Python学习
1、注释
什么是注释
注释就是对代码的解释说明,注释的内容不会被作为代码执行
在前期学习的过程中建议多加注释
今天能看懂的代码,晚上睡一觉明天就不认识了
如何进行注释
单行注释
# 加上注释内容
多行注释
'''
注释内容
'''
"""
注释内容
"""
'''
注释1
"""
对注释1在注释
"""
'''
2、变量
什么是变量
- 变量是用于存储数据值的标识符,可以通过变量名访问和操作这些数据。在程序中,变量就像一个容器,用于存储和管理数据
- 变量就是可以变化的量,量指得是事物的状态。比如人的年龄、游戏角色的等级、金钱等等。
为什么要有变量
- 程序里要有变量,是因为程序经常要处理各种数据,而且这些数据不是一直不变的。
- 比如写一个游戏程序,角色有等级、金币、生命值。如果直接写数字,像
1、100、80,单独看这些数字并不知道它们分别表示什么。写成变量以后就清楚多了:
level = 1
money = 100
blood = 80
这样一看就知道,level 表示等级,money 表示金币,blood 表示生命值。
- 程序运行的时候,数据会不断变化。角色升级了,等级要增加;买了装备,金币要减少;被攻击了,生命值要降低。这些变化都需要有地方保存,变量就是用来保存这些数据的。
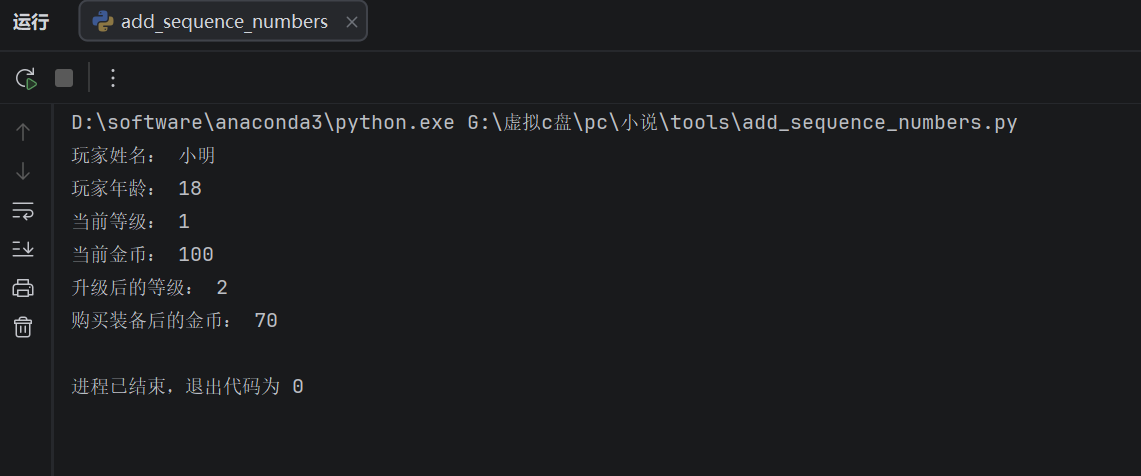
name = "小明" # 玩家姓名
age = 18 # 玩家年龄
level = 1 # 游戏角色等级
money = 100 # 游戏金币数量
print("玩家姓名:", name)
print("玩家年龄:", age)
print("当前等级:", level)
print("当前金币:", money)
# 游戏过程中,角色升级了,金币也发生了变化
level = level + 1
money = money - 30
print("升级后的等级:", level)
print("购买装备后的金币:", money)
变量得定义与调用
在 Python 中,定义变量就是给一个数据起名字,并把这个数据保存起来。写法很简单,一般是:
变量名 赋值符号 变量值
比如:
name = "小明"
age = 18
money = 100
这里的 name、age、money 就是变量名,分别保存了 "小明"、18、100 这些数据。
需要注意的是,Python 里的 = 不是数学里的“等于”,而是“赋值”的意思。也就是说,把右边的数据交给左边的变量保存。
定义好变量之后,后面就可以直接使用变量名,这个过程就叫调用变量。比如:
print(name)
print(age)
print(money)
程序会根据变量名找到它保存的数据,然后输出结果:
小明
18
100
也可以在计算中调用变量:
price = 10
count = 3
total = price * count
print(total)
这段代码中,price 表示单价,count 表示数量,total 表示总价。程序在计算 price * count 时,会自动取出 price 和 count 里面保存的数据,也就是:
$ 10 * 3 $
所以最后输出:
30
可以总结为一句话: 定义变量,就是给数据起名字;调用变量,就是通过这个名字使用变量中保存的数据。
变量的命名规范
变量名不是随便写的,它就像给数据取名字。名字取得好,别人一看代码就能知道这个变量表示什么;名字取得不好,代码虽然可能能运行,但读起来会很费劲。
在 Python 中,变量名一般由字母、数字和下划线组成,但是不能以数字开头。比如下面这些写法是可以的:
name = "小明"
age = 18
student_score = 95
但是下面这种写法是不可以的:
1name = "小明"
- 变量名不能用数字开头。
- 变量名还不能和 Python 已经规定好的关键字重复。比如
if、for、while、class、def这些词在 Python 中本来就有特殊含义,所以不能拿来当变量名。 - Python 对大小写是敏感的。也就是说,
name和Name在 Python 里不是同一个变量:
name = "小明"
Name = "小红"
print(name)
print(Name)
输出结果是:
小明
小红
虽然这样写不会报错,但一般不建议用大小写来区分变量,因为容易看混。
写变量名时,最好做到“见名知意”。比如要表示年龄,就写成:
age = 18
不要写成:
a = 18
虽然 a 也能用,但别人看到 a 并不知道它表示什么。age 就清楚很多,一看就知道是年龄。
命名风格
- 除了要符合基本规则,变量名还要注意命名风格。常见的命名风格有三种:大驼峰命名法、小驼峰命名法和小写字母加下划线命名法。
- 大驼峰命名法是每个单词的首字母都大写
StudentName = "小明"
TotalPrice = 300
- 小驼峰命名法是第一个单词首字母小写,后面的单词首字母大写
studentName = "小明"
totalPrice = 300
- 小写字母加下划线命名法是所有单词都用小写字母,单词之间用下划线连接
student_name = "小明"
total_price = 300
在 Python 中,普通变量更推荐使用“小写字母加下划线”的写法。比如表示学生姓名,写成 student_name 会比 studentName 更符合 Python 的常见习惯,也更容易阅读。
所以,变量命名可以简单理解为:名字要合法,不能以数字开头,也不能使用关键字;名字要清楚,最好能看出它表示什么含义;风格要统一,普通变量在 Python 中一般使用小写字母加下划线的方式来命名。
变量得三大特性
- Python 中变量通常有三大特性:变量值、变量类型、变量内存地址。
变量值
- 变量的第一个特性是值。值就是变量里面保存的具体数据。
age = 18
name = "小明"
print(age)
这里 age 这个变量保存的值是 18,name 这个变量保存的值是 "小明"。我们调用变量时,本质上就是在使用它保存的这个值。
变量类型
- 类型表示这个变量保存的数据属于哪一类。比如
18是整数类型,"小明"是字符串类型。可以用type()查看变量的数据类型。 - 初学 Python 时,常见的八大数据类型
age = 18 # int,整数
height = 175.5 # float,小数
is_student = True # bool,布尔值
name = "小明" # str,字符串
scores = [90, 85, 88] # list,列表
point = (10, 20) # tuple,元组
hobbies = {"篮球", "跑步"} # set,集合
student = {"name": "小明", "age": 18} # dict,字典
print(type(age))
变量内存地址
- 地址可以理解为这个数据在计算机内存中的位置。
- 变量名只是一个名字,真正的数据会存放在内存中。可以用
id()查看变量指向的数据地址:
age = 18
print(id(age))

- 每一次运行代码得时候都会重新开辟内存空间,存储变量值
应用场景
最常见的场景是:判断两个变量是不是指向同一个对象。
a = [1, 2, 3]
b = a
print(id(a))
print(id(b))
print(a is b)
运行结果:
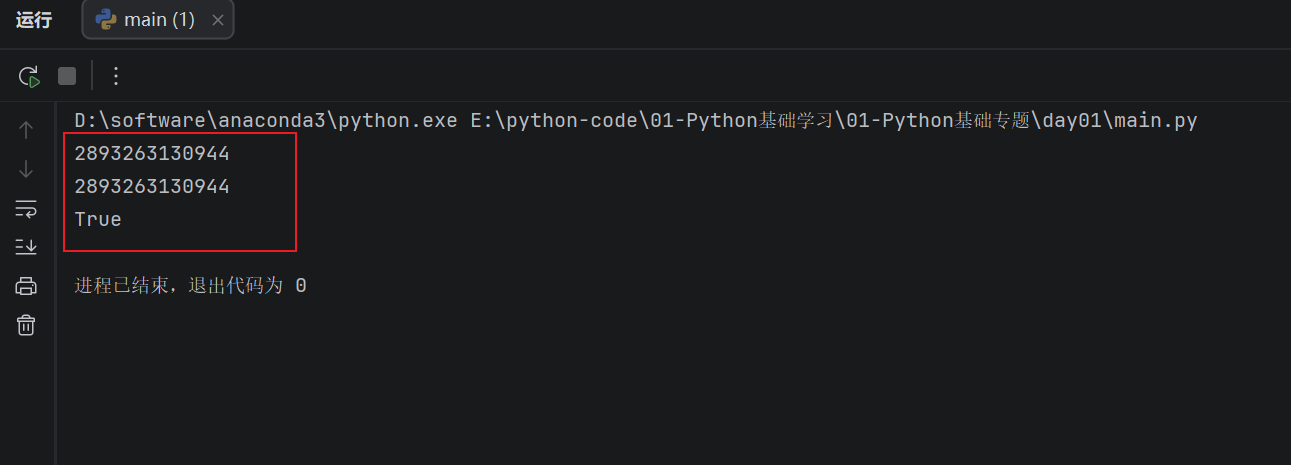
运行结果中,id(a) 和 id(b) 通常是一样的,a is b 的结果是 True。这说明 a 和 b 不是两个独立列表,而是同一个列表的两个名字。
所以如果修改 b:
a = [1, 2, 3]
b = a
b.append(4) #修改 b
print(a)
print(b)
print(id(a))
print(id(b))
print(a is b)
运行结果:
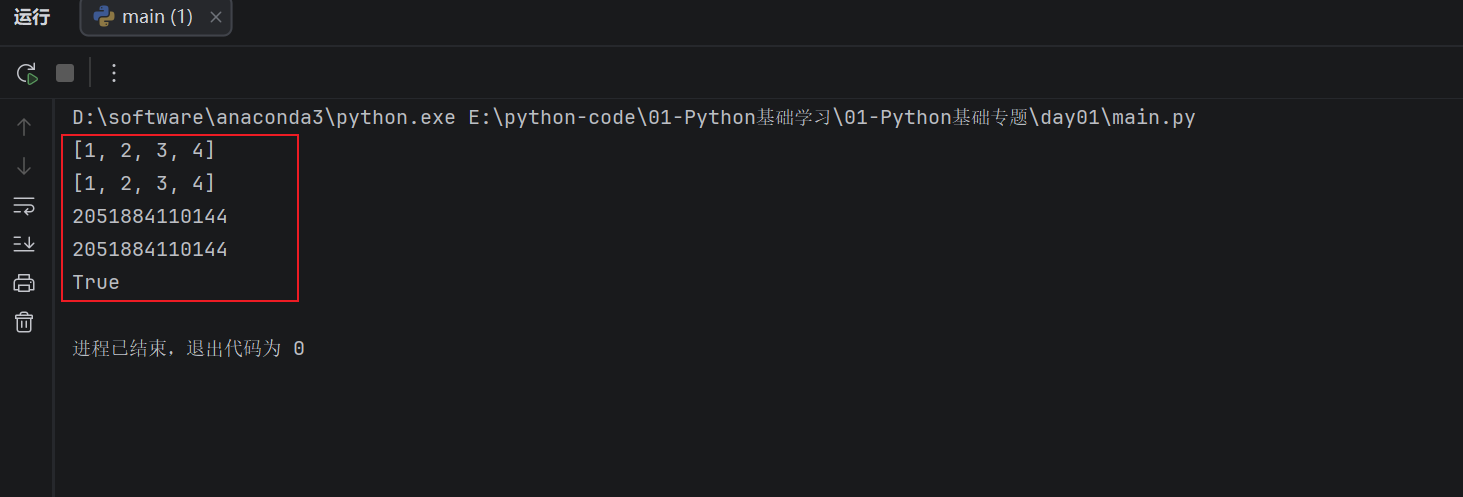
因为 a 和 b 指向的是同一个列表,改了 b,a 看到的内容也变了。
这就是查看内存地址最常见的作用:判断两个变量是不是共用同一份数据。
再看一个容易混淆的例子:
a = [1, 2, 3]
b = [1, 2, 3]
print(a == b)
print(a is b)
print(id(a))
print(id(b))
运行结果:
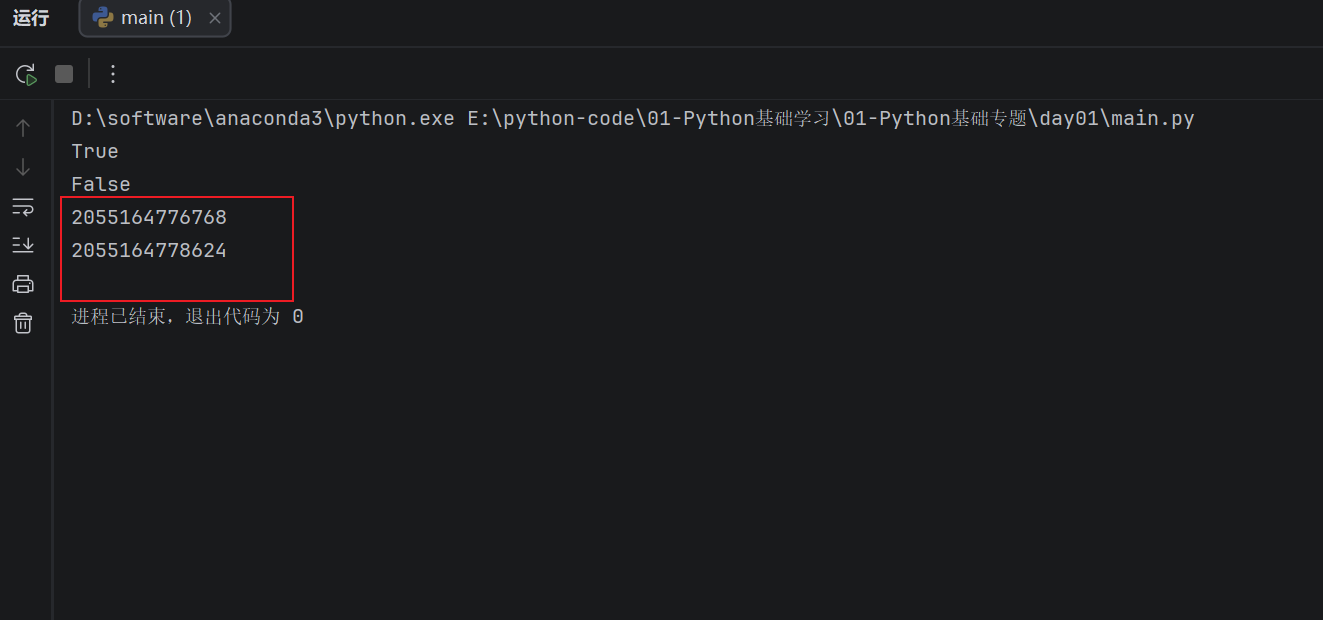
这里 a == b 是 True,因为两个列表里面的内容一样。但是 a is b 通常是 False,因为它们不是同一个列表,只是内容相同而已。
可以这样理解:
== 比较的是“值是否一样”。
is 比较的是“是不是同一个对象”。
id() 查看的是对象的身份编号,也可以简单理解为内存中的位置标识。
在实际开发中,查看变量内存地址一般用于这几类情况:学习 Python 对象机制时,理解变量、对象和引用的关系;调试列表、字典这类可变对象时,判断多个变量是不是指向同一个对象;分析浅拷贝和深拷贝时,观察数据到底有没有被真正复制;排查函数传参后,为什么函数内部修改了列表,外面的列表也跟着变了。
3、常量
什么是常量
- 常量可以理解为在程序运行过程中不希望被改变的数据。它和变量很像,都是用一个名字来保存数据,但区别在于:**变量的值可以根据需要发生变化,而常量的值一般是固定的。 **
- 比如在程序中,圆周率
3.14、一周有7天、考试满分100分,这些数据通常不会在程序运行过程中随便改变。为了让代码更清楚,我们可以给这些固定的数据起一个名字:
PI = 3.14
WEEK_DAYS = 7
MAX_SCORE = 100
需要注意的是,Python 里没有真正严格意义上的常量。也就是说,即使我们写了:
MAX_SCORE = 100
后面仍然可以重新赋值:
MAX_SCORE = 120
- Python 本身不会阻止你这样做。但是在实际开发中,大家通常约定:如果一个变量名全部使用大写字母,并且多个单词之间用下划线连接,就表示它是常量,不应该随便修改。
- 常量可以简单理解为:程序中固定不变、或者不希望被改变的数据。它的作用是让代码更清楚,也方便以后统一修改。比如满分本来是
100,如果代码里到处都直接写100,以后改起来很麻烦;如果统一写成MAX_SCORE,只需要改这一处就可以了。
4、PEP 8规范
- https://peps.python.org/pep-0008/
- PEP 8 是 Python 官方推荐的一套代码书写规范。它不是 Python 的语法规则,也就是说,不完全按照 PEP 8 写,代码不一定会报错。但是按照 PEP 8 来写,代码会更整齐、更清楚,也更方便别人阅读和维护。
5、八大基本数据类型
前面我们已经知道,变量是用来保存数据的。但是程序中的数据并不是都一样的,有的是整数,有的是小数,有的是文字,还有的是一组数据。不同的数据有不同的特点,也适合做不同的操作。
比如,年龄通常用整数表示,身高可以用小数表示,姓名要用字符串表示,判断一个人是否成年可以用布尔值表示。如果想保存多个学生的成绩,就需要用列表;如果想保存一个学生的姓名、年龄、成绩等信息,就可以用字典。
所以,在学习 Python 时,只知道变量还不够,还要知道变量里面保存的数据属于什么类型。数据类型决定了这个数据能怎么使用、能参与什么运算,也决定了程序应该怎样处理它。
接下来,我们就来学习 Python 中常见的八大基本数据类型。
数字类型
数字类型是 Python 中最常用的数据类型之一,主要用来表示和计算数字。只要程序里涉及年龄、价格、成绩、数量、距离、金额等内容,基本都会用到数字类型。
在 Python 中,常见的数字类型主要有三种:整数、小数和复数。
整数
- 整数就是没有小数点的数字,在 Python 中用
int表示。比如年龄、人数、数量、次数、编号和索引等内容 ,一般都可以用整数来保存:
age = 18
count = 20
score = 95
print(age)
print(type(age))
这里的 18、20、95 都是整数。使用 type() 可以查看变量的数据类型,程序会显示它们属于 int 类型。
浮点数
- 浮点类型用于表示带有小数部分的数字,在 Python 中,浮点数用
float表示 。比如身高、体重、价格、温度等,经常会用小数来保存:
height = 175.5
price = 9.9
temperature = 36.5
print(height)
print(type(height))
这里的 175.5、9.9、36.5 都是小数,对应的数据类型是 float。
复数
- 复数在日常编程中用得相对少一些,它由实部和虚部组成,在 Python 中用
complex表示。Python 里用j表示虚部:
number = 3 + 4j
print(number)
print(type(number))
这里的 3 + 4j 就是一个复数,对应的数据类型是 complex。
字符串类型
- 字符串类型用于表示文本内容,是 Python 中非常常见的数据类型之一。只要数据是由文字、字母、数字或符号组成,并且被引号包起来,在 Python 中通常就属于字符串类型。
比如姓名、地址、手机号、用户名、密码、提示信息等,都可以用字符串来表示:
name = "小明"
address = "北京市海淀区"
phone = "18888888888"
message = "欢迎学习 Python"
这里的 "小明"、"北京市海淀区"、"18888888888" 和 "欢迎学习 Python" 都是字符串,对应的数据类型是 str。
- 字符串可以用引号包裹起来。在 Python 中,字符串既可以使用单引号,也可以使用双引号,还可以使用三引号。
# 1. 使用双引号定义字符串
name_1 = "dream"
print(name_1, type(name_1))
# 2. 使用单引号定义字符串
name_2 = 'dream'
print(name_2, type(name_2))
# 3. 使用三个单引号定义字符串
name_3 = '''dream'''
print(name_3, type(name_3))
# 4. 使用三个双引号定义字符串
name_4 = """dream"""
print(name_4, type(name_4))
运行结果如下:
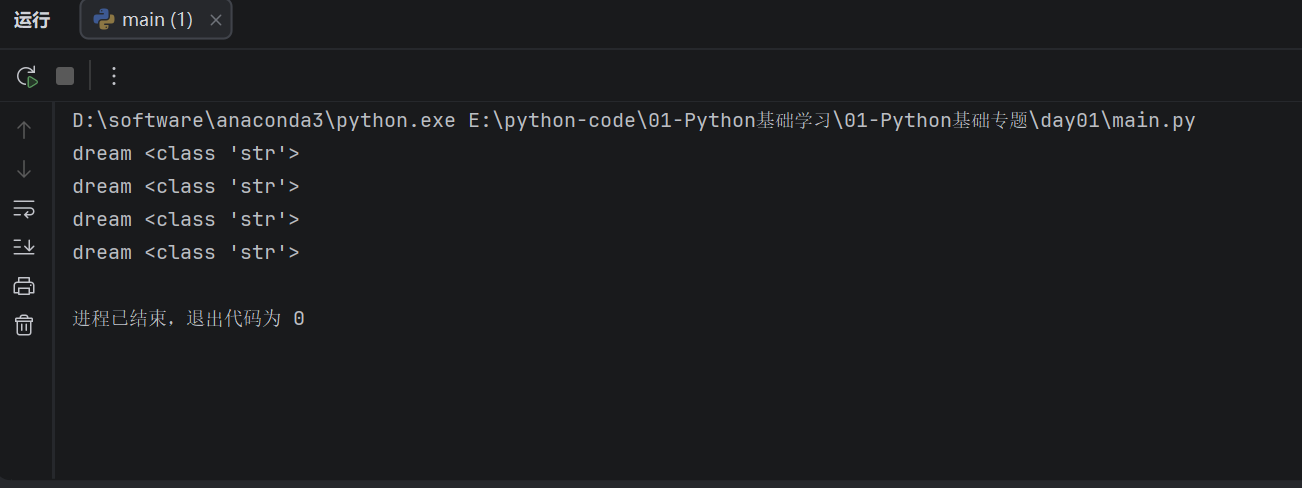 从结果可以看出,不管使用单引号、双引号,还是三引号,只要内容被引号包裹起来,在 Python 中都属于字符串类型,也就是
从结果可以看出,不管使用单引号、双引号,还是三引号,只要内容被引号包裹起来,在 Python 中都属于字符串类型,也就是 str 类型。
语法
- 单引号和双引号在大多数情况下没有区别,平时写简单字符串时,两种都可以使用:
name = "dream"
school = 'Python'
- 如果字符串内容里面本身包含单引号,外面可以使用双引号,这样写起来更方便:
sentence = "I'm a student"
print(sentence)
- 如果字符串内容里面本身包含双引号,外面可以使用单引号:
sentence = '他说:"你好"'
print(sentence)
- 三引号主要用于表示多行字符串,也就是字符串内容可以换行书写:
info = """
姓名:小明
年龄:18
爱好:编程
"""
print(info)
- 三引号也常用于写较长的说明文字,比如函数说明、类说明或者多行注释形式的文本内容。
使用方法
- 字符串除了可以用来保存文本内容,还可以进行一些简单的运算。需要注意的是,字符串的运算规则和数字不完全一样。
- 字符串之间可以使用
+进行拼接:
name = "dream"
message = "hello " + name
print(message)
运行结果:
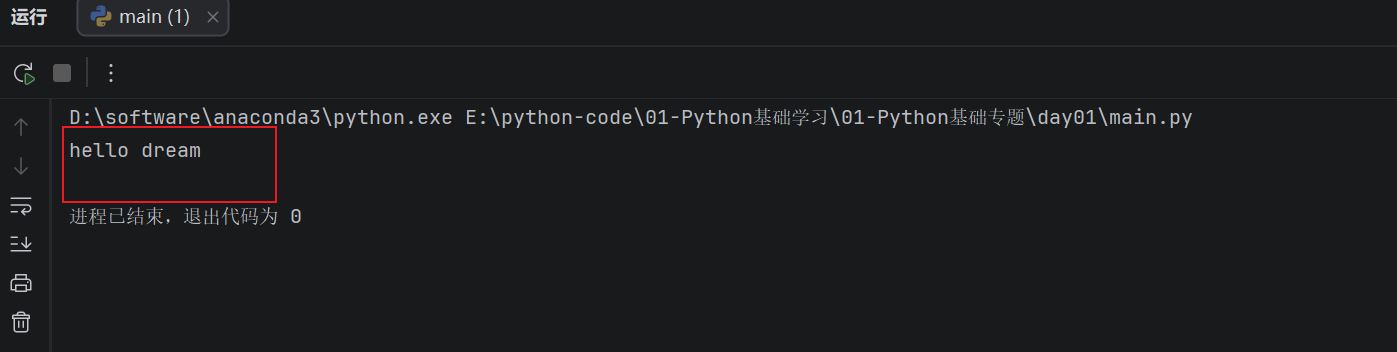
- 字符串也可以和整数相乘,表示把这个字符串重复指定次数:
print("d" * 5)
运行结果:
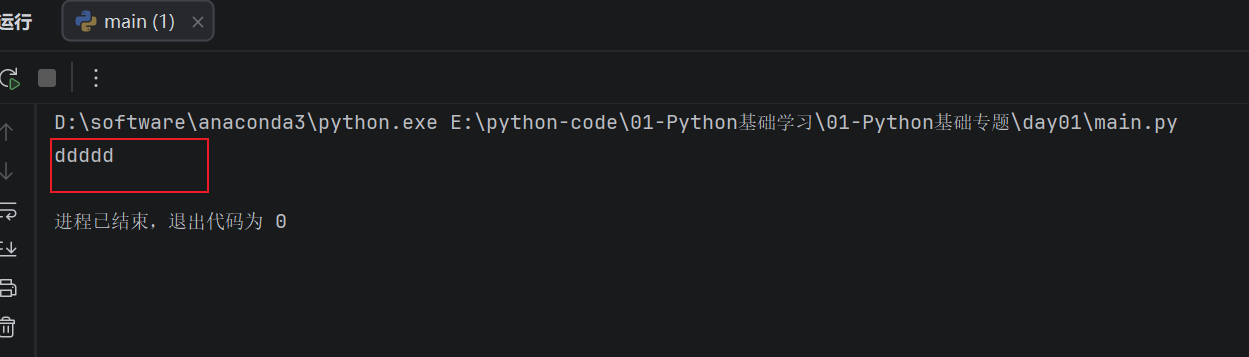
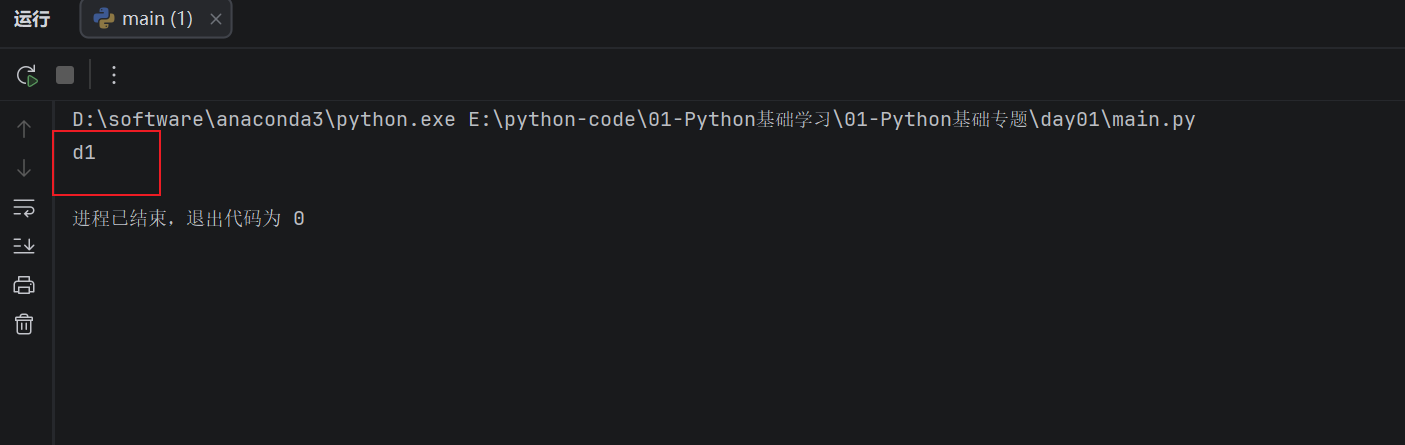
** 但是字符串不能直接和数字相加:**
print("d" + 1)
运行结果:
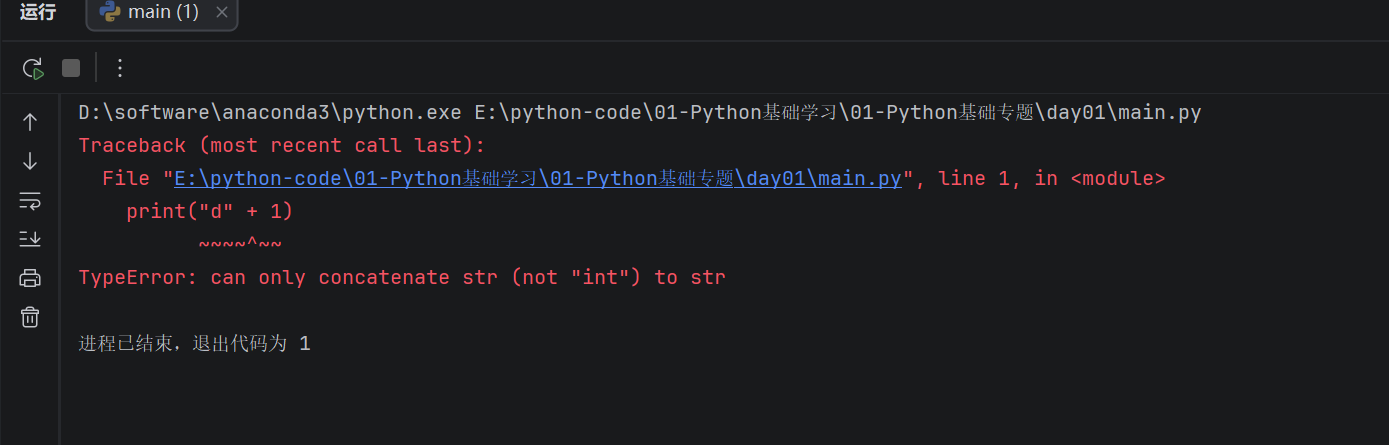
这行代码会报错,因为 "d" 是字符串,1 是整数,两个类型不同,不能直接拼接。如果想把它们连在一起,需要先把数字转换成字符串:
print("d" + '1')
运行结果:
- 字符串还可以通过索引取出指定位置的字符。Python 中的索引从
0开始:
name = "dream"
print(name[0])
print(name[1])
print(name[-1])
运行结果:
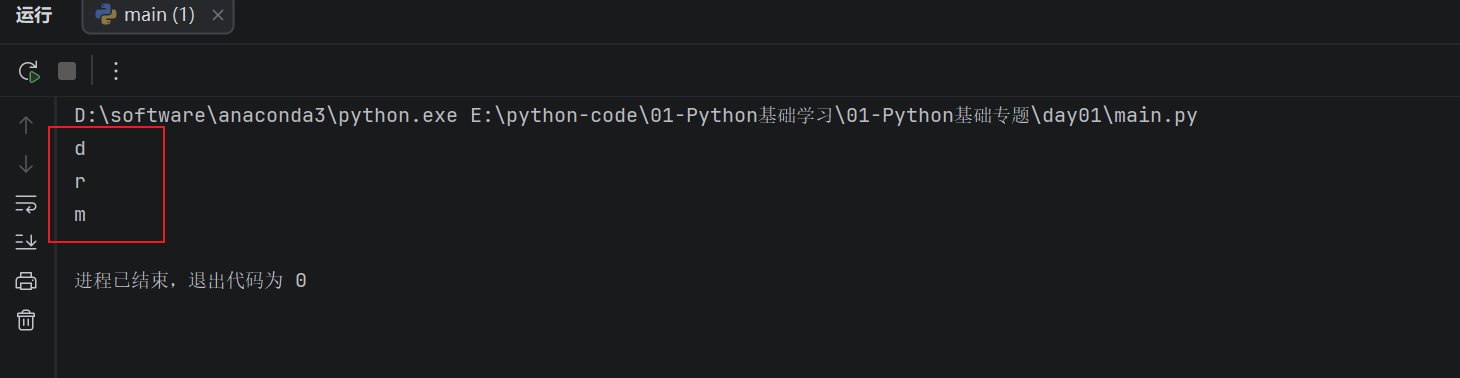
其中,name[0] 表示取第一个字符,name[1] 表示取第二个字符,name[-1] 表示取最后一个字符。
字符串的格式化输出语法
%占位
%格式化输出可以简单理解为:先在字符串中用占位符留好位置,再在后面把变量的值填进去。常用的占位符中,%s表示字符串,%d表示整数,%f表示浮点数,%x表示十六进制整数。%s可以作为通用占位符,用来输出大多数数据;但如果要强调整数、小数,或者需要控制小数位数,就应该使用%d、%f这类更明确的占位符。
比如:
user_name = "张三"
product_name = "Python入门课程"
price = 99.9
order_id = "A20240601001"
print("用户%s购买了%s,订单编号:%s,支付金额:%s元" % (user_name, product_name, order_id, price))
运行结果:

- 在这段代码中,字符串里有 4 个
%s,它们就像 4 个空位。后面的变量会按照顺序依次填进去:第一个%s放用户名,第二个%s放商品名,第三个%s放订单编号,第四个%s放支付金额。 - 虽然
price是小数,但是使用%s也可以输出,因为%s会把数据转换成字符串再显示。
不过,如果是金额、成绩、温度这类数据,通常希望显示得更规范一些,比如金额保留两位小数。这时候可以使用 %.2f:
print("用户%s购买了%s,订单编号:%s,支付金额:%.2f元" % (user_name, product_name, order_id, price))
运行结果:
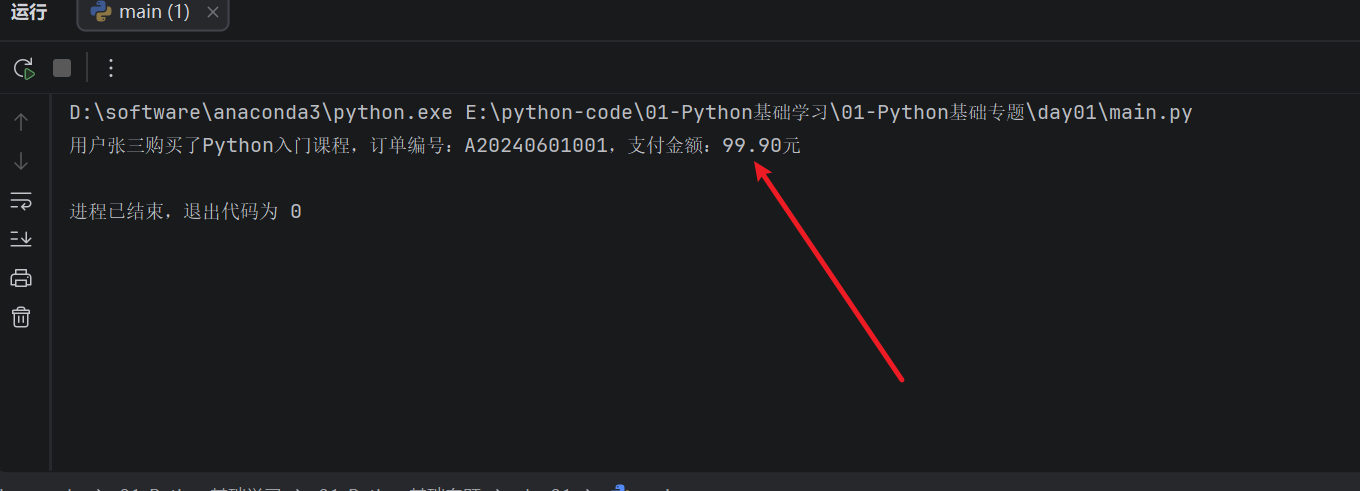
%s适合把变量直接放到字符串中显示,使用起来比较方便;如果要控制数字格式,比如保留几位小数,就要使用%f这类更具体的占位符。
format方法输出
format()方法也可以用来做字符串格式化输出。它的作用和前面的%格式化类似,都是把变量的值放到一段字符串中。- 它的基本写法是:先在字符串中用
{}占好位置,然后在后面使用.format()把数据传进去。
user_name = "张三"
product_name = "Python入门课程"
order_id = "A20240601001"
price = 99.9
print("用户{}购买了{},订单编号:{},支付金额:{:.2f}元".format(user_name, product_name, order_id, price))
运行结果:

在这段代码中,字符串里有 4 个 {},它们就像 4 个空位。.format() 里面的变量会按照顺序依次填进去:第一个 {} 放用户名,第二个 {} 放商品名,第三个 {} 放订单编号,第四个 {} 放支付金额。
需要注意的是,如果使用普通的 **{}**,它是按照位置顺序来填数据的。如果变量顺序写错了,输出结果就会乱。
** **比如:
user_name = "张三"
product_name = "Python入门课程"
print("用户{}购买了{}".format(product_name, user_name))
运行结果:
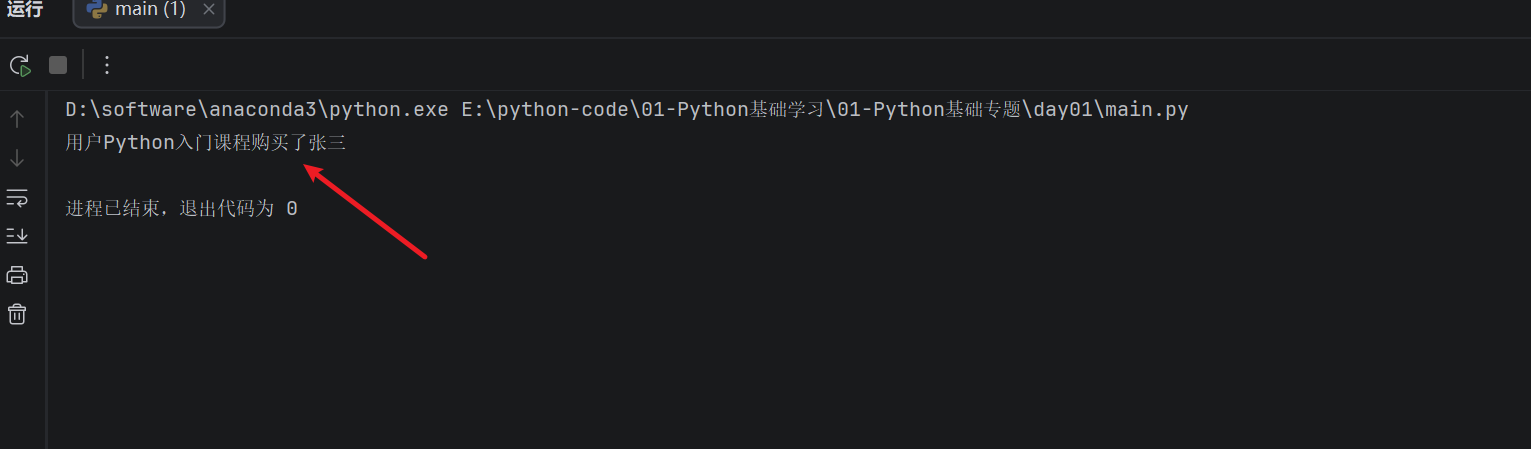
这句话明显不对。原因是 **{}** 会按照 **.format()** 里面参数的顺序取值,第一个 **{}** 取到了 **product_name**,第二个 **{}** 取到了 **user_name**。
为了解决这种顺序容易写错的问题,可以使用关键字传参。也就是在 {} 里面写上名字,然后在 .format() 里面按照这个名字传值。
user_name = "张三"
product_name = "Python入门课程"
order_id = "A20240601001"
price = 99.9
print("用户{name}购买了{product},订单编号:{order},支付金额:{money:.2f}元".format(
name=user_name,
product=product_name,
order=order_id,
money=price
))
运行结果:
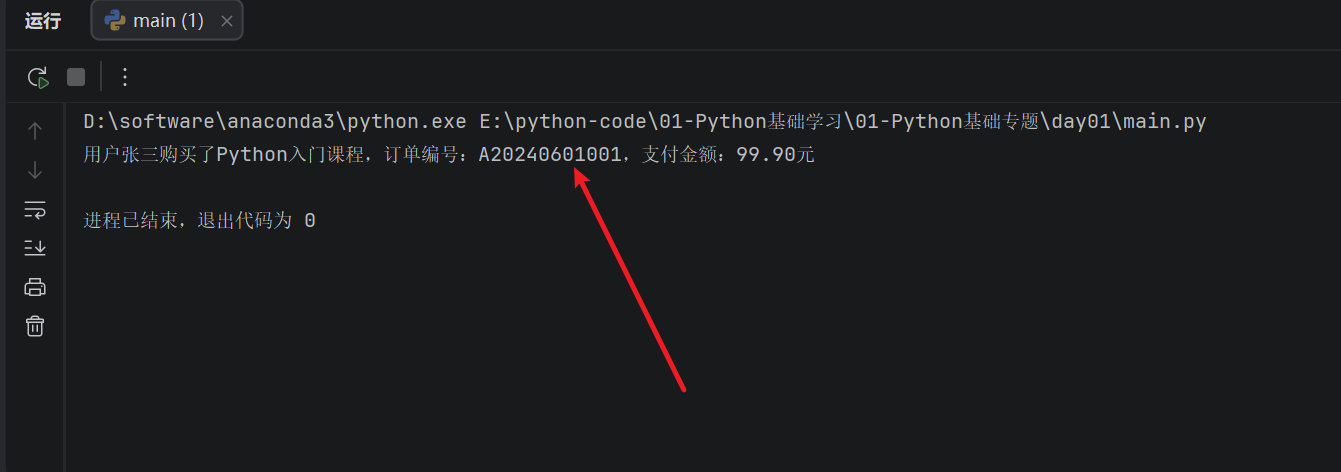
这种写法的好处是,变量不用完全依赖顺序,只要关键字对应正确,结果就不会乱。比如 **{name}** 会去找 **.format()** 里面的 **name=user_name**,**{product}**** 会去找 **product=product_name**。**
format()还可以用位置编号来指定数据:
name = "张三"
course = "Python入门课程"
print("{0}购买了{1},{0}正在学习{1}".format(name, course))
运行结果:

这里的 {0} 表示取 .format() 里面第一个数据,也就是 name;{1} 表示取第二个数据,也就是 course。如果同一个变量要用多次,可以用这种方式重复引用。
f"{name}"也就是f-string
- f-string 是 Python 中一种常用的字符串格式化输出方式。它的作用是把变量的值直接放进字符串里,让输出内容更清楚,也更方便写。
- 它的基本写法是在字符串前面加一个字母
f,然后在字符串中用{}放入变量名。
user_name = "张三"
product_name = "Python入门课程"
price = 99.9
print(f"用户{user_name}购买了{product_name},支付金额:{price}元")
运行结果:
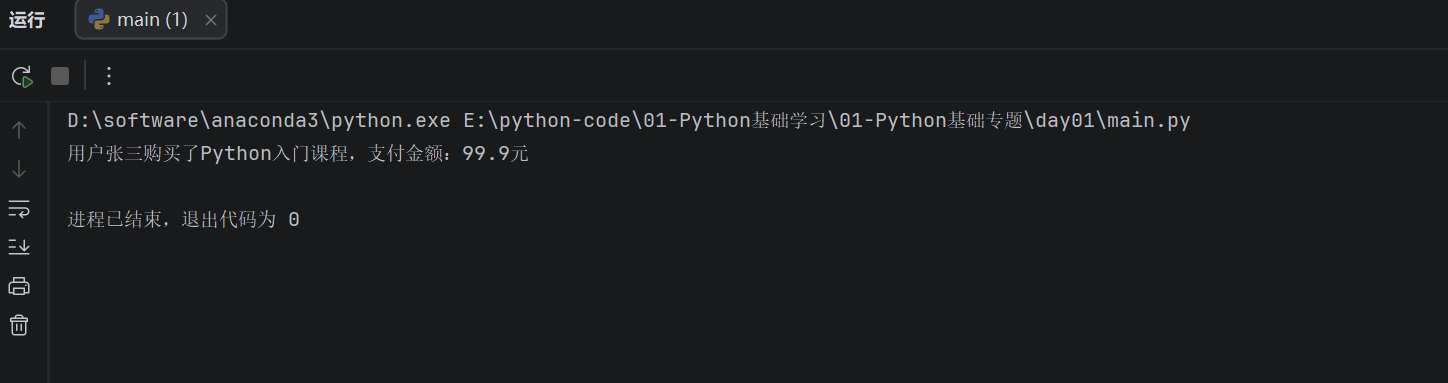
这里的 f 表示这是一个格式化字符串。{user_name}、{product_name}、{price} 就是要被替换的位置。程序运行时,会自动把变量里面保存的值放到对应位置。和 % 占位符、format() 方法相比,f-string 最大的特点是更直观。比如看到 {user_name},就知道这里放的是用户名;看到 {product_name},就知道这里放的是商品名,不需要再去后面找变量的对应顺序。
- f-string 也可以控制数字格式。比如金额通常需要保留两位小数,就可以这样写:
user_name = "张三"
product_name = "Python入门课程"
price = 99.9
print(f"用户{user_name}购买了{product_name},支付金额:{price:.2f}元")
运行结果:
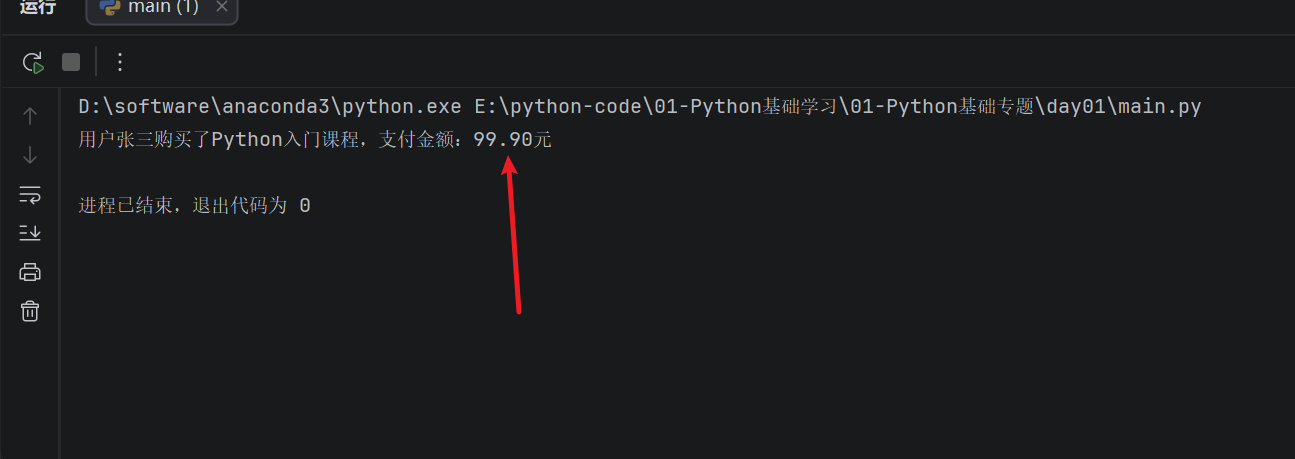
这里的 {price:.2f} 表示把 price 按照小数格式输出,并且保留两位小数。这个写法在金额、成绩、温度、价格等场景中很常用。
- f-string 还可以在
{}里面写简单的计算表达式:
price = 99.9
count = 3
print(f"商品单价:{price:.2f}元,购买数量:{count},总金额:{price * count:.2f}元")
运行结果:
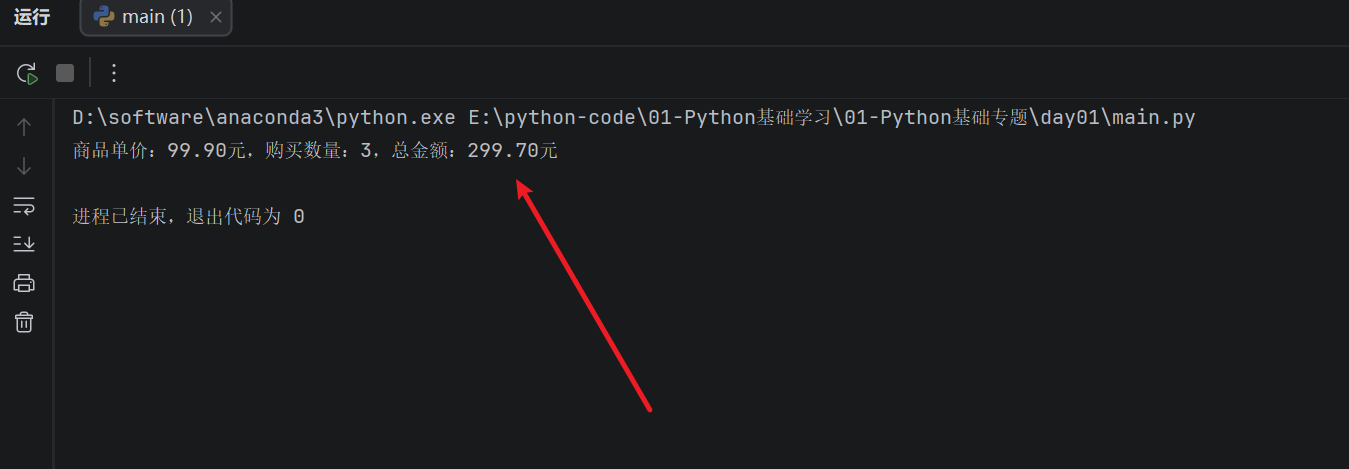
这里的 {price * count:.2f} 会先计算 price * count,再把计算结果保留两位小数输出。
- 在实际开发中,f-string 常用于输出提示信息、订单信息、日志信息、调试信息、文件名、接口返回提示等。
总结
- 字符串类型可以简单理解为:专门用来保存文本内容的数据类型。只要内容是文字、符号,或者不需要参与数学计算的数字,都可以用字符串来表示。
- 单引号和双引号适合写普通的一行字符串;当字符串中包含引号时,可以用另一种引号包裹,避免混乱;三引号适合写多行字符串或较长的说明内容。
- 正向索引取值(从左往右),索引下标从0开始,负向索引取值(从右往左),索引下标从-1开始
- 在实际开发中,
format()常用于生成提示信息、订单信息、日志信息、报表文字等。比如后台系统中输出一条订单记录、程序运行时打印一条日志、生成一段说明文字,都可能用到格式化输出。 format()的优点是比%格式化更灵活,可以按顺序传参,也可以按位置编号传参,还可以按关键字传参;同时也能控制数字格式,比如保留两位小数。- f-string 的优点是写法简单、阅读清楚、不容易因为变量顺序写错导致输出混乱。它很适合在代码中直接使用已经定义好的变量。
- f-string 依赖当前代码中的变量。如果字符串模板是从外部文件、数据库或者配置文件中读取出来的,一般不适合直接用 f-string,这种情况下
format()方法会更合适。 - 字符串格式化输出的发展,可以理解为从“能用”到“好用”,再到“好读”。
%占位符是比较早的写法,通过%s、%d、%f等符号把变量放进字符串中,能完成基本输出,但变量多时容易看乱。format()方法用{}占位,比%更灵活,可以按顺序、编号或关键字传参,适合模板类字符串。f-string 是现在更常用的写法,直接把变量写进{}里,代码最直观,也最容易阅读。 - 简单来说:
%解决了“能输出”,format()解决了“更灵活”,f-string 解决了“更清楚”。
列表
列表是 Python 中用来保存多个数据的一种类型。它使用中括号 [] 表示,数据之间用逗号隔开。
names = ["张三", "李四", "王五"]
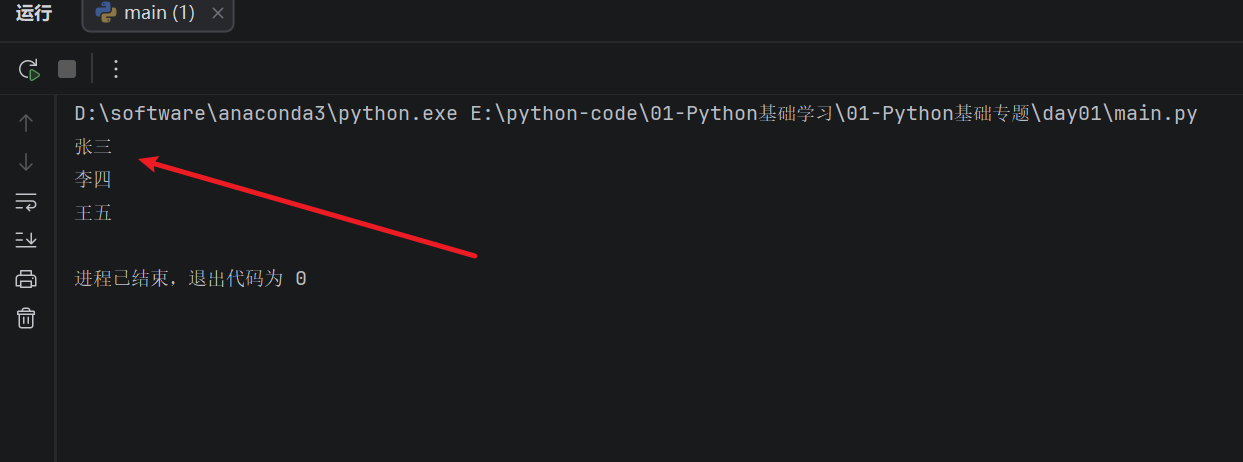
列表中的数据是有顺序的,每个数据都有自己的位置编号,这个编号叫索引。Python 的正向索引从 0 开始:
names = ["张三", "李四", "王五"]
print(names[0])
print(names[1])
print(names[2])
运行结果:
列表也可以嵌套,也就是一个列表里面再放列表。比如用列表保存多个学生的信息:
students = [
["张三", 18, 95],
["李四", 19, 88],
["王五", 18, 76]
]
print(students[0]) # 取出第一个学生的信息
print(students[0][0]) # 取出第一个学生的姓名
print(students[0][2]) # 取出第一个学生的成绩
print(students[1][1]) # 取出第二个学生的年龄
这里的 students 是一个大列表,里面又放了 3 个小列表。每个小列表表示一个学生的信息,分别是姓名、年龄和成绩。
运行结果:
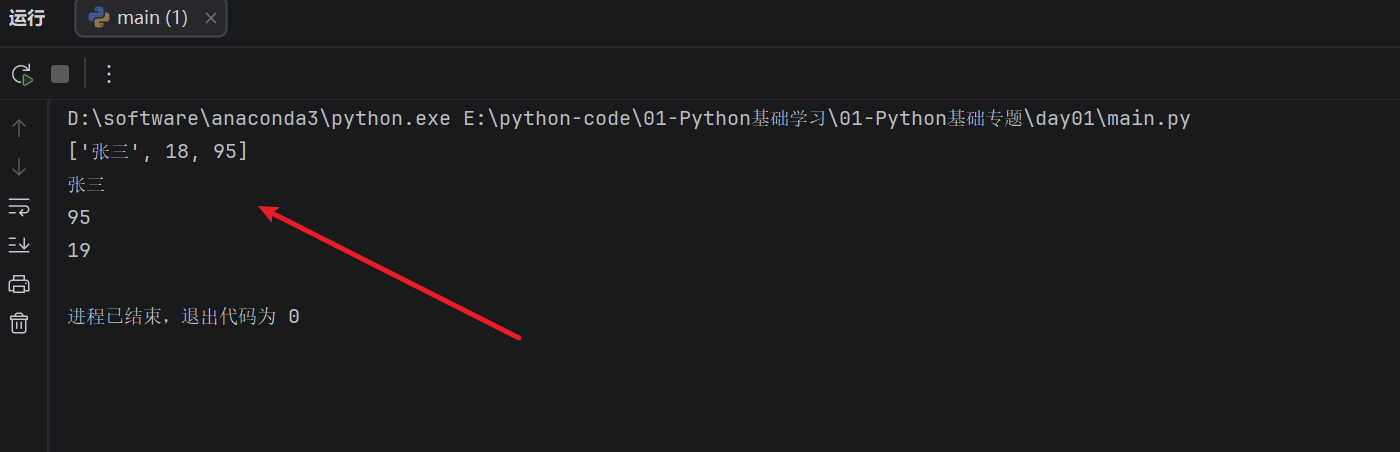
students[0] 先取出第一个小列表,也就是 ["张三", 18, 95];
students[0][0] 再从这个小列表里取第一个数据,所以得到 "张三"。
在实际开发中,列表常用于保存一组有顺序的数据,比如学生名单、商品列表、成绩列表、订单列表等。列表嵌套则适合保存表格一样的数据,比如多个学生的信息、多个商品的信息、二维坐标等。
字典
字典是 Python 中用来保存“键值对”的数据类型。它和列表一样,都可以保存多个数据,但列表是按位置取值,字典是按名字取值。
字典使用大括号 {} 表示,里面的数据由“键”和“值”组成:
person_info = {
"name": "张三",
"age": 18,
"city": "北京"
}
这里的 "name"、"age"、"city" 是键,"张三"、18、"北京" 是对应的值。可以简单理解为:键就是数据的名字,值就是这个名字对应的具体内容。
取值
字典取值常见有两种方式。
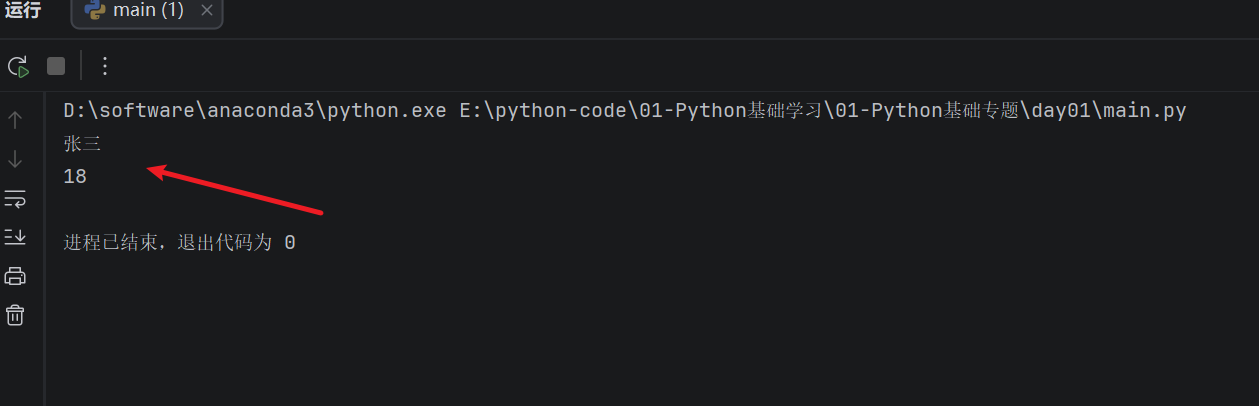
第一种方式是使用 字典["key"] 取值:
person_info = {
"name": "张三",
"age": 18,
"city": "北京"
}
print(person_info["name"])
print(person_info["age"])
运行结果:
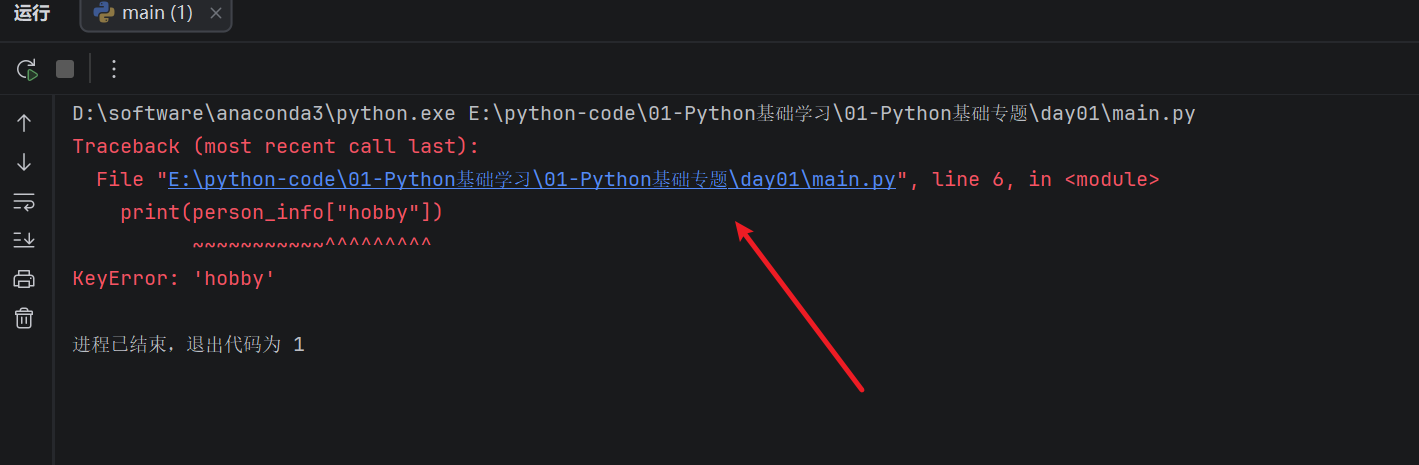
这种方式比较直接,适合确定字典中一定有这个键的情况。但是如果访问了不存在的键,程序就会报错:
person_info = {
"name": "张三",
"age": 18,
"city": "北京"
}
print(person_info["hobby"])
运行结果:
第二种方式是使用 字典.get("key") 取值:
person_info = {
"name": "张三",
"age": 18,
"city": "北京"
}
print(person_info.get("name"))
print(person_info.get("hobby"))
运行结果:
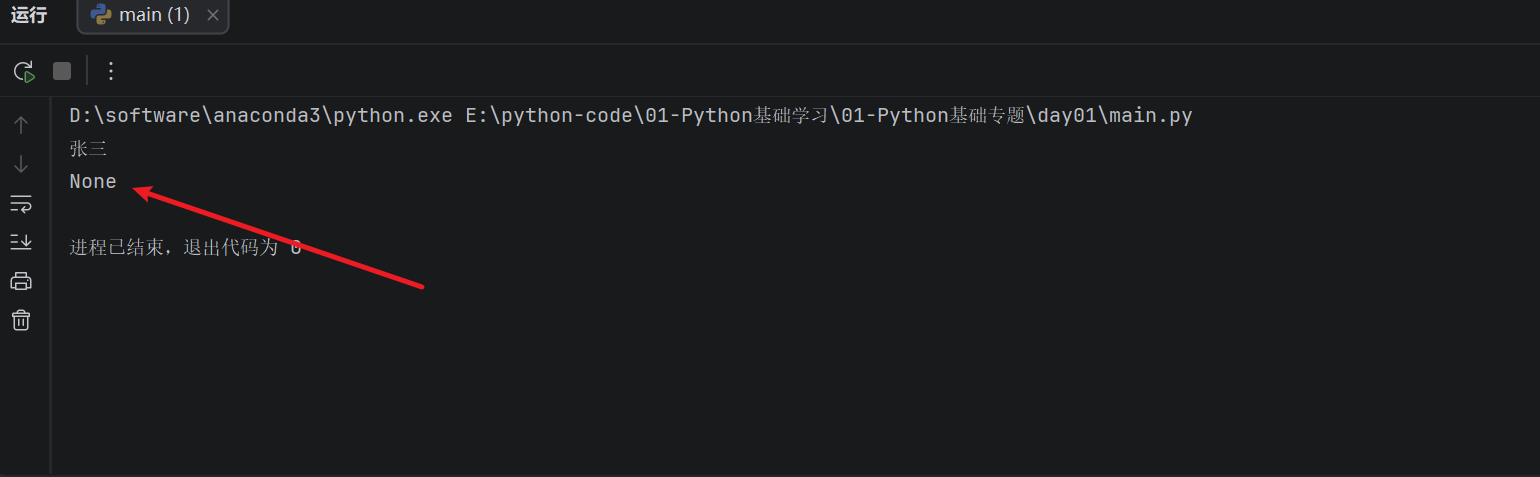
**get()**** 的好处是,如果键不存在,程序不会报错,而是默认返回 **None**。**
也可以给 get() 设置一个默认值:
person_info = {
"name": "张三",
"age": 18,
"city": "北京"
}
print(person_info.get("hobby", "暂无爱好信息"))
运行结果:
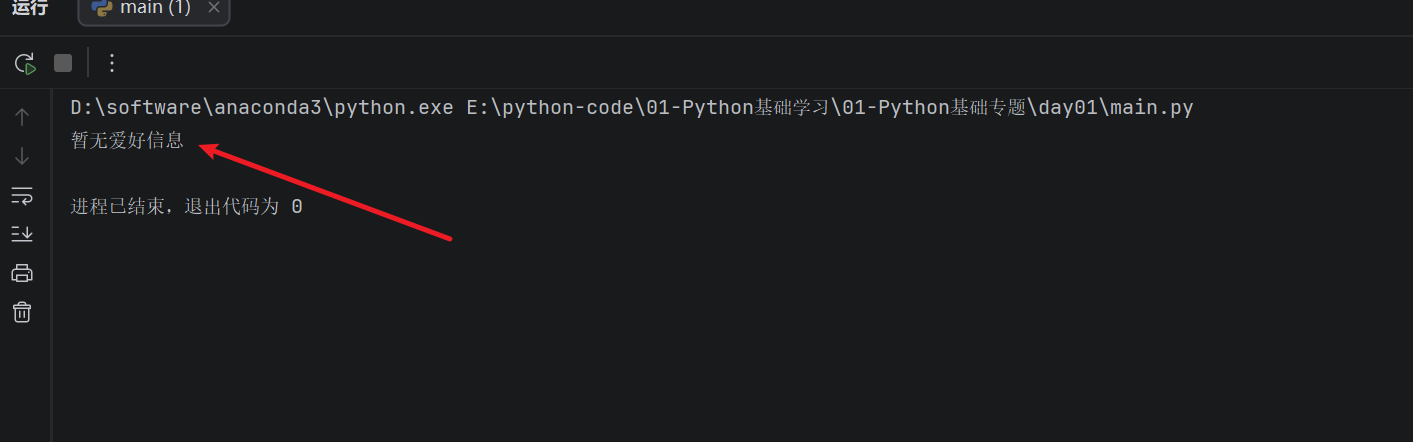
字典也可以修改和新增数据:
person_info = {
"name": "张三",
"age": 18
}
person_info["age"] = 19
person_info["city"] = "北京"
print(person_info)
运行结果:
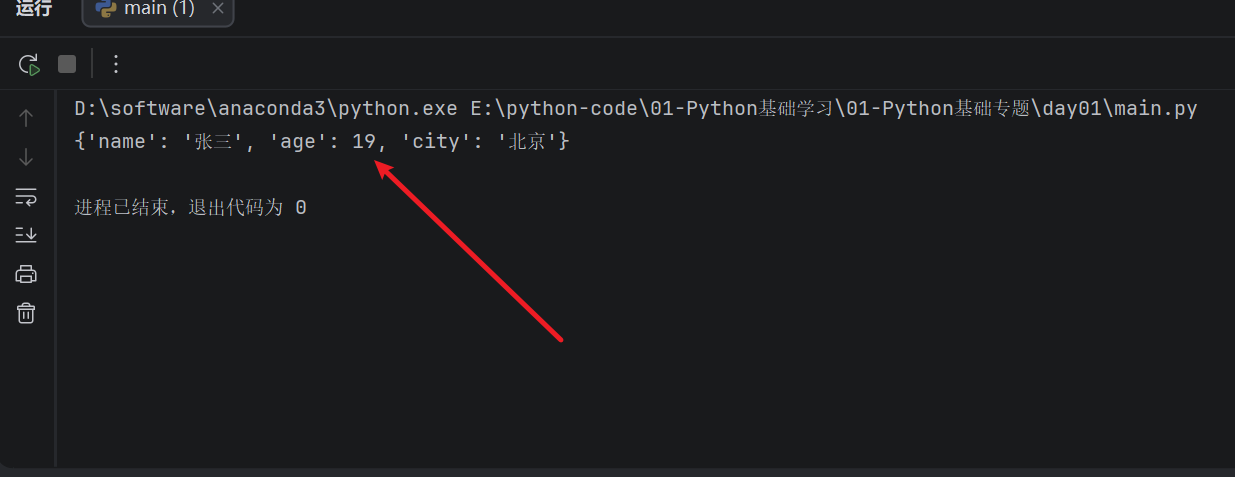
字典还可以嵌套,也就是一个字典里面再放字典。比如保存多个学生的信息:
students = {
"student_1": {
"name": "张三",
"age": 18,
"score": 95
},
"student_2": {
"name": "李四",
"age": 19,
"score": 88
}
}
print(students["student_1"]["name"])
print(students["student_2"]["score"])
运行结果:
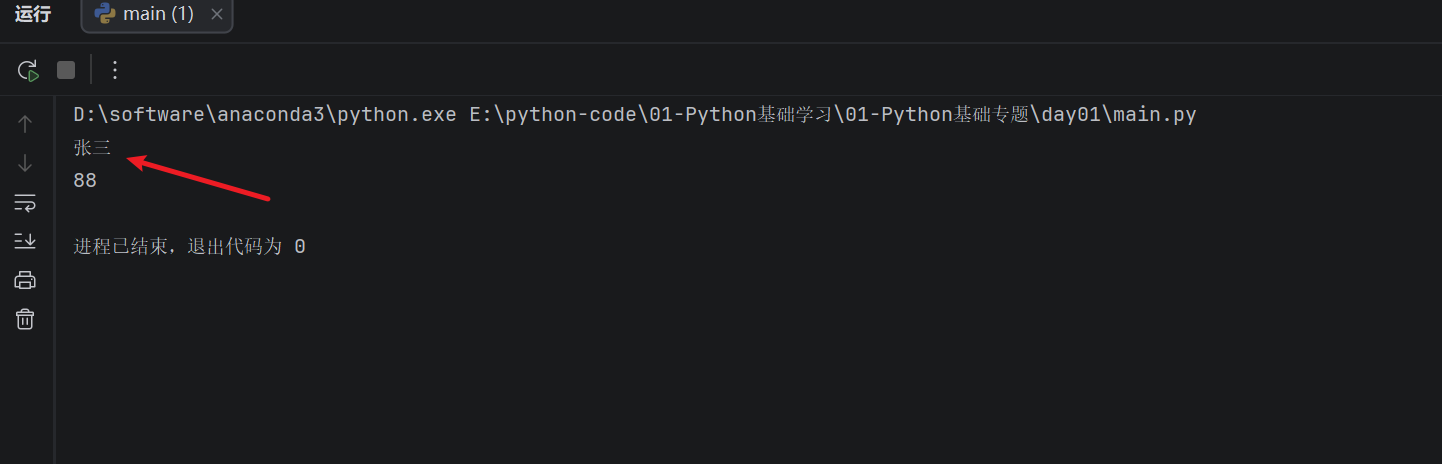
这里的 students["student_1"] 先取出第一个学生的信息,得到的是一个小字典;后面的 ["name"] 再从这个小字典里取出姓名。
字典的优点是含义清楚,取值直观。看到 student["score"],就知道取的是成绩。
字典的缺点是键名不能写错。如果使用 字典["key"] 访问不存在的键,程序会报错。所以在不确定键是否存在时,建议使用 get()。
- 字典就是用来保存“名字和内容对应关系”的容器。列表适合保存一组有顺序的数据,字典适合保存一组有明确名称的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号