
大模型推理服务杂谈
回顾一下大模型推理服务方法, 层级式地说明这些方法, 实例优化、集群扩缩容策略 等等。
实例优化: 模型的部署, 主要是当单卡内存有限, 把模型参数分布到不同卡上的方法。连续请求调度, 通过预测解码长度, 对批处理优先级进行调度, 较短的请求优先处理减少整体的时延。动态批处理主要处理解码过程中请求的 插入和 驱除。 KV Cache 减少冗余计算, 持续解决存储效率、重用策略、压缩方法。由于预填充和解码阶段的明显不同, 引入分离架构, 分别优化每个阶段。
集群优化: 专注于部署策略, 尤其是高性价比的GPU集群配置, 使用异构硬件, 进行服务的集群调度。动态扩缩容引入负载均衡, 以防资源未充分利用, 或不同实例过载。本地硬件基础架构不足以支持部署要求时, 云服务方案解决动态大模型服务的需求。
新兴场景: 包括长上下文处理, 检索增强生成 RAG, 混合专家 MoE, 低秩分解 LoRA, 推测解码 Speculative Decoding, 增强大模型 Augmented LLM, 域适应测试推理 Test-Time Reasoning。
其他杂项: 包括 硬件, 私有化, 公平, 功耗 等。
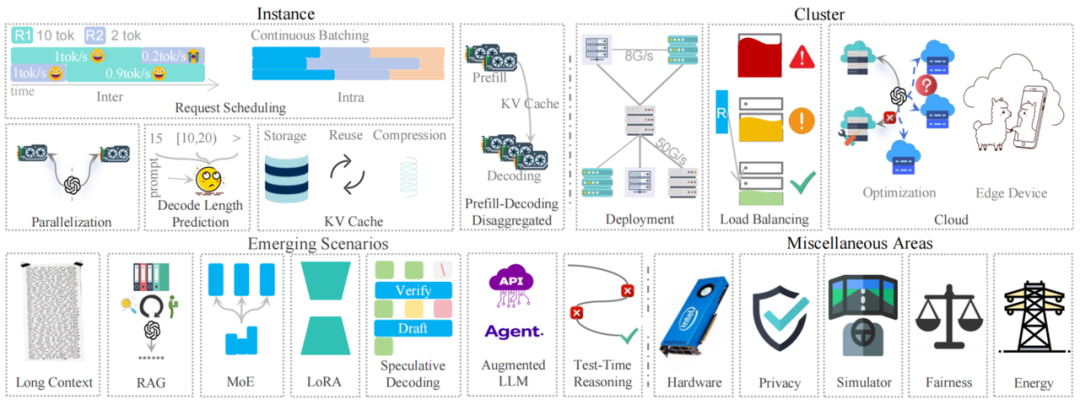
大模型巨量参数, 注意力机制高计算量要求, 对大模型推理服务的低时延和高吞吐量的要求提出了挑战。整个行业在这个方向上的工作也有了很多进展, 加速了这个领域的发展。包括基础的 运行实例级的方法, 集群级别的策略, 新兴场景, 还有其他重要的功能。
-
实例级别, 包括模型推理, 请求调度, 解码长度预测, 存储管理, PD分离方案。
-
集群级别, 包括 GPU 集群的部署, 多实例负载均衡, 云服务解决方案。
-
新兴场景, 包括长文本, RAG, MoE, LoRA, Speculative Decoding, Test-Time Reasoning。
-
重要功能, 包括 硬件, 模拟器, 公平。
添加图片注释,不超过 140 字(可选)
主要介绍 实例, 集群, 新兴场景, 其他功能。请求间调度 R1(10个tokens), R2(2个tokens) 同时到达。忽略了预填充阶段, 如果 R1先处理, 生成效率是 1 tok/s, R2 是 0.2 tok/s。更改顺序 R2 是 1 tok/s, R1 是 0.9 tok/s。默认解码速度是 1 tok/s。
1 Transformer 大模型
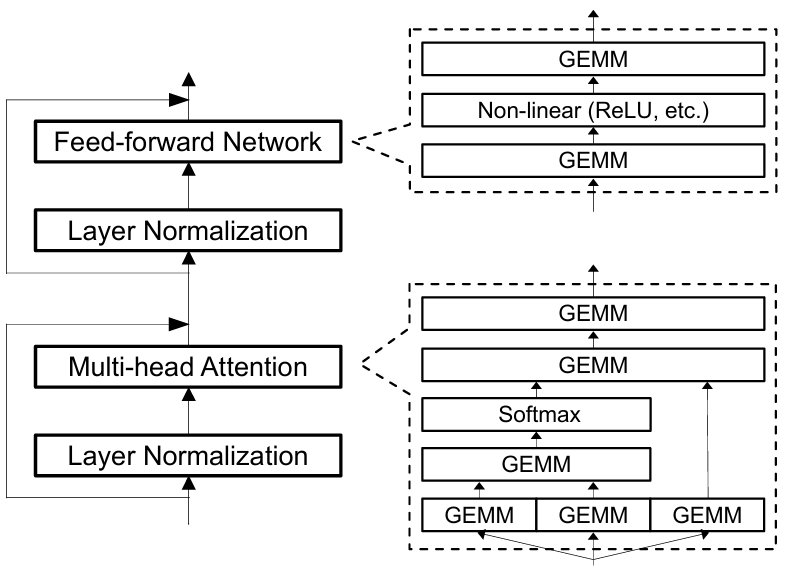
Transformer 架构大模型由多层网络层组成, MHA 多头自注意力模块, FFN 前馈网络模块, LayerNorm 层归一化模块。用户输入文本, 使用 tokenizer 转换成词元 token, 加入位置信息, 通过可训练的权重矩阵 WQ, WK, WV 计算出 对应的 query (Q), key (K), value (V) 向量, 作为 后续 MHA 多头自注意力模块的输入。多头注意力模块的多头分别单独并行计算, 把计算结果连接起来; 再和 WO 权重矩阵计算得到注意力模块的输出结果。前馈网络层 FFN 使用两个线性转换进行计算。
添加图片注释,不超过 140 字(可选)
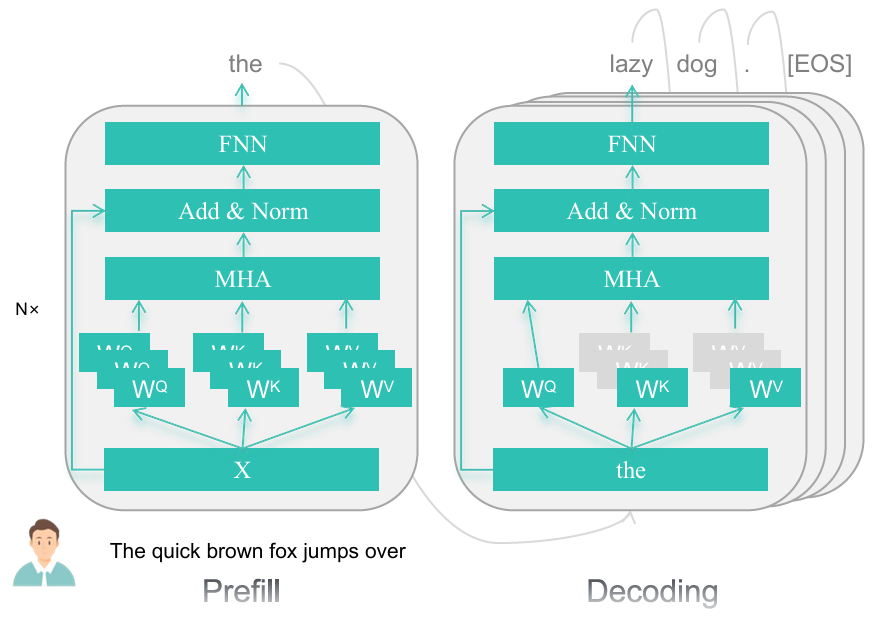
大模型的推理分为2个主要阶段: 预填充和解码。
添加图片注释,不超过 140 字(可选)
预填充阶段模型处理整个输入, 计算束缚的前向计算, 生成第一个词元 token, 缓存 K 和 V (KV cache) 避免 重计算。解码阶段, 使用 KV cache 连续生成 词元 tokens, 随着内存使用的增加, 减少了计算耗时。每个新词元 token 输入模型后, 就会计算 Q, K, V, 确保高效生成, 生成 [EOS]时结束。
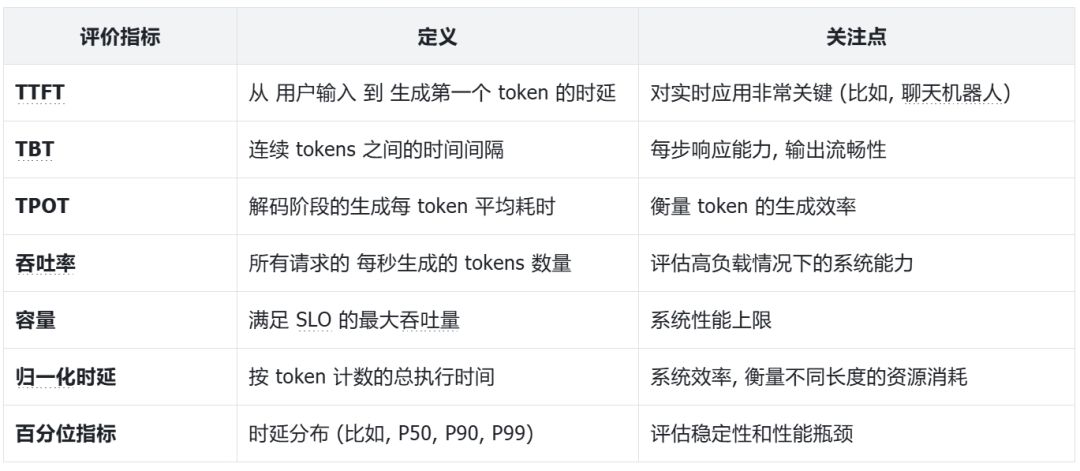
常用的性能统计方法如表所示:
添加图片注释,不超过 140 字(可选)
2 大模型推理服务

添加图片注释,不超过 140 字(可选)
模型分解部署: 单卡可能放不下大模型大量权重参数, 需要分布到多卡上 或 卸载到 CPU 上计算, 是很常见的实践方法。
模型并行: 流水线并行方法, 如 GPipe, PipeDream, Megatron-LM 把不同的模型网络层分布到不同设备上, 可以并发处理顺序流动的数据, 加速训练和推理。张量并行, Megatron-LM 切分算子或网络层, 比如矩阵乘, 变成更小的张量, 在多个设备上并行计算, 加强了计算效率, 模型维度可以变得更大。序列并行 sequential parallelism, 对于长上下文任务, 把 layernorm 和 dropout 激活层沿序列维度切分。上下文并行 context parallelism 扩展了这个方法, 把所有网络层都沿序列维度切分。专家并行 expert parallelism 把稀疏的 MoE 组件分配到多个 GPU 上, 针对稀疏大模型 优化了内存使用。
卸载 offloading: 计算资源有限, 有效利用 GPU 和 CPU 就非常必要了。ZeRO-Offload, DeepSpeed-Inference, FlexGen 都是把模型的主要权重存储在内存或存储中, 只按需加载必要的部分到 GPU 内存中。PowerInfer GPU-CPU 混合引擎 预加载热点神经元到 GPU 上进行加速, 在 CPU上计算 非常用神经元, 减少了GPU内存使用和数据传输。TwinPilots 计算方案在一个非对称多进程框架中, 整合了 两种计算引擎 GPU 和 CPU, 使用了层级内存结构 GPU 和 CPU 内存。 Throughput-oriented LLM Inference 方案通过 动态的、细粒度微调负载分配, 有效利用了计算资源。
3 请求调度
单卡上的请求调度会直接影响时延的优化。调度相关算法包括请求内和请求间调度。
请求间调度: 连续请求数量较大时, 对请求的数据批的优先级进行排序, 主要是执行顺序。主流方案采用先进先服务 FCFS (First Come First Served)策略。这个策略有局限, 把先进来的长序列请求排在短请求的前面, 会延迟短请求的处理, 增加了端到端的时延, 也就是队头阻塞问题。优先处理短请求 可以都满足大家的服务质量。解码长度预测 decoding length prediction 可以优化请求调度。FastServe 引入 MLFQ(Skip-Join Multi-Level Feedback Queue) 调度器, 设置不同优先级队列, 对高优先级请求排序, 评估等待较长的请求, 抢占长时运行的请求, 加速较短的请求。SJF (Shortest Job First) 基于较短请求预测解码时间, 对请求进行排序。SRTF(Shortest Remaining Time First) 动态预测解码长度, 边解码边预测长度, 引入独占率, 避免过度抢占长序列请求。但这个方法可能会要求每次迭代都要运行长度预测模型, 增加相关的开销。预填充/解码分离架构 Prefill-Decoding separated , 在 预填充阶段采用了SJF 方法, 在解码阶段使用了 Skip-Join MLFQ 方法。InferMax 通过推理 cost-model 进行策略性抢占, 相比非抢占方法, 减少了 GPU 成本。BatchLLM 对全局共享的正在处理的请求进行优先级排序。
请求内调度: 请求内调度对并发请求的不同批, 进行调度, 针对 请求到达时间, 完成时间, 输出长度, 提高并行解码效率。Orca 对解码迭代过程进行调度, 每次生成时动态添加和移除请求, 比请求间调度更有弹性。Dynamic SplitFuse 和 Chunked-prefill 把 预填充切分成更小的模块, 在解码阶段再把它们合并, 减少长提示词的时延, 避免在预填充的时候暂停解码过程。SCLS(slice-level scheduling)把最大的生成长度分解成固定长度的片段, 分别顺序处理, 精确控制服务时间和内存使用。
4 解码长度预测
大模型解码生成长度的不确定性, 使得请求调度也具有挑战性。
预测解码长度, 可以分为3类:
精确预测长度, 精确地预测生成 token 的数量。Magnus 使用 BERT embedding 和 随机森林回归, 关联任务类型和生成长度。TetriInfer 使用了OPT小模型。SSJF 使用的是简单的回归模型。
长度范围分类, 这类方法 把请求长度分成直方图。Response length perception and sequence scheduling 使用监督式微调训练模型预测给定提示词长度的解码长度。对长度分类,S3 和 Intelligent Router for LLM Workloads 使用 DistilBERT 分类器, 把长度分为 短/中/长 直方图。 µ-Serve 使用 FFN 处理 BERT 的 CLS, 使用 5% 分组进行微调。 Trail 对 token embeddings 使用轻量分类器, 达到了实时性能, 与 Syncintellects 类似。
预测相对位置, 这类方案预测请求间的相对关系。speculative shortest-job-first (SSJF) scheduler 对比了回归、分类、配对方法, 查找每个适合的数据/模型对。Efficient LLM Scheduling by Learning to Rank 只使用输入请求 预测同一个批内的请求的相对关系, 增强了健壮性, 减少了过拟合。相对排序预测, 更直觉, 它只要求决定同一个批次中的请求顺序。但是,如果一些请求延续到下一批,则必须重新计算它们的排名,从而引入额外的开销。SkipPredict 把任务分成短或长, 对短的进行优先级排序, 长任务后面再排序。BatchLLM 基于输入提示词 和 统计的模式进行预分析, 再预测解码长度。除了预测长度之外, Predicting LLM Inference Latency: A Roofline-Driven ML Method 使用 roofline 方法 预测推理时延。
5KV Cache 优化
KV Cache 重用 把推理的时间复杂度从二次转变成线性。主要面临的挑战是 内存管理, 计算重用, 压缩效率。
内存管理: 无损存储技术中, 使用了 PagedAttention, vLLM 使用 操作系统中的分页机制实现内存分块方案, 近乎零空间浪费。DistAttention 对 KV Cache 进行分布式处理, 处理更长的上下文。FastDecode 通过分布式处理, 把 cache 卸载到 CPU 内存上, LayerKV 基于网络层级, 使用层级式分配和卸载。KunServe 删除部分模型参数释放缓存空间, 通过其他实例上的流水线机制进行复原, Symphony 使用多轮交互模式 动态减少 caches 使用。InstCache 通过大模型指令预测 强化了响应。PQCache 使用低开销的 笛卡尔积量化 Product Quantization (主要应用在 embedding 提取中), 把 embedding 切分成更小的子模块, 对 子模块进行聚类减少计算开销。InfiniGen 是动态 cache 管理框架, 减少了数据搬运开销, 通过 KV cache 的智能存取,增强了性能。
重用策略: PagedAttention 无损重用策略 使用页表式管理方法, 可以共享多个请求的 cache。Radix treed-based 系统, 对动态节点删除, 实现了全局 prefix 共享。CachedAttention 重用多轮缓存, 极大减少了对话中的冗余计算。语义感知重用策略 GPTCache 使用与 Cache 相似语义, 重用大模型输出; Scalm 对请求进行聚类, 挖掘有价值的语义模式。对比 无损重用 与 语义匹配策略, 前者 对 确定的模板输入非常有作用, 比如 法律知识, 医疗知识, 代码生成 应用。后者更适合开放性问题对话。
压缩技术: 权重 和 cache 压缩技术 特指张量量化, 使用压缩表示, 平衡性能和效率。量化压缩从高比特转换成低比特精度, 减少内存使用。FlexGem 使用 group-wise 量化, 把 KV cache 压缩到 4bit。Kivi 提出 cache per-channel / token 量化, 根据这些维度把元素分组。MiniCache 寻找相邻 网络层高相似度 KV Cache , 对层间 cache 进行压缩。AWQ 量化分析模型激活值分布特征, 动态识别不同权重对模型输出的敏感度差异, 减少量化损失。Atom 采用混合精度通道重排, 移除离群点, 细粒度分组量化。对权重和激活值都进行量化减少量化误差损失, 动态量化激活, 更好地捕获每个输入的分布。KV cache 量化减少了内存搬运。QServe 使用算法协同设计, 把大模型量化到 W4A8KV4 精度, 改善了 GPU 利用率。压缩编码架构 希望使用更小的矩阵表示较大矩阵。CacheGen 定制张量编码器 压缩 KV cache 成压缩比特流, 节省带宽, 解码开销最少。
6PD分离
PD 分离把大模型推理计算分解成预填充/上下文编码 context encoding, 计算约束型, 解码过程也就是生成词元 token generation 内存约束的, 分别进行优化。
DistServe 优化了资源分配, 流水线并行, 基于带宽策略性分配, 最小化通信开销。Splitwise 使用了同构和异构设备设计优化成本、吞吐量、功耗。DéjàVu 解决了双峰延迟导致的流水线气泡, GPU使用不平衡, 从 microbatch 交换 和 状态复制 缓慢恢复。Mooncake 使用了 KVCache 为中心的分离架构, 利用了 空闲 CPU , DRAM , SSD 资源进行分布式 KV cache 存储, 高负载减少浪费。TetriInfer 使用两级调度算法, 资源预测避免解码瓶颈。P/D Serve 细粒度组织 预填充/解码, 动态调整, 按需分配请求, 高效 cache 传输。
Mooncake 架构的分离设计是基于 KVCache 调度和优化。Prefill 阶段主要目标是尽可能重用KVCache 避免冗余计算。但 存储 KVCache 时, 会降低 TTFT 服务等级。大量KV-Cache传输导致网络拥挤, 延长等待时间。
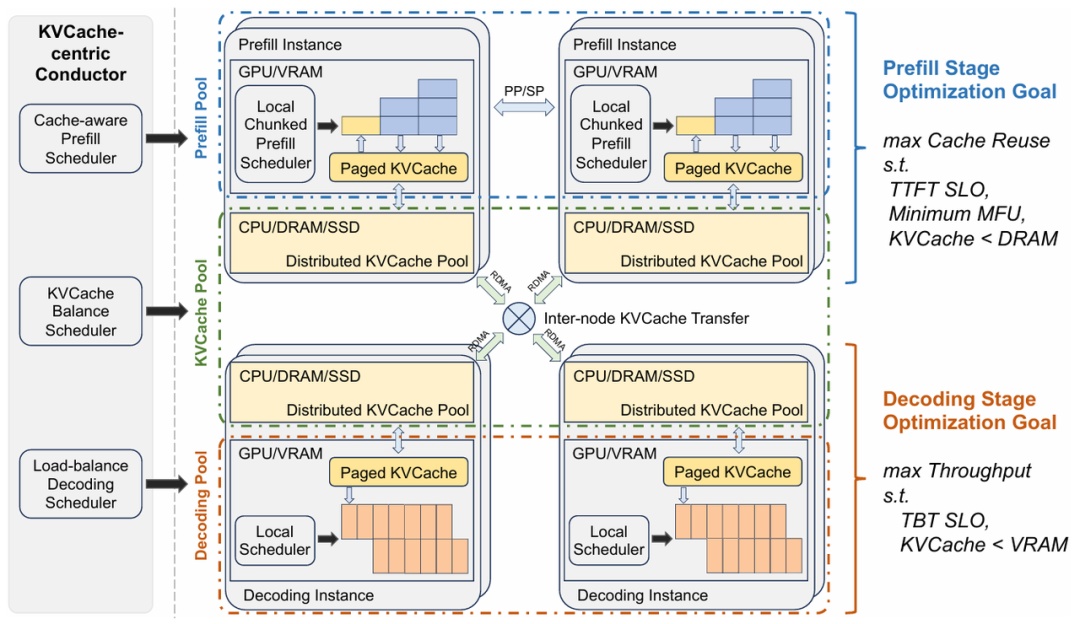
添加图片注释,不超过 140 字(可选)
以Llama2-70B dummy 模型为例。prefill 阶段在 batch=1时, 时延随着sequence length 增长, 呈线性增长。decode 阶段 sequence length 和 batch size 对比如下图。
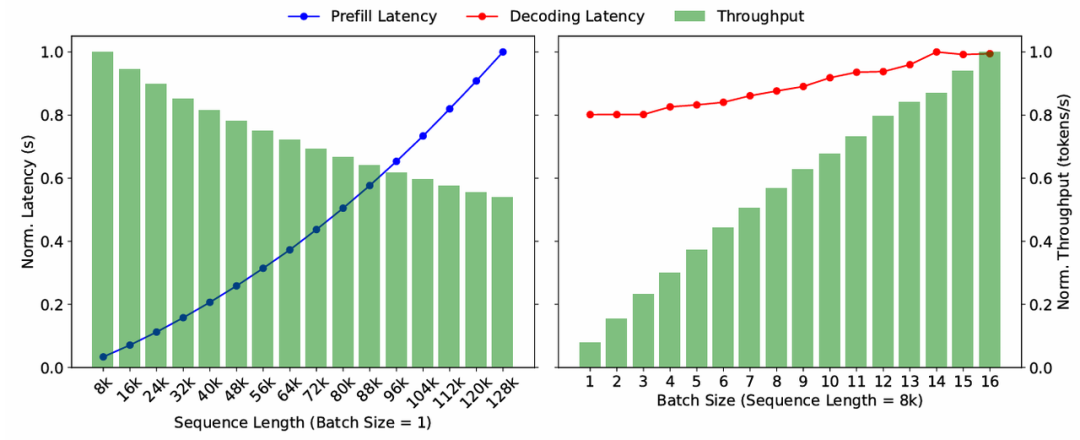
添加图片注释,不超过 140 字(可选)
Mooncake 不仅分离 prefill 和 decoding 节点, 还把 CPU, DRAM, SSD, RDMA, GPU 集群资源分组, 实现 KVCache 分离。
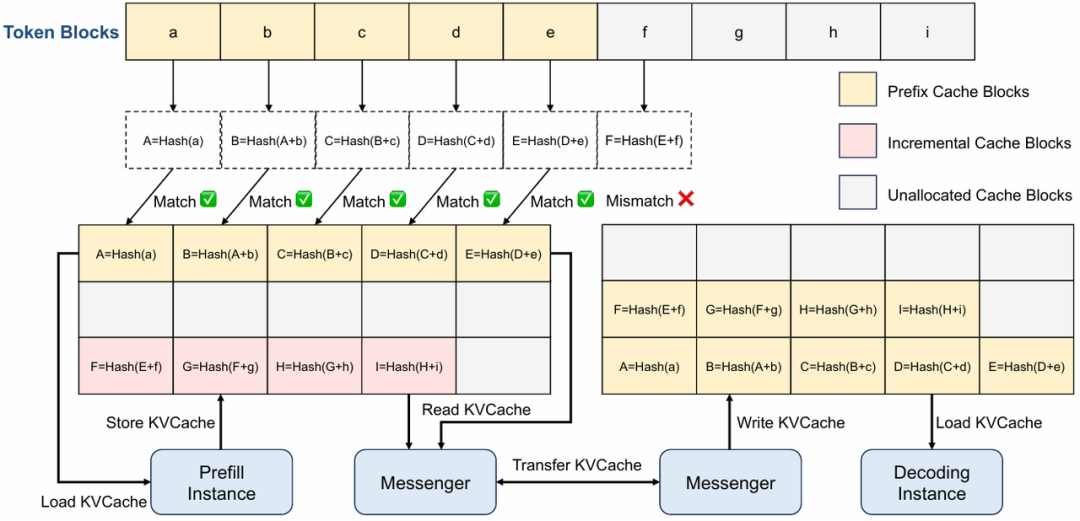
添加图片注释,不超过 140 字(可选)
图中演示了CPU 内存中的 KVCache pool。每个 block 都带有一个 hash 值由自己的 hash 和 prefix 决定,用于去重。上图演示了 KVCache blocks 的存储和传输 逻辑。CPU 内存中 KVCache 存储为 paged blocks。
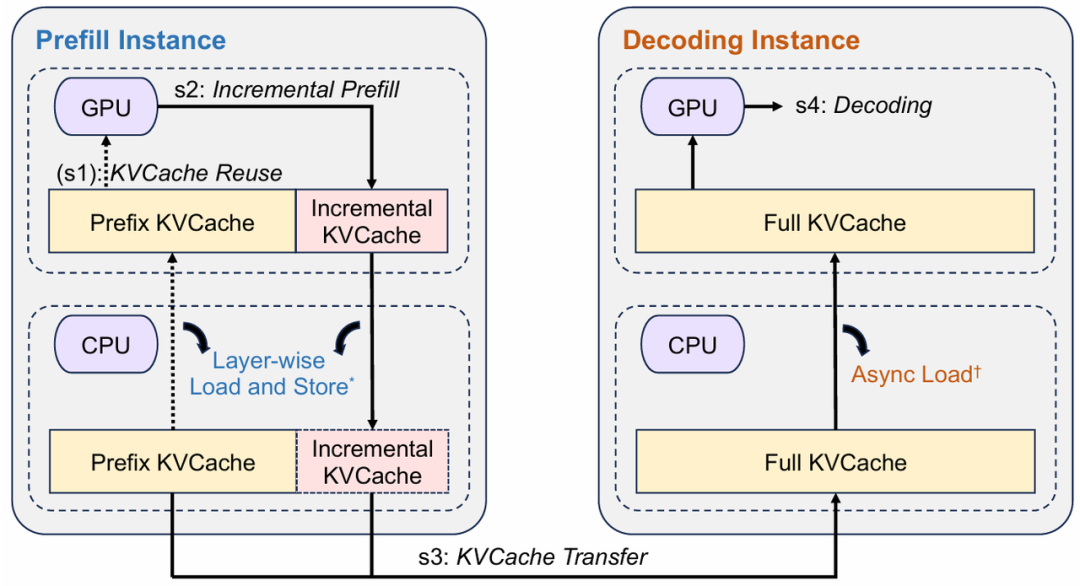
添加图片注释,不超过 140 字(可选)
上图是推理实例的工作流程。
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号