TextRank
在PageRank上的启发
当一个节点连接到另一个节点时,相当于给另一个节点投票。节点票数越高,节点重要性越高
节点得分基于票数和投票的点的得分
定义\(G=(V,E)\)是一个有向图,\(V\)是节点集合,\(E\)是\(V\times V\)边集合(可以看成一个连接矩阵)
\(In(V_i)\)为指向节点\(V_i\)的节点集合,\(Out(V_i)\)为节点\(V_i\)指向的后续节点集合
节点得分计算: \(S\left(V_{i}\right)=(1-d)+d * \sum\limits_{j \in I n\left(V_{i}\right)} \frac{1}{\left|O u t\left(V_{j}\right)\right|} S\left(V_{j}\right)\)
\(d\)为一个(0,1)的阻尼系数,表示指定节点随机跳到其他节点的概率。在页面点击问题中,\(d\)是用户随机点击链接的概率,\(1-d\)是跳转到一个全新页面的概率,\(d\)通常取为0.85
得分计算步骤:
初始化节点得分,迭代计算类似PageRank,直到收敛到低于给定阈值。收敛值不受初始值的选择影响,只有收敛的迭代次数可能不同。每个节点都有一个关联分数。
上述公式是基于有向图的,在无向图中,\(In(V_i)=Out(V_j)\)
网页浏览的PageRank假设是未加权的图,文本数据下使用词语作为节点时,一个节点可以链接到多个节点,即一个词语与多个词语有解释作用,因此可以赋予链接一个权重\(w_{ij}\),\(w_{ij}=\frac{1}{V_j的边数}\),加入权重后修改得分计算公式为:
\(\large W S\left(V_{i}\right)=(1-d)+d * \sum\limits_{V_{j} \in I n\left(V_{i}\right)} \frac{w_{j i}}{\sum\limits_{V_{k} \in O u t\left(V_{j}\right)} w_{j k}} W S\left(V_{j}\right)\)
上述公式和计算步骤都是基于图的方法,TextRank应用在文本数据中的步骤如下:
- 确定节点,比如句子中的词语
- 识别连接这些节点的关系并绘制边,把词语作为节点时,连接可以是有向、无向、加权、未加权的
- 迭代每个节点的分数直到收敛
- 最后根据得分对节点排序
关键词提取中的TextRank
思想:
将单词视为节点。N个单词定义为一个窗口,如果两个单词同时出现在窗口中,则这两个单词是连接的。N可以设置为2-10。
有以下一段句子:
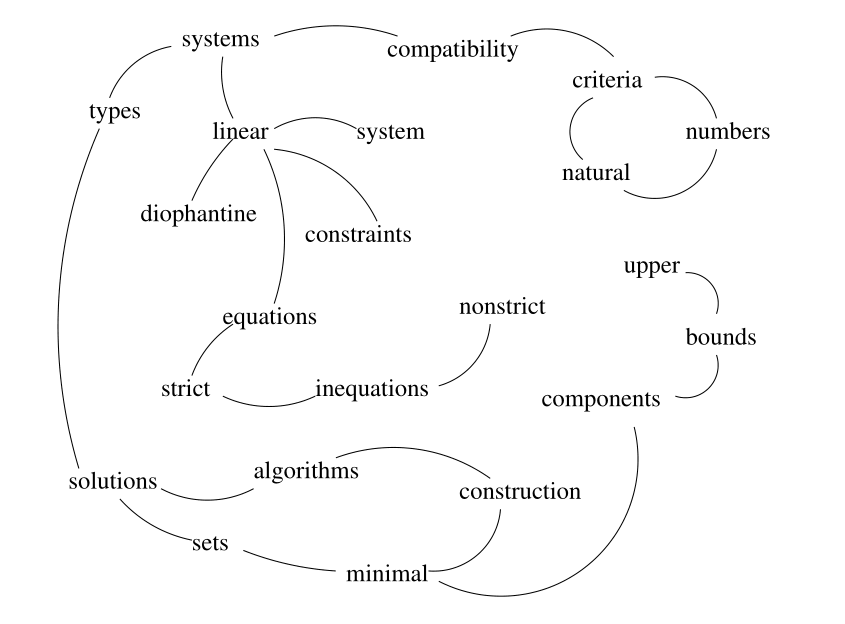
Compatibility of systems of linear constraints over the set of natural numbers.
Criteria of compatibility of a system of linear Diophantine equations, strict
inequations, and nonstrict inequations are considered. Upper bounds for
components of a minimal set of solutions and algorithms of construction of
minimal generating sets of solutions for all types of systems are given.
These criteria and the corresponding algorithms for constructing a minimal
supporting set of solutions can be used in solving all the considered types
systems and systems of mixed types.
Compatibility of systems 出现在一个窗口中,则Compatibility和systems有连接
Criteria of compatibility 出现在一个窗口中,则Compatibility和Criteria有连接
连接图例子如下图:
节点得分计算步骤:
1.构建无向未加权连接图,初始化每个节点的得分为1,由此迭代得分直到收敛,通常20-30次迭代就会收敛,迭代停止阈值一般设为0.0001。
2.得到每个中心节点的得分后,倒序排序,提取出得分最高的5-20个关键字
思考:
窗口越大精度不一定越高,相隔较远的单词之间的关系可能不够强
关键句提取中的TexTRank
句子与句子之间的连接权重用相似度衡量,因此需要一个相似度计算方法
比较简单的想法有,如果两个句子中相同词语越多,那么这两个句子就越相似,有如下公式:
\(S_i\):句子\(i\),\(w_k\):词语
当然也可以使用其他相似度计算方法,例如余弦相似度,BM25
再使用加权计算公式计算每个句子的得分
注意:句子不再使用窗口,认为所有句子之间都是相邻的
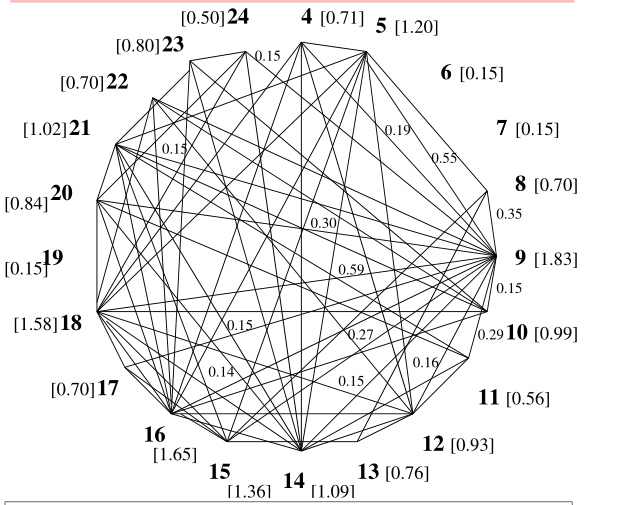
例如有如下文档

则相应的加权图为:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号