
作业一:关于Linux进程的分析
在我们分析Linux的进程模型之前我们要先知道Linux是什么。
1.Linux概述
Linux是一个基于POSIX和Unix的多用户、多任务、支持多线程和多CPU的性能稳定的操作系统,可免费使用并自由传播。
Linux继承了Unix以网络为核心的设计思想,它同时也是一个类Unix操作系统,能运行主要的Unix工具软件、应用程序和网络协议,支持32位及64位硬件,可安装在比如手机、平板电脑、路由器、台式计算机、超级计算机等各种计算机硬件设备中。
Linux操作系统最初由一位名为Linus Torvalds(林纳斯 托瓦兹)的芬兰赫尔辛基大学的学生编制内核,随后由全世界各地的成千上万的程序员设计和实现。其目的是建立不受任何商品化软件的版权制约的、全世界都能自由使用的类Unix兼容产品。
我们了解了Linux后就应该知道什么是进程
2.进程:
2.1进程的概念:
进程是操作系统结构的基础;是一个正在执行的程序;计算机中正在运行的程序实例;可以分配给处理器并由处理器执行的一个实体;由单一顺序的执行显示,一个当前状态和一组相关的系统资源所描述的活动单元。在电脑的应用程序被运行后,就相当于将应用程序装进容器里了,你可以往容器里加其他东西(如:应用程序在运行时所需的变量数据、需要引用的DLL文件等),当应用程序被运行两次时,容器里的东西并不会被倒掉,系统会找一个新的进程容器来容纳它。为了深刻描述程序动态执行过程的性质,人们引入“进程(Process)”概念。
了解进程基本概念后我们就要深入探究进程的具体运行
2.2 进程的表示:
在 Linux 内核内,进程是由一个称为 task_struct 的结构表示的。此结构包含所有表示此进程所必需的数据,此外,还包含了大量的其他数据用来统计和维护与其他进程的关系。这个结构是非常庞大的。将它的所有域按其功能可做如下划分:
- 进程状态(State)
- 进程调度信息(Scheduling Information)
- 各种标识符(Identifiers)
- 进程通信有关信息(IPC:Inter_Process Communication)
- 时间和定时器信息(Times and Timers)
- 进程链接信息(Links)
- 文件系统信息(File System)
- 虚拟内存信息(Virtual Memory)
- 页面管理信息(page)
- 对称多处理器(SMP)信息
- 和处理器相关的环境(上下文)信息(Processor Specific Context)
- 其它信息
我们都知道进程是非常多的,那么如何用简单的方式来标识进程就非常的重要。他可以帮助我们轻松地管理进程,那么我们就开始了解一下进程的标记符
2.3进程的标识符
2.3.1标识符的作用:
进程标识符是用来唯一地标识一个进程的一个数值。每个进程都有一个唯一的标识符,内核通过这个标识符来识别不同的进程,同时,进程标识符PID也是内核提供给用户程序的接口,用户程序通过PID对进程发号施令。
2.3.2Linux上标识符的特点;
PID是32位的无符号整数,它被顺序编号:新创建进程的PID通常是前一个进程的PID加1。然而,为了与16位硬件平台的传统Linux系统保持兼容,在Linux上允许的最大PID号是32767,当内核在系统中创建第32768个进程时,就必须重新开始使用已闲置的PID号。
3.操作系统是如何组织进程的
来源:http://www.bubuko.com/infodetail_83248.html
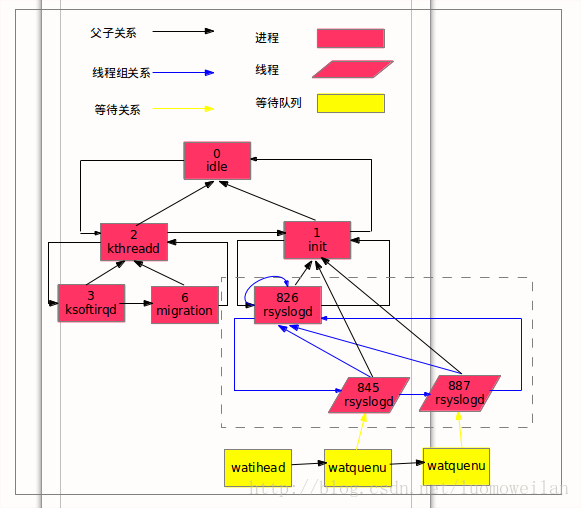
为了管理进程的创建、消亡(处理僵尸进程等操作)使用了父子、兄弟关系;为了统一处理同一信号量,使用线程组关系;为了方便全局查找,使用了哈希表关系;为了调度程序,使用了运行队列、等待队列数据结构。
4.进程的状态是如何转换的
4.1进程的状态:
|
内核表示 |
含义 |
|
TASK_RUNNING |
可运行 |
|
TASK_INTERRUPTIBLE |
可中断的等待状态 |
|
TASK_UNINTERRUPTIBLE |
不可中断的等待状态 |
|
TASK_ZOMBIE |
僵死 |
|
TASK_STOPPED |
暂停 |
|
TASK_SWAPPING |
换入/换出 |
(1)可运行状态:处于这种状态的进程,要么正在运行、要么正准备运行。正在运行的进程就是当前进程,而准备运行的进程只要得到CPU就可以立即投入运行,CPU是这些进程唯一等待的系统资源。
(2).等待状态:处于该状态的进程正在等待某个事件(event)或某个资源,它肯定位于系统中的某个等待队列(wait_queue)中。
(3).暂停状态:此时的进程暂时停止运行来接受某种特殊处理。通常当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或 SIGTTOU信号后就处于这种状态。例如,正接受调试的进程就处于这种状态。
(4).僵死状态:进程虽然已经终止,但由于某种原因,父进程还没有执行wait()系统调用,终止进程的信息也还没有回收。顾名思义,处于该状态的进程就是死进程,这种进程实际上是系统中的垃圾,必须进行相应处理以释放其占用的资源。
我们已经知道了进程的各个状态,那么状态之间是如何转换的呢。我们通过一个状态的转换图来了解一下
4.2进程状态转换图
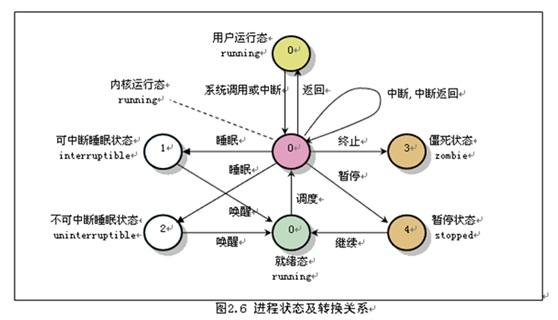
看了状态之间的转换方式后我相信你一定对于进程有了大致的了解。但是你肯定疑惑如何合理的调度进程才能使系统更加的高效,那我们下面就来看看进程的调度信息
5.进程的调度
5.1 什么是进程调度:
调度程序利用一部分信息决定系统中哪个进程最应该运行,并结合进程的状态信息保证系统运转的公平和高效。这一部分信息通常包括进程的类别(普通进程还是实时进程)、进程的优先级等。
通俗的说进程的调度就是利用某些信息并且根据一种的规则来合理的决定进程的运行,那么很显然要合理高效的来组织进程运行,这种规则是至关重要的。这种规则就是我们说的调度算法。我们后面就详细的说明调度算法。
5.2调度算法——CFS调度算法:
5.2.1 CFS原理:
cfs定义了一种新的模型,它给cfs_rq(cfs的run queue)中的每一个进程安排一个虚拟时钟,vruntime。如果一个进程得以执行,随着时间的增长(也就是一个个tick的到来),其vruntime将不断增大。没有得到执行的进程vruntime不变。
需要强调的是调度器总是选择vruntime跑得最慢的那个进程来执行。这就是所谓的“完全公平”。为了区别不同优先级的进程,优先级高的进程vruntime增长得慢,以至于它可能得到更多的运行机会。
5.2.2 CFS设计思路:
(注:这个算法设计思路看起来很简单但是里面具体的部分有些我是真的有点蒙,我只能是大概给大家说一下。里面的细节等我研究透彻后再重新写一下。下面只是我粗略的对于大神思路的一些简单整理)
思路我们可以简单的理解为就是根据进程的权重来分配运行时间(当然如何计算权重也是非常重要)
那么分配给进程的时间应该如何计算。其公式为:
分配给进程的运行时间 = 调度周期 * 进程权重 / 所有进程权重之和
我觉得一个调度算法最重要的应该是他的公平性,那么CFS的公平性如何体现呢
其实公平是体现在另外一个量上面,叫做virtual runtime(vruntime),它记录着进程已经运行的时间,但是并不是直接记录,而是要根据进程的权重将运行时间放大或者缩小一个比例。
我们来看下从实际运行时间到vruntime的换算公式
vruntime = 实际运行时间 * 1024 / 进程权重 。
这里大神有提到这个1024是指 nice为0的进程的权重,代码中是NICE_0_LOAD。也就是说,所有进程都以nice为0的进程的权重1024作为基准,计算自己的vruntime增加速度。那么我们简单理解CFS的思想就是让每个调度实体的vruntime互相追赶,而每个调度实体的vruntime增加速度不同,权重越大的增加的越慢,那么就必须执行更多的次数来达到VRUNtime的平衡,这样就能获得更多的cpu执行时间。
5.2.3 CFS的数据结构
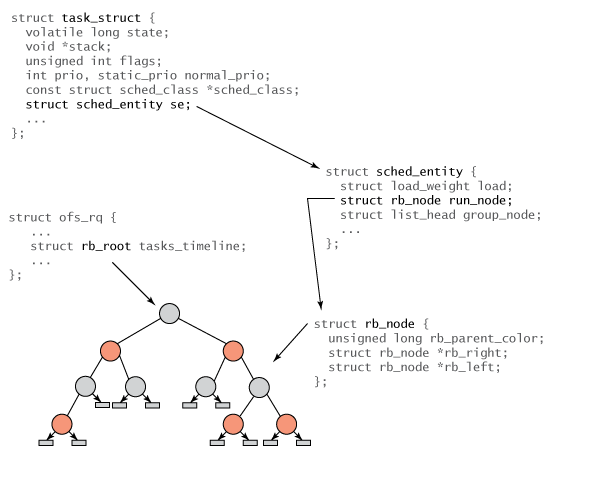
struct task_struct 的变化
CFS 去掉了 struct prio_array,并引入调度实体(scheduling entity)和调度类 (scheduling classes),分别由 struct sched_entity 和 struct sched_class 定义。因此,task_struct 包含关于 sched_entity 和 sched_class这两种结构的信息:
struct task_struct { /* Defined in 2.6.23:/usr/include/linux/sched.h */ .... - struct prio_array *array; + struct sched_entity se; + struct sched_class *sched_class; .... .... };
struct sched_entity
该结构包含了完整的信息,用于实现对单个任务或任务组的调度。它可用于实现组调度。调度实体可能与进程没有关联。
清单 2. sched_entity 结构
struct sched_entity { /* Defined in 2.6.23:/usr/include/linux/sched.h */ long wait_runtime; /* Amount of time the entity must run to become completely */ /* fair and balanced.*/ s64 fair_key; struct load_weight load; /* for load-balancing */ struct rb_node run_node; /* To be part of Red-black tree data structure */ unsigned int on_rq; .... };
struct sched_class
该调度类类似于一个模块链,协助内核调度程序工作。每个调度程序模块需要实现 struct sched_class 建议的一组函数。
清单 3. sched_class 结构
struct sched_class { /* Defined in 2.6.23:/usr/include/linux/sched.h */ struct sched_class *next; void (*enqueue_task) (struct rq *rq, struct task_struct *p, int wakeup); void (*dequeue_task) (struct rq *rq, struct task_struct *p, int sleep); void (*yield_task) (struct rq *rq, struct task_struct *p); void (*check_preempt_curr) (struct rq *rq, struct task_struct *p); struct task_struct * (*pick_next_task) (struct rq *rq); void (*put_prev_task) (struct rq *rq, struct task_struct *p); unsigned long (*load_balance) (struct rq *this_rq, int this_cpu, struct rq *busiest, unsigned long max_nr_move, unsigned long max_load_move, struct sched_domain *sd, enum cpu_idle_type idle, int *all_pinned, int *this_best_prio); void (*set_curr_task) (struct rq *rq); void (*task_tick) (struct rq *rq, struct task_struct *p); void (*task_new) (struct rq *rq, struct task_struct *p); };
1.enqueue_task:当某个任务进入可运行状态时,该函数将得到调用。它将调度实体(进程)放入红黑树中,并对nr_running变量加 1。2.dequeue_task:当某个任务退出可运行状态时调用该函数,它将从红黑树中去掉对应的调度实体,并从nr_running变量中减 1。3.yield_task:在compat_yield sysctl关闭的情况下,该函数实际上执行先出队后入队;在这种情况下,它将调度实体放在红黑树的最右端。4.check_preempt_curr:该函数将检查当前运行的任务是否被抢占。在实际抢占正在运行的任务之前,CFS 调度程序模块将执行公平性测试。这将驱动唤醒式(wakeup)抢占。5.pick_next_task:该函数选择接下来要运行的最合适的进程。6.load_balance:每个调度程序模块实现两个函数,load_balance_start()和load_balance_next(),使用这两个函数实现一个迭代器,在模块的load_balance例程中调用。内核调度程序使用这种方法实现由调度模块管理的进程的负载平衡。7.set_curr_task:当任务修改其调度类或修改其任务组时,将调用这个函数。8.task_tick:该函数通常调用自 time tick 函数;它可能引起进程切换。这将驱动运行时(running)抢占。9.task_new:内核调度程序为调度模块提供了管理新任务启动的机会。CFS 调度模块使用它进行组调度,而用于实时任务的调度模块则不会使用这个函数。
6.对操作系统进程模型的看法
我在探究进程模型的过程中,逐渐被Linux的进程模型所折服。因为我没有了解到其他系统的进程模型 ,我也不好跟其他的相比较。按照我对于这段时间学习进程模型,我大致说一下自己不成熟的看法,毕竟我对于进程还知之甚少。首先想要一个较好的用户体验,进程模型是真的非常重要 ,而在进程模型中,调度算法更是重中之重。CFS调度我觉得已经做得非常完美。Linux的调度算法,也是不断改进的。曾经2.6内核的O(1)调度器非常经典,但是后来内核调度器就改成了以红黑树为基本数据结构的算法了。调度算法,是个复杂的问题,但其功能非常明确,就是选择“合适的进程”去执行。选择完进程之后,当然就是执行了。进程模型当然不只是只有调度算法,还有进程状态的转换关系也十分重要。当然我觉得进程状态应该很难在有所改变,调度算法的优化也不是简单的问题。我个人是没办法找到现有的进程模型有什么不足。
相关资料的链接
1.https://blog.csdn.net/dyllove98/article/details/9281081
https://blog.csdn.net/zjf280441589/article/details/43339007
http://blog.sina.com.cn/s/blog_79e165ef0102wcvz.html
https://blog.csdn.net/fdssdfdsf/article/details/7894211


