
数据采集第二次作业
作业1:
(1)实验要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
(2)实验代码:
import requests
from bs4 import BeautifulSoup
import re
def get_page(url):
try:
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers = kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '错误'
def parse_page(html, return_list):
soup = BeautifulSoup(html, 'html.parser')
day_list = soup.find('ul', 't clearfix').find_all('li')
for day in day_list:
date = day.find('h1').get_text()
wea = day.find('p', 'wea').get_text()
if day.find('p', 'tem').find('span'):
hightem = day.find('p', 'tem').find('span').get_text()
else:
hightem = ''
lowtem = day.find('p', 'tem').find('i').get_text()
#win = re.search('(?<= title=").*?(?=")', str(day.find('p','win').find('em'))).group()
win = re.findall('(?<= title=").*?(?=")', str(day.find('p','win').find('em')))
wind = '-'.join(win)
level = day.find('p', 'win').find('i').get_text()
return_list.append([date, wea, lowtem, hightem, wind, level])
#return return_list
def print_res(return_list):
print('城市:河南南阳')
tplt = '{0:<10}\t{1:^10}\t{2:^10}\t{3:{6}^10}\t{4:{6}^10}\t{5:{6}^5}'
print(tplt.format('日期', '天气', '最低温', '最高温', '风向', '风力',chr(12288)))
for i in return_list:
print(tplt.format(i[0], i[1],i[2],i[3],i[4],i[5],chr(12288)))
def main():
url = 'http://www.weather.com.cn/weather/101180701.shtml'
html = get_page(url)
wea_list = []
parse_page(html, wea_list)
print_res(wea_list)
if __name__ == '__main__':
main()
(3)实验结果:

(4)心得体会:
不同城市有不同城市的代码,可以根据城市的不同替换URL就好;
也可以把城市代码也到数据库中,根据输入城市名字找到对应的城市代码后再进行爬取。但是这里只想知道自己城市的天气,因此URL是用家乡河南南阳作为例子写的
作业2:
(1)要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
(2)实验代码:
#CrawGuchengStocks.py
import requests
from bs4 import BeautifulSoup
import re #引入正则表达式库,便于后续提取股票代码
import xlwt #引入xlwt库,对Excel进行操作。
import time #引入time库,计算爬虫总共花费的时间。
def getHTMLText(url, code="utf-8"): #获取HTML文本
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except:
return ""
def getStockList(lst, stockURL): #获取股票代码列表
html = getHTMLText(stockURL, "GB2312")
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a') #得到一个列表
for i in a:
try:
href = i.attrs['href'] #股票代码都存放在href标签中
lst.append(re.findall(r"[S][HZ]\d{6}", href)[0])
except:
continue
def getStockInfo(lst, stockURL, fpath):
count = 0
#lst = [item.lower() for item in lst] 股城网url是大写,所以不用切换成小写
for stock in lst:
url = stockURL + stock + "/" #url为单只股票的url
html = getHTMLText(url) #爬取单只股票网页,得到HTML
try:
if html=="": #爬取失败,则继续爬取下一只股票
continue
infoDict = {} #单只股票的信息存储在一个字典中
soup = BeautifulSoup(html, 'html.parser') #单只股票做一锅粥
stockInfo = soup.find('div',attrs={'class':'stock_top clearfix'})
#在观察股城网时发现,单只股票信息都存放在div的'class':'stock_top clearfix'中
#在soup中找到所有标签div中属性为'class':'stock_top clearfix'的内容
name = stockInfo.find_all(attrs={'class':'stock_title'})[0]
#在stockInfo中找到存放有股票名称和代码的'stock_title'标签
infoDict["股票代码"] = name.text.split("\n")[2]
infoDict.update({'股票名称': name.text.split("\n")[1]})
#对name以换行进行分割,得到一个列表,第1项为股票名称,第2项为代码
#如果以空格股票名称中包含空格,会产生异常,
#如“万 科A",得到股票名称为万,代码为科A
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
#股票信息都存放在dt和dd标签中,用find_all产生列表
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
#将信息的名称和值作为键值对,存入字典中
with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
#将每只股票信息作为一行输入文件中
count = count + 1
print("\r爬取成功,当前进度: {:.2f}%".format(count*100/len(lst)),end="")
except:
count = count + 1
print("\r爬取失败,当前进度: {:.2f}%".format(count*100/len(lst)),end="")
continue
def get_txt(): #将爬取的数据保存在TXT文件中
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'https://hq.gucheng.com/'
output_file = '\\文件\\中大\\Python\\练习项目\\MOOC python爬虫\\GuChengStockInfoTest.txt'
slist=[]
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
def T_excel(file_name,path): #将TXT文件转换为Excel文件
fo = open(file_name,"rt",encoding='utf-8')
file = xlwt.Workbook(encoding='utf-8', style_compression=0)
#创建一个Workbook对象,这就相当于创建了一个Excel文件。
#Workbook类初始化时有encoding和style_compression参数
#w = Workbook(encoding='utf-8'),就可以在excel中输出中文了。
sheet = file.add_sheet('stockinfo')
line_num = 0 #初始行用来添加表头
#给Excel添加表头
title = ['股票代码', '股票名称', '最高', '最低', '今开', '昨收',
'涨停', '跌停', '换手率', '振幅', '成交量', '成交额',
'内盘', '外盘', '委比', '涨跌幅', '市盈率(动)', '市净率',
'流通市值', '总市值']
for i in range(len(title)):
sheet.write(0, i, title[i])
for line in fo:
stock_txt = eval(line)
#print(stock_txt)
line_num += 1 #每遍历一行TXT文件,line_num加一
keys = []
values = []
for key,value in stock_txt.items():
#遍历字典项,并将键和值分别存入列表
keys.append(key)
values.append(value)
#print(keys,values,len(values))
for i in range(len(values)):
#sheet.write(0, i, keys[i])
sheet.write(line_num,i,values[i]) #在第line_num行写入数据
i = i+1
file.save(path) #将文件保存在path路径。
def main():
start = time.perf_counter()
get_txt()
txt = "/Users/dar_z/Desktop/test/gupiao.txt"
excelname = '/Users/dar_z/Desktop/test/gupiao.xls'
T_excel(txt,excelname)
time_cost = time.perf_counter() - start
print("爬取成功,文件保存路径为:\n{}\n,共用时:{:.2f}s".format(excelname,time_cost))
main()
(3)实验结果:
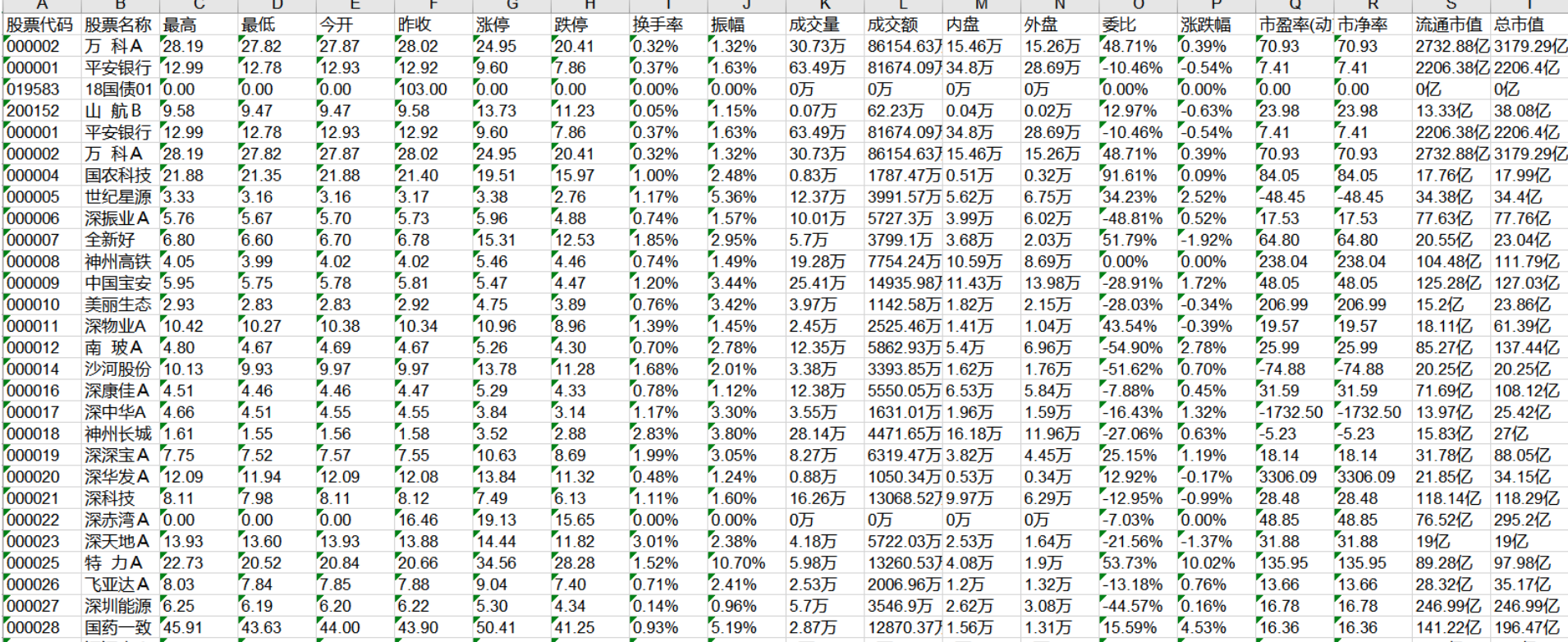
(4)新的体会:
向爬取对象发送http请求,获取HTML文本;
②获取所有股票代码,存入列表,将用于生成单只股票URL。从股城网我们可以看到单只股票的网页URL格式为“https://hq.gucheng.com/股票代码/”,如平安银行的url为https://hq.gucheng.com/SZ000001/;
③对每只股票的网页进行爬取,并解析网页,将获取的信息存入字典中;
④将股票信息存入TXT文件中;
⑤将TXT文件转换为Excel。

