
深入解析:【即插即用模块】注意力篇 | CVPR 2025 | CASAB:能涨2个点!通道+空间双注意力增强特征,简单结构水论文必看!
2025-11-29 10:50 tlnshuju 阅读(0) 评论(0) 收藏 举报VX: shixiaodayyds,备注【即插即用】,添加即插即用模块交流群。
模块出处

Code:https://github.com/saadwazir/MCADS-Decoder
模块介绍
MCADS整体以及各组件架构: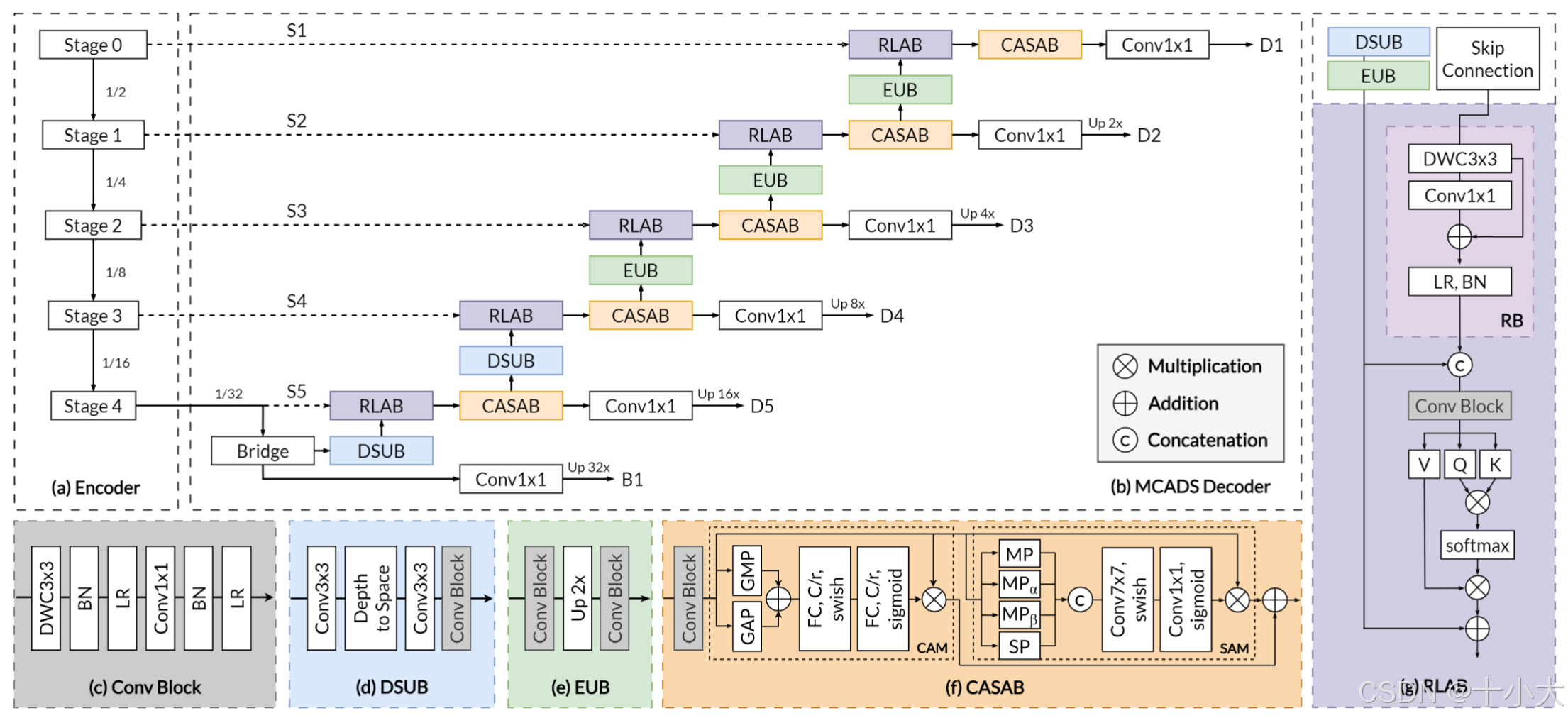
本文要介绍的CASAB模块,包含Channel Attention Module (CAM)和Spatial Attention Module (SAM)两部分。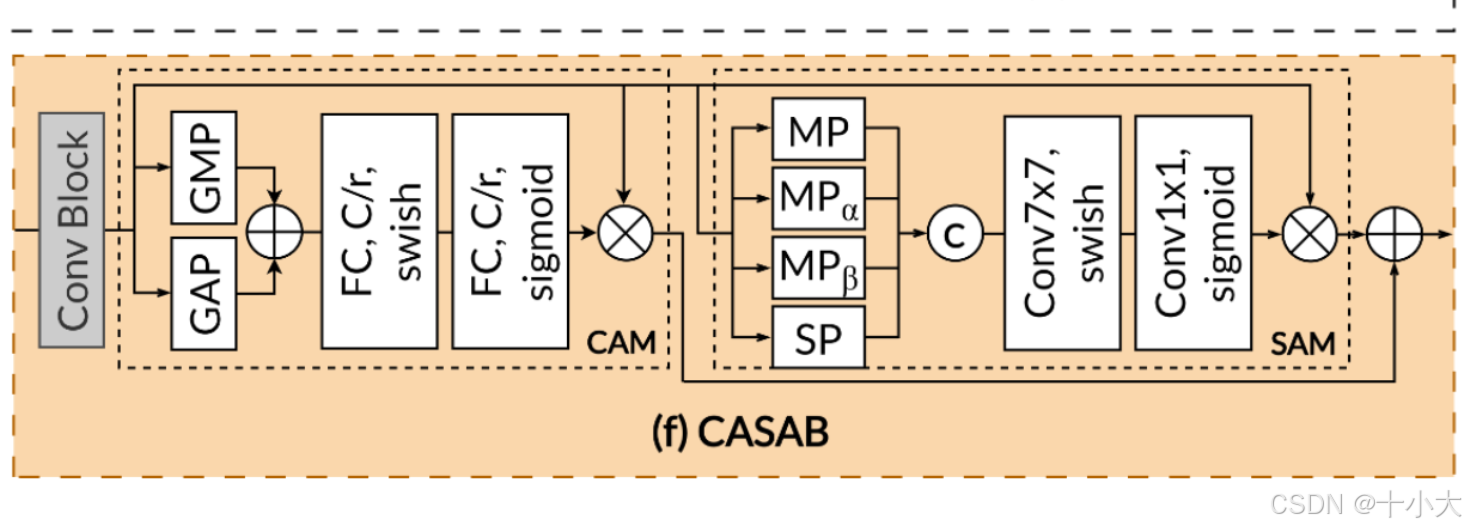
CASAB模块的核心是局部特征增强→通道权重学习→空间权重学习→双注意力融合的端到端流程,专为关键特征突出(如医学图像病理区域)与轻量级部署设计:
局部特征增强(ConvBlock):Depthwise 卷积 + Pointwise卷积 提取局部特征;
通道注意力加权(ChannelAttention):池化后融合,通道压缩激活后恢复,加权后Sigmoid归一化,与原始特征逐通道相乘,突出关键通道;
空间注意力加权(SpatialAttention):
- 多统计特征提取:在通道维度计算 4 种统计特征(均值、最大值、最小值、求和),分别捕捉不同空间信息;
- 空间权重学习:4 种特征拼接为 4 通道特征图,经 7×7 卷积(大感受野捕捉全局空间关联)、SiLU 激活、1×1 卷积(微调权重)、Sigmoid 归一化,得到 1 通道空间权重图(高权重对应病灶区域,低权重对应背景);
- 空间加权:权重图与原始特征逐像素相乘,突出关键空间区域,抑制背景噪声。
双注意力融合输出: 通道加权特征与空间加权特征逐元素相加,达成 “通道 - 空间” 协同增强。
模块提出的动机(Motivation)
医学图像分割医学图像中的生物标志物对于各种生物手艺应用至关重要。尽管取得了进展,但基于 Transformer 和 CNN 的方法往往难以处理染色和形态的变化,限制了特征提取由于奏效地将丰富的多尺度特征从编码器转移到解码器的挑战,以及解码器效率的限制。就是。在医学图像分割中,数据集的样本可用性通常有限,最近最先进的 (SOTA) 方法通过利用预训练的编码器完成了更高的准确度,而端到端方法往往表现不佳。这
为了解决这些问题,大家提出了一种捕获多尺度局部和全局上下文信息的架构,以及一种新颖的解码器设计,它有效地集成了来自编码器的特征,强调要紧的通道和区域,并重建空间维度以提高分割精度。
改善Encoder结构: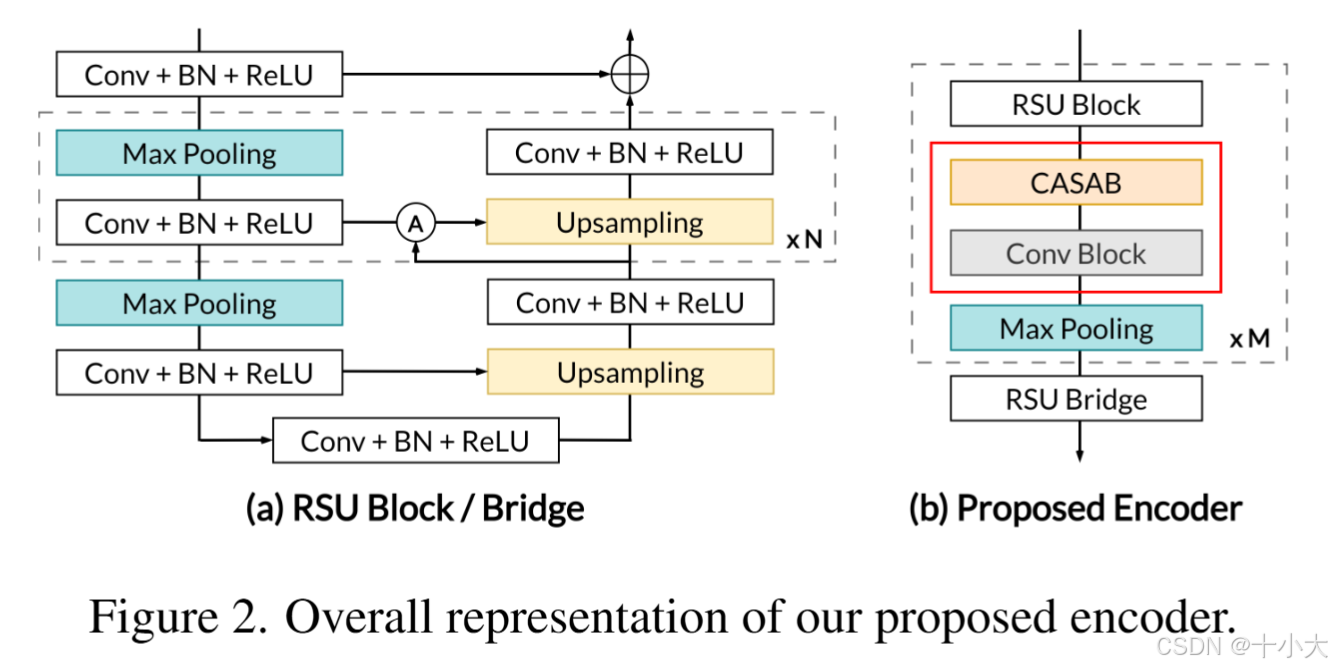
适用范围与模块效果
适用范围:适用于通用视觉领域,特有是需要边缘/纹理增强的高精度/轻量级任务,比如(小目标)分割/检测/增强等。
缝合位置:需要特征增强,边缘/纹理等需关键检测的位置。
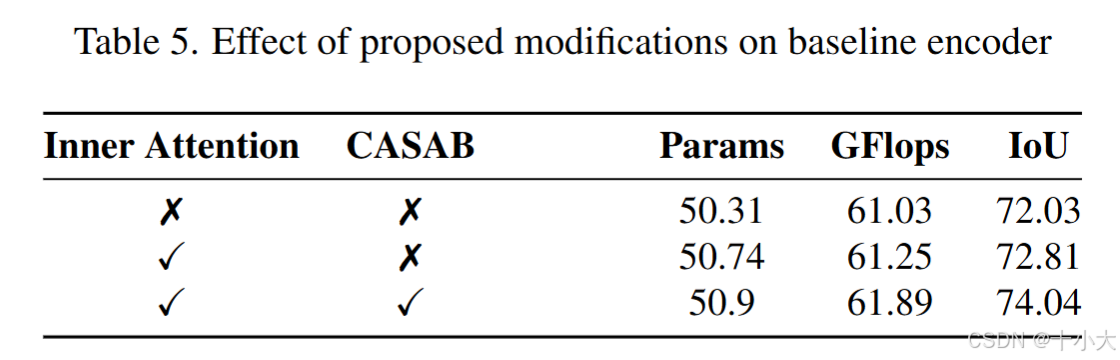
模块效果:CASAB的消融结果如下,可以看到,利用CASAB后虽然计算成本略有增加,但明显涨点,IoU涨了近2个点。

模块代码及运用方式
代码逻辑:

模块代码(详细注释与特征流前向传播过程中的维度变化):
import torch
import torch.nn as nn
class ConvBlock(nn.Module):
"""
深度可分离卷积块:Depthwise Conv + Pointwise Conv + BN + LeakyReLU
功能:替代传统普通卷积,在保持特征提取能力的同时降低计算量与参数量
输入:特征图 [B, in_channels, H, W](B=批次,H/W=特征图高/宽)
输出:特征图 [B, out_channels, H, W](与输入尺寸一致,通道数可调整)
核心优势:计算量仅为普通3×3卷积的1/in_channels + 1/(in_channels×out_channels),参数量大幅减少
"""
def __init__(self, in_channels, out_channels=None):
super(ConvBlock, self).__init__()
# 若未指定输出通道,默认与输入通道一致(残差连接兼容)
if out_channels is None:
out_channels = in_channels
# 1. Depthwise卷积(深度卷积):单通道独立卷积,提取空间特征
self.depthwise = nn.Conv2d(
in_channels, in_channels, kernel_size=3, padding=1,
groups=in_channels, bias=False # groups=in_channels→每个通道单独卷积
)
# 2. Pointwise卷积(点卷积):1×1卷积,调整通道数
self.pointwise = nn.Conv2d(
in_channels, out_channels, kernel_size=1, bias=False
)
# 批量归一化(BN):稳定训练,加速收敛(分别对应Depthwise和Pointwise输出)
self.bn1 = nn.BatchNorm2d(in_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
# LeakyReLU激活:避免ReLU的死亡神经元问题,增强梯度流动(inplace=True节省内存)
self.act = nn.LeakyReLU(inplace=True)
def forward(self, x):
# 深度卷积→BN→激活:提取空间局部特征
x = self.depthwise(x)
x = self.bn1(x)
x = self.act(x)
# 点卷积→BN→激活:调整通道维度,融合空间特征
x = self.pointwise(x)
x = self.bn2(x)
x = self.act(x)
return x
class ChannelAttention(nn.Module):
"""
通道注意力模块(CAM):基于全局池化与共享卷积,学习通道维度的重要性权重
功能:突出关键通道特征(如医学图像中病理区域对应的通道),抑制冗余通道
输入:特征图 [B, in_channels, H, W]
输出:通道加权后的特征图 [B, in_channels, H, W]
核心创新:融合全局平均池化(GAP)与全局最大池化(GMP),捕捉通道统计信息的多样性
"""
def __init__(self, in_channels, reduction=16):
super(ChannelAttention, self).__init__()
# 全局池化:压缩空间维度,保留通道统计信息
self.avg_pool = nn.AdaptiveAvgPool2d(1) # GAP:全局平均池化→[B, C, 1, 1]
self.max_pool = nn.AdaptiveMaxPool2d(1) # GMP:全局最大池化→[B, C, 1, 1]
# 共享卷积层(替代全连接层):通道数压缩→激活→通道数恢复,降低参数量
self.fc = nn.Sequential(
# 1×1卷积压缩通道:in_channels→in_channels//reduction(reduction=16→压缩16倍)
nn.Conv2d(in_channels, in_channels // reduction, kernel_size=1, bias=False),
nn.SiLU(), # Swish激活:非线性更强,比ReLU更适合注意力权重学习
# 1×1卷积恢复通道:in_channels//reduction→in_channels
nn.Conv2d(in_channels // reduction, in_channels, kernel_size=1, bias=False),
nn.Sigmoid() # 归一化权重(0~1),表示通道重要性
)
def forward(self, x):
# 平均池化路径:GAP→共享卷积→权重
avg_out = self.fc(self.avg_pool(x))
# 最大池化路径:GMP→共享卷积→权重
max_out = self.fc(self.max_pool(x))
# 权重融合:平均权重+最大权重,增强通道判别性
scale = avg_out + max_out
# 通道加权:原始特征×权重,突出关键通道
return x * scale
class SpatialAttention(nn.Module):
"""
空间注意力模块(SAM):基于多统计特征融合与卷积,学习空间维度的重要性权重
功能:突出关键空间区域(如医学图像中的肿瘤区域),抑制背景噪声
输入:特征图 [B, in_channels, H, W]
输出:空间加权后的特征图 [B, in_channels, H, W]
核心创新:融合均值、最大值、最小值、求和4种统计特征,比传统2种特征更全面捕捉空间信息
"""
def __init__(self):
super(SpatialAttention, self).__init__()
# 卷积序列:4通道输入(统计特征)→1通道输出(空间权重)
self.conv = nn.Sequential(
# 7×7卷积:更大感受野,捕捉全局空间关联(padding=3保持尺寸)
nn.Conv2d(4, 1, kernel_size=7, padding=3, groups=1),
nn.SiLU(), # 非线性激活,增强空间权重的判别性
nn.Conv2d(1, 1, kernel_size=1), # 1×1卷积微调权重,减少参数
nn.Sigmoid() # 归一化权重(0~1),表示空间区域重要性
)
def forward(self, x):
# 计算4种空间统计特征(通道维度压缩为1)
mean_out = torch.mean(x, dim=1, keepdim=True) # 通道均值:突出整体亮度区域
max_out, _ = torch.max(x, dim=1, keepdim=True) # 通道最大值:突出局部高亮区域(如病灶)
min_out, _ = torch.min(x, dim=1, keepdim=True) # 通道最小值:突出局部暗区(如背景阴影)
sum_out = torch.sum(x, dim=1, keepdim=True) # 通道求和:增强全局对比度
# 特征拼接:4种统计特征在通道维度拼接→[B, 4, H, W]
pool = torch.cat([mean_out, max_out, min_out, sum_out], dim=1)
# 空间权重计算:卷积→激活→归一化
attention = self.conv(pool)
# 空间加权:原始特征×权重,突出关键空间区域
return x * attention
class CASAB(nn.Module):
"""
通道-空间注意力块(CASAB):整合深度可分离卷积、通道注意力、空间注意力
核心流程:特征增强(ConvBlock)→通道加权(CAM)→空间加权(SAM)→双注意力融合
输入:特征图 [B, in_channels, H, W]
输出:双注意力增强后的特征图 [B, in_channels, H, W](与输入维度一致,支持即插即用)
设计目标:在轻量级架构中,通过双注意力协同增强关键特征,适配医学图像、边缘设备等场景
"""
def __init__(self, in_channels, reduction=16):
super(CASAB, self).__init__()
# 1. 特征增强块:深度可分离卷积,为注意力模块提供高质量特征
self.convblock = ConvBlock(in_channels, in_channels)
# 2. 通道注意力模块:学习通道权重
self.channel_attention = ChannelAttention(in_channels, reduction)
# 3. 空间注意力模块:学习空间权重(二次创新:4种统计特征融合)
self.spatial_attention = SpatialAttention()
def forward(self, x):
# 步骤1:特征增强:深度可分离卷积提取局部特征,增强后续注意力的判别基础
x = self.convblock(x)
# 步骤2:通道注意力加权:突出关键通道(如病理特征通道)
ca = self.channel_attention(x)
# 步骤3:空间注意力加权:突出关键区域(如病灶位置)
sa = self.spatial_attention(x)
# 步骤4:双注意力融合:通道加权特征+空间加权特征,协同增强关键信息
return ca + sa
if __name__ == '__main__':
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
x = torch.rand(1, 64, 32, 32).to(device)
model = CASAB(in_channels=64)
model.to(device)
y = model(x)
print("微信公众号:十小大的底层视觉工坊")
print("知乎、CSDN:十小大")
print("输入特征维度:", x.shape)
print("输出特征维度:", y.shape)运行结果:

至此本文结束。
如果本文对你有所帮助,请点赞收藏,创作不易,感谢您的支持!
点击下方公众号区域,扫码关注,可免费领取一份200+即插即用模块资料!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号