MIT6.824 lab1 实验反思
MIT6.824 lab1 实验反思
0. 实验文档
1. 环境搭建
实验文档中并没有指出应该在哪个操作系统的环境下进行实验,但是需要使用到 Go 的插件功能,考虑到插件功能在 Windows 上支持有限,所以应该选择类 Unix 系统。恰好手里有一台Linux的物理机,索性就用 VsCode + ssh 的环境进行实验了。
1.1 配置 Go SDK
以下摘自 6.5840 Go:
Depending on your Linux distribution, you might be able to get an up-to-date version of Go from the package repository, e.g. by running apt install golang. Otherwise, you can manually install a binary from Go's website. First, make sure that you're running a 64-bit kernel (uname -a should mention "x86_64 GNU/Linux"), and then run:
$ wget -qO- https://go.dev/dl/go1.25.0.linux-amd64.tar.gz | sudo tar xz -C /usr/local
You'll need to make sure /usr/local/go/bin is on your PATH. You can do this by adding export PATH=$PATH:/usr/local/go/bin to your shell's init file ( commonly this is one of .bashrc, .bash_profile or .zshrc)
本次实验采用的 Go 版本是 1.25.0 。
1.2 VsCode 插件安装
VsCode这边大概要安装一个Go语言的插件,Code Runner 随意吧
1.3 VsCode 编码体验优化
执行命令:
$ go install -v github.com/sqs/goreturns@latest
- 该命令会在你的
$GOPATH/bin目录下(或者如果你设置了$GOBIN,则在$GOBIN目录下)生成一个名为goreturns的可执行文件。 goreturns是一个用于格式化 Go 源代码的工具,特别适用于在保存文件时自动格式化。它在gofmt的基础上增加了额外的功能,比如自动添加或移除导入语句(类似goimports),并且会针对返回语句(return)进行特殊处理(例如在函数返回多个值且类型复杂时,自动拆分成多行以增强可读性),因此得名 “goreturns”。
1.4 VsCode debug 工具配置(重要)
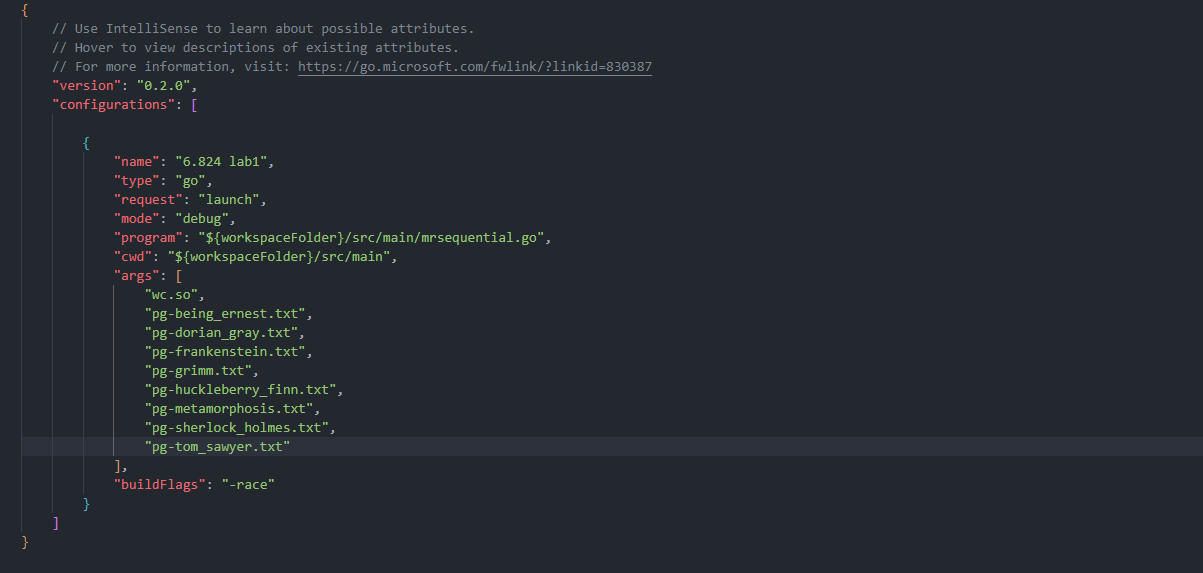
在项目根目录下(当然也可以自己选择一个工作目录,feel free)新建 .vscode/launch.json,编写好基本的配置:

关键配置详解:
-
configurations.program: 要debug的程序入口文件
-
configurations.cwd: 程序工作目录
-
configurations.args: 参数,这里是编译好的插件和输入文件
-
configurations.bulldFlags: 开启竞态条件检测
这里的 debug 工具默认使用 $GOPATH/bin 路径下的 delve 工具。通常来说,delve 工具支持的 Go SDK 版本一定要和当前 Go SDK 版本是兼容的才行。本机环境是 Go 1.25.0,采用的 delve 版本是 1.25.1、
在配置好这些以后启动调试,可能会出现一个匪夷所思的问题:

这里显示无法加载 wc.go 编译来的插件。
如果我们使用实验文档给出来的编译命令的确是会出现这个问题。原因是通常来说,编译器对源码进行编译的时候多少会带点优化手段,比如调整一些指令顺序,以达到较好的性能。但这样对于 debug 肯定是不利的。
解决办法就是,禁止编译器进行优化。所以如果要使用 delve 对代码进行 debug 的话,需要把编译插件的命令改成这样:
$ go build -race -buildmode=plugin -gcflags="all=-N -l" -o wc.so ../mrapps/wc.go
参数详解:
- race:开启竞态条件检测
- buildmode=plugin:输出是共享库文件
- gcflags=
- all:表示这些选项应用于当前模块的所有包(包括依赖包)
- N:禁止编译器优化
- -l:禁止函数内联
做完wg.so插件的一些琐碎的工作以后,运行 debug,会发现还有一个问题:

这是因为 go build 命令不支持通配符的使用,解决方案是直接把文件名写死在 debug 配置文件里:
做好上面的一切以后,就可以开始快乐 debug 了。Have fun~
2. lab——,启动——
2.1 需求描述
- 简单复刻 MapReduce 论文中描述的分布式数据处理系统——其中包含一个 master (实验中采用了 Coordinator 这个术语)和若干个 worker。master 负责调度分配任务,监测 worker 是否可能下线;worker 则负责执行具体的 Map 阶段任务和 Reduce 阶段任务
- 主要需求如下:
- 协调者(coordinator):
- 跟踪所有 Map 和 Reduce 任务的状态(待分配、进行中、已完成)。
- 响应工作者的任务请求,分配任务(Map任务或Reduce任务)。
- 当Map任务全部完成后,才能开始分配Reduce任务。
- 监控任务超时(10秒),将超时任务重新分配。
- 当所有任务完成后,协调者退出(通过
Done()方法返回true)。
- 工作者(worker):
- 循环向协调者请求任务。
- 根据任务类型(Map/Reduce)读取输入文件,调用对应的Map/Reduce函数。
- 将Map任务的输出写入中间文件(按照
nReduce分桶),格式为mr-X-Y,其中X是Map任务编号,Y是Reduce任务编号。 - 将Reduce任务的输出写入最终文件
mr-out-X(每个Reduce任务一个输出文件)。 - 如果协调者没有任务可分配(例如所有任务已完成),工作者应退出。
- 文件处理:
- Map任务:输入是多个文件(每个文件对应一个Map任务),输出是
nReduce个中间文件(每个中间文件对应一个Reduce任务桶)。 - Reduce任务:从多个Map任务产生的中间文件(同一个Reduce桶编号)中读取数据,执行Reduce函数,输出到一个最终文件。
- 使用JSON格式写入和读取中间文件(键值对)。
- 最终输出文件
mr-out-X的格式:每行是"%v %v",即键和值。
- Map任务:输入是多个文件(每个文件对应一个Map任务),输出是
- 容错:
- 工作者可能在执行任务时崩溃,协调者等待10秒后重新分配该任务给其他工作者。
- 确保最终结果正确,不能因为任务重复执行而出现错误(Map和Reduce函数必须是幂等的)。
- 并发:
- 多个Map任务和Reduce任务可以并行执行。
- 协调者需要处理并发的RPC请求,注意锁的使用。
- 测试:
- 通过
test-mr.sh测试,包括:单词计数(wc)、索引生成(indexer)、并行性测试、任务计数、提前退出测试和崩溃测试。
- 通过
- 协调者(coordinator):
2.2 详细实现方案
2.2.1 任务及其状态
定义Map任务和Reduce任务的结构:
type Task struct {
TimeStamp time.Time // time stamp that give the task to any worker
Filenames []string // input files
TaskID int // task ID
TaskType int // task type, 0 map task, 1 reduce task
Status int // task status, 0 init, 1 ready, 2 in process, 3 completed, 4 failed
}
这里我们要记录每个任务的开始时间戳、输入文件列表、任务ID、任务类型、任务状态。其中任务包含3个状态,分别是就绪、处理中和已完成:
const (
TASK_READY = iota // ready
TASK_IN_PROCESS // in process
TASK_COMPLETED // completed
)
其有限状态机如下:

任务创建的时候,应该是赋成 ready 状态。这个时候的时间戳没有含义,所以也应该赋零值;在任务分发出去以后,应该进入 in process 状态,表示任务正在处理中。这期间有3种情况:成功、失败、超时。如果任务处理成功了,自然标记成 completed 状态,表示任务完成;如果任务处理失败,或者是超时,在 Coordinator 这边都只能感知到 worker 进程有一段时间没有发送任务完成的通知了,所以就把任务初始化,然后分配给下一个来寻求新任务的 worker。
2.2.2 Coordinator 实现细节
Coordinator 结构
对于 Coordinator来说,需要记录所有的输入文件的信息,所有的 Map 任务和 Reduce 任务的信息,同时考虑到这些任务信息都是并发的读写操作,所以需要引入互斥锁对临界资源进行保护。所以定义 Coordinator 结构如下:
type Coordinator struct {
// Your definitions here.
mu *sync.Mutex // mutex lock, to protect 2 maps below
nReduce int
tasks map[int][]*Task // all the tasks, key = 0 -> map tasks, key = 1 -> reduce tasks
}
这里我选择了 map 这个数据结构去存放两种类型的任务,每个 key 对应一个任务列表,列表中的就是尚未完成的任务。
Coordinator 需要给 Worker 提供的 RPC
GetTask
func (c *Coordinator) GetTask(args *GetTaskRequest, response *GetTaskResponse) (err error) {
c.mu.Lock()
defer c.mu.Unlock()
mapTaskRem := len(c.tasks[TASK_TYPE_MAP])
reduceTaskRem := len(c.tasks[TASK_TYPE_REDUCE])
if mapTaskRem > 0 {
err = c.getMapTask(response)
if err != nil {
return err
}
return nil
} else if reduceTaskRem > 0 {
err = c.getReduceTask(response)
if err != nil {
return err
}
return nil
}
response.TaskType = TASK_DONE
return nil
}
根据实验文档的要求,要先完成所有 Map 任务,再处理 Reduce 任务。显然 GetTask 需要实现这一点。大致逻辑是,先加好锁,然后获取 Map 任务剩余数量和 Reduce 任务剩余数量。根据剩余任务数量判断应该获取 Map 任务还是 Reduce 任务。如果两个任务都没有剩余,就可以返回 TASK_DONE 这个任务类型,表示没有任务可做,这时 Worker 就可以退出了。
这里的 TASK_DONE 这个类型是必须的。如果不从这里获取没有任务执行的信息,而单从 response 有没有记录具体任务来判断是否有任务执行的话,会出现一种情况:当前所有任务都在处理中和没有任务处理两种状态是无法区分的,这个时候程序的行为就不符合预期了。
ReportTask
func (c *Coordinator) ReportTask(args *ReportTaskArgs, response *struct{}) error {
taskID, taskType := args.TaskId, args.TaskType
c.mu.Lock()
defer c.mu.Unlock()
for _, task := range c.tasks[taskType] {
if task.TaskID != taskID {
continue
}
if time.Since(task.TimeStamp) < TASK_TIMEOUT { // report in time, and mark the task as completed
task.Status = TASK_COMPLETED
log.Printf("Coordinator.ReportTask: task %d completed.", taskID)
} else { // report timeout, and mark the task as failed
task.Status = TASK_READY
task.TimeStamp = time.Time{}
if task.TaskType == TASK_TYPE_REDUCE {
task.Filenames = nil
}
log.Printf("Coordinator.ReportTask: task %d timeout.", taskID)
}
}
return nil
}
当 Worker 执行完某个任务以后,就要调用 ReportTask 向 Coordinator 通告当前任务已经完成。这个时候 Coordinator 需要做的就是判断通告到达的时间,如果超出了 TASK_TIMEOUT(10s),就要重置任务状态,期待其他 Worker 重新获取这个任务并执行;否则就标记为已完成状态,等待后台 goroutine 将已完成的任务从任务列表中清除。不过通常来说,这里不会出现 TASK_TIMEOUT,因为 Coordinator 也会在后台跑一个 goroutine,周期性地检查并重置超时任务。
2.2.3 Worker 实现细节
相对于 Coordinator 来说,Worker 就简单很多了,它只要循环地获取任务、执行任务、通告任务完成就好了。
但是也有一点需要注意,比如当前 Worker 实际上已经执行一段时间了,触发了 TASK_TIMEOUT。在 Coordinator 端,发现了这个超时任务,并分配给了其他正在请求任务的 Worker。但是当前的 Worker 并不知道 Coordinator 做的这个事情,它一直执行,直到算出了所有的结果——这个时候它要把结果写入到对应的中间文件中。这里如果处理不当,可能在中间文件中会看到两份一模一样的结果,这样就会影响到最终结果的生成。
根据实验文档的提示,可以使用临时文件+原子性重命名操作来规避这个问题。当 Worker 正在计算结果的时候,要将结果写入临时文件中,当结果计算完之后,就要原子性重命名这个临时文件,将它重命名成当前阶段任务的输出结果文件。当然如果在重命名之前就发现这个输出结果文件存在的话,就不必再进行重命名操作了,因为这个时候有其他 Worker 接替当前 Worker 完成了任务。
func runMapTask(res *GetTaskResponse, mapf func(string, string) []KeyValue) error {
intermediate := []KeyValue{}
filenames := res.Filenames
for _, filename := range filenames {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close()
content, err := ioutil.ReadAll(file)
if err != nil {
return err
}
kva := mapf(filename, string(content))
intermediate = append(intermediate, kva...)
}
// write the kvs into intermediate file
finalFilenames := make([]string, res.NReduce)
outFiles := make([]*os.File, res.NReduce)
outEncoders := make([]*json.Encoder, res.NReduce)
for i := 0; i < res.NReduce; i++ {
filename := fmt.Sprintf("mr-%d-%d", res.TaskId, i)
tmpFilename := fmt.Sprintf("tmp-%s", filename)
outFiles[i], _ = os.CreateTemp(".", tmpFilename)
outEncoders[i] = json.NewEncoder(outFiles[i])
finalFilenames[i] = filename
}
for _, kv := range intermediate {
reduceID := ihash(kv.Key) % res.NReduce
outEncoders[reduceID].Encode(&kv)
}
for i, tmpFile := range outFiles {
if err := tmpFile.Close(); err != nil {
return fmt.Errorf("close temp file %s failed: %w", tmpFile.Name(), err)
}
tmpPath := tmpFile.Name()
finalPath := finalFilenames[i]
if _, err := os.Stat(finalPath); err == nil { // exist, ignore this rename operation
continue
}
if err := os.Rename(tmpPath, finalPath); err != nil {
return fmt.Errorf("rename temp file %s to %s failed: %w", tmpPath, finalPath, err)
}
}
return nil
}
当这个任务完成以后,要向 Coordinator 通告当前任务 ID,表示这个任务已经完成了,通知 Coordinator 后台 goroutine 将其删除。
2.2.4 验证
-
可以参照实验文档,跑一遍这个分布式计算系统,然后通过命令:
$ cat mr-out-* | LC_ALL=C sort | more查看计算结果。
-
运行
test-mr-many.sh脚本若干次,如果一直稳定通过,就表示当前实现可以通过实验。

3. 总结
本实验旨在实现一个简单的分布式计算框架,引出分布式系统的知识。
对于本实验来说,有以下三个难点:
- 理清 Coordinator 和 Worker 各自的职责
- 哪些信息需要进行通告
- 提供一个简单的容错机制保证任务能够及时处理
在阅读过 MapReduce 论文 以后,其实可以发现这个分布式计算框架仍然有很多值得改进的地方。但是对于分布式系统的启蒙作用,不管是于当时的技术人员,还是于当下初步认识分布式系统的我们,都有着极高的历史地位。所以,还是对 Google 的技术人员们说一声:Respect!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号