


爬取关键词相关图片
需求
看到抖音上有人展示的一个小应用,输入任意一个关键词,自动保存网络上的相关图片。出于兴趣,我也来试试。
工具
编程语言:Python
IDE:PyCharm
思路
要完成这个需求,第一想法就是借助百度图片先把相关图片搜出来,然后用Python保存页面上的图片。
实现
明确了思路后,就动手写代码。
# -*- coding:utf-8 -*-
import re
import requests
import os
def download_pic(html, keyword):
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
i = 1
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
file_path = 'F:/images/' + keyword
if os.path.exists(file_path):
print()
else:
os.mkdir(file_path)
for each in pic_url:
print('正在下载第' + str(i) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=5)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
pic_dir = 'F:/images/' + keyword + '/' + keyword + '_' + str(i) + '.jpg'
fp = open(pic_dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__ == '__main__':
word = input("请输入关键词: ")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip'
result = requests.get(url)
download_pic(result.text, word)
问题及解决方法
问题:控制台报如下错误
Traceback (most recent call last):
File "F:\Python_Projects\WordCloudTest\GrabPics\Demo1.py", line 39, in <module>
result = requests.get(url)
File "F:\Python_Projects\WordCloudTest\venv\lib\site-packages\requests\api.py", line 76, in get
return request('get', url, params=params, **kwargs)
File "F:\Python_Projects\WordCloudTest\venv\lib\site-packages\requests\api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
File "F:\Python_Projects\WordCloudTest\venv\lib\site-packages\requests\sessions.py", line 542, in request
resp = self.send(prep, **send_kwargs)
File "F:\Python_Projects\WordCloudTest\venv\lib\site-packages\requests\sessions.py", line 677, in send
history = [resp for resp in gen]
File "F:\Python_Projects\WordCloudTest\venv\lib\site-packages\requests\sessions.py", line 677, in <listcomp>
history = [resp for resp in gen]
File "F:\Python_Projects\WordCloudTest\venv\lib\site-packages\requests\sessions.py", line 166, in resolve_redirects
raise TooManyRedirects('Exceeded {} redirects.'.format(self.max_redirects), response=resp)
requests.exceptions.TooManyRedirects: Exceeded 30 redirects.
解决方法:定义headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3760.400 QQBrowser/10.5.4083.400',
}
完整代码
# -*- coding:utf-8 -*-
import re
import requests
import os
def download_pic(html, keyword):
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
i = 1
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
file_path = 'F:/images/' + keyword
if os.path.exists(file_path):
print()
else:
os.mkdir(file_path)
for each in pic_url:
print('正在下载第' + str(i) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=5)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
pic_dir = 'F:/images/' + keyword + '/' + keyword + '_' + str(i) + '.jpg'
fp = open(pic_dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__ == '__main__':
word = input("请输入关键词: ")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3760.400 QQBrowser/10.5.4083.400',
}
result = requests.get(url, headers=headers)
download_pic(result.text, word)
成果
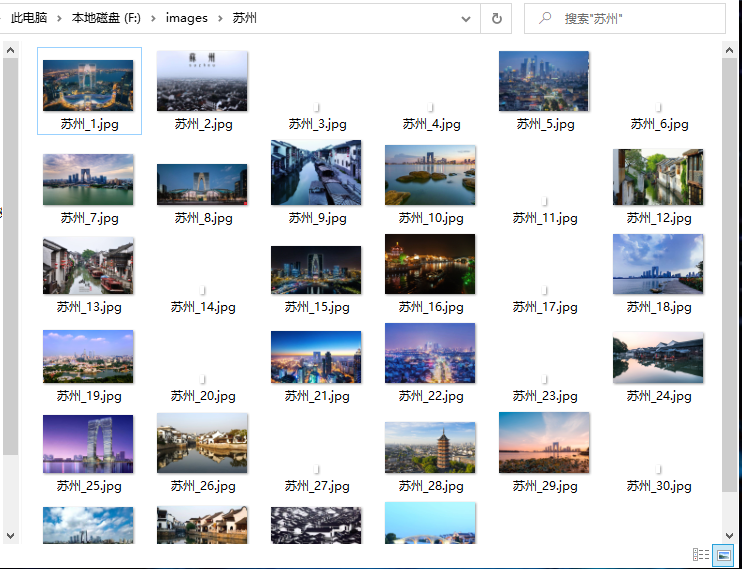
执行程序,输入关键词“苏州”,程序就会将爬取到的图片存入指定路径。
从下图可以看到,有些图片无法显示。猜测原因可能是这些图片的源地址已经失效,具体是为什么暂时不明。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号