
BUAA_2022_OO_第一单元总结
前言
第一单元作业的主题是表达式解析计算,主要任务是在去除非必要括号的基础上尽量缩短表达式。从第一次的单层括号表达式化简开始迭代开发,在第二次作业加入求和函数、三角函数与自定义函数,在第三次作业允许三角函数和自定义的嵌套。
本文将从代码的五个主要部分——抽象表达设计、表达式解析、结果运算、优化缩短、结果输出,展开分析,在每一部分分别讲述自己的迭代过程。
一、架构概述
本次作业的基准思路为递归下降(构建二叉树),灵感来自于第一周上机代码。
拿到一个表达式后第一步是进行解析,构建出一个根节点、子节点为运算符,叶子节点为因子的二叉树。这一步完成了预解析的任务。
有了这样一个表达式树,就开始进行遍历计算,得到每一个节点对应的表达式的抽象表达结果。在计算的过程中进行合并同类项等优化。
最后,将根节点中的抽象表达结果输出。

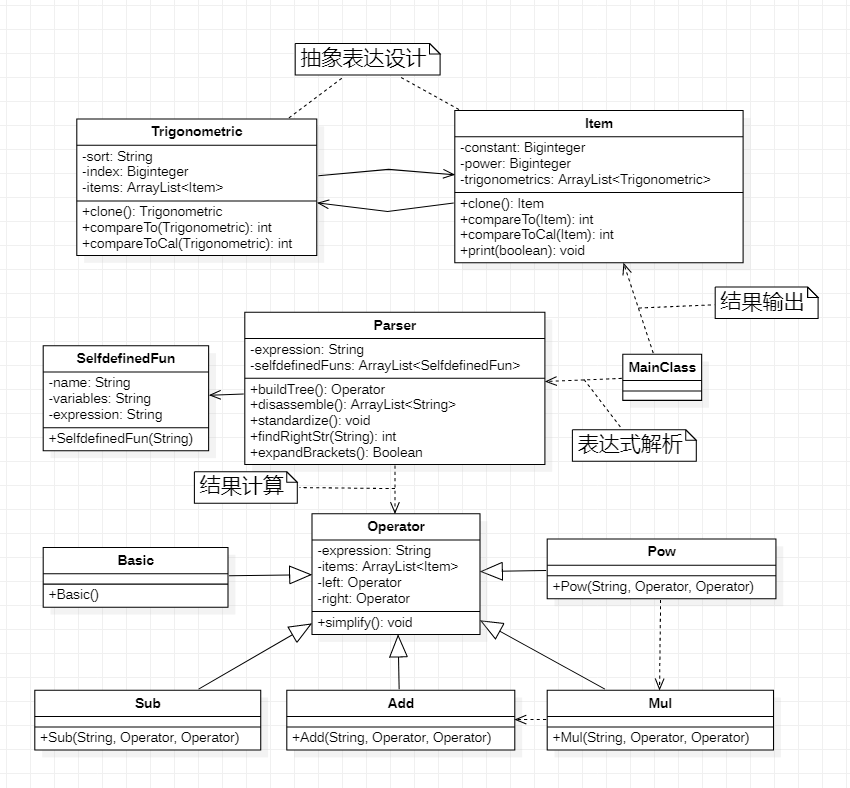
二、抽象表达设计
为了方便计算并摆脱对字符串的操作,我设计了Trigonometric(三角函数因子)以及Item(项)两个类,最终表达式即看作一组项相加。

在类的设计时二者应当相差不大,但Item多出来print方法,使得复杂度、篇幅提高。
属性
Item
Item自第一次作业即存在,它的属性如下:
private BigInteger constant;
private BigInteger power;
private ArrayList<Trigonometric> trigonometrics;
将一个项看作常数(constant)、幂函数(x的power次方)、一组三角函数相乘的结果。
其中constant、power自第一次作业即存在,trigonometrics在第二次作业添加。
Trigonometric
Trigonometric设计于第二次作业,它的属性如下:
private String sort;
private BigInteger index;
private ArrayList<Item> items;
通过类型(sort:sin/cos)、指数(index)、自变量(表达式:一组项相加)描述一个三角函数。
其中sort、index出现于第二次作业,第三次作业用items替代constant、power(自变量从常数因子或幂函数因子升级为任何因子)。
方法
由于Item、Trigonometric的属性中均有对方的对象,因此以下三个方法均涉及调用对方对应函数。
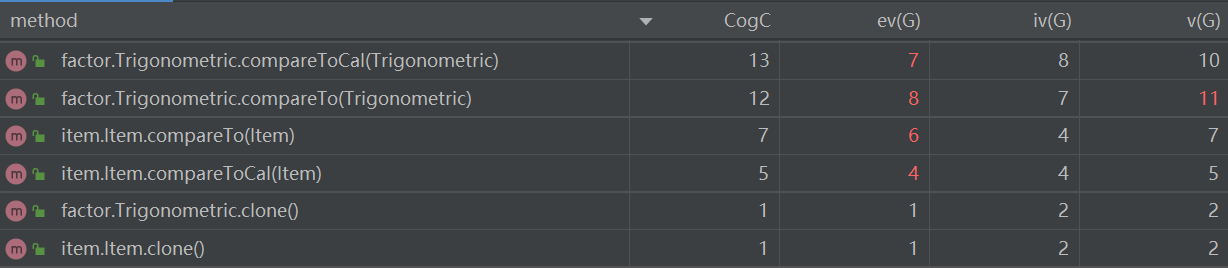
由于compare方法需要依次判断项的各个属性,导致复杂度上升。
clone
写于第三次作业,用于解决深克隆问题。
对Biginteger包装类直接clone,对Item和Trigonometric调用对应clone。
compareTo
由第二次作业(比较Trigonometric)迭代至第三次作业,用于排序和compareToCal。
依次比较每个属性返回-1、0、1即可,比较对方类的对象时,调用对应compareTo即可。保证返回0时,两个对象完全相同。(items、trigonometrics均已经过排序,逐项比较即可)
compareToCal
由第一次作业迭代至第三次作业,用于同类项合并。
与compareTo基本相同。Item无需比较constant即返回0,Trigonometric无需比较index即返回0。
三、表达式解析
第一次作业采用预解析模式,第二次作业设计Parser类完成预解析的任务:建立二叉表达式树,根节点、子节点为运算符,叶子节点为因子。

由于关于解析的所有方法都在此类中,致使篇幅、复杂度飙升。
属性
private String expression;
private ArrayList<SelfdefinedFun> selfdefinedFuns;
一个表达式和一组自定义函数定义。
方法

关于解析的方法多是对字符串的直接操作,以致判断循环语句很多,复杂度高;此外,这些方法有明显的层次结构,相互依赖,耦合度高、内聚性低,相当于把一个大方法拆解成许多部分,再依赖层次联系起来。
buildTree
public Operator buildTree()
核心思路函数,依据当前表达式,建立二叉表达式树并进行运算。
第一步,利用disassemble方法将表达式拆为左支和右支,再拆解左支和右支,直到为基础因子:常数因子、幂函数因子、三角函数因子。
第二步,若表达式为基础因子,则将字符串转换为抽象表达结果;若不是,则根据左右两支的抽象表达结果及运算符计算结果,返回Operator类对象(节点类)。(第二步将在结果计算部分详细介绍)
disassemble
public ArrayList<String> disassemble()
寻找表达式中括号外优先级最低的运算符。
如找得到,返回的字符串数组中含有三项——第一项为找到的运算符,后两项分别为以运算符为界将表达式拆成的左右两部分。
如找不到,则表达式一定为因子,如为表达式因子、自定义函数因子、求和函数因子,则进一步展开重复以上步骤;如为常数因子、幂函数因子、三角函数因子,则返回的字符串数组中含有两项——第一项为"basic",第二项为表达式本身。
用于建树过程。
standardize
public void standardize()
将表达式标准化为可解析状态:去除空白项,合并连续的加减号,若表达式以负号开头则在前面添加"0"、去除正号、为负数套上括号(使括号外没有正负号)。
用于标准化刚刚得到的表达式,表达式因子、自定义函数因子、求和函数因子展开后的表达式。
findRightStr
public int findRightStr(String str)
寻找表达式中括号外最右边str的位置,不存在则返回-1。
用于disassemble方法中寻找低优先级运算符位置。
expandBrackets
public Boolean expandBrackets()
若表达式为表达式因子、自定义函数因子、求和函数因子,将其展开以进一步解析,返回值表示是否有展开操作。
四、结果运算
在第一次作业中设计,二三次作业根据增加的三角函数、自定义函数、求和函数、嵌套等内容不断迭代。
基本思路为:对基本因子(常数因子、幂函数因子、三角函数因子),将字符串转化为抽象表达结果;其它依据运算符及左右两支的抽象表达结果计算。
设计Operator类,作为Basic(基础因子)、Add(加)、Sub(减)、Mul(乘)、Pow(乘方)的父类。
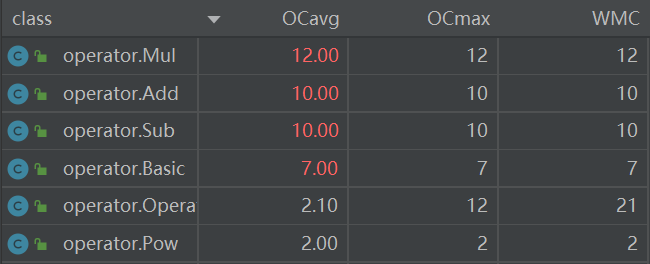
属性
private String expression;
private ArrayList<Item> items;
private Operator left;
private Operator right;
expression为表达式的字符串形式、items则为抽象表达形式,left、right为左右支。
方法
Basic、Add、Sub、Mul、Pow分别重写构造方法,计算出items。

循环判断提高复杂度。
Basic
常数因子、幂函数因子直接转化。
三角函数因子将其自变量当作表达式解析,其余部分直接转化。
Add、Sub、Mul、Pow
模仿数学计算方法。
Add、Sub:遍历左支每一项,查看右支中是否有可合并部分;遍历右支寻找未合并项。
Mul:遍历左支每一项,分别与右支相乘,调用Add累加。
Pow:调用Mul累乘左支。
五、优化缩短
合并同类项
第一次作业设计,第二次作业迭代加入三角函数内容。
在结果运算部分调用compareToCal方法判断是否可以合并,通过合并两项、合并三角函数实现优化缩短。
计算sin(0)、cos(0)
第二次作业设计,第三次作业修改。
在Basic类构造方法中,若发现三角函数因子自变量为0,判断类型后直接转化为常数因子。
提出三角函数自变量负号
第二次作业设计,第三次作业修改。
在Basic类构造方法中,通过compareTo对三角函数自变量中一组项排序,提出负号保证第一项为正。
合并sin平方和cos平方
第三次作业设计。
设计simplify方法,每次结果计算完毕调用化简。
第一步,找到含有cos^2的一项。
第二步,调用clone方法并加以修改,制造含有sin^2的目标项。
第三步,调用conpareTo方法找到目标项位置。
第四步,提出找到的两项合并。

六、结果输出
在Item类中设计print方法用于输出一项,针对项的每一部分考虑是否有必要输出。
三次作业根据项的定义的变化不断迭代。

输出时每一部分都要对各种情况判断。
常数
constant若为1或-1,且该项不只有常数,省略或输出"-"。
幂函数
若index为0,不输出;若为1,输出x;若为2且并非是三角函数自变量中的因子,输出x*x。
三角函数
指数部分同幂函数。若自变量是因子,则自变量无需套括号。
因子间*
设计isFirst标识是否为输出的第一个因子,是则不输出*。
七、架构的优缺点
优点
模块功能清晰,各个类之间耦合度低,方便在不修改代码的前提下,增添功能。
递归的思路清晰,只需把一件事做好,然后重复该过程,方便debug。
缺点
递归的结构耗时长,占用空间大。
部分类功能过于强大,篇幅太长,复杂度太高。
八、Bug分析
在互测和强测中均未出现bug以下讨论几个本地发现的问题。
字符串越界:出现于Parser类的standardize方法中。
for循环break时i的取值错误:出现于Parser类的standardize方法中。
计算错误,compareTo功能误用:出现于Item、Trigonometric类的compareTo方法中。
深克隆问题::出现于Item、Trigonometric类的compareTo方法中。
出现bug的方法圈复杂度明显更高。
九、hack策略
首先明确本次指导书更新的点,对可能出现的数据类型组合进行全覆盖测试。
其次,将上一次容易出现bug的问题通过新的数据类型复现。
再者,测试需要特殊判断的点,和数据边界(0、爆int等)。
最后,对下载下来的代码选择性查看解析、优化等易错点,但理解思路相对困难,能从代码中找到的bug往往是和自己相近的思路。
这四步的hack准确率依次提高。
十、心得体会
首先,我感受到的架构的重要性,一开始依照题意确定一个适合的架构,清晰划分功能,将使迭代过程逻辑清晰,减少bug。就像盖一座摩天大厦时,打好地基一样重要。
其次,我养成了写注释的习惯,第二次作业最初完成时问题一抓一大把,于是,我一边阅读代码一边写注释,思路瞬间清晰起来。而在第三次作业中,代码与注释齐头并进,几乎不需要返工。测试只能发现bug,只有对代码的透彻理解才能保证没有bug。

