
数据采集第六次作业
作业①:
(1)实验要求:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
了解正则的使用方法
(2)实验代码:
import requests
# 调用bs4库里的BeautifulSoup类
from bs4 import BeautifulSoup
# 利用requests库的get方法爬取网页
def getHtmlText(url):
try:
r = requests.get(url, timeout=20)
r.raise_for_status()
# 分析得到网页的编码格式
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 爬取数据并放入list列表中
def fillList(list,html):
lst = []
try:
# 调用bs4库里的BeautifulSoup类的方法,利用BeautifulSoup的html.parser解析网页
soup = BeautifulSoup(html, "html.parser")
div = soup.find_all('div',attrs={'class':'hd'})
for i in div:
# name = i.find_all('span') 下边为简写写法
name = i('span')
# 以\xa0为分隔符将name[1]进行2次分割
Name = name[1].string.split('\xa0',2)
href = i('a')
# 将href从bs4.element.ResultSet类型转换为str类型
for h in href:
lst.append(str(h))
# 此时"".join(lst)即为href的str类型
soup1 = BeautifulSoup("".join(lst), "html.parser")
# Href即为得到电影的链接
Href = soup1.a.attrs['href']
# 清空lst列表
lst.clear()
# 将数据存入列表中
list.append([name[0].string, Name[2],Href])
except:
print("fillList()函数解析出错")
# 输出格式
def printList(list,num):
# 由于中英文空格占用的长度不同,导致对齐时可能会出现问题
# 此处的{4},是指当用.format()方法时,用第五个元素代替英文空格
# chr(12288)即为中文空格
tplt = "{0:^10}\t{1:{4}^15}\t{2:{4}<30}\t{3:<30}"
print(tplt.format("排名", "电影名", "电影链接", "电影别名",chr(12288)))
count = 0
# 输出的格式
for i in range(num):
count = count + 1
lst = list[i]
print(tplt.format(count,lst[0],lst[2],lst[1],chr(12288)))
def main():
# 首页网址
start_url = "https://movie.douban.com/top250"
# page为需要爬取的网页的页数
page = 5
list = []
# num为爬取的电影的个数,一页是有25个电影数据
num = page * 25
for i in range(page):
try:
# 由分析知每增加一页start增加25
url = start_url + '?start=' + str(25* i)
html = getHtmlText(url)
fillList(list, html)
except:
# 如果出现错误,继续执行
continue
printList(list, num)
main()
(3)实验结果图:
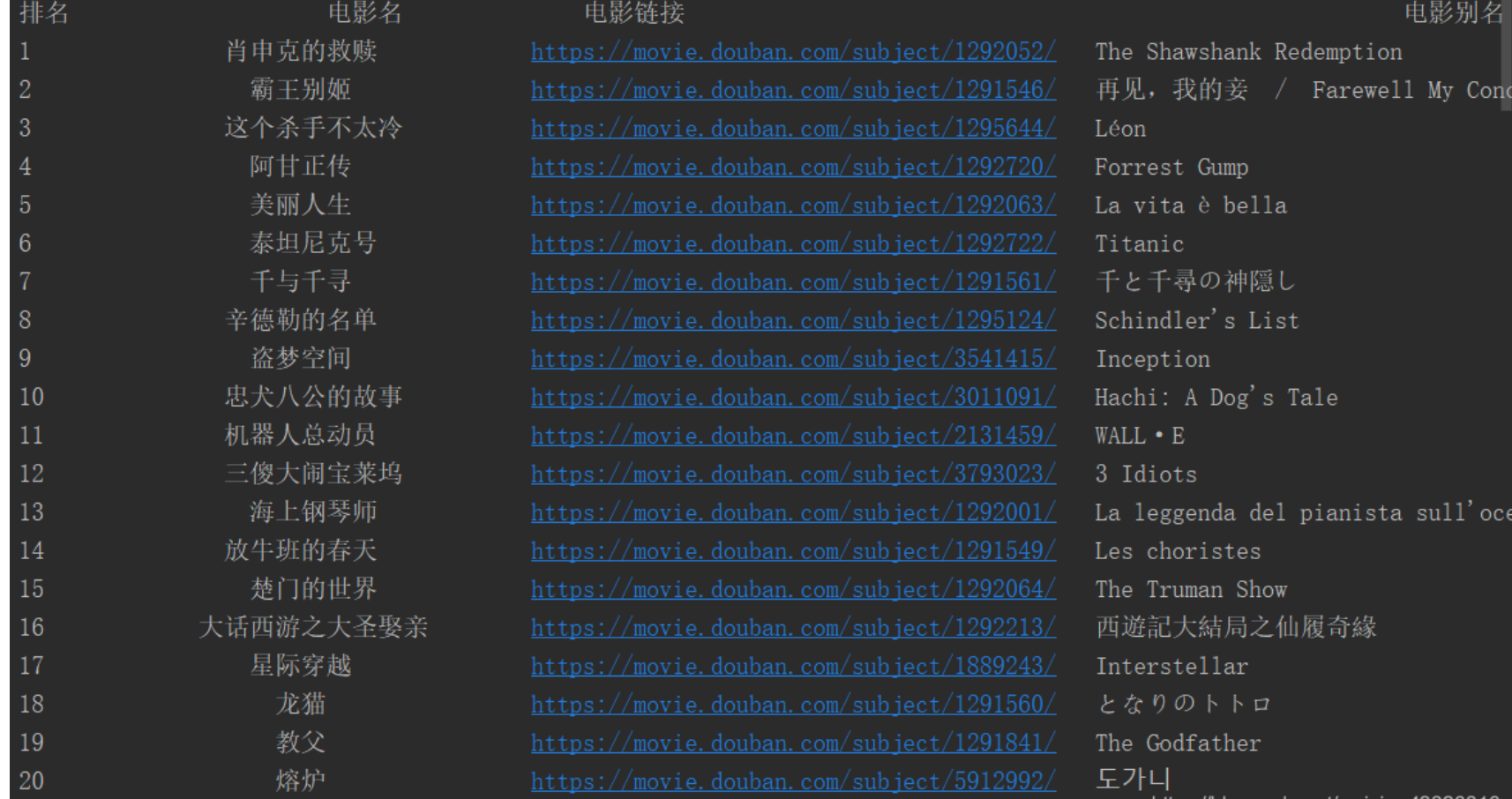
作业②:
(1)实验要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
(2)实验代码:
item:
class UniversityrankItem(scrapy.Item):
sNo = scrapy.Field()
schoolName = scrapy.Field()
city = scrapy.Field()
officalUrl = scrapy.Field()
info = scrapy.Field()
mFile=scrapy.Field()
mSrc=scrapy.Field()
spider.py:
import time
import requests
import scrapy
from universityRank.items import UniversityrankItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
start_urls = []
urls=[]
sNo=0
names=[]
citys=[]
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51"}
# 获取所有大学详细链接
def __init__(self):
resp = requests.get('https://www.shanghairanking.cn/rankings/bcur/2020', headers=self.headers)
resp.encoding = resp.apparent_encoding
data = resp.text
selector = scrapy.Selector(text=data)
trs = selector.xpath("//*[@id='content-box']/div[2]/table/tbody/tr")
for tr in trs:
url = 'https://www.shanghairanking.cn' + tr.xpath("./td[2]/a/@href").extract_first().strip()
self.names.append(tr.xpath("./td[2]/a/text()").extract_first().strip())
self.citys.append(tr.xpath("./td[3]/text()").extract_first().strip())
self.start_urls.append(url)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
schoolName = self.names[self.sNo]
city = self.citys[self.sNo]
officalUrl=selector.xpath("//div[@class='univ-website']/a/text()").extract_first()
info=selector.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
time.sleep(1)
mSrc=selector.xpath("//td[@class='univ-logo']/img/@src").extract_first()
self.sNo+=1
item= UniversityrankItem()
item["sNo"] = self.sNo
item["schoolName"] = schoolName.strip() if schoolName else ""
item["city"] = city.strip() if city else ""
item["officalUrl"] = officalUrl.strip() if officalUrl else ""
item["info"] = info.strip() if info else ""
item["mFile"]=str(self.sNo)+".jpg"
item["mSrc"]=mSrc.strip() if mSrc else ""
yield item
except Exception as err:
print(err)
pipelines:
from itemadapter import ItemAdapter
import pymysql
class RuankePipeline:
def open_spider(self, spider):
print("建立连接")
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd='031804114.hao', db='mydb',
charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
self.cursor.execute("drop table if exists ruanke")
sql = """create table ruanke(
sNo varchar(32) primary key,
schoolName varchar(32),
city varchar(32),
officalUrl varchar(64),
info text,
mFile varchar(32)
)character set = utf8
"""
self.cursor.execute(sql)
except Exception as err:
print(err)
print("表格创建失败")
self.open = True
self.count = 1
except Exception as err:
print(err)
self.open = False
print("数据库连接失败")
def process_item(self, item, spider):
print(item['sNo'], item['schoolName'], item['city'], item['officalUrl'], item['info'], item['mFile'])
if self.open:
try:
self.cursor.execute(
"insert into ruanke(sNo,schoolName,city,officalUrl,info,mFile) values(%s,%s,%s,%s,%s,%s)", \
(item['sNo'], item['schoolName'], item['city'], item['officalUrl'], item['info'], item['mFile']))
self.count += 1
except:
print("数据插入失败")
else:
print("数据库未连接")
return item
def close_spider(self, spider):
if self.open:
self.con.commit()
self.con.close()
self.open = False
print('closed')
print("一共爬取了", self.count, "条")
(3)实验结果图:
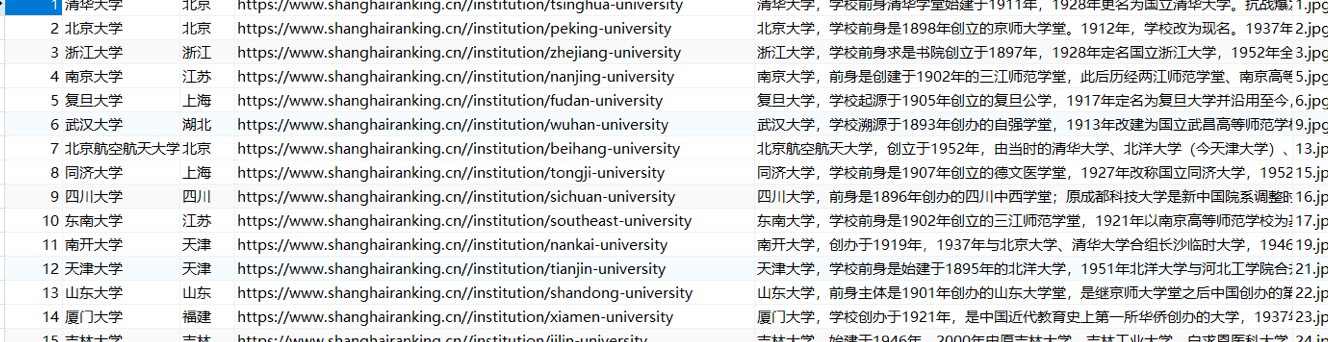

作业3:
(1)要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
(2)实验代码:
# -*- coding:utf-8 -*-
import time
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import json
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--disable-gpu")
browser = webdriver.Chrome(executable_path='G:\\chromedriver.exe', options=chrome_options)
browser.get('https://www.icourse163.org/learn/NJTU-1002530017#/learn/content?type=detail&id=1004513821') # 目标网页
time.sleep(3)
video = {}
soup = BeautifulSoup(browser.page_source, 'html.parser')
c_l = soup.find("div", attrs={"class": "j-breadcb f-fl"})
chapter_all = c_l.find("div", attrs={"class": "f-fl j-chapter"})
chapter = chapter_all.find_all("div", attrs={"class": "f-thide list"})
for chap in chapter:
js = 'document.querySelectorAll("div.down")[0].style.display="block";'
browser.execute_script(js)
chapter_name = chap.text
a = browser.find_element_by_xpath("//div[@title = '"+chapter_name+"']")
a.click()
time.sleep(3)
soup1 = BeautifulSoup(browser.page_source, 'html.parser')
c_l1 = soup1.find("div", attrs={"class": "j-breadcb f-fl"})
lesson_all = c_l1.find("div", attrs={"class": "f-fl j-lesson"})
lesson = lesson_all.find_all("div", attrs={"class": "f-thide list"})
for les in lesson:
js1 = 'document.querySelectorAll("div.down")[1].style.display="block";'
browser.execute_script(js1)
lesson_name = les.text
b = browser.find_element_by_xpath("//div[@title = '"+lesson_name+"']")
b.click()
time.sleep(3)
soup2 = BeautifulSoup(browser.page_source, 'html.parser')
units = soup2.find_all("li", attrs={"title": re.compile(r"^视频")}) # 只爬取视频课件
for unit in units:
video_name = unit.get("title")
video_link = browser.find_element_by_xpath("//li[@title = '"+video_name+"']")
video_link.click()
time.sleep(3)
soup2 = BeautifulSoup(browser.page_source, 'html.parser')
try:
video_src = soup2.find("source")
video[chapter_name + " " + lesson_name + video_name] = video_src.get("src")
except:
continue
browser.quit()
(3)实验结果图:


