
数据采集第一次大作业
第一次作业
一、作业内容
- 作业①:
– 要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
– 输出信息:
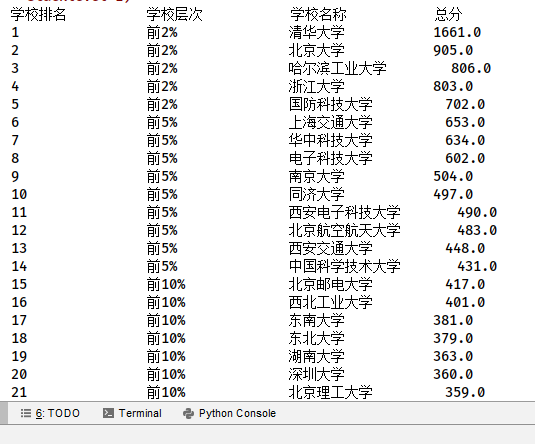
|
2020排名 |
2019排名 |
全部层次 |
学校类型 |
总分 |
|
1 |
2 |
前2% |
中国人民大学 |
1069.0 |
|
2...... |
|
|
|
|
主要步骤:
1.分析网页,查找表格元素所在地
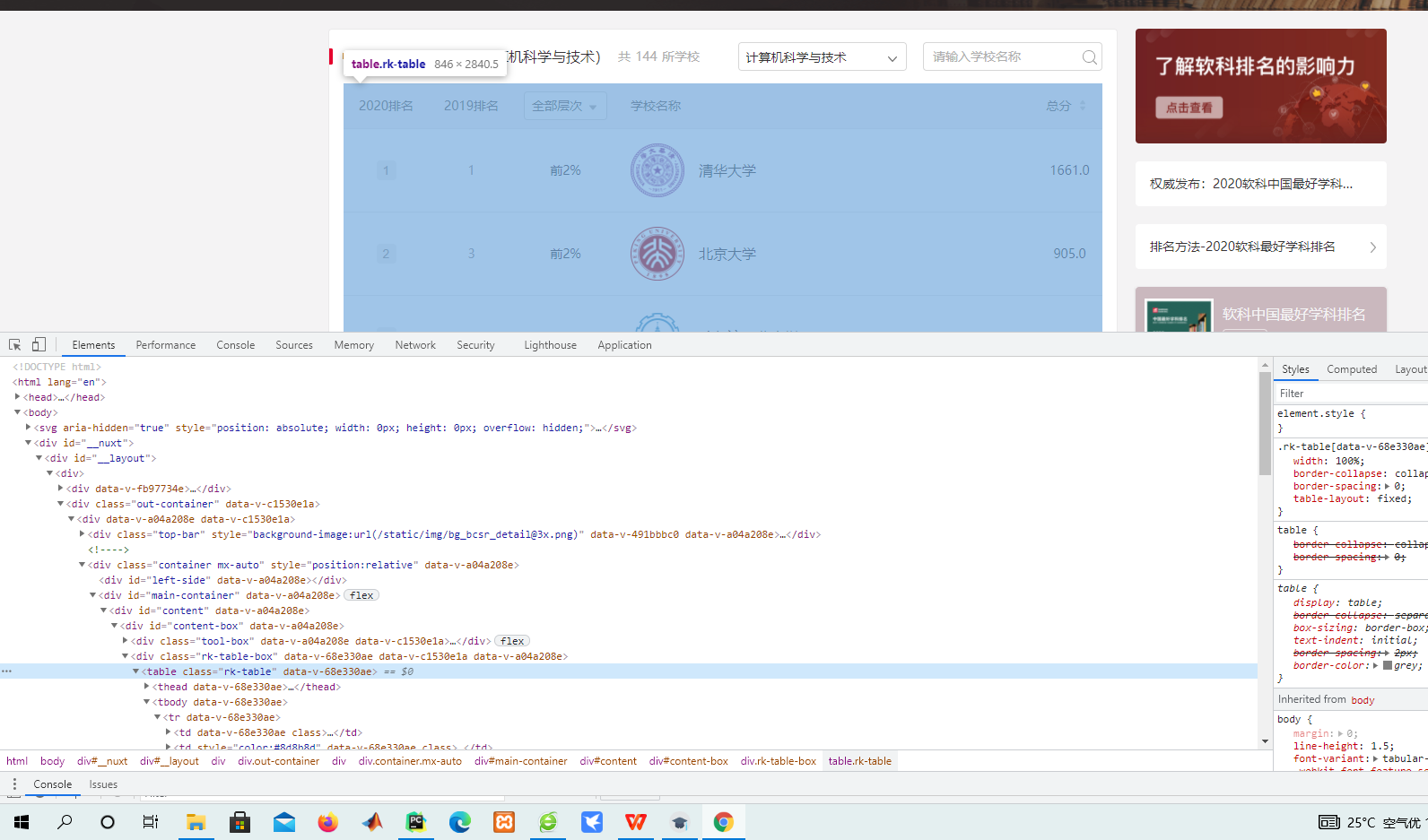
2.urlib请求网页

3.定位表格,用re提取内容
info = re.findall(r'<div class="ranking" data-v-68e330ae>(.*?)</div>.*?</span></td><td data-v-68e330ae>(.*?)<!----></td><td class="align-left" data-v-68e330ae>.*?class="name-cn" data-v-b80b4d60>(.*?) </a> <div class="collection".*?</div></div> <!----> <!----> <!----> <!----></div></div></td><td data-v-68e330ae>(.*?)</td></tr>',res)
print("学校排名 学校层次 学校名称 总分")
for i in info:
print(f"{i[0].strip():<17}{i[1].strip():<17}{i[2].strip():<15}{i[3].strip():<17}")
- 作业②:
– 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
– 输出信息:
|
序号 |
城市 |
AQI |
PM2.5 |
SO2 |
No2 |
Co |
首要污染物 |
|
1 |
北京 |
55 |
6 |
5 |
1.0 |
225 |
— |
|
2...... |
|
|
|
|
|
|
|
1.分析网页
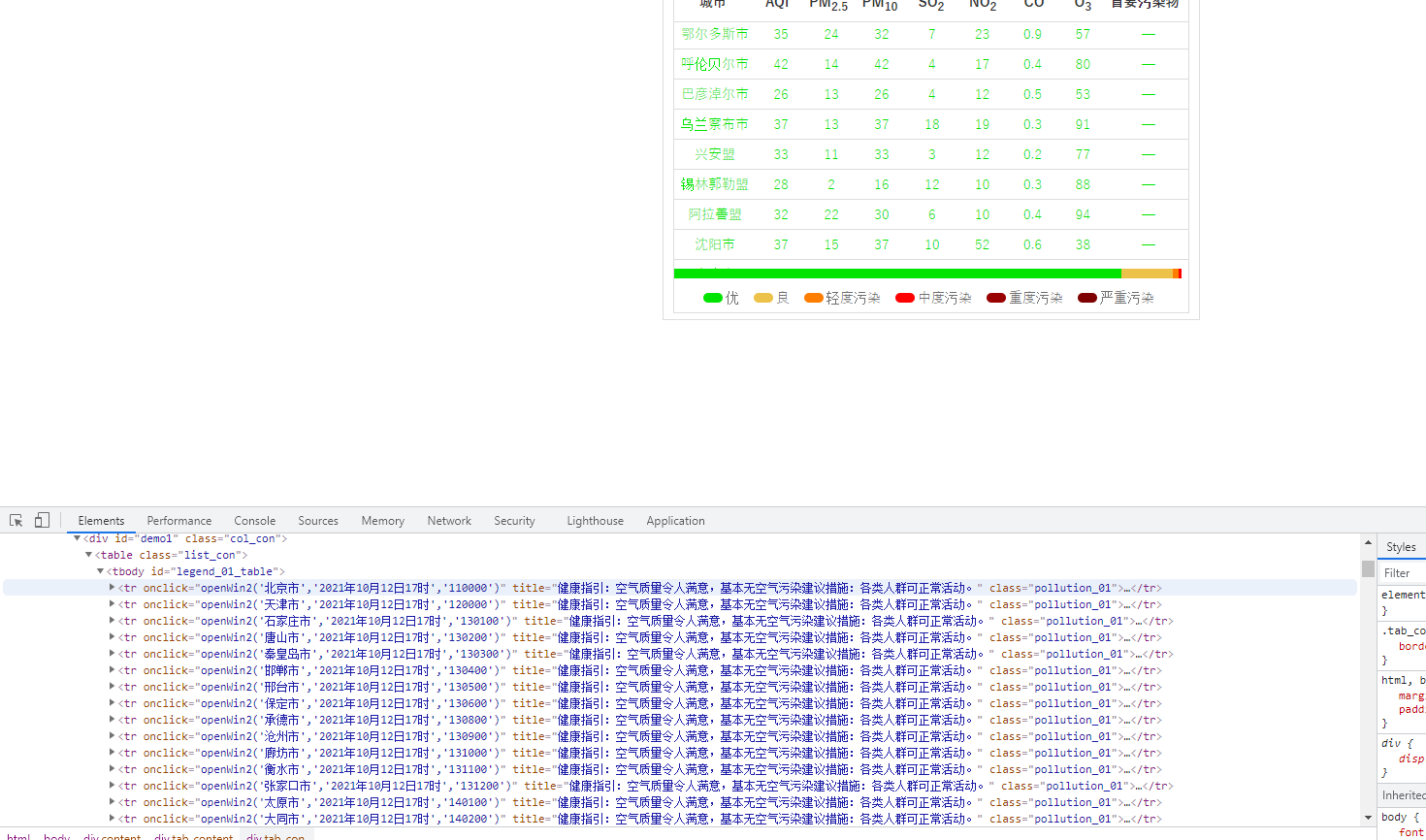
2.requests请求

3.写beautiful soup 表达式

4.结果
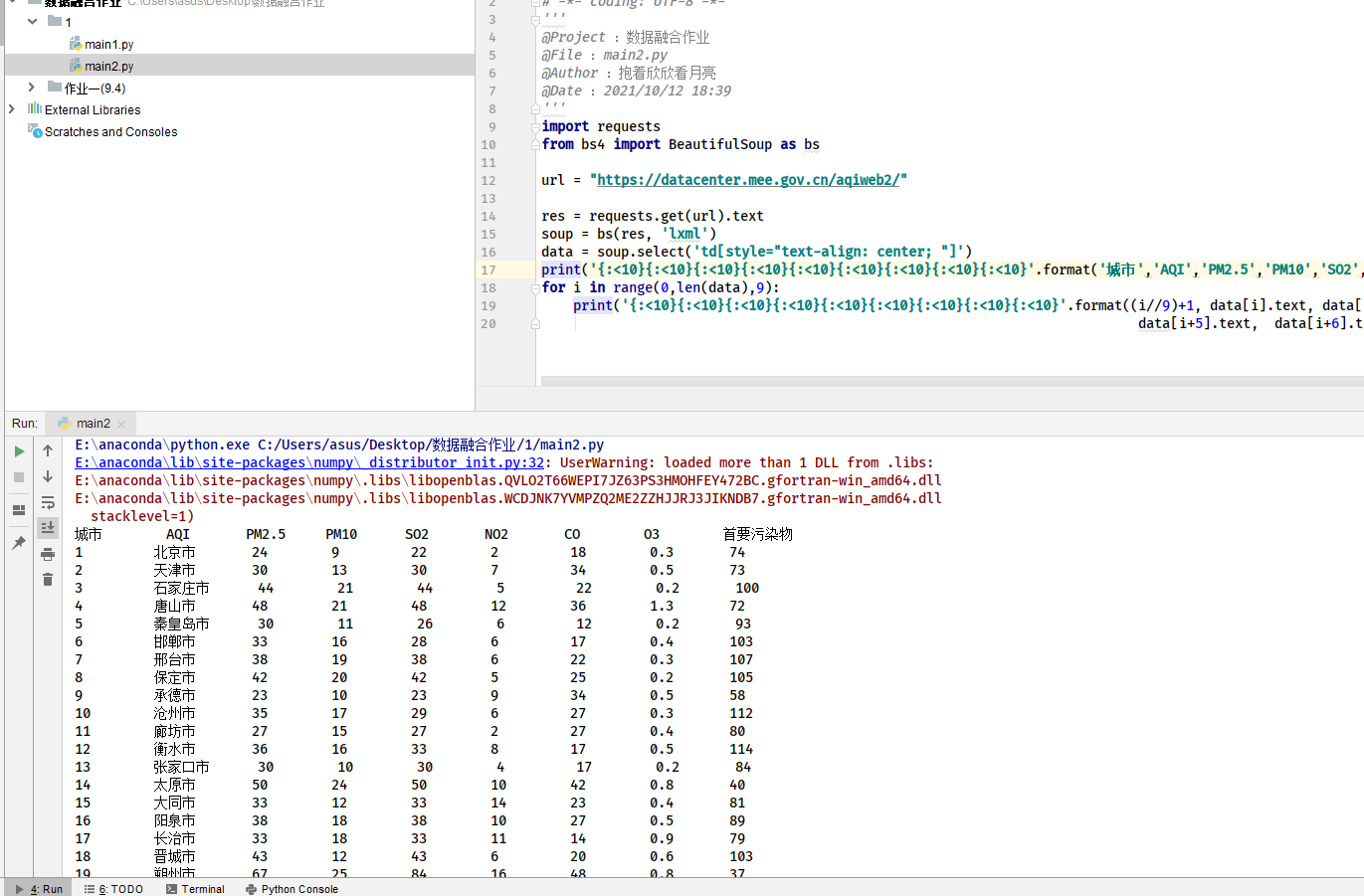
- 作业③:
– 要求:使用urllib和requests和re爬取一个给定网页(https://news.fzus.edu.cn/)爬取该网站下的所有图片
– 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
代码
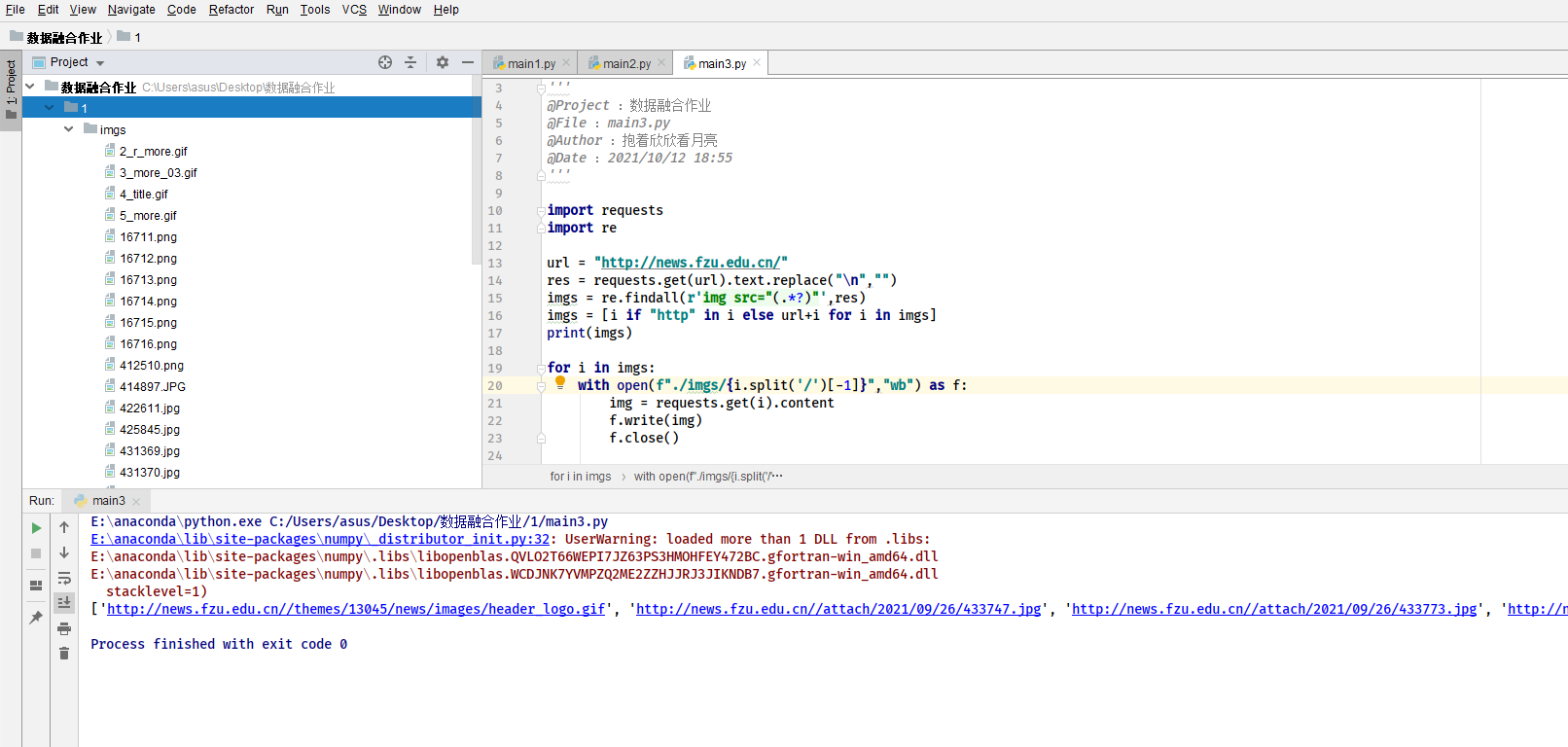
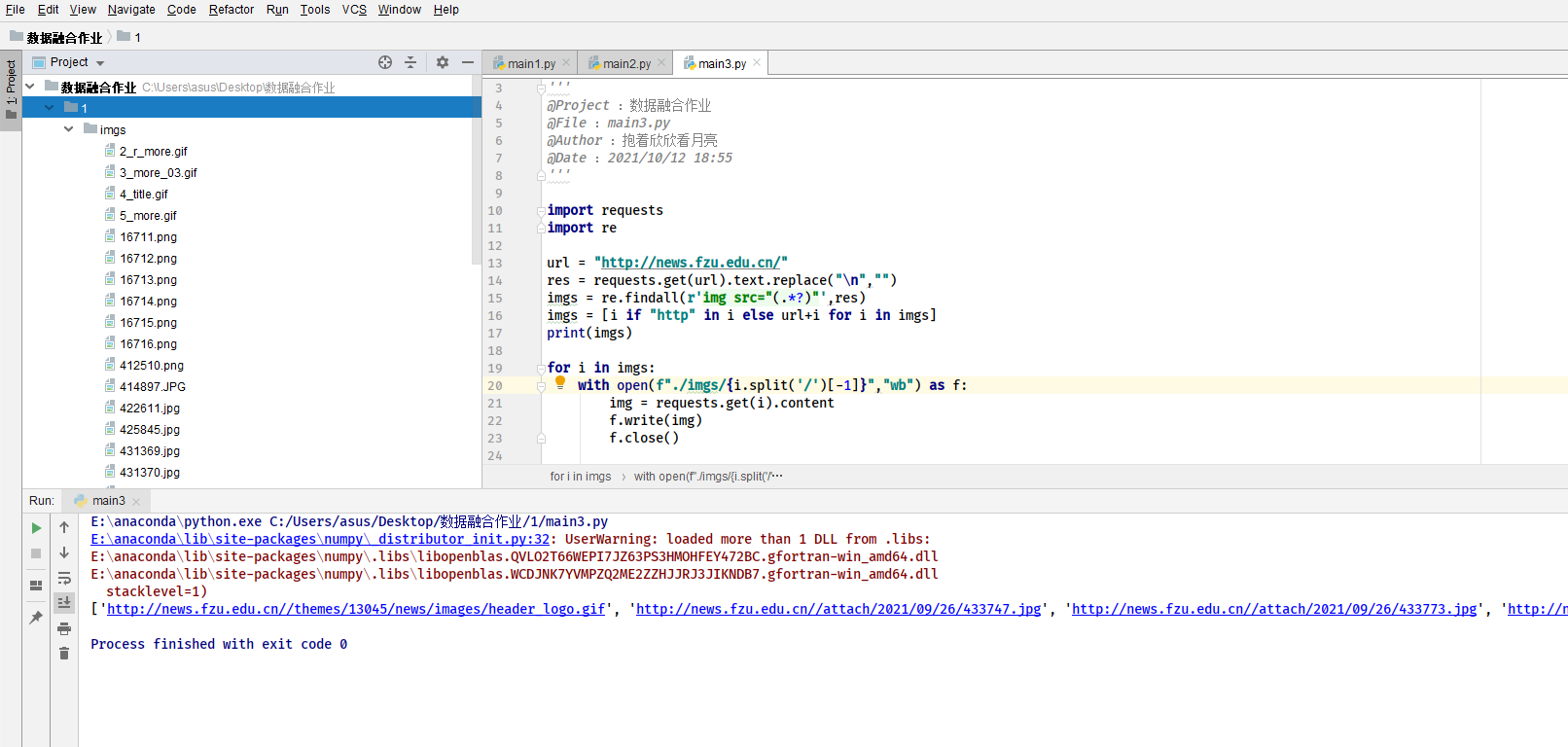
心得体会:
-
通过此题实践,我掌握了从网页上保存图片至本地的urllib方法和requests方法,同时也对正则表达式的使用更加的熟练。
- 代码链接

