

作业一
作业要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架爬取京东商城某类商品信息及图片。
候选网站:http://www.jd.com/
实验过程:
驱动配置
chrome_options = Options() chrome_options.add_argument("——headless") chrome_options.add_argument("——disable-gpu") self.driver = webdriver.Chrome(chrome_options=chrome_options)
数据获得
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']") time.sleep(1) for li in lis: time.sleep(1) try: src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src") time.sleep(1) except: src1 = "" try: src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img") time.sleep(1) except: src2 = "" try: price = li.find_element_by_xpath(".//div[@class='p-price']//i").text time.sleep(1) except: price = "0" note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text mark = note.split(" ")[0] mark = mark.replace("爱心东东\n", "") mark = mark.replace(",", "") note = note.replace("爱心东东\n", "") note = note.replace(",", "")
保存图片
if src1: src1 = urllib.request.urljoin(self.driver.current_url, src1) p = src1.rfind(".") mFile = no + src1[p:] elif src2: src2 = urllib.request.urljoin(self.driver.current_url, src2) p = src2.rfind(".") mFile = no + src2[p:] if src1 or src2: T = threading.Thread(target=self.downloadDB, args=(src1, src2, mFile)) T.setDaemon(False) T.start() self.threads.append(T) else: mFile = ""
数据插入
def insertDB(self, mNo, mMark, mPrice, mNote, mFile): try: sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)" self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile)) except Exception as err: print(err)
图片下载
def downloadDB(self, src1, src2, mFile): data = None if src1: try: req = urllib.request.Request(src1, headers=JD.header) resp = urllib.request.urlopen(req, timeout=100) data = resp.read() except: pass if not data and src2: try: req = urllib.request.Request(src2, headers=JD.header) resp = urllib.request.urlopen(req, timeout=100) data = resp.read() except: pass if data: print("download begin!", mFile) fobj = open(JD.imagepath + "\\" + mFile, "wb") fobj.write(data) fobj.close() print("download finish!", mFile)
实验结果:

实验心得:这次实验是课堂代码的复现,通过这次实验我加深了对Selenium的理解,已经xpath的掌握
码云地址:作业5/main.py · 刘洋/2019数据采集与融合 - 码云 - 开源中国 (gitee.com)
作业二
作业要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、教学
进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹
中,图片的名称用课程名来存储。
候选网站:中国mooc网:https://www.icourse163.org
实验过程:
发送请求
option = webdriver.ChromeOptions() option.add_experimental_option("detach", True) driver = webdriver.Chrome(chrome_options=option) #请求 driver.get('https://www.icourse163.org/')
数据库部分,包括插入数据的实现
class CSDB: con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="20010109l?y!", db="class", charset="utf8") cursor = con.cursor(pymysql.cursors.DictCursor) def createDB(self): try: self.cursor.execute('create table Course(Id varchar (10),cCourse varchar (40),cCollege varchar (20),cSchedule varchar (30),' 'cCourseStatus varchar (30), clmgUrl varchar (255))') except Exception as err: print(err) print(1) def insert(self,id,course,college,schedule,coursestatus,clmgurl): try: self.cursor.execute('insert into Course(Id,cCourse,cCollege,cSchedule,cCourseStatus,clmgUrl) ' 'values (%s,%s,%s,%s,%s,%s)', (id, course, college, schedule, coursestatus, clmgurl)) except Exception as err: print(err) def closeDB(self): self.con.commit() self.con.close()
保存照片,照片名为课程名,照片保存在images文件夹中
def download(url,name): req = urllib.request.Request(url,) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open(r"images/" + str(name) + ".jpg", "wb") fobj.write(data) fobj.close() print("downloaded" + (name) + ".jpg")
通过点击操作进入登录页面,在登录页面进行扫码登录,然后通过点击进入我的课程页面,获取数据
sign = driver.find_element(By.XPATH, '/html/body/div[4]/div[2]/div[1]/div/div/div[1]/div[3]/div[3]/div').click() time.sleep(10) #进入我的课堂 find = driver.find_element(By.XPATH, '//*[@id="j-indexNav-bar"]/div/div/div/div/div[7]/div[3]/div/div/a/span') # 图标被遮挡,导致无法直接用find.click()点击 driver.execute_script("arguments[0].click();", find)
数据的获取
#课程名 course = driver.find_elements(By.XPATH, '//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[2]/div[1]/div[1]/div/span[2]') #学校 college = driver.find_elements(By.XPATH, '//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[2]/div[1]/div[2]/a') #课时 sche = driver.find_elements(By.XPATH, '//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[2]/div[2]/div[1]/div[1]/div[1]/a/span') #状态 status = driver.find_elements(By.XPATH, '/html/body/div[4]/div[2]/div[3]/div/div[1]/div[3]/div/div[2]/div/div/div[2]/div[1]/div[2]/div/div[1]/div/div[1]/a/div[2]/div[2]/div[2]') #url url = driver.find_elements(By.XPATH, '/html/body/div[4]/div[2]/div[3]/div/div[1]/div[3]/div/div[2]/div/div/div[2]/div[1]/div[2]/div/div[1]/div/div[1]/a/div[1]/img')
实验结果:


实验心得:通过这次实验我加深了对Selenium的理解,熟悉了xpath的使用方法。
码云地址:作业5/task2_1.py · 刘洋/2019数据采集与融合 - 码云 - 开源中国 (gitee.com)
作业三
作业要求:
理解Flume架构和关键特性,掌握使用Flume完成日志采集任务。
完成Flume日志采集实验,包含以下步骤:任务一:开通MapReduce服务
任务二:Python脚本生成测试数据
任务三:配置Kafka
任务四:安装Flume客户端
任务五:配置Flume采集数据
实验过程及结果:
python脚本生成测试数据
编写Python脚本使用Xshell 7连接服务器,进入/opt/client/目录用xftp7将本地的autodatapython.py文件上传至服务器/opt/client/目录下即可。
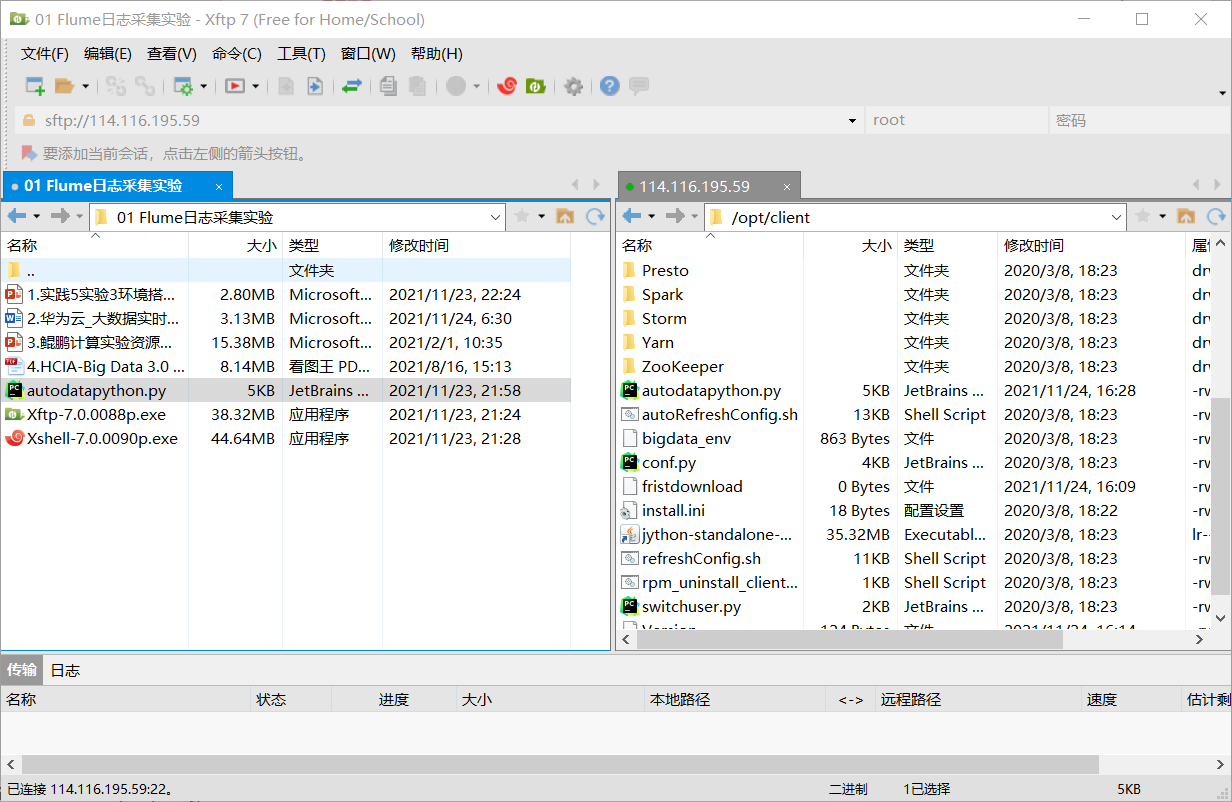
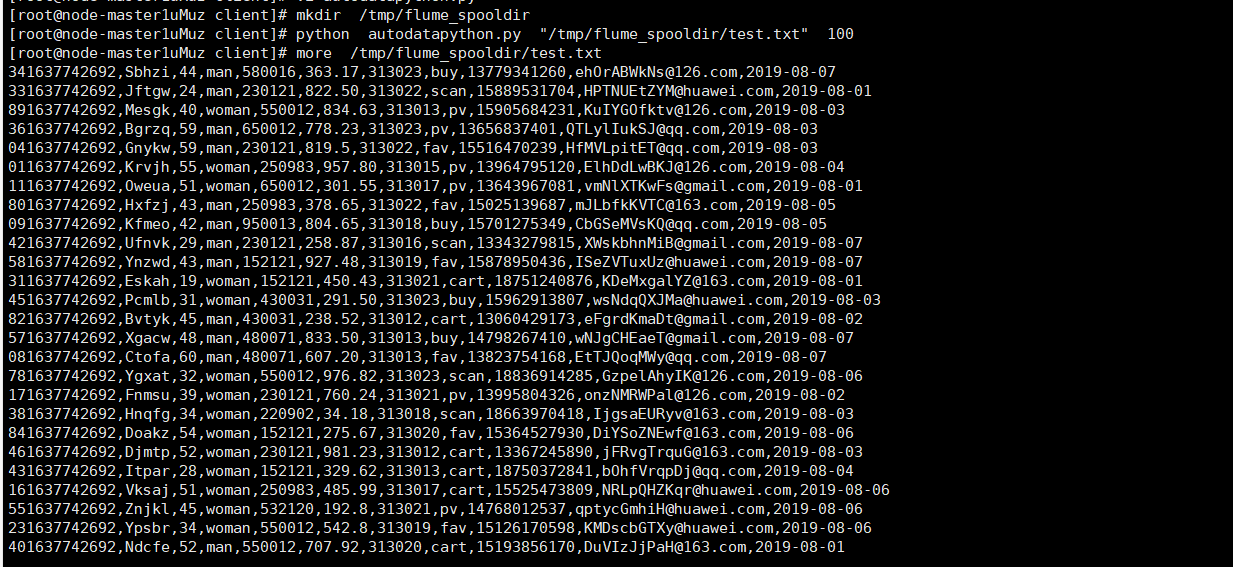
使用mkdir命令在/tmp下创建目录flume_spooldir,执行Python命令,测试生成100条数据
配置Kafka
首先设置环境变量,执行source命令,使变量生效,在kafka中创建topic

查看topic信息

安装Flume客户端
解压下载的flume客户端文件

解压压缩包获取校验文件与客户端配置包

校验文件包

解压“MRS_Flume_ClientConfig.tar”文件

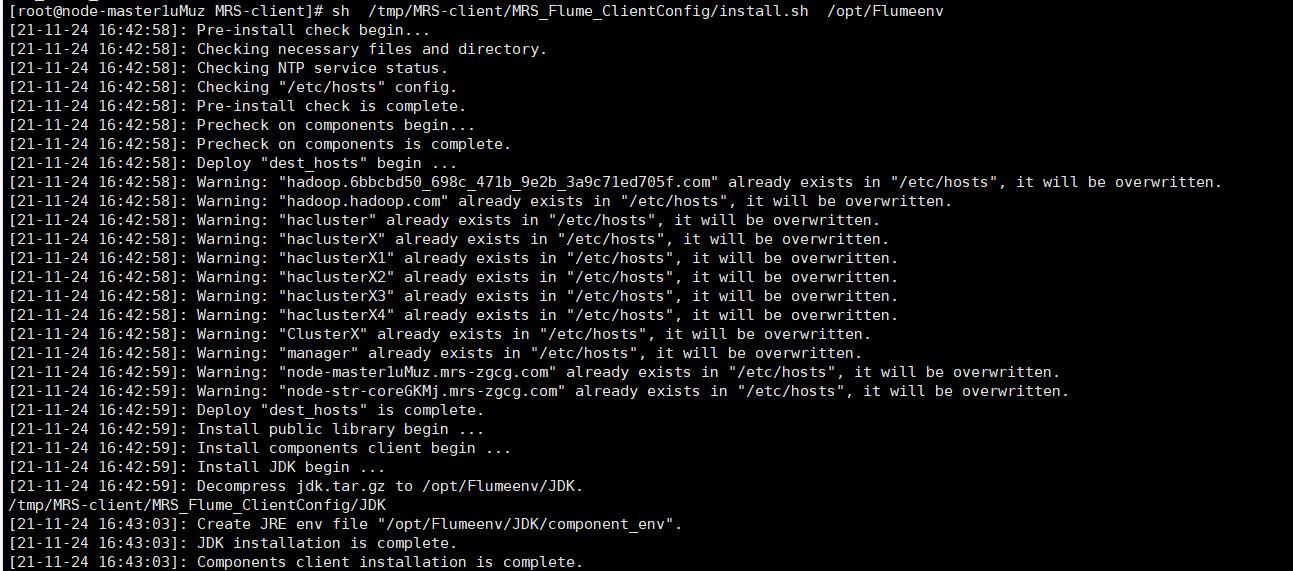
安装Flume环境变量
安装客户端运行环境到新的目录“/opt/Flumeenv”,安装时自动生成目录
解压Flume客户端
安装Flume客户端安装Flume到新目录”/opt/FlumeClient”,安装时自动生成目录

重启Flume服务,安装完成

配置Flume采集数据
在conf目录下编辑文件properties.properties

创建消费者消费kafka中的数据

新开一个Xshell 7窗口(右键相应会话-->在右选项卡组中打开),执行Python脚本命令,再生成一份数据
实验心得:初步了解使用华为云。

