

达梦数据库执行计划介绍
参考文章:
前言:
我们在碰到sql执行慢的时候,需要分析sql执行过程,看下是否走了索引等等。这时候就需要查看执行计划。达梦数据库查看执行计划的方式有两种:
1.explain,在待执行的sql语句前面加上explain,再执行
2.利用DM管理工具,选择要查看的sql语句,点击执行计划(P)(F9)
一、操作符说明
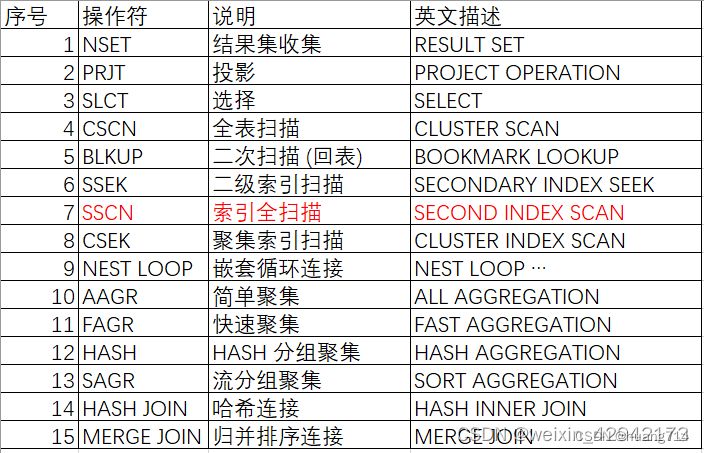
二、对于操作符说明和解释:
本文参考于达梦官方 Explain 指标的介绍:https://eco.dameng.com/document/dm/zh-cn/ops/performance-optimization.html 自己搜索:查看执行计划
一般SQL结果只要保持为 SSEK2就好了。
反面教材

explain select * from sysobjects;
--执行计划
1 #NSET2: [1, 986, 396]
2 #PRJT2: [1, 986, 396]; exp_num(17), is_atom(FALSE)
3 #CSCN2: [1, 986, 396]; SYSINDEXSYSOBJECTS(SYSOBJECTS as SYSOBJECTS)
结果集解释:
1. NSET:结果集收集
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
NSET 是用于结果集收集的操作符,一般是查询计划的顶层节点,优化工作中无需对该操作符过多关注,一般没有优化空间。
2. PRJT:投影
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
PRJT 是关系的【投影】 (project) 运算,用于选择表达式项的计算。广泛用于查询,排序,函数索引创建等。优化工作中无需对该操作符过多关注,一般没有优化空间。
3. SLCT:选择
EXPLAIN SELECT * FROM T1 WHERE C2='TEST';
1 #NSET2: [1, 250, 156]
2 #PRJT2: [1, 250, 156]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [1, 250, 156]; T1.C2 = TEST
4 #CSCN2: [1, 10000, 156]; INDEX33556717(T1)
SLCT 是关系的【选择】运算,用于查询条件的过滤。可比较返回结果集与代价估算中是否接近,如相差较大可考虑收集统计信息。若该过滤条件过滤性较好,可考虑在条件列增加索引。
4. AAGR:简单聚集
EXPLAIN SELECT COUNT(*) FROM T1 WHERE C1 = 10;
1 #NSET2: [0, 1, 4]
2 #PRJT2: [0, 1, 4]; exp_num(1), is_atom(FALSE)
3 #AAGR2: [0, 1, 4]; grp_num(0), sfun_num(1)
4 #SSEK2: [0, 1, 4]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
AAGR 用于没有 GROUP BY 的 COUNT、SUM、AGE、MAX、MIN 等聚集函数的计算。
5. FAGR:快速聚集
EXPLAIN SELECT MAX(C1) FROM T1;
1 #NSET2: [1, 1, 0]
2 #PRJT2: [1, 1, 0]; exp_num(1), is_atom(FALSE)
3 #FAGR2: [1, 1, 0]; sfun_num(1)
FAGR 用于没有过滤条件时,从表或索引快速获取 MAX、MIN、COUNT 值。
6. HAGR:HASH 分组聚集
EXPLAIN SELECT COUNT(*) FROM T1 GROUP BY C2;
1 #NSET2: [1, 100, 48]
2 #PRJT2: [1, 100, 48]; exp_num(1), is_atom(FALSE)
3 #HAGR2: [1, 100, 48]; grp_num(1), sfun_num(1)
4 #CSCN2: [1, 10000, 48]; INDEX33556717(T1)
HAGR 用于分组列没有索引只能走全表扫描的分组聚集,该示例中 C2 列没有创建索引。
7. SAGR:流分组聚集
EXPLAIN SELECT COUNT(*) FROM T1 GROUP BY C1;
1 #NSET2: [1, 100, 4]
2 #PRJT2: [1, 100, 4]; exp_num(1), is_atom(FALSE)
3 #SAGR2: [1, 100, 4]; grp_num(1), sfun_num(1)
4 #SSCN: [1, 10000, 4]; IDX_C1_T1(T1)
SAGR 用于分组列是有序的情况下,可以使用流分组聚集,C1 列上已经创建了索引,SAGR2 性能优于 HAGR2。
8. BLKUP:二次扫描 (回表)
EXPLAIN SELECT * FROM T1 WHERE C1=10;
1 #NSET2: [0, 1, 156]
2 #PRJT2: [0, 1, 156]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 156]; IDX_C1_T1(T1)
4 #SSEK2: [0, 1, 156]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
BLKUP 先使用二级索引索引定位 rowid,再根据表的主键、聚集索引、rowid 等信息获取数据行中其它列。
9. CSCN:全表扫描
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
CSCN2 是 CLUSTER INDEX SCAN 的缩写即通过聚集索引扫描全表,全表扫描是最简单的查询,如果没有选择谓词,或者没有索引可以利用,则系统一般只能做全表扫描。全表扫描 I/O 开销较大,在一个高并发的系统中应尽量避免全表扫描。
10. SSEK、CSEK、SSCN:索引扫描
-- 创建所需索引
CREATE CLUSTER INDEX IDX_C1_T2 ON T2(C1);
CREATE INDEX IDX_C1_C2_T1 ON T1(C1,C2);(1)SSEK
EXPLAIN SELECT * FROM T1 WHERE C1=10;
1 #NSET2: [0, 1, 156]
2 #PRJT2: [0, 1, 156]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 156]; IDX_C1_T1(T1)
4 #SSEK2: [0, 1, 156]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
SSEK2 是二级索引扫描即先扫描索引,再通过主键、聚集索引、rowid 等信息去扫描表。
(2)CSEK
EXPLAIN SELECT * FROM T2 WHERE C1=10;
1 #NSET2: [0, 250, 156]
2 #PRJT2: [0, 250, 156]; exp_num(5), is_atom(FALSE)
3 #CSEK2: [0, 250, 156]; scan_type(ASC), IDX_C1_T2(T2), scan_range[10,10]
CSEK2 是聚集索引扫描只需要扫描索引,不需要扫描表,即无需 BLKUP 操作,如果 BLKUP 开销较大时,可考虑创建聚集索引。
(3)SSCN
EXPLAIN SELECT C1,C2 FROM T1;
1 #NSET2: [1, 10000, 60]
2 #PRJT2: [1, 10000, 60]; exp_num(3), is_atom(FALSE)
3 #SSCN: [1, 10000, 60]; IDX_C1_C2_T1(T1)
SSCN 是索引全扫描,不需要扫描表。
11. NEST LOOP:嵌套循环连接
嵌套循环连接是最基础的连接方式,将一张表(驱动表)的每一个值与另一张表(被驱动表)的所有值拼接,形成一个大结果集,再从大结果集中过滤出满足条件的行。驱动表的行数就是循环的次数,将在很大程度上影响执行效率。
连接列是否有索引,都可以走 NEST LOOP,但没有索引,执行效率会很差,语句如下所示:
select /*+use_nl(t1,t2)*/* from t1 inner join t2 on t1.c1=t2.c1 where t1.c2='A';
1 #NSET2: [17862, 24725, 296]
2 #PRJT2: [17862, 24725, 296]; exp_num(8), is_atom(FALSE)
3 #SLCT2: [17862, 24725, 296]; T1.C1 = T2.C1
4 #NEST LOOP INNER JOIN2: [17862, 24725, 296];
5 #SLCT2: [1, 250, 148]; T1.C2 = 'A'
6 #CSCN2: [1, 10000, 148]; INDEX33555594(T1)
7 #CSCN2: [1, 10000, 148]; INDEX33555595(T2)可针对 T1 和 T2 的连接列创建索引,并收集统计信息,语句如下所示:
CREATE INDEX IDX_T1_C2 ON T1(C2);
CREATE INDEX IDX_T2_C1 ON T2(C1);
DBMS_STATS.GATHER_INDEX_STATS(USER,'IDX_T1_C2');
DBMS_STATS.GATHER_INDEX_STATS(USER,'IDX_T2_C1');再次查看执行计划可看出效率明显改善,代价有显著下降,语句如下所示:
select /*+use_nl(t1,t2)*/* from t1 inner join t2 on t1.c1=t2.c1 where t1.c2='A';
1 #NSET2: [9805, 17151, 296]
2 #PRJT2: [9805, 17151, 296]; exp_num(8), is_atom(FALSE)
3 #SLCT2: [9805, 17151, 296]; T1.C1 = T2.C1
4 #NEST LOOP INNER JOIN2: [9805, 17151, 296];
5 #BLKUP2: [1, 175, 148]; IDX_T1_C2(T1)
6 #SSEK2: [1, 175, 148]; scan_type(ASC), IDX_T1_C2(T1), scan_range['A','A']
7 #CSCN2: [1, 10000, 148]; INDEX33555585(T2)适用场景:
- 驱动表有很好的过滤条件
- 表连接条件能使用索引
- 结果集比较小
12. HASH JOIN:哈希连接
哈希连接是在没有索引或索引无法使用情况下大多数连接的处理方式。哈希连接使用关联列去重后结果集较小的表做成 HASH 表,另一张表的连接列在 HASH 后向 HASH 表进行匹配,这种情况下匹配速度极快,主要开销在于对连接表的全表扫描以及 HASH 运算。
select * from t1 inner join t2 on t1.c1=t2.c1 where t1.c2='A';
1 #NSET2: [4, 24502, 296]
2 #PRJT2: [4, 24502, 296]; exp_num(8), is_atom(FALSE)
3 #HASH2 INNER JOIN: [4, 24502, 296]; KEY_NUM(1); KEY(T1.C1=T2.C1) KEY_NULL_EQU(0)
4 #SLCT2: [1, 250, 148]; T1.C2 = 'A'
5 #CSCN2: [1, 10000, 148]; INDEX33555599(T1)
6 #CSCN2: [1, 10000, 148]; INDEX33555600(T2)哈希连接比较消耗内存如果系统有很多这种连接时,需调整以下 3 个参数:
|
参数名 |
说明 |
|---|---|
|
HJ_BUF_GLOBAL_SIZE |
HASH 连接操作符的数据总缓存大小 ()>=HJ_BUF_SIZE),系统级参数,以兆为单位。有效值范围(10~500000) |
|
HJ_BUF_SIZE |
单个哈希连接操作符的数据总缓存大小,以兆为单位。有效值范围(2~100000) |
|
HJ_BLK_SIZE |
哈希连接操作符每次分配缓存( BLK )大小,以兆为单位,必须小于 HJ_BUF_SIZE。有效值范围(1~50) |
13. MERGE JOIN:归并排序连接
归并排序连接需要两张表的连接列都有索引,对两张表扫描索引后按照索引顺序进行归并。
-- 对连接列创建索引
CREATE INDEX IDX_T1_C1C2 ON T1(C1,C2);select /*+use_merge(t1 t2)*/t1.c1,t2.c1 from t1 inner join t2 on t1.c1=t2.c1 where t2.c2='b';
1 #NSET2: [13, 24725, 56]
2 #PRJT2: [13, 24725, 56]; exp_num(2), is_atom(FALSE)
3 #SLCT2: [13, 24725, 56]; T2.C2 = 'b'
4 #MERGE INNER JOIN3: [13, 24725, 56]; KEY_NUM(1); KEY(COL_0 = COL_0) KEY_NULL_EQU(0)
5 #SSCN: [1, 10000, 4]; IDX_C1_T1(T1)
6 #BLKUP2: [1, 10000, 52]; IDX_T2_C1(T2)
7 #SSCN: [1, 10000, 52]; IDX_T2_C1(T2)特殊说明: 上述文章均是作者实际操作后产出。烦请各位,请勿直接盗用!转载记得标注原文链接:www.zanglikun.com
三、操作符后面的三元组解释:
能正常读取执行计划描述的执行顺序后,我们关注下执行计划各个节点的详细信息,执行计划中所有操作符的后面都会有一个三元组,如:
#CSCN2: [1, 9999, 4]
[1, 9999, 4]就是我们提到的这个三元组,3个数字分别表示该操作符的估算代价,该操作符的输出行数,该操作符涉及数据的行长。
#CSCN2: [1, 9999, 4] 表示的意义为,这是一个全表扫描操作,涉及的行数为9999,每场数据长度为4,整体代价估算为1。
我们将三元组中的第二项称为估算行数(card),在复杂查询中,估算行数对于执行计划以及SQL性能的影响很大。
--

 浙公网安备 33010602011771号
浙公网安备 33010602011771号