
zookeeper学习笔记
数据一致性
zookeeper的数据一致性,是通过分布式2parse commit实现的,过程如下
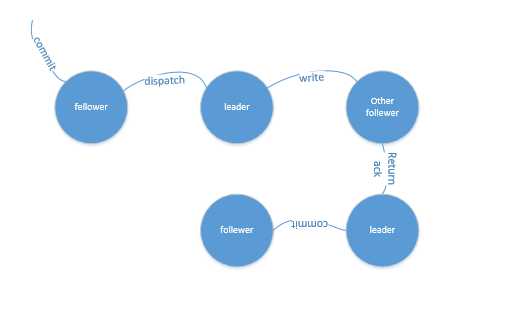
- 收到写入请求的follewer节点,将写入请求转发给leader
- leader收到后,向所有follewer节点发送写操作,
- follewer节点收到写操作请求后,返回ack给leader节点
- leader节点收到所有ack后,向follewer发送commit命令并提交事务
watcher接口
zk在创建链接和setData的时候,都会用到watcher接口:
public interface Watcher { abstract public void process(WatchedEvent event);} |
WatchedEvent状态机
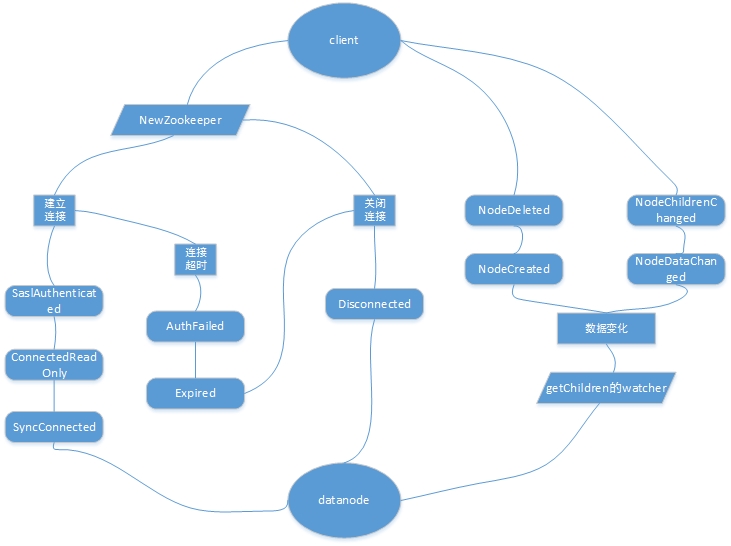
还有一些其他内容需要了解
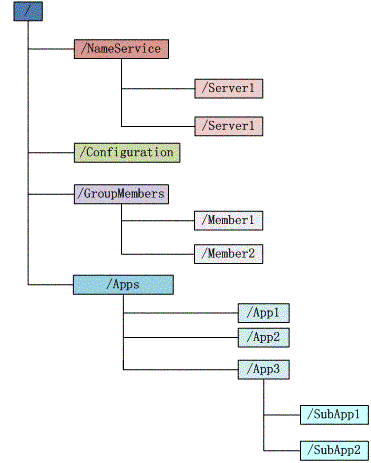
zk存储
每一个文件夹都是一个zknode,建立链接的对象是zknode,数据同步的最终对象也是zknode
leader选举
在n个节点的zookeeper集群中,需要经过n/2+1轮投票选出新的leader,选举需要的信息{myid, lasttxid}
myid是zookeeper节点启东时在myid中配置的,lasttxid是当前节点最后一次写入的事务id递增
选举过程如下:
1.每个节点广播{myid, lasttxid}给其他节点,
2.收到广播的节点,比较{myid,lasttxid}和自己的大小,
- 若 new lastid大于自己,则广播新收到的{myid,lasttxid};
- 若new lastid和自己相等,比较myid,广播myid娇小的;
- 若new lastid小于自己,则广播自己;
3.直到某一个节点收到n/2+1次相同的信息,则停止发送广播,转为follewer
广播的实现,是通过EPHEMERAL_SEQUENTIAL类型的临时zknode实现的,zookeeper还有另一类EPHEMERAL临时zknode,但EPHEMERAL 类zknode不能有子node
- EPHEMERAL_SEQUENTIAL 链接断开时,zknode会消失,但创建时包含id
- EPHEMERAL 链接断开时,zknode会消失
在zknode父目录创建临时zknode,连接断开时,临时node消失,触发client watch父目录的回调函数,刷新zknode list,选出新的zknode
静水流深

 浙公网安备 33010602011771号
浙公网安备 33010602011771号