。通常原始图像尺寸比较大,比如常见监控摄像机出来的是1080P高清或者720P准高清画面,而网络模型输入一般没有这么大,像Yolo系列目标检测的网络模型输入大小一般为608*608/512*512 等等。那么如何将大尺寸图像输入到网络模型呢?很容易想到的一个方法就是对原始图像进行Resize,将1920*1080的原始图像Resize到网络模型输入尺寸,比如608*608。在压缩图像的过程中,有以下两个问题需要重点讨论:
1、图像Resize前后,是否应该保持宽高比例一致?图像内容变形是否对模型效果有影响
2、图像Resize过程,应该选择什么样的插值方式?
对于第一个问题,其实两种方式均可,前提是要保证模型训练和模型推理时的操作方式一致。也就是说,如果在网络模型训练时,所有的训练素材都是直接拉伸到网路的输入尺寸(不保持宽高比例),那么模型推理时也应该如此,反之亦然。其中保持宽高比例的做法一般是用增加padding的方式,然后用固定颜色填充,保证图像画面中部的内容不变形。下图说明两种方式的差异:

图1 是否保持宽高比
其实对于网络模型来讲,图像是否变形其实不太重要。如果在训练的时候,模型认为一个变形的动物是猫,那么经过大量数据拟合后,在推理阶段,它同样会正确识别出变形的目标。当然根据相关资料显示,通常一般推荐使用直接拉伸的方式去做图像Resize,原因是增加padding填充后会对网络带来一定噪音,影响模型准确性,具体影响有多大我目前没有具体数据证明。这里需要指出的是,一些算法应用框架对细节封装得太好,对原始图像进行Resize的过程被隐藏起来,具体Resize的方式也不得而知。如果你发现模型集成后的准确性下降严重,这时候就需要检查一下框架对图像Resize的方式跟我们模型训练时是否一致。
对于第二个问题,图像Resize过程应该选择什么插值方式?如果对插值不太了解的朋友可以上网搜索一下。这里简单介绍一下图像插值的含义:我们在对图像进行上下采样时(缩放),有时候要在原有像素基础上删除一些像素值(缩小),有时候要在原有像素基础上增加一些像素值(放大),增加/删除像素的方式叫图像插值算法。对OpenCV比较熟悉的朋友可能知道它里面的Resize函数其实有一个‘插值模式’的参数,这个参数有一个默认值:INTER_LINER线性插值。它是一种插值方式,如果你在调用Resize函数时没有修改该参数值,那么该函数就以“线性插值”的方式进行图像缩放。除此之外,还有其他的一些插值方式,每种插值算法的区别请具体参考OpenCV文档。
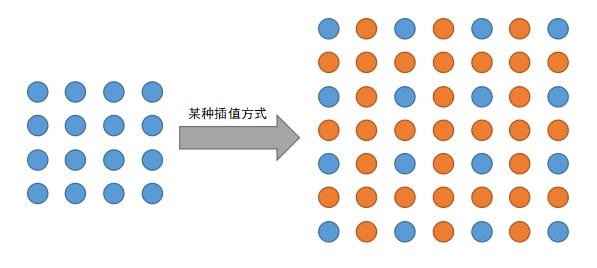
图2 插值示意图
通过上面的介绍,图像在进行Resize操作时,本质上是改变数字图像矩阵大小和矩阵内容,Resize时采用不同的插值方式最终会得到不同的结果(这里说的结果是指微观上像素矩阵,可能肉眼查看画面差别不大)。那么在深度学习应用过程中,我们应该采用什么样的插值方式呢?经过实际测试验证,不管用哪种方式进行插值,模型训练阶段对图像Resize的插值方式跟模型推理阶段对图像Resize的插值方式最好能保持一致,前后两个阶段不同的插值方式确实会影响最终模型的效果。
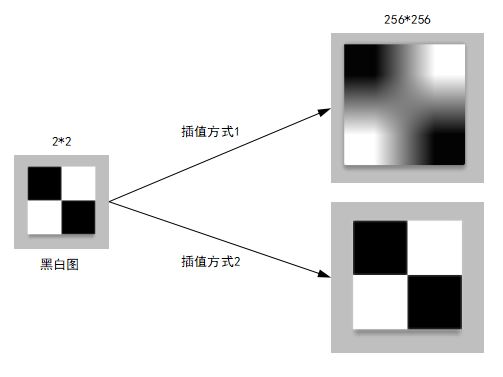
图3 不同插值结果
除了Resize插值方式应该保持一致之外,Resize的次数最好也能保持统一,如果在模型训练阶段,我们将原始图像素材从1000*800缩放到400*400,然后输入网络进行训练,那么我们在模型推理阶段,同样应该将原始图像以相同的插值方式一次性缩放到400*400,然后输入网络进行推理。之所以强调一次性缩放,因为有些算法应用框架在做图像预处理时隐藏了图像缩放的细节,有可能不止一次缩放操作,比如先将原图缩放到800*800,然后再进行二次缩放,最终变成400*400,虽然两次用到的插值方式都跟模型训练阶段保持一致,但是由于进行了两次操作,还是会影响最终推理效果。
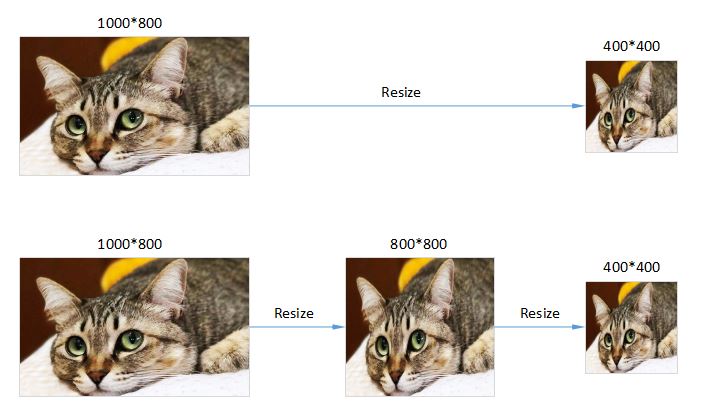
图4 缩放次数不一致
最后总结一下图像缩放方式对模型效果的影响:在模型训练和模型推理阶段,应保持相同的图像预处理方式,这样才能充分发挥模型的推理效果。原因很简单,模型训练的过程就是寻找数据集规律的过程,如果训练用到的和实际推理的数据规律不一样,必然会影响模型效果。当然,本文虽然讨论图像缩放的不同方式对模型效果有影响,但是由于深度学习是一个基于大量数据统计的过程,在有大量数据拟合的情况下,这种影响可能相对来讲并不大,如果你非常在意(或者实际观察发现影响非常大),那么本文讲到的问题可能对你有帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号