

[SPDK/NVMe存储技术分析]013 - libibverbs API应用案例分析
本文是对论文Dissecting a Small InfiniBand Application Using the Verbs API所做的中英文对照翻译
Dissecting a Small InfiniBand Application Using the Verbs API
Gregory Kerr∗
College of Computer and Information Science
Northeastern University
Boston, MA
kerrg@ccs.neu.edu
Abstract | 摘要
InfiniBand is a switched fabric interconnect. The InfiniBand specification does not define an API. However the OFED package, libibverbs, has become the default API on Linux and Solaris systems. Sparse documentation exists for the verbs API. The simplest InfiniBand program provided by OFED, ibv_rc_pingpong, is about 800 lines long. The semantics of using the verbs API for this program is not obvious to the first time reader. This paper will dissect the ibv_rc_pingpong program in an attempt to make clear to users how to interact with verbs. This work was motivated by an ongoing project to include direct InfiniBand support for the DMTCP checkpointing package.
InfiniBand是一种基于交换结构的网络互连方式。InfiniBand标准并没有定义API。然而,OFED软件包(libibverbs)已经成为了Linux和Solaris系统默认的API。一些稀疏的文档存在于verbs API中。OFED提供了一个最简单的IB程序(ibv_rc_pingpong),约800行代码。在这个程序中,使用的API的语义对第一次接触verbs的读者来说并不那么容易理解。本文将剖析ibv_rc_pingpong程序,以帮助读者弄清楚如何与verbs打交道。之所以写作本文,是因为一个正在进行的项目,该项目将在DMTCP检查点软件包中包含对IB的直接支持。
1 Introduction | 概述
The program ibv_rc_pingpong can be found at openfabrics.org, under the "examples/" directory of the OFED tarball. The source code used for this document is from version 1.1.4. The ibv_rc_pingpong program sets up a connection between two nodes running InfiniBand adapters and transfers data. Let's begin by looking at the program in action. In this paper, I will refer to two nodes: client and server. There are various command line flags that may be set when running the program. It is important to note that the information contained within this document is based on the assumption that the program has been run with no command line flags configured. Configuring these flags will alter much of the program's behavior.
程序ibv_rc_pingpong可以在penfabrics.org上找到,位于OFED压缩包的"examples/"目录下面。本文使用的源代码版本是1.1.4。程序ibv_rc_pingpong在两个具有IB适配器的节点之间建立连接并进行数据传输。让我们从看程序代码开始。在本文中,我将提及两个结点:client和server。当运行程序的时候,可以设置各种命令行标志。值得注意的是,本文中包含的信息基于一个假定,即该程序在运行时没有配置命令行标志。如果配置这些标志的话,将改变程序的许多行为。
Since both nodes run the same executable, the "client" is the instance that is launched with a hostname as an argument. The LID, QPN, and PSN will be explained later.
由于两个节点都运行相同的可执行文件,"client"是一个使用主机名作为参数的启动的实例。有关LID、QPN和PSN将稍后做解释。
[user@server]$ ibv_rc_pingpong local address: LID 0x0008, QPN 0x580048, PSN 0x2a166f, GID :: remote address: LID 0x0003, QPN 0x580048, PSN 0x5c3f21, GID :: 8192000 bytes in 0.01 seconds = 5167.64 Mbit/sec 1000 iters in 0.01 seconds = 12.68 usec/iter [user@client]$ ibv_rc_pingpong server local address: LID 0x0003, QPN 0x580048, PSN 0x5c3f21, GID :: remote address: LID 0x0008, QPN 0x580048, PSN 0x2a166f, GID :: 8192000 bytes in 0.01 seconds = 5217.83 Mbit/sec 1000 iters in 0.01 seconds = 12.56 usec/iter
Before we delve into the actual code, please look at a list of all verbs API functions which will be used for our purposes. I encourage the reader to pause and read the man page for each of these.
在深入研究实际代码之前,请看一下我们将用到的verbs API列表。读者朋友不妨暂停一下,先阅读一下这些API的man页面。
1 ibv_get_device_list(3) 2 ibv_open_device(3) 3 ibv_alloc_pd(3) 4 ibv_reg_mr(3) 5 ibv_create_cq(3) 6 ibv_create_qp(3) 7 ibv_modify_qp(3) 8 ibv_post_recv(3) 9 ibv_post_send(3) 10 ibv_poll_cq(3) 11 ibv_ack_cq_events(3)
2 Layers | 分层
There are multiple drivers, existing in kernel and userspace, involved in a connection. See Figure 2a. To explain it simply, much of the connection setup work goes through the kernel driver, as speed is not a critical concern in that area.
在内核和用户空间,有多个驱动参与连接。请参见图2a。简单地说,大部分连接安装工作都是通过内核驱动完成,因为速度对建立连接来说并不关键。

The user space drivers are involved in function calls such as ibv_post_send and ibv_post_recv. Instead of going through kernel space, they interact directly with the hardware by writing to a segment of mapped memory. Avoiding kernel traps is one way to decrease the overall latency of each operation.
用户空间设备驱动参与到函数调用之中,例如ibv_post_send和ibv_post_recv。它们不经过内核空间,而是通过对内存映射段执行写操作来直接与硬件打交道。避免陷入内核是降低单个操作的总时延的一种方法。
3 Remote Direct Memory Access | RDMA(远程直接内存访问)
One of the key concepts in InfiniBand is Remote Direct Memory Access (RDMA). This allows a node to directly access the memory of another node on the subnet, without involving the remote CPU or software layers.
IB的核心概念之一就是RDMA(远程直接内存访问)。这允许一个结点直接访问子网内的另一个结点的系统内存,而不需要远端CPU或者软件层的干预。
Remember the key concepts of Direct Memory Access (DMA) as illustrated by Figure 2b.
图2b演示了DMA(直接内存访问)的核心概念。
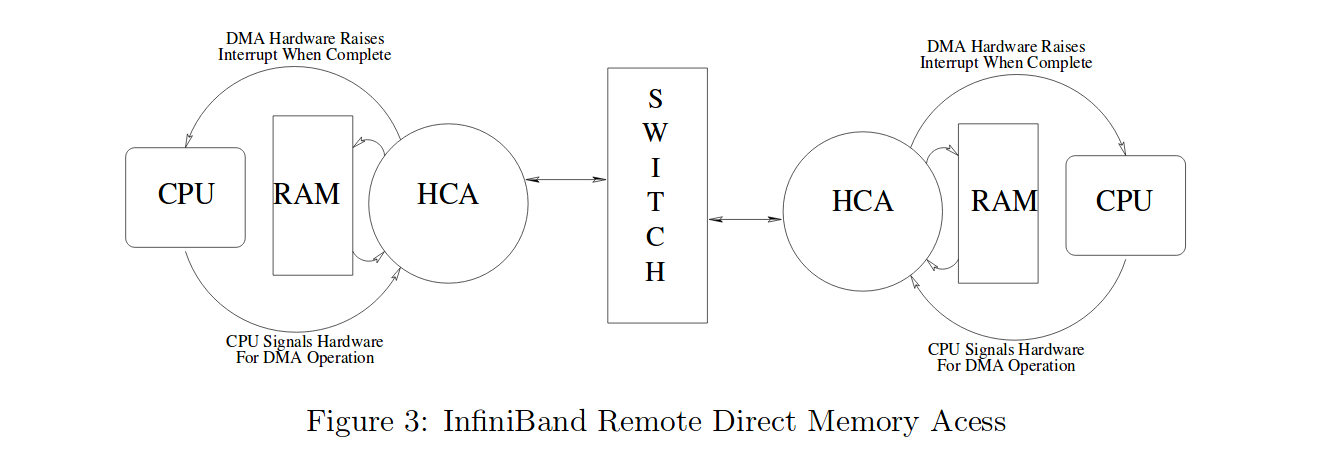
In the DMA, the CPU sends a command to the hardware to begin a DMA operation. When the operation finishes, the DMA hardware raises an interrupt with the CPU, signaling completion. The RDMA concept used in InfiniBand is similar to DMA, except with two nodes accessing each other's memory; one node is the sender and one is the receiver.
在DMA中,CPU给硬件发送一个开始DMA操作的命令。当操作完成后,DMA硬件引发一个中断高速CPU, DMA操作已经完成。用在InfiniBand中RDMA概念与DMA类似,两个节点相互访问对方的系统内存,一个结点为sender(发送方), 另一个结点为receiver(接收方)。
Figure 3 illustrates an InfiniBand connection. In this case the DMA Hardware is the Host Channel Adapter (HCA), and the two HCAs are connected, through a switch, to each other. The HCA is InfiniBand's version of a network card; it is the hardware local to each node that facilitates communications. This allows an HCA on one node to use another HCA to perform DMA operations on a remote node.
图3演示了IB连接。在这个示例中,DMA硬件是HCA(主机通道适配器)。两个结点各有一个HCA,通过交换机互联。HCA就是InfiniBand的网卡。它是每个结点用来通信的硬件。这允许一个节点上的HCA使用另一个结点上的HCA来在远程节点上执行DMA操作。
4 Overview | 概要
The ibv_rc_pingpong program does the following.
程序ibv_rc_pingpong做了如下6件事情。
- Reserves memory from the operating system for sending and receiving data 在操作系统中申请内存,为发送和接收数据做准备
- Allocates resources from the verbs API 从verbs API中申请资源
- Uses a TCP socket to exchange InfiniBand connection information 使用TCP socket交换IB连接信息
- Creates a connection between two InfiniBand ports 在两个IB端口中创建一个连接
- Transfers data over the connection 在连接上传输数据
- Acknowledges the successful completion of the transfer 在传输成功完成后给一个ACK
5 Data Transfer Modes | 数据传输模型
The InfiniBand specification states four different connection types: Reliable Connection (RC), Unreliable Connection (UC), Reliable Datagram (RD), Unreliable Datagram (UD). This program, ibv_rc_pingpong uses a simple RC model. RD is not supported by current hardware.
InfiniBand技术规范定义了四种不同的连接类型:可靠连接(RC)、不可靠连接(UC)、可靠数据报(RD)和不可靠数据报(UD)。ibv_rc_pingpong程序使用的是简单的可靠连接(RC)。目前硬件不支持可靠数据报(RD)。
The difference between reliable and unreliable is predictable -- in a reliable connection data is transferred in order and guaranteed to arrive. In an unreliable connection neither of those guarantees is made.
可靠与不可靠的区别在于是否可预测 -- 在可靠连接中,数据按顺序到达并保证能够到达。在不可靠连接中,这两项都保证不了。
A connection type is an association strictly between two hosts. In a datagram, a host is free to communicate with any other host on the subnet.
连接类型是主机之间的严格关联。在数据报中,主机可以自由地与子网上的任何其他主机进行通信。
6 Queue Based Model | 基于队列的模型
The InfiniBand hardware processes requests from the client software through requests, which are placed into queues. To send messages between nodes, each node must have at minimum three queues: a Send Queue (SQ), Receive Queue (RQ), and Completion Queue (CQ).
IB硬件处理来自client的请求是通过把请求放置到队列上。在两个结点之间发送数据,每一个结点至少包含3个队列:发送队列(SQ)、接收队列(RQ)和完成队列(CQ)。
In a reliable connection, used in the ibv_rc_pingpong program, queue pairs on two distinct hosts compromise an end-to-end context. They send messages to each other, and only each other. This paper restricts itself to this mode.
在用于ibv_rc_pingpong程序的可靠连接中,两个独立的主机之间的QP(队列对)协商一个端到端的上下文。他们互相传递信息,而且只在彼此之间。本文的讨论仅限于这一模式。
The queues themselves exist on the HCA. However the libibverbs will return to the user a data structure which corresponds with the QP. While the library will create the QP, the user assumes the responsibility of "connecting" the QP with the remote node. This is generally done by opening an out-of-band socket connection, trading the identification numbers for the queues, and then updating the hardware with the information.
队列本身存在于HCA硬件上。libibverbs将返回一个跟QP一致关联的数据结构给用户。QP的创建由libibverbs函数库负责,但连接远端结点的QP则由用户自己负责。通常的实现是打开一个带外socket连接,为队列交换标识符,然后把信息更新到硬件上。
More recently, librdma_cm (an OFED library for connection management) allows a user to create and connect QPs through library calls reminiscent of POSIX sockets. Those calls are outside the scope of this document.
最近,librdma_cm(OFED针对连接管理发布的函数库)允许用户创建和连接QP, 通过调用POSIX socket。这些调用不在本文的讨论范围之内。
6.1 Posting Work Requests to Queues | 给队列里放置工作请求
To send and receive data in the InfiniBand connection (end-to-end context), work requests, which become Work Queue Entries (WQE, pronounced "wookie") are posted to the appropriate queue. These work requests point to lists of scatter/gather elements (each element has an address and size associated with it). This is a means of writing to and reading from buffers which are non-contiguous in memory.
在InfiniBand连接(即是端到端的上下文)中发送和接收数据,工作请求(即工作队列元素,WQE,发音为wookie)被放置到相应的队列中。这些工作请求指向一个分散/聚合元素(SGE)的列表(每个元素都有一个虚拟内存地址和与之相关联的缓冲区大小)。这是一种在非连续的内存缓冲区中写入和读取数据的方法。
The memory buffers must be registered with the hardware; that process is explained later. Memory buffers must be posted to the receive queue before the remote host can post any sends. The ibv_rc_pingpong program posts numerous buffers to the receive queue at the beginning of execution, and then repopulates the queue as necessary. A receive queue entry is processed when the remote host posts a send operation.
内存缓冲区必须在硬件中注册,注册过程稍后予以解释。在远程主机放置任何发送请求到发送队列之前,内存缓冲区必须在放置到接收队列。ibv_rc_pingpong程序在开始执行的时候放置大量的缓存区到发送队列,然后在必要的时候重新填充队列。当远程主机放置一个发送操作的时候,接收队列条目将被处理。
When the hardware processes the work request, a Completion Queue Entry (CQE, pronounced "cookie") is placed on the CQ. There is a sample of code showing how to handle completion events in ibv_ack_cq_events(3).
当硬件处理一个工作请求(WR)的时候,一个完成队列条目(CQE,发音为cookie)被放置到完成队列(CQ)中。在ibv_ack_cq_events(3)中,有样本代码演示如何处理完成事件。
7 Connecting the Calls | 连接使用的函数调用
The table below which the function calls used in ibv_rc_pingpong to create a connection, and the order in which they are called.
在下表中,列出了ibv_rc_pingpong创建一个连接使用的函数以及调用顺序。

This table introduces the resources which are allocated in the process of creating a connection. These resources will be explained in detail later.
上面的表格也介绍了在创建一个连接中分配的资源,对这些资源稍后做解释。
8 Allocating Resources | 分配资源
8.1 Creating a Context | 创建上下文
The first function call to the verbs API made by the ibv_rc_pingpong source code is here:
619 dev_list = ibv_get_device_list(NULL);
As the man page states, this function returns a list of available HCAs.
ibv_rc_pingpong源代码调用的第一个verbs API就是ibv_get_device_list(), 该函数在手册里有明确说明,返回一个可用的HCA列表。
The argument to the function is an optional pointer to an int, which the library uses to specify the size of the list.
该函数的参数是一个可选的执行int的指针,用来指定列表的长度。
Next it populates the pingpong_context structure with the function pp_init_ctx.
接下来,在函数pp_init_ctx填充pingpong_context结构体。
The pingpong_context structure wraps all the resources associated with a connection into one unit.
pingpong_context结构体包装了与连接相关联的所有分配的资源。
/* Listing 1: struct pingpong context */ 59 struct pingpong_context { 60 struct ibv_context *context; 61 struct ibv_comp_channel *channel; 62 struct ibv_pd *pd; 63 struct ibv_mr *mr; 64 struct ibv_cq *cq; 65 struct ibv_qp *qp; 66 void *buf; 67 int size; 68 int rx_depth; 69 int pending; 70 struct ibv_port_attr portinfo; 71 };
/* Listing 2: Initializing the struct pingpong context */ 643 ctx = pp_init_ctx(ib_dev, size, rx_depth, ib_port, use_event, !servername);
The ib_dev argument is a struct device * and comes from dev_list. The argument size specifies the size of the message to be sent (4096 bytes by default), rx_depth sets the number of receives to post at a time, ib_port is the port of the HCA and use_event specifies whether to sleep on CQ events or poll for them.
参数ib_dev来自于dev_list, 类型为struct device *。参数size指定发送的消息长度(默认4096字节),rx_depth设置一次放置到接收队列的接收请求的个数(即接收队列深度),ib_port是HCA的port,use_event指定是在CQ事件上睡眠或还是进行轮询。
The function pp_init_ctx first allocates a buffer of memory, which will be used to send and receive data. Note that the buffer is memalign-ed to a page, since it is pinned (see section 8.3 for a definition of pinning).
函数pp_init_ctx首先分配内存缓冲区,用于发送和接收数据。注意缓冲区是按页对齐的,由于该缓冲区是需要被凝固的(有关pinning的定义,请参见8.3节)。
/* Listing 3: Allocating a Buffer */ 320 ctx->buf = memalign(page_size, size); 321 if (!ctx->buf) { 322 fprintf(stderr, "Couldn't allocate work buf.\n"); 323 return NULL; 324 } 325 326 memset(ctx->buf, 0x7b + is_server, size);
Next the ibv_context pointer is populated with a call to ibv_open_device. The ibv_context is a structure which encapsulates information about the device opened for the connection.
接下来,ibv_context指针被赋值,通过调用ibv_open_device()。ibv_context是一个结构体,封装了为建立连接而打开的设备信息。
/* Listing 4: Opening a Context */ 328 ctx->context = ibv_open_device(ib_dev); 329 if (!ctx->context) { 330 fprintf(stderr, "Couldn't get context for %s\n", 331 ibv_get_device_name(ib_dev)); 332 return NULL; 333 }
From the "infiniband/verbs.h" header, the struct ibv_context is as follows:
结构体ibv_context来自头文件"infiniband/verbs.h",如下所示:
/* Listing 5: struct ibv_context */ 766 struct ibv_context { 767 struct ibv_device *device; 768 struct ibv_context_ops ops; 769 int cmd_fd; 770 int async_fd; 771 int num_comp_vectors; 772 pthread_mutex_t mutex; 773 void *abi_compat; 774 struct ibv_more_ops *more_ops; 775 };
The struct ibv_device * is a pointer to the device opened for this connection. The struct ibv_context_ops ops field contains function pointers to driver specific functions, which the user need not access directly.
结构ibv_device *是一个指向为建立连接而打开的设备的指针。结构ibv_context_ops ops域包含了一系列函数指针,这些函数指针执行驱动程序的具体功能,用户不需要直接访问这些函数指针。
8.2 Protection Domain | 保护域
After the device is opened and the context is created, the program allocates a protection domain.
在设备被打开和上下文创建完毕之后,程序分配一个保护域(PD)。
/* Listing 6: Opening a Protection Domain */ 344 ctx->pd = ibv_alloc_pd(ctx->context); 345 if (!ctx->pd) { 346 fprintf(stderr, "Couldn't allocate PD\n"); 347 return NULL; 348 }
A protection domain, according to the InfiniBand specification, allows the client to control which remote computers can access its memory regions during InfiniBand sends and receives.
根据IB的技术规范,保护域(PD)允许cient在IB发送和接收过程中,控制它的内存区域,该内存取可以被远程电脑访问。
The protection domain mostly exists on the hardware itself. Its user-space data structure is sparse:
保护域(PD)主要存在于硬件本身。其用户空间数据结构实为稀疏:
/* Listing 7: struct ibv_pd from "infiniband/verbs.h" */ 308 struct ibv_pd { 309 struct ibv_context *context; 310 uint32_t handle; 311 };
8.3 Memory Region | 内存区域
The ibv_rc_pingpong program next registers one memory region with the hardware.
接下来ibv_rc_pingpong程序注册一段内存区域(MR),该区域将被硬件访问。
When the memory region is registered, two things happen. The memory is pinned by the kernel, which prevents the physical address from being swapped to disk. On Linux operating systems, a call to mlock is used to perform this operation. In addition, a translation of the virtual address to the physical address is given to the HCA.
当内存区域(MR)注册了,有两件事情将发生。(首先,) 内存被内核锁定,防止物理地址(内存里存放的数据)被交换到硬盘上。在Linux操作系统中,使用mlock调用来执行这一操作。其次,(HCA驱动)将虚拟内存地址转换为物理内存地址,然后将这一对应关系交给HCA硬件去使用。
/* Listing 8: Registering a Memory Region */ 350 ctx->mr = ibv_reg_mr(ctx->pd, ctx->buf, size, IBV_ACCESS_LOCAL_WRITE); 351 if (!ctx->mr) { 352 fprintf(stderr, "Couldn't register MR\n"); 353 return NULL; 354 }
The arguments are the protection domain with which to associate the memory region, the address of the region itself, the size, and the flags. The options for the flags are defined in "infiniband/verbs.h".
参数是与MR相关联的PD, MR本身的地址,大小和标志。标志选项的定义在文件"infiniband/verbs.h"里。
/* Listing 9: Access Flags */ 300 enum ibv_access_flags { 301 IBV_ACCESS_LOCAL_WRITE = 1, 302 IBV_ACCESS_REMOTE_WRITE = (1<<1), 303 IBV_ACCESS_REMOTE_READ = (1<<2), 304 IBV_ACCESS_REMOTE_ATOMIC = (1<<3), 305 IBV_ACCESS_MW_BIND = (1<<4) 306 };
When the memory registration is complete, an lkey field or Local Key is created. According to the InfiniBand Technical Specification the lkey is used to identify the appropriate memory addresses and provide authorization to access them.
当内存注册(MR)完成的时候,lkey(或Local Key)字段就创建好了。根据IB的技术规范,lkey用来确定合适的内存地址和提供访问授权。
8.4 Completion Queue | 完成队列
The next part of the connection is the completion queue (CQ), where work completion queue entries are posted. Please note that you must create the CQ before the QP. As stated previously, ibv_ack_cq_events(3) has helpful examples of how to manage completion events.
建立连接的接下来的一部分是创建完成队列(CQ),工作完成条目(CQE)被放置到完成队列(CQ)上。请注意,必须在创建QP之前创建CQ。如何管理完成事件,前面提及的ibv_ack_cq_events(3)中例子可供参考。
/* Listing 10: Creating a CQ */ 356 ctx->cq = ibv_create_cq(ctx->context, rx_depth + 1, NULL, 357 ctx->channel, 0); 358 if (!ctx->cq) { 359 fprintf(stderr, "Couldn't create CQ\n"); 360 return NULL; 361 }
8.5 Queue Pairs | 队列对
Communication in InfiniBand is based on the concept of queue pairs. Each queue pair contains a send queue and a receive queue, and must be associated with at least one completion queue. The queues themselves exist on the HCA. A data structure containing a reference to the hardware queue pair resources is returned to the user.
在IB中,通信是基于队列对(QP)的概念而实现。每一个队列对(QP)包含有一个发送队列(SQ)和接收队列(RQ),并且必须与至少一个完成队列(CQ)相关联(换言之,一个QP中的SQ和RQ可以关联到同一个CQ上)。这些队列(SQ, RQ和CQ)都存在于HCA硬件上。一个包含有对硬件QP资源的引用的数据结构,被返回给用户使用。
First, look at the code to create a QP.
首先,让我们看看创建一个QP的源代码。
/* Listing 11: Creating a QP */ 364 struct ibv_qp_init_attr attr = { 365 .send_cq = ctx->cq, 366 .recv_cq = ctx->cq, 367 .cap = { 368 .max_send_wr = 1, 369 .max_recv_wr = rx_depth, 370 .max_send_sge = 1, 371 .max_recv_sge = 1 372 }, 373 .qp_type = IBV_QPT_RC 374 }; 375 376 ctx->qp = ibv_create_qp(ctx->pd, &attr); 377 if (!ctx->qp) { 378 fprintf(stderr, "Couldn't create QP\n"); 379 return NULL; 380 }
Notice that a data structure which defines the initial attributes of the QP must be given as an argument. There are a few other elements in the data structure, which are optional to define.
注意,定义QP初始属性的数据结构必须作为一个参数传递。在这个数据结构中,有一些元素是可选的。
The first two elements, send_cq and recv_cq, associate the QP with a CQ as stated earlier. The send and receive queue may be associated with the same completion queue.
前两个元素是send_cq和recv_cq,(如前面所说)是与QP相关联的完成队列(CQ)。发送队列和接收队列可能关联到同一个完成队列上。
The cap field points to a struct ibv_qp_cap and specifies how many send and receive work requests the queues can hold. The max_{send, recv}_sge field specifies the maximum number of scatter/gather elements that each work request will be able to hold. A scatter gather element is used in a direct memory access (DMA) operation, and each SGE points to a buffer in memory to be used in the read or write. In this case, the attributes state that only one buffer may be pointed to at any given time.
字段cap指向一个结构体struct ibv_qp_cap, 指定可以容纳的发送和接收工作请求的个数。max_{send, recv}_sge字段指定了每一个工作请求能够容纳的最大的SGE数目。一个SGE用来做DMA操作,每一个SGE指向一个可用于读/写的内存缓冲区。在这个例子中,属性状态说明了在任何给定的时间内仅指向一个缓冲区。
The qp_type field specifies what type of connection is to be used, in this case a reliable connection.
qp_type字段指定了使用的连接类型,在这里是可靠连接(RC)。
Now the queue pair has been created. It must be moved into the initialized state, which involves a library call. In the initialized state, the QP will silently drop any incoming packets and no work requests can be posted to the send queue.
现在QP已经创建好了。必须通过库函数调用将它的状态设置为初始化状态。在初始化状态下,任何传入的数据包将被QP悄悄地丢弃,并且工作请求不能够被放置到发送队列上。
/* Listing 12: Setting QP to INIT */ 384 struct ibv_qp_attr attr = { 385 .qp_state = IBV_QPS_INIT, 386 .pkey_index = 0, 387 .port_num = port, 388 .qp_access_flags = 0 389 }; 390 391 if (ibv_modify_qp(ctx->qp, &attr, 392 IBV_QP_STATE | 393 IBV_QP_PKEY_INDEX | 394 IBV_QP_PORT | 395 IBV_QP_ACCESS_FLAGS)) { 396 fprintf(stderr, "Failed to modify QP to INIT\n"); 397 return NULL; 398 }
The third argument to ibv_modify_qp is a bitmask stating which options should be configured. The flags are specified in enum ibv_qp_attr_mask in "infiniband/verbs.h".
ibv_modify_qp()的第3个参数是一个位掩码,说明应该配置的选项。flags在头文件"infiniband/verbs.h"的枚举体ibv_qp_attr_mask中定义。
At this point the ibv_rc_pingpong program posts a receive work request to the QP.
在这里,ibv_rc_pingpong程序放置一个接收工作请求到QP上。
650 routs = pp_post_recv(ctx, ctx->rx_depth);
Look at the definition of pp_post_recv.
看一下pp_post_recv的定义。
/* Listing 13: Posting Recv Requests */ 444 static int pp_post_recv(struct pingpong_context *ctx, int n) 445 { 446 struct ibv_sge list = { 447 .addr = (uintptr_t) ctx->buf, 448 .length = ctx->size, 449 .lkey = ctx->mr->lkey 450 }; 451 struct ibv_recv_wr wr = { 452 .wr_id = PINGPONG_RECV_WRID, 453 .sg_list = &list, 454 .num_sge = 1, 455 }; 456 struct ibv_recv_wr *bad_wr; 457 int i; 458 459 for (i = 0; i < n; ++i) 460 if (ibv_post_recv(ctx->qp, &wr, &bad_wr)) 461 break; 462 463 return i; 464 }
The ibv_sge list is the list pointing to the scatter/gather elements (in this case, a list of size 1). To review, the SGE is a pointer to a memory region which the HCA can read to or write from.
ibv_sge列表是指向SGE数组的列表(在这里,列表长度为1)。SGE指向一个内存区域,该区域能被HCA读写。
Next is the ibv_recv_wr structure. The first field, wr_id, is a field set by the program to identify the work request. This is needed when checking the completion queue elements; it specifies which work request completed.
下一个结构体是ibv_recv_wr。第一个字段wr_id由应用程序设置,以标识对应的WR。在检查完成队列元素时需要wr_id,它指定了哪一个WR已经完成了。
The work request given to ibv_post_recv is actually a linked list, of length 1.
传给ibv_post_recv()的WR实际上是一个长度为1的链表。
/* Listing 14: Linked List */ 451 struct ibv_recv_wr wr = { 452 .wr_id = PINGPONG_RECV_WRID, 453 .sg_list = &list, 454 .num_sge = 1, 455 };
If one of the work requests fails, the library will set the bad_wr pointer to the failed wr in the linked list.
如果一个WR执行失败了,那么库函数就将bad_wr指向在此链表中失败的那个wr。
Receive buffers must be posted before any sends. It is common practice to loop over the ibv_post_recv call to post numerous buffers at the beginning of execution. Eventually these buffers will be used up; internal flow control must be implemented by the applications to ensure that sends are not posted without corresponding receives.
接收缓冲区必须在发送之前放置到SQ上。 通常的做法是在执行开始的时候循环调用ibv_post_recv()将多个buffer放置到接收队列上。最终这些buffer将被全部消耗掉。应用程序必须实现内部的流量控制,以确保在远端没有准备好接收的情况下不放置任何发送请求到SQ上。
8.6 Connecting | 连接
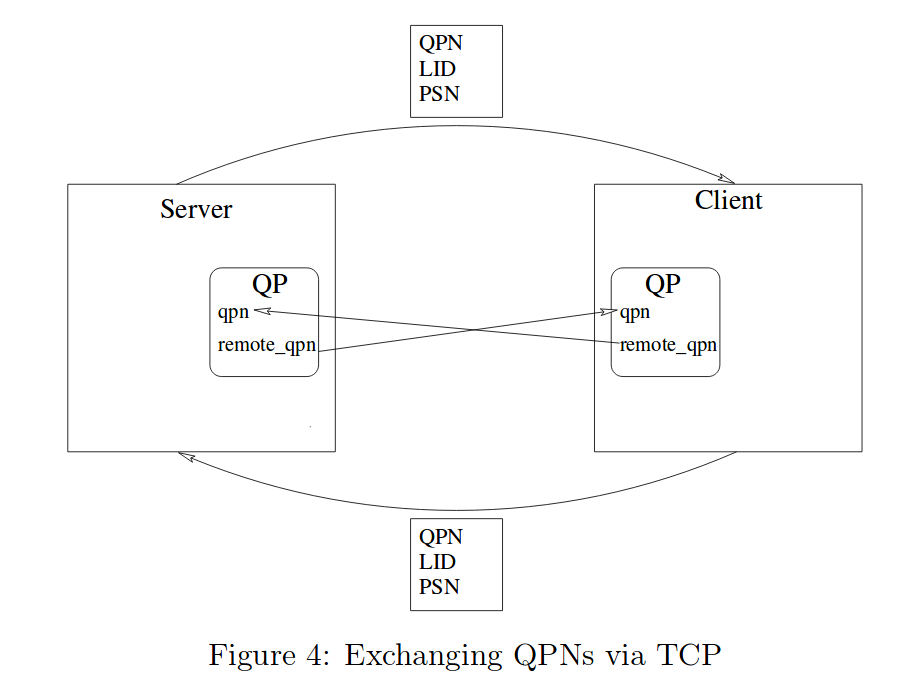
The next step occurs in pp_client_exch_dest and pp_server_exch_dest. The QPs need to be configured to point to a matching QP on a remote node. However, the QPs currently have no means of locating each other. The processes open an out-of-band TCP socket and transmit the needed information. That information, once manually communicated, is given to the driver and then each side's QP is configured to point at the other. (The OFED librdma_cm library is an alternative to explicit out-of-band TCP.)
下一步发生在pp_client_exch_dest和pp_server_exch_dest中。QP需要配置一下,指向远端结点的QP。然而,目前QP没有定位对方的方法。进程打开带外TCP socket并传输所需要的信息。这些信息传递给驱动,然后每一方的QP就被配置为指向另一方的QP。(使用OFED的librdma_cm库,可以用来替代显式的TCP带外数据。)
So what information needs to be exchanged/configured? Mainly the LID, QPN, and PSN. The LID is the "Local Identifier" and it is a unique number given to each port when it becomes active. The QPN is the Queue Pair Number, and it is the identifier assigned to each queue on the HCA. This is used to specify to what queue messages should be sent. Finally, the destinations must share their PSNs.
那么,哪些信息需要交换和配置? LID, QPN和PSN。 LID是本地ID的缩写,当一个port变成活跃状态的时候,port就被分配了一个独一无二的数字。QPN是QP Number的缩写,是在HCA上分配给每一个队列的标识符。QPN用来指定消息发送到哪个队列上去。最后,目标必须共享它们的PSN。
The PSN stands for Packet Sequence Number. In a reliable connection it is used by the HCA to verify that packets are coming in order and that packets are not missing. The initial PSN, for the first packet, must be specified by the user code. If it is too similar to a recently used PSN, the hardware will assume that the incoming packets are stale packets from an old connection and reject them.
PSN代表的是包序列号。在可靠连接中,HCA用PSN来保证一个个数据包是有序到达的而且没有丢包。第一个数据包最初的PSN,必须由用户代码指定。如果PSN与最近使用的一个PSN很相似的话,硬件就假定传入的数据包是一个陈腐的包,来自一个旧连接,然后予以拒绝。
The GID, seen in the code sample below, is a 128-bit unicast or multicast identifier used to identify an endport. The link layer specifies which interconnect the software is running on; there are other interconnects that OFED supports, though that is not within the scope of this paper.
在下面的代码示例中,GID是一个128位的单播或者多播的标识符,用来标识一个终端端口。链路层指定了软件在哪种互联协议上运行。OFED还支持除IB之外的其他互联协议,那些协议不在本论文的讨论范围之内。
Within pp_connect_ctx the information, once transmitted, is used to connect the QPs into an end-to-end context.
在pp_connect_ctx之中的信息,一旦传输完成,就用于连接QP对到一个端到端的上下文中。
/* Listing 15: Setting Up Destination Information */ 665 my_dest.lid = ctx->portinfo.lid; 666 if (ctx->portinfo.link_layer == IBV_LINK_LAYER_INFINIBAND && !my_dest.lid) { 667 fprintf(stderr, "Couldn't get local LID\n"); 668 return 1; 669 } 670 671 if (gidx >= 0) { 672 if (ibv_query_gid(ctx->context, ib_port, gidx, &my_dest.gid)) { 673 fprintf(stderr, "Could not get local gid for gid index %d\n", gidx); 674 return 1; 675 } 676 } else 677 memset(&my_dest.gid, 0, sizeof my_dest.gid); 678 679 my_dest.qpn = ctx->qp->qp_num; 680 my_dest.psn = lrand48() & 0xffffff;
The my_dest data structure is filled and then transmitted via TCP. Figure 4 illustrates this data transfer.
数据结构my_dest被填充,然后通过TCP传送。图4显示了这一数据传送。
8.6.1 Modifying QPs | 修改QP
Look at the attributes given to the ibv_modify_qp call.
让我们看一看传递给ibv_modify_qp()调用的属性。
/* Listing 16: Moving QP to Ready to Recv */ 84 struct ibv_qp_attr attr = { 85 .qp_state = IBV_QPS_RTR, 86 .path_mtu = mtu, 87 .dest_qp_num = dest->qpn, 88 .rq_psn = dest->psn, 89 .max_dest_rd_atomic = 1, 90 .min_rnr_timer = 12, 91 .ah_attr = { 92 .is_global = 0, 93 .dlid = dest->lid, 94 .sl = sl, 95 .src_path_bits = 0, 96 .port_num = port 97 } 98 }; ... 106 if (ibv_modify_qp(ctx->qp, &attr, 107 IBV_QP_STATE | 108 IBV_QP_AV | 109 IBV_QP_PATH_MTU | 110 IBV_QP_DEST_QPN | 111 IBV_QP_RQ_PSN | 112 IBV_QP_MAX_DEST_RD_ATOMIC | 113 IBV_QP_MIN_RNR_TIMER)) { 114 fprintf(stderr, "Failed to modify QP to RTR\n"); 115 return 1; 116 }
As you can see .qp_state is set to IBV_QPS_RTR, or Ready-To-Receive. The three fields swapped over TCP, the PSN, QPN, and LID, are now given to the hardware. With this information, the QPs are registered with each other by the hardware, but are not ready to begin exchanging messages. The min_rnr_timer is the time, in seconds, between retries before a timeout occurs.
正如你所看到的,.qp_state被设置为IBV_QPS_RTR或Ready-To-Receive(接收就绪)。通过TCP交换到的三个字段(PSN, QPN和LID),现在传给硬件。有了这些信息,彼此的QP被注册到对方的硬件上,但还没有为开始消息交换准备就绪。min_rnr_timer是重试的时间间隔(以秒为单位),在发生超时的时候。
The QP must be moved into the Ready-To-Send state before the "connection" process is complete.
在连接过程完成之前,QP状态必须被改变到Ready-To-Send(发送就绪)状态。
/* Listing 17: Moving QP to Ready to Send */ 118 attr.qp_state = IBV_QPS_RTS; 119 attr.timeout = 14; 120 attr.retry_cnt = 7; 121 attr.rnr_retry = 7; 122 attr.sq_psn = my_psn; 123 attr.max_rd_atomic = 1; 124 if (ibv_modify_qp(ctx->qp, &attr, 125 IBV_QP_STATE | 126 IBV_QP_TIMEOUT | 127 IBV_QP_RETRY_CNT | 128 IBV_QP_RNR_RETRY | 129 IBV_QP_SQ_PSN | 130 IBV_QP_MAX_QP_RD_ATOMIC)) { 131 fprintf(stderr, "Failed to modify QP to RTS\n"); 132 return 1; 133 }
The attr used to move the QP into IBV_QPS_RTS is the same attr used in the previous call. There is no need to zero out the structure because the bitmask, given as the third argument, specifies which fields should be set.
用来将QP状态改变到IBV_QPS_RTS的attr跟前面调用使用的attr是一模一样的。没有必要将数据结构初始化为0, 因为第三个参数bitmask指定了哪些字段需要被设置。
After the QP is moved into the Ready-To-Send state, the connection (end-to-end context) is ready.
当QP状态处于Ready-to-Send的时候,端到端的连接就准备好了。
8.7 Sending Data | 数据发送
Since the server already posted receive buffers, the client will now post a "send" work request.
既然服务器端已经放置了接收缓冲区,那么客户端即将放置一个“发送”工作请求。
/* Listing 18: Client Posting Send */ 468 struct ibv_sge list = { 469 .addr = (uintptr_t) ctx->buf, 470 .length = ctx->size, 471 .lkey = ctx->mr->lkey 472 }; 473 struct ibv_send_wr wr = { 474 .wr_id = PINGPONG_SEND_WRID, 475 .sg_list = &list, 476 .num_sge = 1, 477 .opcode = IBV_WR_SEND, 478 .send_flags = IBV_SEND_SIGNALED, 479 }; 480 struct ibv_send_wr *bad_wr; 481 482 return ibv_post_send(ctx->qp, &wr, &bad_wr);
The wr_id is an ID specified by the programmer to identify the completion notification corresponding with this work request. In addition, the flag IBV_SEND_SIGNALED sets the completion notification indicator. According to ibv_post_send(3), it is only relevant if the QP is created with sq_sig_all = 0.
wr_id是由程序员指定的ID,用来识别与这个WR相对应的完成通知。另外,标志IBV_SEND_SIGNALED设置了完成通知指示灯。根据ibv_post_send(3),只有当QP创建的时候设置了sq_sig_all等于0时才相关。
8.8 Flow Control | 流量控制
Programmers must implement their own flow control when working with the verbs API. Let us examine the flow control used in ibv_rc_pingpong. Remember from earlier that a client cannot post a send if its remote node does not have a buffer waiting to receive the data.
当使用verbs API的时候,程序员必须自己实现流量控制。让我们看看ibv_rc_pingpong里的流量控制。记住我们在前面强调的,如果远端结点没有准备好等待接收数据的缓冲区,client就不能够发送数据。
Flow control must be used to ensure that receivers do not exhaust their supply of posted receives. Furthermore, the CQ must not overflow. If the client does not pull CQEs off the queue fast enough, the CQ is thrown into an error state, and can no longer be used.
使用流量控制是必须的,以确保接收端不会耗尽它所提供的接收资源。此外,CQ必须不能够溢出。如果client不能足够快地把CQE从CQ上拉取下来的话,那么CQ就会陷入错误状态以致于不能再被使用。
You can see at the top of the loop, which will send/recv the data, that ibv_rc_pingpong tracks the send and recv count.
可以看到,发送/接收数据位于循环的顶部,ibv_rc_pingpong跟踪了发送和接收的计数器。
/* Listing 19: Flow Control */ 717 rcnt = scnt = 0; 718 while (rcnt < iters || scnt < iters) {
Now the code will poll the CQ for two completions; a send completion and a receive completion.
现在,代码将为发送完成(SC)和接收完成(RC)轮询CQ。
/* Listing 20: Polling the CQ */ 745 do { 746 ne = ibv_poll_cq(ctx->cq, 2, wc); 747 if (ne < 0) { 748 fprintf(stderr, "poll CQ failed %d\n", ne); 749 return 1; 750 } 751 752 } while (!use_event && ne < 1);
The use_event variable specifies whether or not the program should sleep on CQ events. By default, ibv_rc_pingpong will poll. Hence the while-loop. On success, ibv_poll_cq returns the number of completions found.
变量use_event指定是否在CQ时间上进行sleep。默认地,ibv_rc_pingpong进行轮询。因此使用了while循环。轮询成功后,ibv_poll_cq()返回工作完成(WC)的数量。
Next, the program must account for how many sends and receives have been posted.
接下来,程序必须统计放置的发送请求和接受工作请求的个数。
/* Listing 21: Flow Control Accounting */ 762 switch ((int) wc[i].wr_id) { 763 case PINGPONG_SEND_WRID: 764 ++scnt; 765 break; 766 767 case PINGPONG_RECV_WRID: 768 if (--routs <= 1) { 769 routs += pp_post_recv(ctx, ctx->rx_depth - routs); 770 if (routs < ctx->rx_depth) { 771 fprintf(stderr, 772 "Couldn't post receive (%d)\n", 773 routs); 774 return 1; 775 } 776 } 777 778 ++rcnt; 779 break; 780 781 default: 782 fprintf(stderr, "Completion for unknown wr_id %d\n", 783 (int) wc[i].wr_id); 784 return 1; 785 }
The ID given to the work request is also given to its associated work completion, so that the client knows what WQE the CQE is associated with. In this case, if it finds a completion for a send event, it increments the send counter and moves on.
给WR使用的ID也被给到相关联的WC上,于是client就知道CQE是关联到那一个WQE上。在这个案例中,如果为一个发送事件找到了一个工作完成,就增加发送计数器然后继续。
The case for PINGPONG_RECV_WRID is more interesting, because it must make sure that receive buffers are always available. In this case the routs variable indicates how many recv buffers are available. So if only one buffer remains available, ibv_rc_pingpong will post more recv buffers. In this case, it calls pp_post_recv again, which will post another 500 (by default). After that it increments the recv counter.
PINGPONG_RECV_WRID的案例更有趣,因为它必须确保接收缓冲区总是可用的。在这种情况下,变量routs表示有多少接收缓冲区可用。所以,如果只有一个缓冲仍然可用,ibv_rc_pingpong将会放置更多的接收缓冲区。在这种情况下,它要求pp_post_recv再放置500(默认值)个接收缓冲区,然后增加recv计数器。
Finally, if more sends need to be posted, the program will post another send before continuing the loop.
最后,如果需要放置更多的发送请求,程序将在继续循环之前放置另一个发送请求。
/* Listing 22: Posting Another Send */ 787 ctx->pending &= ~(int) wc[i].wr_id; 788 if (scnt < iters && !ctx->pending) { 789 if (pp_post_send(ctx)) { 790 fprintf(stderr, "Couldn't post send\n"); 791 return 1; 792 } 793 ctx->pending = PINGPONG_RECV_WRID | 794 PINGPONG_SEND_WRID; 795 }
8.9 ACK
The ibv_rc_pingpong program will now ack the completion events with a call to ibv_ack_cq_events. To avoid races, the CQ destroy operation will wait for all completion events returned by ibv_get_cq_event to be acknowledged. The call to ibv_ack_cq_events must take a mutex internally, so it is best to ack multiple events at once.
程序ibv_rc_pingpong将调用ibv_ack_cq_events()对完成的事件进行确认。为了避免竞态,CQ的destroy操作将等待所有完成事件并确认。调用ibv_ack_cq_events()必须持有内部的互斥锁,所以最好是一次确认多个事件。
816 ibv_ack_cq_events(ctx->cq, num_cq_events);
As a reminder, ibv_ack_cq_events(3) has helpful sample code.
友情提醒一下,ibv_ack_cq_events(3)有提供帮助性的示例代码。
9 Conclusion | 结束语
InfiniBand is the growing standard for supercomputer interconnects, even appearing in departmental clusters. The API is complicated and sparsely documented, and the sample program provided by OFED, ibv_rc_pingpong, does not fully explain the functionality of the verbs. This paper will hopefully enable the reader to better understand the verbs interface.
在超级计算机互联标准中,IB正在蓬勃生长,已经出现在集群中。由于verbs的API较为复杂,而且文档记录比较稀疏。OFED提供的示例程序ibv_rc_pingpong并不能完全解释verbs的功能。本文希望读者在阅读之后,能够更好地理解verbs的用户接口。
10 Acknowledgements | 致谢
Gene Cooperman (Northeastern University) and Jeff Squyres (Cisco) contributed substantially to the organization, structure, and content of this document. Jeff also took the time to discuss the details of InfiniBand with me. Josh Hursey (Oak Ridge National Laboratory) shared his knowledge of InfiniBand with me along the way. Roland Dreier (PureStorage) pointed out, and corrected, a mistake in my explanation of acks.
东北大学的Gene Cooperman和思科的Jeff Squyres对此文档的结构,内容做出了重大贡献。Jeff还花了不少时间和我讨论IB的细节。橡树岭国家实验室的John Hursey跟我分享了有关IB的知识。Pure存储的Roland Dreier指出和纠正了我在解释ACK时存在的错误。
References | 参考文献
- [1] Jason Ansel, Gene Cooperman, and Kapil Arya. DMTCP: Scalable user-level transparent checkpointing for cluster computations and the desktop. In Proc. of IEEE International Parallel and Distributed Processing Symposium (IPDPS-09, systems track). IEEE Press, 2009. published on CD; software available at http://dmtcp.sourceforge.net.
- [2] InfiniBand Trade Assocation. InfiniBand Architecture Specification Volume 1, Release 1.2.1, November 2007. http://www.infinibandta.org/content/pages.php? pg=technology_download.
Do one thing at a time, and do well. | 一次只做一件事,做到最好!

