
手把手教你编写一个具有基本功能的shell(已开源)
刚接触Linux时,对shell总有种神秘感;在对shell的工作原理有所了解之后,便尝试着动手写一个shell。下面是一个从最简单的情况开始,一步步完成一个模拟的shell(我命名之为wshell)的过程。这个所谓的shell和主流的shell还是有不少区别的,最大的区别是它本身不能执行shell脚本、也不能对一些复杂的命令行进行分析——原因很简单,我没有写相应的解释器。如果想自己实现一个简化的shell脚本解释器,如果有编译原理的知识准备,本身不是难事,但是工作量比较大,这里就不完成了,有兴趣的读者可以进行尝试。
本文是边写代码边记录的,更接近于实现过程的思考过程,因此前面的章节可能和最新版的代码有不小的差别,较大的改动会在后文提出,请注意。不过读者不用担心,这些改动都是在原有基础上的完善和提升,并非推倒重来。可以算作上一篇博文《现代操作系统》精读与思考笔记 第一章 引论的副产品。
全部的代码开源,已托管至github:https://github.com/vvy/wshell,因此不再往文中大段大段地粘源代码了。第一次用github托管代码,如果有哪里没设置好请告诉我。
文中所指的和所模仿的shell均指bash。
一.基本功能
1.1 程序框架
首先,shell的基本框架可以用下面的代码概括,这部分代码出自于《现代操作系统(英文第三版)》(Modern Operating Systems)原书P54图1-19,这在上一篇博文《现代操作系统》精读与思考笔记 第一章 引论中已经提到过一次了:
#define TRUE 1 while(TRUE) { /* repeat forever */ type_prompt(); /* display prompt on the screen */ read_command(command,parameters); /* read input from terminal */ if(fork()!=0) { /* fork off child process */ /* Parent code */ waitpid(-1,&status,0); /* wait for child to exit */ } else { /* Child code */ execve(command,parameters,0); /* execute command */ } }
不怕写不出来代码,就怕没思路。想想这么搞确实能够模拟出shell最基本的行为:接受用户输入<=>执行相应程序,甚至借助execv族函数可以直接给程序传参数。有了这个框架就好办了,把那几个函数给实现不就成了呗?
1.2 type_prompt()的实现
来思考下type_prompt()该如何实现。顾名思义,这个要提供一个终端上的提示符,比如

再如

这里的实现需要注意的是,如果当前路径在用户路径下,那么用户路径就用~代替,否则会显示完整路径。分析这两个例子,可以看到输出是这样的形式:“用户名@主机名:路径$”(root权限的#提示符马上提到),对应地:
- 用户名使用getpwuid(getuid())获得,同时可以获得该用户home目录的路径;
- 主机名使用gethostname()获得;
- 路径使用getcwd()获得,如果这个路径包含了该用户home路径,那么使用~把home路径缩略。
- 对于提示符,模仿bash的风格,对于普通用户使用"$",root用户使用"#",需要检测执行这个wshell的用户权限,利用geteuid()是否为0来判断。
这样,就可以着手编写type_prompt()了。为了以示和bash的区别,可以在提示符里加点自己的东西,比如下图第二行那样:

注:查看默认shell版本的命令是echo $SHELL。
1.3 read_command()
在type_prompt()写好之后,可以做一点简单的测试,屏幕上会出现上一节最末的效果图,乍一看还挺唬人的。不过此时还是徒有其表,尚且不能执行任何程序,难道就让它在这里孤芳自赏?接下来需要实现read_command(),它从用户输入中读取命令和参数,分别放入command[]和parameters[][]中,作为exec族函数执行。
最初的版本只是通过fgets()把整行输入读入一个较大的缓冲区中,再对这行进行分析,提取出命令以及参数,分别放到相应的位置。其实Linux本身接受的参数表总长度大小是有限的,这个限制由ARG_MAX给出。因此,这里的缓冲区也的大小用宏定义做一个硬性限制就行了。当然,fgets()有个坏处:如果输入时想要使用退格键修改前面的输入,是不能完成的,这和真实的shell相差有点大。不过这里暂不考虑这个问题,留在后面补充。
输入的分析,其实就是字符串的处理,把一个字符串拆成多个字符串(命令、参数)并分别复制到由malloc()分配的空间中。最初版本的思路比较复杂,本文2.2提供了比较好的实现。
另外一点需要注意:实际上command保存的是路径+命令,而命令本身按照惯例应该存在parameters[0]中。这一点在最初时没有注意,后面用ls命令测试时发现了这一点。
1.4 选择execve()还是execvp()
既然示例中的execve()的环境变量参数env恒为0,没有使用的必要了。况且execvp()能够直接执行ls这样的命令而不用加上路径,更接近于shell,于是选择后者。
1.5 简单测试
动手写一个hello world的程序,然后用这个wshell运行。下面的输出包含了一些分析输入的调试信息:
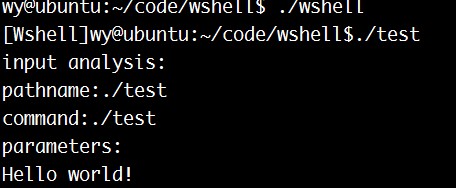
再试试最初未把command中命令放入parameters[0]时不能运行的ls:
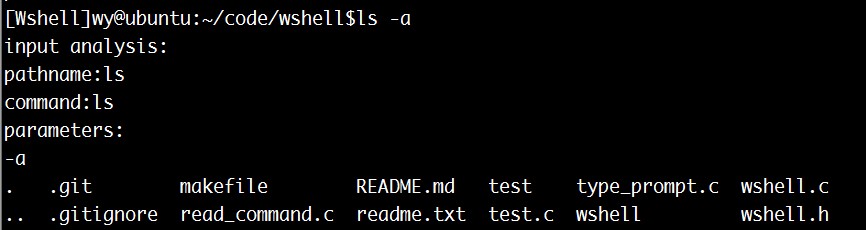
虽然和shell相比,没有颜色区分,但已经可以正常运行了。这两个测试表明,wshell已经初具shell的基本功能。
这个版本对应于github上10.31及以前的提交。
二、改善用户体验:内建命令、readline库
2.1.内建命令(built-in command)
当完成基本功能、喜滋滋地在其中测试各种常用命令时,top、vim等都乖乖就范,唯独cd没有任何效果。本来以为cd只能改变子进程的工作目录,而wshell是父进程,导致无效。然而输入whereis cd来查看cd所在目录,没有显示它的路径,顿生疑惑:cd是怎么实现的?看到stackoverflow上一个问答,解释了这个疑惑:像cd这样的命令实际并非可执行程序,(如果想在自己编写的shell里使用)需要自己来实现为内建命令。那么,对于这种命令,肯定是不能exec()了,需要进行分析和额外处理。而且可以看出,它的执行并不需要建立子进程。
这个分析和处理过程,实际上应该是解释器的一部分功能,当然这里比较简化,只是针对特定的命令进行处理罢了。这个过程由buildin_command()完成,并且不创建子进程。因此,主进程相应地添加
if(buildin_command(command,parameters)) continue;
接下来实现几个内建命令。最简单的是exit和quit,直接调用exit()结束wshell主进程即可。
顺便编写一个about命令,这是我自己添加的,shell本身是没有这个命令的,它会显示一些关于wshell的简短信息。
接下来是cd的实现了。对于以下几种使用方法,使用chdir()就可以直接完成对应的操作:
cd
cd PATHNAME
cd .
cd ..
但是对于cd ~以及cd ~/PATHNAME就不行了。对于这种情况,可以发现这个路径的特点是以“~”开始,那么利用type_prompt()中的获取工作目录的方式,重新拼接出完整路径再作为参数进行传递即可。为了提高效率,把type_prompt()中获取的信息做成是全局的,这样实现cd时可以直接调用。
chdir()的出错处理也从简了,直接把strerror的内容显示在屏幕上。如果想建立一个比较完善的错误处理机制,可以参考《UNIX网络编程(卷一)》(UNPv1)的附录D.3。
甚至可以发现,shell本身似乎也是用对"~"路径补全的方式来实现的,这可以通过cd一个不存在的目录所表现的行为发现:
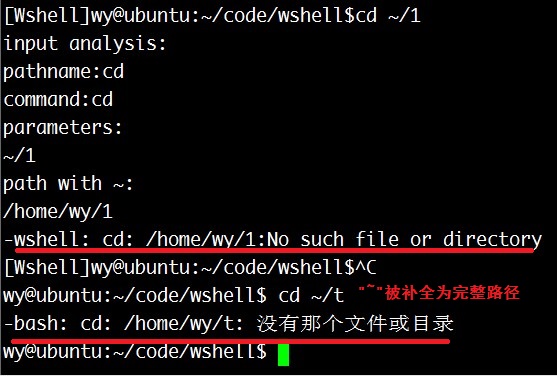
这一天发现最初的版本没有对分配的内存进行回收,可能导致内存泄漏。打算重写这一部分代码,使其更接近于Linux内部实现。
2.2 readline库的使用以及read_command()的重写
在1.3节提到,read_command()的行为和真实的shell命令输入不一样,后者是基于readline库实现的。让wshell也是用这个库,就可以做出同样的行为了。正好之前发现了原先的read_command()处理command和parameter两个参数时没有释放,会导致内存泄漏,这里重写一下。为了便于理解,下图是前后二者的区别:

使用后者,不必每次为command和parameter[][]分配空间,只需要一个足够大(也就是ARG_MAX大小)的buffer即可,不必操心内存分配的问题了。同时,由于后者中参数的定位全部是由指针完成,在添加更多的功能(后文的重定向、pipe)也会更加方便。这种实现我不确定是否为bash的实现,但看上去更接近于“所有参数总长度限制为ARG_MAX”的设定。改写之后,代码也比之前精简不少。
回到本节正题上来,看看readline库是怎么使用的。
首先,这个库是需要安装的,我所使用的Ubuntu10.04上默认并没有安装这个库。执行下面语句进行安装:
sudo apt-get install libreadline5-dev
同时为了便于以后调试的方便,同时提供了两个版本的read_command(),使用READLINE_ON来控制编译时是否选择使用了readline库的版本,并在对应的makefile中加上-D READLINE_ON -I /usr/include -lreadline -ltermcap。
直接使用
buffer = readline(NULL);
这时,似乎已经很接近shell的用户体验了。但是使用退格键消除所有字符后,发现居然连着提示符也消失了。看来,type_prompt()也需要重写了:把完整的提示符字符串作为参数传递给readline()。
这样之后,就能模仿shell的输入体验,甚至可以进行命令补全和路径补全。不过想实现历史命令还是不行,可以参考使用readline库实现应用程序下的仿终端输入模式等。
这一节内容完成后,对应于github上11.1提交的版本。
三、进阶功能:后台执行、输入/输出重定向、pipe
3.1 准备工作
有了前面的经验,这些功能看上去无非也就是利用一些Linux的库函数、系统调用等API完成的嘛。不过麻烦的地方在于,如何从用户输入中判断使用哪一种或哪几种功能?这似乎又绕不过句法分析这一步,因此继续简化设计,首先把一个合法用户输入规定为下面的形式:
command1 [[parameter1_1] ... [parameter1_n]] [<</< file1] [>>/> file2] [| command2 [parameter2_1] ... [parameter2_n]] [&]
并作出规定:
1.一个正确输入只能为上面的形式,一共可以有20个单元,长度为MAXLINE大小,非法输入的执行结果是未定义的;
2.当输出重定向>>/>和管道符|同时出现时,command1的输出只会重定向至file2,这样之后才执行command2;
3.无论是否出现command2,"&"只对command1有效,且必须与前一个可选项中有一个空格(bash可以直接使用"ls&"这样的命令,但在这里只能写成"ls &")
这样,就可以专注于处理合法输入的情况了。当然,一个健壮的解释器肯定是需要处理异常输入的。
对于输入的句法分析结果,使用一个结构体来进行保存,以便接下来的使用。这个结构体如下:
struct parse_info { int flag; //表明使用了哪些功能的标志位 char* in_file; //输入重定向的文件名 char* out_file; //输出重定向的文件名 char* command2; //命令2 char** parameter2; //命令2的参数表 };
编写句法分析函数parsing()来填充这个结构体,以备后续使用。
以下各节的实现(API的选取)参考了《UNIX操作系统设计》7.8节 shell部分,主干如下,在理解了1.1节介绍的《现代操作系统》上的shell框架之后,下面无非在这个框架里面加了点东西而已。不过这个框架似乎不适合我原先写的代码,需要进行调整。
/*read command line until EOF*/ while(read(stdin,buffer,numchars)) { /*parse command line*/ if(/* command line contains & */) amper = 1; else amper = 0; /* for commands not part of the shell command language */ if(fork() == 0) { /* redirection of IO?*/ if(/* redirect output */) { fd = creat(newfile,fmask); close(stdout); dup(fd); close(fd); /* stdout is now redirected */ } if(/* piping */) { pipe(fildes); if(fork() == 0) { /* first component of command line */ close(stdout); dup(fildes[1]); close(fildes[1]); close(fildes[0]); /* stdout now goes to pipe */ /* child process does command */ execlp(command1,command1,0); } /* 2nd command component of command line*/ close(stdin); dup(fildes[0]); close(fildes[0]); close(fildes[1]); /* standard input now comes from pipe */ } execve(command2,command2,0); } /* parent continues over here ... /* waits for child to exit if required */ if(amper == 0) retid = wait(&status); }
3.2 后台运行
这个比较简单,让父进程不等待子进程退出而直接读入用户的下一步操作即可,不执行wait()。为了进一步模拟shell,可以把子进程ID显示出来。
(2014.4.14更新)
注意,对于后台运行的子进程,如果父进程提前退出了,自然会成为init进程的孩子;而如果这些子进程在父进程退出前退出,又没有对应的waitpid()进行回收,就会成为僵尸进程。使用signal()处理SIGCHLD可以解决这个问题,并且由于Linux的信号是不排队的,需要将所有的已结束的子进程进行回收。
但是,仅仅增加一个信号处理函数,对于前台运行的进程,waitpid()阻塞过程是否会失效?为了让这两种waitpid()不相互干扰,把后台运行进程的pid放入一个专门的数组中,信号处理函数只对这一类进程进行处理。对于不是后台运行的子进程,在信号处理函数什么也不做就返回后,使用指定了其pid的waitpid()处理。
3.3 输入/输出重定向
因为重定向只适用于用户输入中的command1,一旦判断出有command2的存在,就应该着手分离二者了,否则会导致二者的输入/输出都被重定向到同样的文件上去。
不过要注意,虽然'>'和'>>'都是输出重定向,前者会覆盖原有文件内容,而后者是在文件尾部增加,需要进行简单的分别对待。(12.8更新)
先利用flag的IS_PIPED标志位判断是否需要为command2创建新进程,内容暂略,先利用dup2()把重定向功能写好,下面只写出了输入重定向,输出重定向是类似的:
if(info.flag & IS_PIPED) //command2 is not null { if(fork() == 0)//command2 { //pipe //execvp(info.command2,info.parameters2); } } int in_fd,out_fd; if(info.flag & IN_REDIRECT) { in_fd = open(info.in_file, O_CREAT |O_RDONLY, 0666); close(fileno(stdin)); dup2(in_fd, fileno(stdin)); close(in_fd); } if(info.flag & OUT_REDIRECT) { out_fd = open(info.out_file, O_CREAT|O_RDWR, 0666); close(fileno(stdout)); dup2(out_fd, fileno(stdout)); close(out_fd); } execvp(command,parameters);
3.4 管道
直接使用pipe()就可以了,管道的写法没什么特别,不过对于同时使用了输出重定向和管道的command1,需要把它的管道关闭,这样就会给command2发送一个EOF。
3.5 模仿,再模仿……
使用系统自带的wc,并随便编写个1.txt,测试目前的版本吧。

看上去怎么就那么别扭呢?对比一下,下图是真实的shell的行为:

这个问题的原因我尝试了很久才想明白:第二个wc是第一个wc的子进程,而wshell最多只等待第一个wc,不等后一个进程结束就显示下一行提示符了!
首先想到两种解决办法:
(1)wait()/waitpid()。但发现Linux本身的wait()/waitpid()函数不能处理子进程的子进程,同时command1在执行时就被替换成了wc,不能让它执行wait()/waitpid();
(2)改变command2的父进程ppid使其为wshell的pid。但没有查到可以完成的API。
因此,只好根据(1)的思路进行修改,为了能使用wait()/waitpid(),唯一的方法是让command1和command2都是wshell的子进程了。这样修改需要改变一部分已有逻辑关系,不过为了追求高仿,还是进行了。
修改完再试试:

嗯,还不错,这样修改后,甚至可以为command2也配置出"&"了。
这一节对应于github上11.3提交的版本。
四、总结
4.1 和真实的shell相比,有什么不足
- 暗藏了不少bug是肯定的,毕竟调试次数还是很少;
- 内建指令不全,只实现了最常用的cd,作为示例,姑且算是足够了吧;
- 不能执行shell脚本、用户命令分析模式单一,这都是没有编写完整解释器的缘故。以前本科编译原理实验课的时候写过还算完整的一个小语言的词法分析和句法分析器,那时就写的有点吐血。当然,正则表达式这样高端的功能更是别想了。如果真写起来shell的解释器,代码量绝对比上文中的shell多。这个shell只用parsing()来替代了这部分功能;
- 异常处理机制不够健全,只有少数的异常处理,并且对不正确的用户命令也无法处理,部分还是因为解释器,另一部分是因为示例程序,我对它的健壮性就偷懒了不少;
- shell机制没模仿全,只有管道、重定向、后台执行——如果加其他功能,同样是需要扩充解释器的;
- 命令行没有历史命令,这是readline库的特性,我没有加上;
- 一些可能的性能优化没有进行,因为主要目的是展示原理,关于性能没有再做深入思考。
4.2 收获
- 练习了Linux的一些API(主要是进程相关API)的使用,深入了解或动手实现了一些机制
- 不再对shell感到神秘莫测:你也可以实现一个嘛!
- 第一次练习使用git/github
作者:五岳
出处:http://www.cnblogs.com/wuyuegb2312
对于标题未标注为“转载”的文章均为原创,其版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

