

DS博客作业05--查找
0.PTA得分截图

1.本周学习总结
1.1 总结查找内容
静态查找及ASL
1.静态查找:仅作查询和检索操作的查找表。
关键字的平均比较次数,也称为平均搜索长度ASL
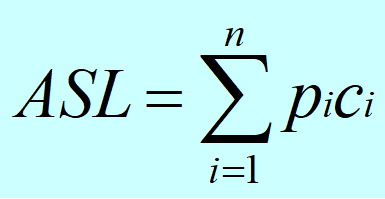
n:记录的个数;pi:查找第i个记录的概率 ( 通常认为pi =1/n );ci:找到第i个记录所需的比较次数
成功情况下的平均查找长度ASL成功是指找任一记录平均需要的关键字比较次数。

ASL成功=(1+2+3+4+5+6+7+8+9)/9=5
2.顺序查找:从表的一端开始,顺序扫描线性表,依次将扫描到的关键字和给定值k相比较,若当前扫描到的关键字与k相等,则查找成功;若扫描结束后,仍未找到关键字等于k的记录,则查找失败。
算法如下:
int SeqSearch(SeqList R,int n,KeyType k)
{ int i=0;
while (i<n && R[i].key!=k) //从表头往后找
i++;
if (i>=n) //未找到返回0
return 0;
else
return i+1;//找到返回逻辑序号i+1
}
时间复杂度为O(n)
成功时顺序查找的平均查找长度为:ASL=(n+1)/2;查找成功时的平均比较次数约为表长的一半,查找不成功时的平均查找长度为n
3.二分查找
二分查找也称为折半查找,要求线性表中的节点必须己按关键字值的递增或递减顺序排列。
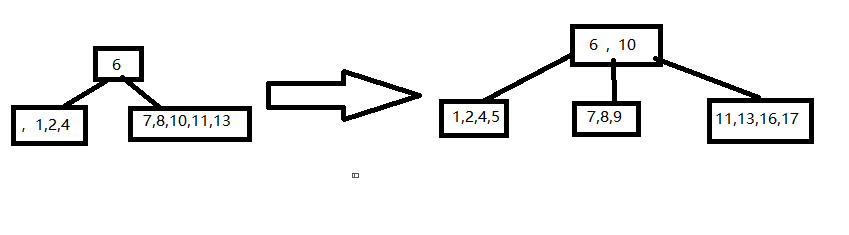
例如:如图所示随机创建一个例子:查找21
首先应先排序完后再进行查找,首先mid指向56的位置

进行比较后进行折半
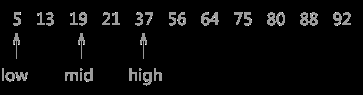
最后查找到并更新

算法如下:
int BinSearch(SeqList R,int n,KeyType k)
{ int low=0,high=n-1,mid;
while (low<=high) //当前区间存在元素时循环
{ mid=(low+high)/2;
if (R[mid].key==k)//查找成功
return mid+1;
if (k<R[mid].key)
high=mid-1;
else
low=mid+1; }
return 0;
}
二分查找的时间复杂度为O(log2n).
4.二分查找的性能分析-判定树
将上一题的例子列举出判定树:
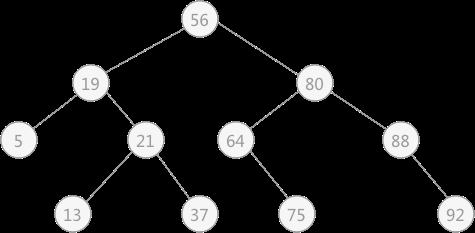
再根据此求出成功ASL和不成功ASL:
成功ASL=(11+22+43+44)/11=3
不成功ASL=(43+84)/12=3.67
动态查找
1.静态查找表的缺点:当表的插入或删除操作频繁时,为维护表有序性,需要移动表中很多记录;二分查找和分块查找只适用于静态查找表;以二叉树或树作为表的组织形式, 称为树表。
2.二叉排序树
特点:若它的左子树不空,则左子树上所有结点的值均小于根结点的值;若它的右子树不空,则右子树上所有结点的值均大于根结点的值;它的左、右子树也都分别是二叉排序树而且二叉排序树中没有相同关键字的节点。
3.二叉排序树的查找
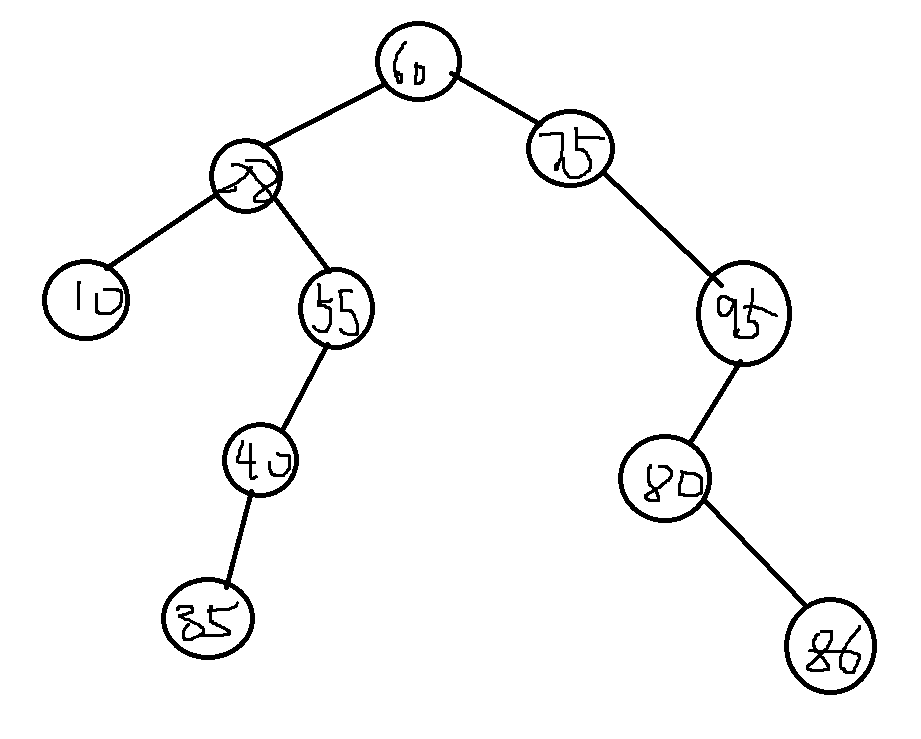
如图一棵树:查找40则往左子树一直下去找到,而查找100在结点没有,就要往不成功的地方查找
成功ASL=(11+22+33+42+52)/13.2
不成功ASL=(12+43+24+4*5)/11
二叉排序树结点类型定义:
typedef struct node
{ KeyType key; //关键字项
InfoType data; //其他数据域
struct node *lchild,*rchild; //左右孩子指针
} BSTNode,*BSTree;
4.二叉排序树的查找:
二叉排序树可看做是一个有序表,所以在二叉排序树上进行查找,和二分查找类似,也是一个逐步缩小查找范围的过程。
递归算法如下:
BSTNode *SearchBST(BSTNode *bt,KeyType k)
{ if (bt==NULL || bt->key==k) //递归终结条件
return bt;
if (k<bt->key)
return SearchBST(bt->lchild,k);
//在左子树中查找
else
return SearchBST(bt->rchild,k); //右子树中查找
}
非递归:
BSTNode *SearchBST1(BSTNode *bt,KeyType k)
{ while (bt!=NULL)
{
if (k==bt->key)
return bt;
else if (k<bt->key)
bt=bt->lchild; //在左子树中迭代查找
else
bt=bt->rchild; //在左子树中迭代查找
}
return NULL; //没有找到返回NULL
}
5.二叉排序树的插入
插入的元素一定在叶结点上;在二叉排序树中插入一个关键字为k的新结点,要保证插入后仍满足BST性质;插入过程:边查找边插入。
int InsertBST(BSTree &p,KeyType k)
{ if (p==NULL) //原树为空 {
p=new BSTNode;
p->key=k;p->lchild=p->rchild=NULL;
return 1;
}
else if (k==p->key) //相同关键字的节点0
return 0;
else if (k<p->key)
return InsertBST(p->lchild,k); //插入到左子树
else
return InsertBST(p->rchild,k); //插入到右子树
}
BSTNode *CreatBST(KeyType A[],int n) //返回树根指针
{ BSTNode *bt=NULL; //初始时bt为空树
int i=0;
while (i<n)
{
InsertBST(bt,A[i]); //将A[i]插入二叉排序树T中
i++;
}
return bt; //返回建立的二叉排序树的根指针
}
两个函数进行调用,即可用插入来创建二叉树
6.二叉排序树-生成
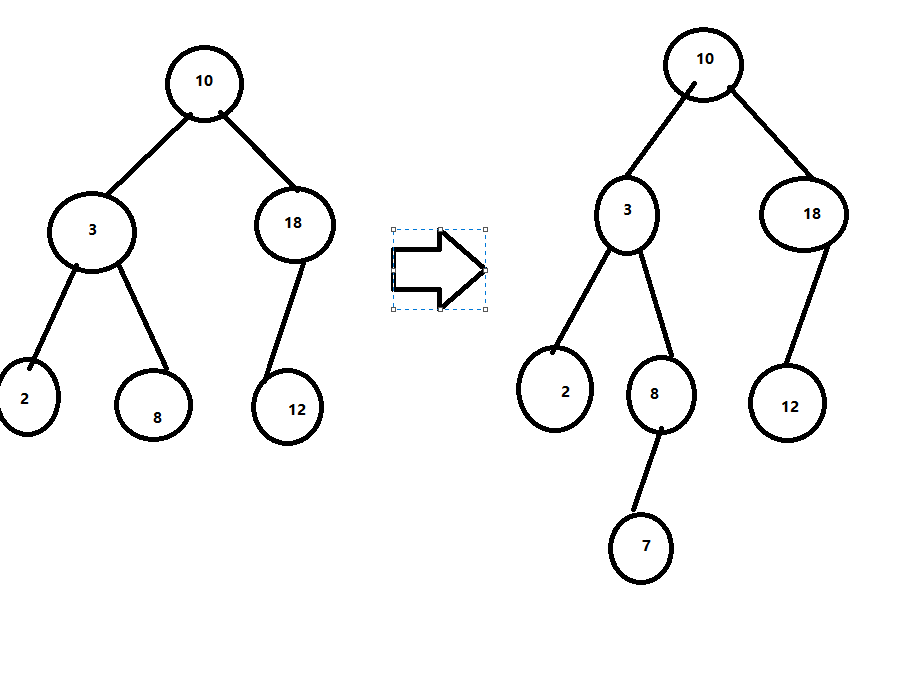
从空树出发,经过一系列的查找、插入操作之后,可生成一棵二叉排序树;任何节点插入到二叉排序树时,都是以叶子节点插入的;不同插入次序的序列生成不同形态的二叉排序树。
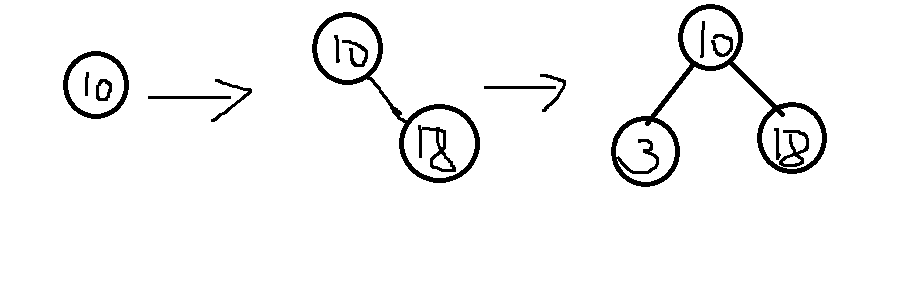
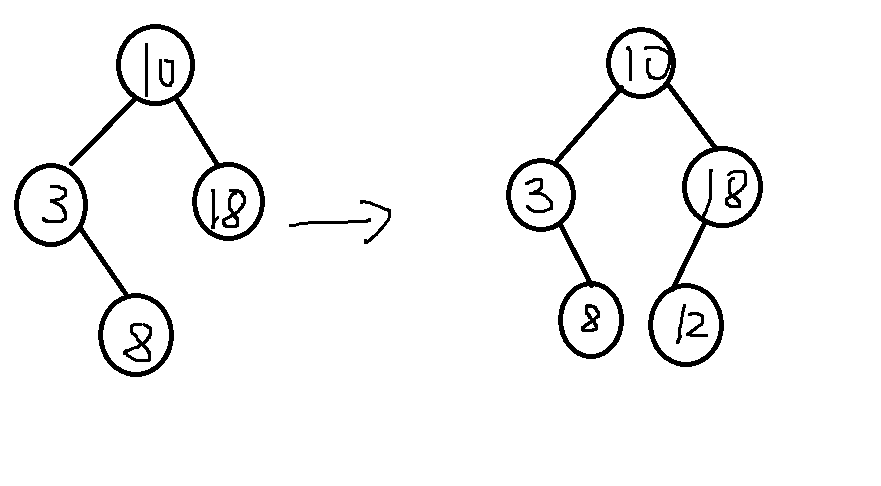
举例: {10, 18, 3, 8, 12, 2, 7}
例如:40,24,12,37,55序列
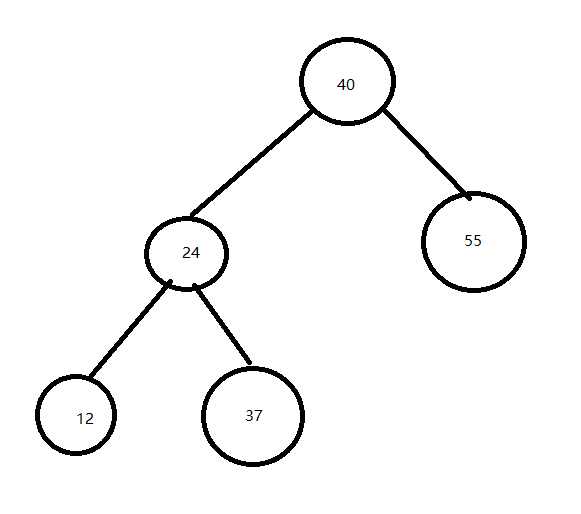
ASL1=(1+22+33)/5=2.8
例如:12,24,37,40,55序列
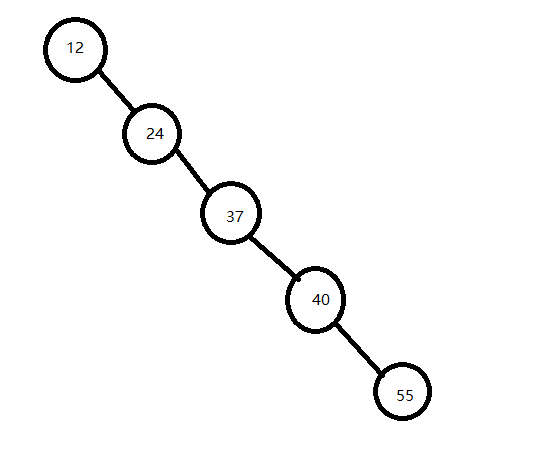
ASL2=(1+2+3+4+5)/5=3
7.求最小节点和最大节点
二叉排序树的中序序列是一个递增有序序列
根结点的最左下结点是关键字最小的结点
根结点的最右下结点是关键字最大的结点
算法:
KeyType maxnode(BSTNode *p)
//返回一棵二叉排序树中最大节点关键字
{ while (p->rchild!=NULL)
p=p->rchild;
return(p->data);
}
KeyType minnode(BSTNode *p)
//返回一棵二叉排序树中的最小节点关键字
{ while (p->lchild!=NULL)
p=p->lchild;
return(p->data);
}
8.二叉排序树的删除
分为情况如下:
原树:
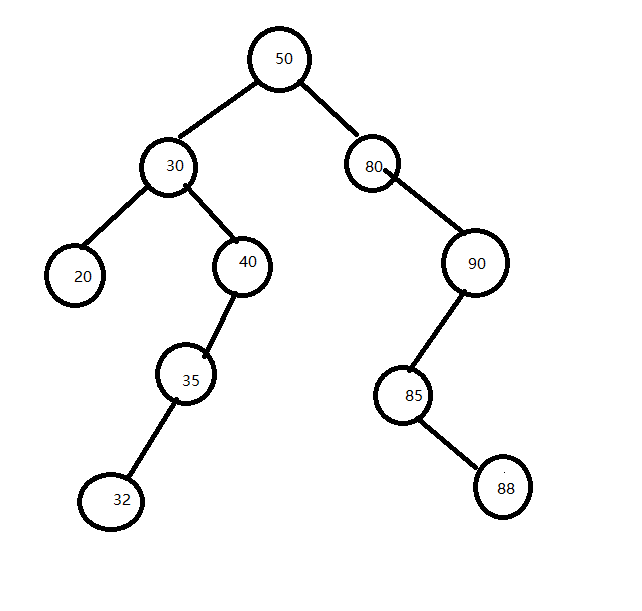
1)被删除的节点是叶子节点。
删除20,88,20,88为叶子节点,直接删除:

2)被删除的节点只有左子树或者只有右子树
删除节点40;其双亲节点的相应指针域的值改为 “指向被删除节点的左子树或右子树”
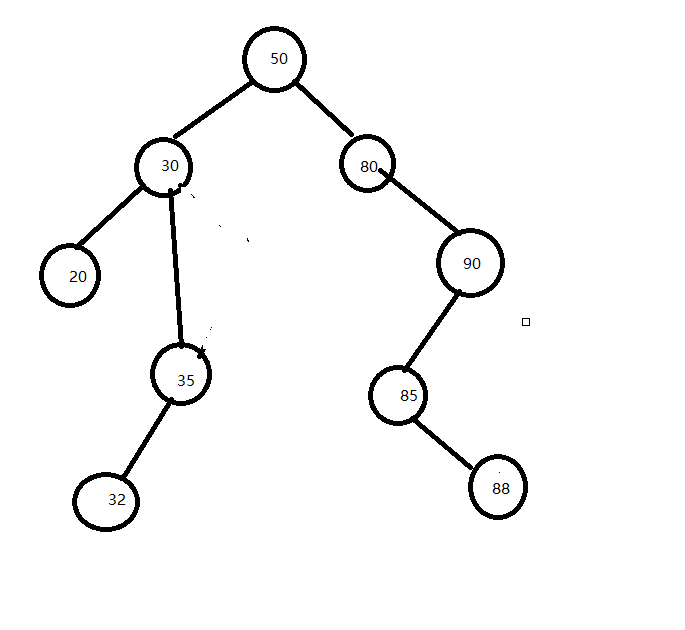
3)被删除的节点既有左子树,也有右子树。
被删除节点:50

以其前驱替代之,然后再删除该前驱节点。前驱是左子树中最大的节点。
也可以用其后继替代之,然后再删除该后继节点。后继是右子树中最小的节点。
算法思路:
int DeleteBST(BSTNode *&bt,KeyType k)
{if(bt->key<k) 递归左子树查找k
if(bt->key>k) 递归右子树查找k
if(bt->key==k)
{ if(bt是叶子节点) 删除bt
if(bt只有左孩子) 保存bt左孩子node,删除bt,bt=node
if(bt只有右孩子) 保存bt右孩子node,删除bt,bt=node
if(bt有左右孩子)
{ 递归查找bt左子树最右孩子r
bt->key=r->key
保存r左孩子node,删除r
r=node
}
}
void Delete(BSTreee &p) //从二叉排序树中删除*p节点
{ BSTNode *q;
if (p->rchild==NULL) //*p节点没有右子树的情况
{
q=p; p=p->lchild;delete q;
}
else if (p->lchild==NULL) //*p节点没有左子树
{
q=p; p=p->rchild;delete q;
}
else Delete1(p,p->lchild);
//*p节点既有左子树又有右子树的情况
}
AVL树的定义及4种调整做法。
AVL树:平衡二叉树:左、右子树是平衡二叉树;所有结点的左、右子树深度之差的绝对值≤ 1
平衡因子:该结点左子树与右子树的高度差;最坏情况下的时间也均为O(log2n).
平衡树:
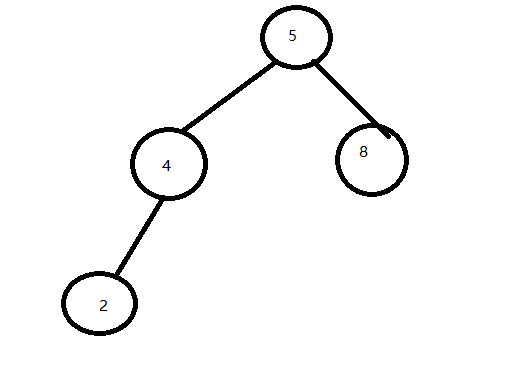
不是平衡树:
定义节点:
typedef struct node //记录类型
{ KeyType key; //关键字项
int bf; //增加的平衡因子
InfoType data; //其他数据域
struct node *lchild,*rchild;//左右孩子指针
} BSTNode;
如果在一棵AVL树中插入一个新结点,就有可能造成失衡,此时必须重新调整树的结构,使之恢复平衡。我们称调整平衡过程为平衡旋转。
四种调整:LL平衡旋转;RR平衡旋转;LR平衡旋转;RL平衡旋转
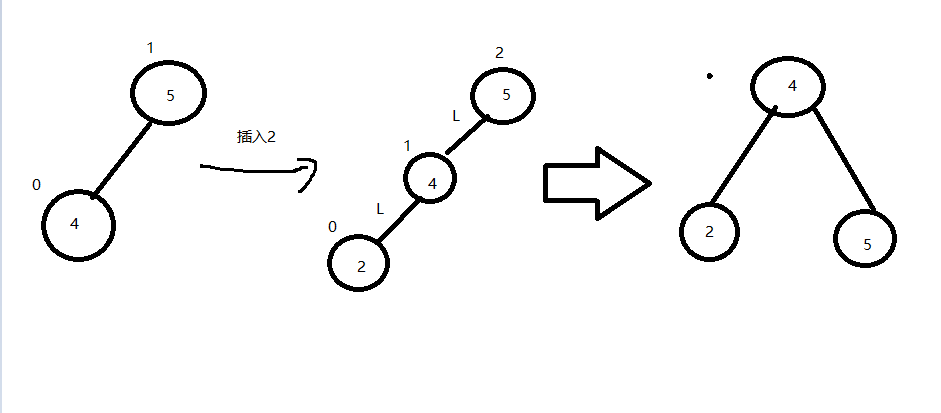
LL调整演示:
若在A的左子树的左子树上插入结点,使A失衡,平衡因子2,需要进行一次顺时针旋转。
1.A的左孩子B右上旋转作为A的根节点
2.A节点右下旋转称为B的右孩子
3.B原右子树称为A左子树
RR调整演示:
若在A的右子树的右子树上插入结点,使A的平衡因子从-1增加至-2,需要进行一次逆时针旋转
1.A的右孩子B左上旋转作为A的根节点
2.A节点左下旋转称为B的左孩子
3.B原左子树称为A右子树
先插入2,1,8,6,10,15排序得:
LR调整
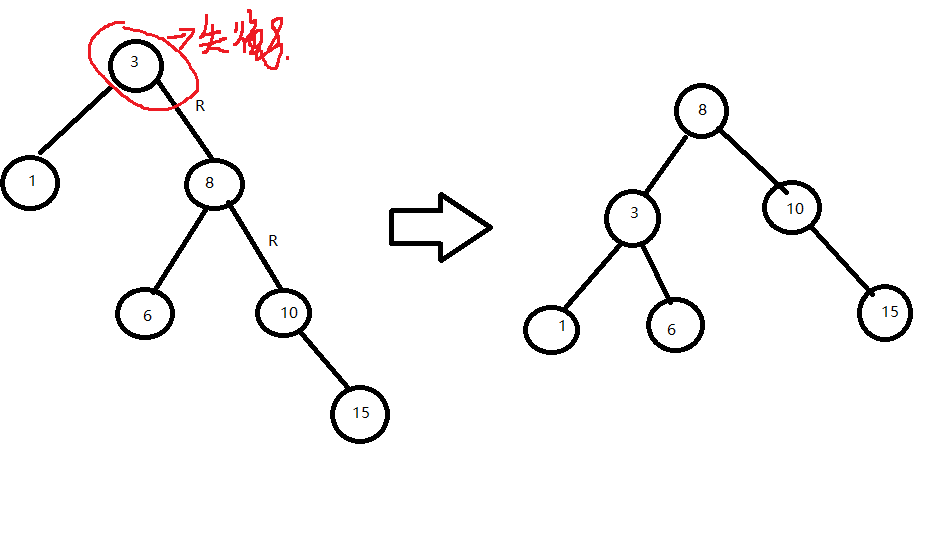
若在A的左子树的右子树上插入结点,使A的平衡因子从1增加至2,(以插入的结点C为旋转轴),先C进行逆时针旋转,A再顺时针旋转。
1.C向上旋转到A的位置,A作为C右孩子
2.C原左孩子作为B的右孩子
3.C原右孩子作为A的左孩子
保持二叉排序树有序

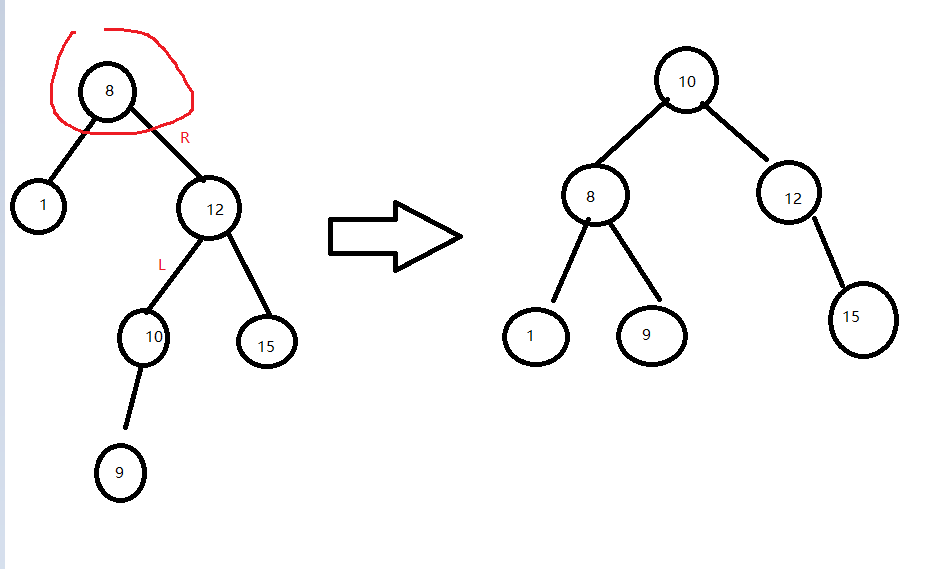
RL调整:
若在A的右子树的左子树上插入结点,使A的平衡因子从-1增加至-2,(以插入的结点C为旋转轴),先进行顺时针旋转,再逆时针旋转。
1.C向上旋转到A的位置,A作为C左孩子
2.C原左孩子作为A的右孩子
3.C原右孩子作为B的左孩子
保持二叉排序树有序
B-树和B+树定义
1.定义:B-树和B+树:一个节点可放多个关键字,降低树的高度。可放外存,适合大数据量查找。如数据库中数据;B-树又称为多路平衡查找树;一棵m阶B-树或者是一棵空树,或者是满足下列要求的m叉树:
2.B-树结构
(1)每个节点至多m个孩子节点(至多有m-1个关键字)
(2)除根节点外,其他节点至少有(m/2)个孩子节点(即至少有(m/2)-1个关键字);
(3)若根节点不是叶子节点,根节点至少两个孩子节点
(4)B-树是所有结点的平衡因子均等于0的多路查找树。所有外部结点都在同一层上。
(5)外部结点就是失败结点,指向它的指针为空,不含有任何信息,是虚设的。一棵B树中总有n个关键字,则外部结点个数为n+1。
3.结点特点(m)阶为例
(1)非根节点:孩子个数:最小: (m/2) 最大:m
(2)非根节点:关键字个数:最小: (m/2) -1 最大:m-1
(3)根节点至少两个孩子(2--m)
4.结点定义
#define MAXM 10 //定义B-树的最大的阶数
typedef int KeyType; //KeyType为关键字类型
typedef struct node //B-树节点类型定义
{ int keynum; //节点当前拥有的关键字的个数
KeyType key[MAXM]; //[1..keynum]存放关键字,[0]不用
struct node *parent; //双亲节点指针
struct node *ptr[MAXM];//孩子节点指针数组[0..keynum]
} BTNode;
5.B-树的查找
将k与根节点中的key[i]进行比较:
(1)若k=key[i],则查找成功;
(2)若k<key[1]
则沿着指针ptr[0]所指的子树继续查找;
(3)若key[i]<k<key[i+1]
则沿着指针ptr[i]所指的子树继续查找;
(4)若k>key[n]
则沿着指针ptr[n]所指的子树继续查找。
查找到某个叶结点,若相应指针为空,落入一个外部结点,表示查找失败。
6.B-树的插入操作(图像演示为主)
在查找不成功之后,需进行插入。关键字插入的位置必定在叶子结点层,有下列几种情况:该结点的关键字个数n<m-1,不修改指针; 该结点的关键字个数 n=m-1,则需进行“结点分裂”
1.如果没有双亲结点,新建一个双亲结点,树的高度增加一层。
2.如果有双亲结点,将ki插入到双亲结点中。
现在距离关键字序列:(1,2,6,7,11,4,8,13,10,5,17,9,16,20,3,12,14,18,19,15)。创建一颗5阶B树;最多关键字个数为4
插入11,4,8,13

插入10,5,17,9,16
以此延伸到最后一步,插入最后一个15
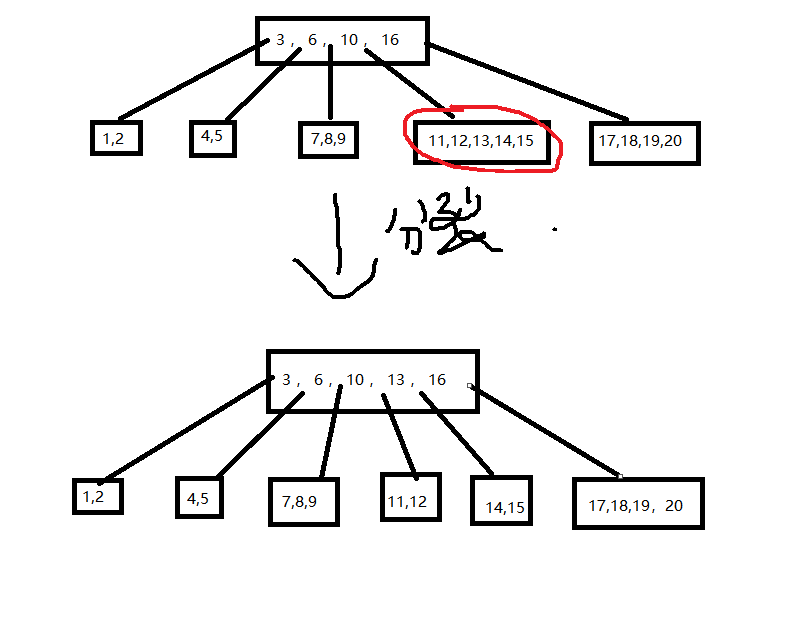
最后应该再持续分裂一次

7.B-树的删除(图示为主)
(1)B树非叶子结点删除
在非叶子结点上删除关键字ki
1.从pi子树节点借调最大或最小关键字key代替ki。
2.pi子树中删除key
3.若子树节点关键字个数< m/2-1,重复步骤1
4.若删除关键字为叶子结点层,按叶子结点删除操作法
(2)B树叶子结点删除
- 假如b结点的关键字个数大于Min,说明删去该关键字后该结点仍满足B树的定义,则可直接删去该关键字。
- 假如b结点的关键字个数等于Min,说明删去关键字后该结点将不满足B树的定义。若可以从兄弟结点借。兄弟结点最小关键字上移双亲结点;双亲结点大于删除关键字的关键字下移删除结点
3.b结点的关键字个数等Min,兄弟节点关键字个数也等于Min
1).删除关键字
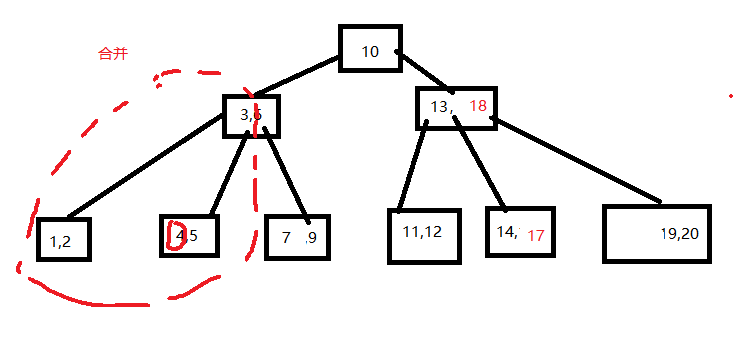
2).兄弟节点及删除关键字节点、双亲结点中分割二者关键字合并一个新叶子结点
3).若双亲结点关键字个数<=Min,重复2
图示:
对于前例生成的B树,给出删除8,16,15,4等4个关键字的过程。
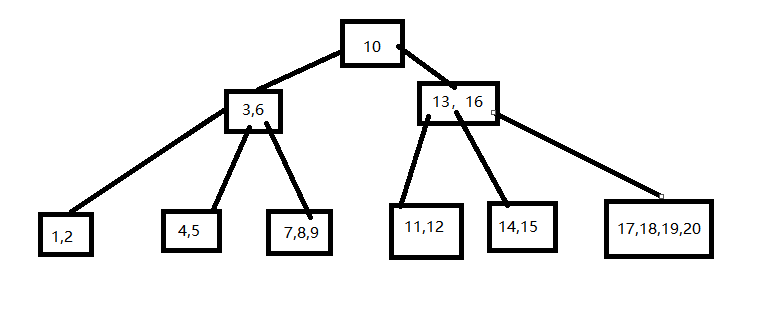
删除8操作,直接移除
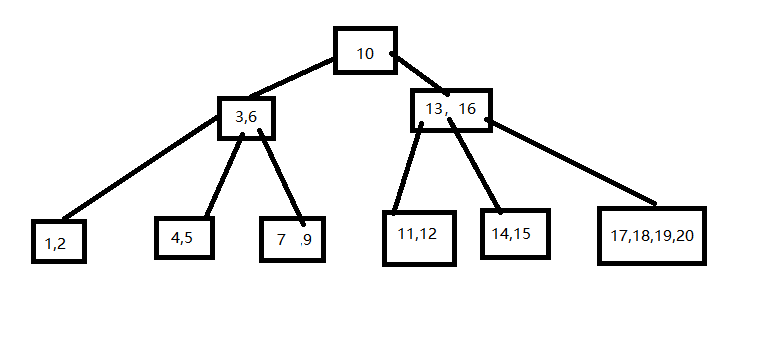
删除16操作,在右子树找最小关键字,赋值再删除
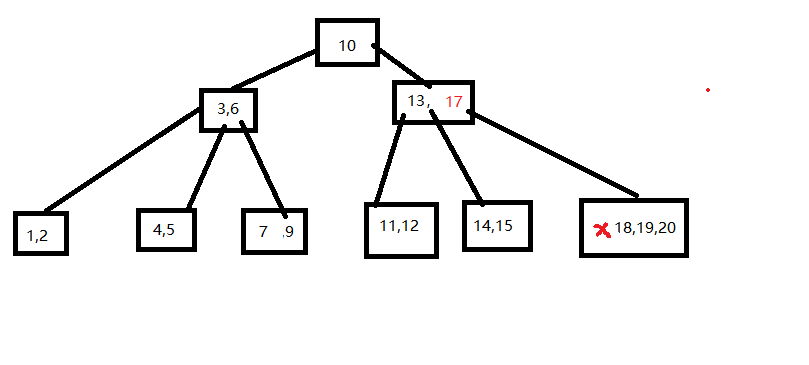
删除15操作,从兄弟结点中借
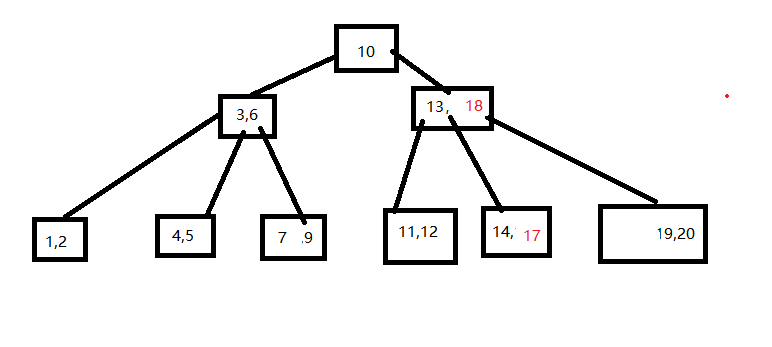
删除4操作需要进行合并
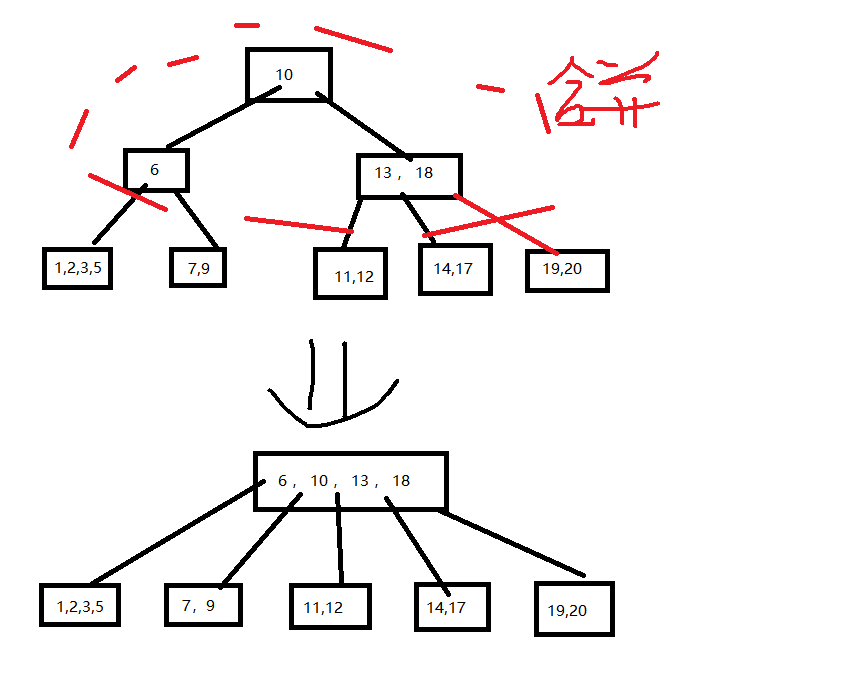
8.B+树
B+树的特点:
1)每个分支节点至多有m棵子树。
2)根节点或者没有子树,或者至少有两棵子树
3)除根节点,其他每个分支节点至少有m/2棵子树
4)有n棵子树的节点有n个关键字。
5)所有叶子节点包含全部关键字及指向相应记录的指针
散列查找
1.哈希表的概念
哈希表又称散列表,是除顺序表存储结构、链接表存储结构和索引表存储结构之外的又一种存储线性表的存储结构。哈希表是一种存储结构,它并非适合任何情况,主要适合记录的关键字与存储地址存在某种函数关系的数据。
2.哈希表设计
哈希表设计主要需要解决哈希冲突。实际中哈希冲突是难以避免的,主要与3个因素有关:
(1)哈希表长度(装填因子α=存储的记录个数/哈希表的大小=n/m )
(2)与所采用的哈希函数有关
(3)与解决冲突方法有关
3.哈希冲突的解决方法
开放地址法:即冲突时找一个新的空闲的哈希地址
(1)线性探查法
线性探查法的数学递推描述公式为:
d0=h(k)
di=(di-1+1) mod m (1≤i≤m-1)
线性探查法容易出现堆积现象:
举例说明:将关键字序列{7,8,30,11,18,9,14}散列存储到散列表中,散列表的存储空间是一个下标从0开始的一维数组,散列函数为:H(key)=(key×3) mod 7,要求装填(载)因子为0.7

(2)平方探查法
平方探查法的数学描述公式为:
d0=h(k)
di=(d0± i2) mod m (1≤i≤m-1)
如如{16,74,60,90,46,17,31,29,88,77}。h=k mod 13
h(16)=3,h(74)=9,h(60)=8,h(90)=12,h(46)=7,h(17)=4,h(31)=5
h(29)=3 出现冲突
h(88)=10
h(77)=12,出现冲突
出现冲突马上找空地址搜索:

分析时间性能ASL
按照上个例子:
成功ASL=(18+21+1*4)/10=1.4
不成功ASL=(2+1+1+9+8+7+6+5+4+3+2+1+3)/13=4.692
4.哈希表结构体定义:
#define MaxSize 100
#define NULLKEY -1
#define DELKEY -2
typedef char * InfoType ;
typedef struct{
int key;// 关键字域
InfoType data;//其他数据域
int count; //探查次数
}HashTable[MaxSize];
5.哈希表插入及建表
int InsertHT(HashTable ha,int p,int k,int &n)
{
计算k的哈希地址adr=k%p;
若ha[adr]=k,则已存在k,不需要插入
while(ha[adr]不为空 或ha[adr]不等删除标记 )
{ 线性探查k的位置。即adr=adr+1;
计算探查次数count }
ha[adr]=k;
哈希表长度增1
}
int InsertHT(HashTable ha,int p,int k,int &n){
int adr,i;
adr=k % p;
if(adr==NULLKEY || adr==DELKEY) //地址为空,可插入数据
{ ha[adr].key=k;ha[adr].count=1;}
else
{ i=1;
while(ha[adr].key!=NULLKEY && ha[adr].key!=DELKEY)
{
adr=(adr+1) % m;
i++;}//查找插入位置
ha[adr].key=k;ha[adr].count=i; //找到插入位置
}
n++;
}
哈希表查找算法
int SearchHT(HashTable ha,int p,int k)
{
int i=0,adr;
adr=k % p;
while(ha[adr].key!=NULLKEY && ha[adr].key!=k)
adr=(adr+1) % m;//探查下一个地址
if(ha[adr].key==NULLKEY) return -1;//地址为空,找不到
if(ha[adr].key==k) return adr; //找到关键字k
else return -1;
}
6.哈希链
举例:采用拉链法解决冲突的哈希表。
(16,74,60,43,54,90,46,31,29,88,77)

查找关键字为16的记录:
h(16)=16%13=3
p指向ha[3]的第1个结点,29≠16;
p指向ha[3]的第2个结点, 16=16
2次关键字比较
成功ASL=(19+22)/11=1.182
不成功ASL=(17+22)/13=0.846
7.哈希链相关算法
(1)哈希链结构体
typedef struct HashNode{
int key;
struct HashNode *next;
}HashNode,* HashTable;
HashTable ht[MAX];
(2)建哈希链
void CreateHash(HashTable ht[],int n)
{
建n条带头结点的哈希链,初始化链表;
for i=1 to k:
输入数据data
InsertHash(ht,data)
}
1.哈希链插入数据
InsertHash(ht,data)
{
计算哈希地址adr=data%P;
查找链ht[adr],存在不插入。
不存在:
data生成数据节点node
头插法插入链ht[adr]
}
2.哈希链删除数据
InsertHash(ht,data)
{
计算哈希地址adr=data%P;
若链ht[adr]不为空:
查找链ht[adr],找到删除
}
1.2.谈谈你对查找的认识及学习体会。
查找最主要的就是二叉树、平衡二叉树、哈希表以及各个ASL的时间性能的计算。
(1)二叉树
以判断这棵树是否为二叉排序树,如果输出的数值是从小到大,即为二叉排序树。二叉树的删除是比较复杂的,需要再多次复习学会操作。二叉排序树和树的内容紧紧结合在一起,所以树的内容也要相对应结合去解题。
(2)平衡二叉树
平衡二叉树是对二叉排序树的调整,在调整的过程中,在新插入向根方向查找第一个失衡点。
(3)哈希表和哈希链
哈希表要会构造,都知道它的长度是多少,散列表的长度是根据长度=元素个数/装填因子得出来。还有ASL的计算也非常容易出错,要清楚计算。哈希链主要就是在ASL的计算方面跟线性探查法的计算结果不一样。
2.PTA题目介绍
2.1 二叉搜索树的最近公共祖先






2.1.1 该题的设计思路
题面分析:
- 输入样例

- 存储方式
- 输入的第一行给出两个正整数:待查询的结点对数 M和二叉搜索树中结点个数 N。
- 随后一行给出 N 个不同的整数,为二叉搜索树的先序遍历序列。最后 M 行,每行给出一对整数键值 U 和 V。所有键值都在整型int范围内。
解题思路:
二叉排序树的查找和插入
二叉排序树可看做是一个有序表,所以在二叉排序树上进行查找,和二分查找类似,也是一个逐步缩小查找范围的过程。递归和非递归
BSTNode *SearchBST(BSTNode *bt,KeyType k)
{ if (bt==NULL || bt->key==k) //递归终结条件
return bt;
if (k<bt->key)
return SearchBST(bt->lchild,k); //在左子树中查找
else
return SearchBST(bt->rchild,k); //右子树中查找
}
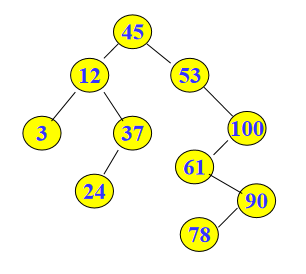
方法:该题先将输入的数据利用数组存储,并且调用函数生成一颗二叉搜索树,再利用每组进行判断祖先的关系;调用Search函数找到u和v的位置的关系,再通过LCA函数先判断是否找到uv再进行调用,最后通过判断来读取祖先的关系
时间复杂度:O(n)
2.1.2 该题的伪代码
# include头文件
结构体定义
int main()
{
//输入格式设置
定义 M, N, i, j, U, V;
定义 a[30];
输入节点对数和结点个数;
for (i = 0; i < N; i++)
{
输入数据存入数组;
}
//创建二叉搜索树
BTree bt;
bt = Create(a, N);
//判断祖先
for (j = 0; j < M; j++)
{
if (j != 0)
{
printf("\n");
}
输入U和V;
调用LCA函数;
}
return 0;
}
Node* Create(int a[],int n) //返回树根指针
{
初始时bt为空树;
定义 i = 0;
while (i)
{
调用Insert函数;//将A[i]插入二叉排序树T中
i++;
}
返回建立的二叉排序树的根指针
}
void Insert(BTree& bt, int e)
{
if (原树为空)
{
将第一个数据插入;
使其左右孩子为空;
}
else if (插入数据大于结点)
{
递归右子树;
}
else
{
递归调用左子树;
}
}
BTree Search(BTree bt, int u, int v)
{
if (原树为空)
{
返回空指针;
}
if (如果u和v分别处于改结点的左右两侧)
{
返回结点;
}
if (如果u或者v比结点数据小)
{
递归左子树;
}
if (如果u或者v比结点数据大)
{
递归右子树;
}
return bt;
}
int LCA(BTree bt, int u, int v, int a[], int n)
{
BTree p;
if (如果u和v都不在树结点中)
{
printf("ERROR: %d and %d are not found.", u, v);
}
else if (找到u而没有找到v)
{
printf("ERROR: %d is not found.", v);
}
else if (找到v没找到U)
{
printf("ERROR: %d is not found.", u);
}
else
{
p = Search(bt, u, v);
if (如果返回的结点数据等于u)
{
printf("%d is an ancestor of %d.", u, v);
}
else if (如果返回的结点数据等于v)
{
printf("%d is an ancestor of %d.", v, u);
}
else
{
printf("LCA of %d and %d is %d.", u, v, p->data);
}
}
return 0;
}
bool find(int e, int n, int a[])
{
定义 i;
for (i = 0; i < n; i++)
{
if (找到该结点)
return true;
}
return false;
}
2.1.3 PTA提交列表
Q1:部分正确,在输出的时候显示最近公共祖先显示的是根节点而不是最近的公共祖先
A1:通过改正Search函数和LCA函数中的return 的返回代码,由于没有成功调用,导致没有到最近的公共点去
Q2:在判断找到的结果的时候,没有全部调用正确
A2:在find函数中没有返回false,并且在find函数在LCA函数的调用中改正一下
2.1.4 本题设计的知识点
1.建立二叉树的基本的操作
2.二叉排序树的查找,通过查找来完成题目的判断
3.二叉排序树的插入
2.2是否完全二叉搜索树
解题代码:
#include<iostream>
#include<queue>
using namespace std;
typedef struct BSTNode
{
int data;
struct BSTNode* lchild;
struct BSTNode* rchild;
} BSTNode, * BSTree;
BSTNode* Create(int a[], int n);
void Insert(BSTree& bt, int e);
bool Judge(BSTree& T, int n);
void Print(BSTree& T, int n);
BSTNode* Create(int a[], int n)
{
BSTNode* bt = NULL;
int i = 0;
while (i < n)
{
Insert(bt, a[i]);
i++;
}
return bt;
}
void Insert(BSTree& bt, int e)
{
if (bt == NULL)
{
bt = new BSTNode;
bt->data = e;
bt->lchild = NULL;
bt->rchild = NULL;
}
else if (e < bt->data)
{
return Insert(bt->rchild, e);
}
else
{
return Insert(bt->lchild, e);
}
}
bool Judge(BSTree& T, int n)
{
queue<BSTree> q;
if (T == NULL)
return true;
int j = 0;
BSTree t;
q.push(T);
while ((t = q.front()) != NULL)
{
q.push(t->lchild); q.push(t->rchild);
q.pop();
j++;
}
if (j == n)
return true;
return false;
}
void Print(BSTree& T, int n)
{
int i = 0,a[100];
queue<BSTree> q;
BSTree bt;
q.push(T);
while (!q.empty())
{
bt = q.front();
a[i++] = bt->data;
if (bt->lchild != NULL)
{
q.push(bt->lchild);
}
if (bt->rchild != NULL)
{
q.push(bt->rchild);
}
q.pop();
}
cout << a[0];
for (int j = 1; j < n; j++)
{
cout << " " << a[j];
}
cout << endl;
}
int main()
{
int N;
cin >> N;
int b[100];
for (int i = 0; i < N; i++)
{
cin >> b[i];
}
BSTree Tree;
Tree = NULL;
Create(b, N);
if (Judge(Tree, N) == true)
{
Print(Tree, N);
cout << "YES" << endl;
}
else
{
Print(Tree, N);
cout << "NO" << endl;
}
}
2.2.1该题的设计思路
题面分析:
-
输入样例:
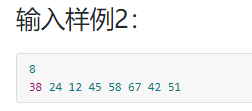
-
存储方式
给定一个二叉树结点,并且将其建立成一颗二叉树
解题思路:
完全二叉树:如果二叉树的深度为k,则除第k层外其余所有层节点的度都为2,且叶子节点从左到右依次存在。也即是,将满二叉树的最后一层从左到右依次删除若干节点就得到完全二叉树。满二叉树是一棵特殊的完全二叉树,但完全二叉树不一定是满二叉树。
完全二叉树的性质:
1.满二叉树是一棵特殊的完全二叉树,但完全二叉树不一定是满二叉树。
2.在满二叉树中最下一层,连续删除若干个节点得到完全二叉树。
3.在完全二叉树中,若某个节点没有左子树,则一定没有有子树。
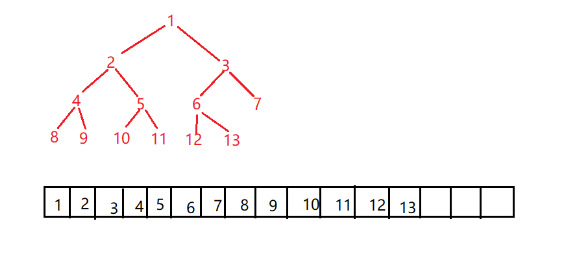
方法:首先该题要求左边值比较大,而且右边的值比较小;将输入的数据按照顺序建立成一颗二叉树,再通过层次遍历和完全二叉树的性质来判断出该树是否为一颗完全二叉树
时间复杂度:O(n²)
2.2.2该题的伪代码
int main()
{
输入结点个数;
定义 A数组;
for (int i = 0; i < N; i++)
{
输入数据并且存储入数组中;
}
BSTree Tree;
Create(A, N);//创建二叉搜索树
if (Judge(Tree, N) == true)
{
输出层序遍历的结果;
输出YES;
}
else
{
输出层序遍历的结果;
输出NO;
}
}
BSTNode* Create(int a[], int n)
{
初始时bt为空树;
定义 i = 0;
while (i)
{
调用Insert函数;
i++;
}
返回建立的二叉排序树的根指针
}
void Insert(BTree& bt, int e)
{
if (原树为空)
{
将第一个数据插入;
使其左右孩子为空;
}
else if (插入数据大于结点)
{
递归右子树;
}
else
{
递归调用左子树;
}
}
void Print(BSTree& T, int n)
{
i定义i = 0;
定义a[100];
根节点入队列;
while (队列不为空)
{
去队首元素;
if (左子树不为空)
{
左边结点入列;
}
if (右边不为空)
{
右边如队列;
}
Q.pop();
}
cout << a[0];//输出格式
for (int j = 1; j < n; j++)
{
cout << " " << a[j];
}
cout << endl;
}
bool Judge(BSTree& T, int n)
{
定义队列Q;
if (树为空)
return true;
else
{
根节点入列;
BSTree t;
while (没有遇到空结点则继续循环)
{
左子树和右子树分别入队列;
i++;
}
if (遇到空节点的时候的i值等于总结点数)
是完全二叉树
else
return false;
}
}
2.2.3PTA提交列表
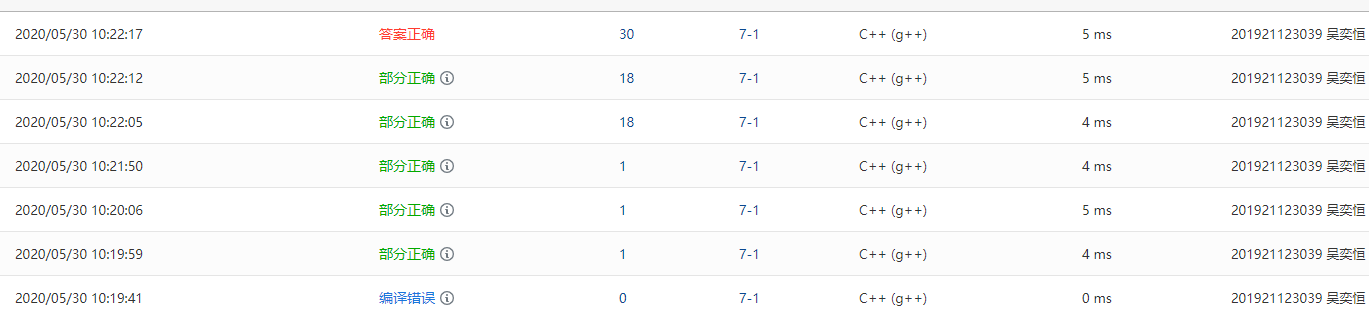
Q1:第一次的部分正确只有一分,本来发现调试也没有什么问题,就在输出的时候错了该题左值要求比较大
A1:在插入元素的部分函数将左子树的调用大小改掉
Q2:部分正确,在改正后,发现在判断是否为完全二叉树的代码出了问题
A2:在循环开始前要入队列根节点,加Q.push(T);
2.2.4本题设计的知识点
1.学会建立二叉树,将顺序按照题目要求插入
2.完全二叉树的性质
3.层次遍历的树操作
2.3 整型关键字的散列映射
解题代码:
#include<iostream>
#define NULLKEY -1
#define DELKEY -1
using namespace std;
typedef char* InfoType;
typedef struct node
{
int key;
InfoType data;
int count;
} Hash;
int Insert(Hash* ha, int k, int p)
{
int adr;
int counts;
adr = k % p;
counts = 1;
if (ha[adr].key == NULLKEY)
{
ha[adr].key = k;
ha[adr].count = counts;
}
else
{
while (ha[adr].key != NULLKEY && ha[adr].key != DELKEY)
{
if (k != ha[adr].key)
{
adr = (adr + 1) % p;
counts++;
}
else
{
return adr;
}
}
ha[adr].key = k;ha[adr].count = counts;
}
return adr;
}
void Create(Hash* ha, int n, int p)
{
int i,key,adr;
bool flag;
flag = true;
ha = new Hash[p];
for (i = 0; i < p; i++)
{
ha[i].key = NULLKEY;
}
for (i = 0; i < n; i++)
{
cin >> key;
adr = Insert(ha, key, p);
if (flag)
{
printf("%d", adr);
flag = false;
}
else
{
printf(" ");
printf("%d", adr);
}
}
}
int main()
{
int N, p;
Hash* ha;
cin >> N >> p;
Create(ha, N, p);
}
2.3.1该题的设计思路
题面分析:
- 首先该题要除留余数法定义的散列函数将关键字映射到长度为P的散列表中。用线性探测法解决冲突。P为散列表长度
解题思路:
哈希表:结构体定义好关键字域和探查次数,利用哈希表的概念来设计,以及哈希表的查找算法,将输入的数据导入哈希表中建立哈希表,再利用线性探查法来解决冲突的问题。
时间复杂度:O(n²)
2.3.2该题的伪代码
int Insert(Hash* ha, int k, int p)
{
计算k的哈希地址adr = k % p;
if (地址为空,可以插入数据)
{
插入k并且记录位置;
}
while (ha[adr]不为空或者不等删除标记)
{
if (线性探查k的位置,如果重复) return adr;
线性探查继续;
记录探查的次数;
}//查找插入位置
找到插入位置插入k;
}
void Create(Hash* ha, int n, int p)
{
初始化哈希表,并且赋值为空;
for (i = 0; i < n; i++)
{
输入关键字;
调用插入函数;
输出其再散列表的位置;
}
}
int main()
{
定义哈希表;
输入数值;
Create(ha, n, p);
}
2.3.3PTA提交列表
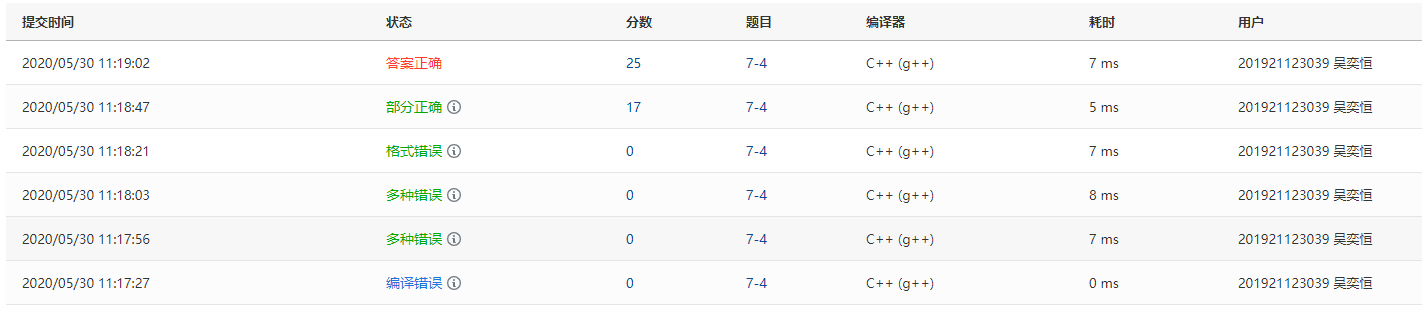
Q1:在部分正确那里,根据课件的代码,在线性重新探查的时候,写下的是adr=adr+1
A1:改成adr=(adr+1)%p
Q2:格式错误,在输出的时候输出格式错误
A2:在最后更改格式输出
2.3.4本题设计的知识点
1.线性探查法解决冲突问题
2.哈希表的建立
3.哈希表查找算法

