


软件工程第二次作业
Github仓库链接:https://github.com/SorrowSquirrel/3123004193
| 这个作业属于哪个课程 | 23级计科12班 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13468 |
| 这个作业的目标 | 提高我的项目开发能力,设计并实现一个论文查重系统,通过计算两篇论文的相似度来检测抄袭,继续熟悉Git操作 |
PSP 表格(预估)
| PSP2.1 | 阶段 | 预估时间(分钟) |
|---|---|---|
| 计划 | 估计任务时间 | 30 |
| 开发 | 需求分析 | 60 |
| 开发 | 生成设计文档 | 60 |
| 开发 | 设计复审 | 30 |
| 开发 | 代码规范 | 30 |
| 开发 | 具体设计 | 60 |
| 开发 | 具体编码 | 180 |
| 开发 | 代码复审 | 30 |
| 开发 | 测试 | 60 |
| 报告 | 测试报告 | 30 |
| 报告 | 计算工作量 | 30 |
| 报告 | 事后总结 | 30 |
| 总计 | 600 |
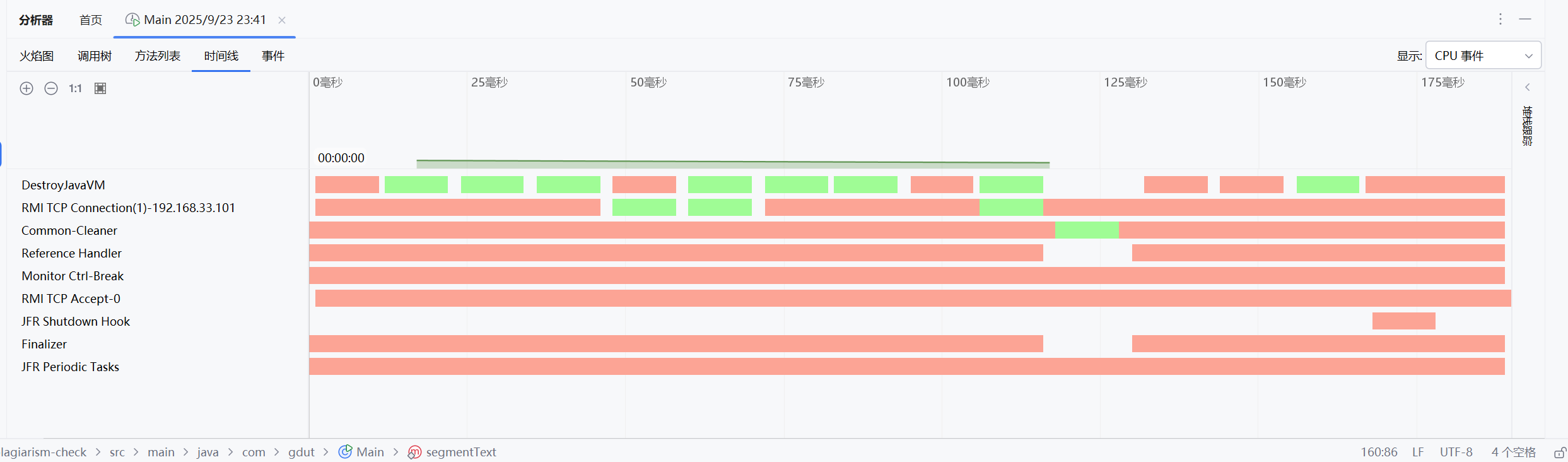
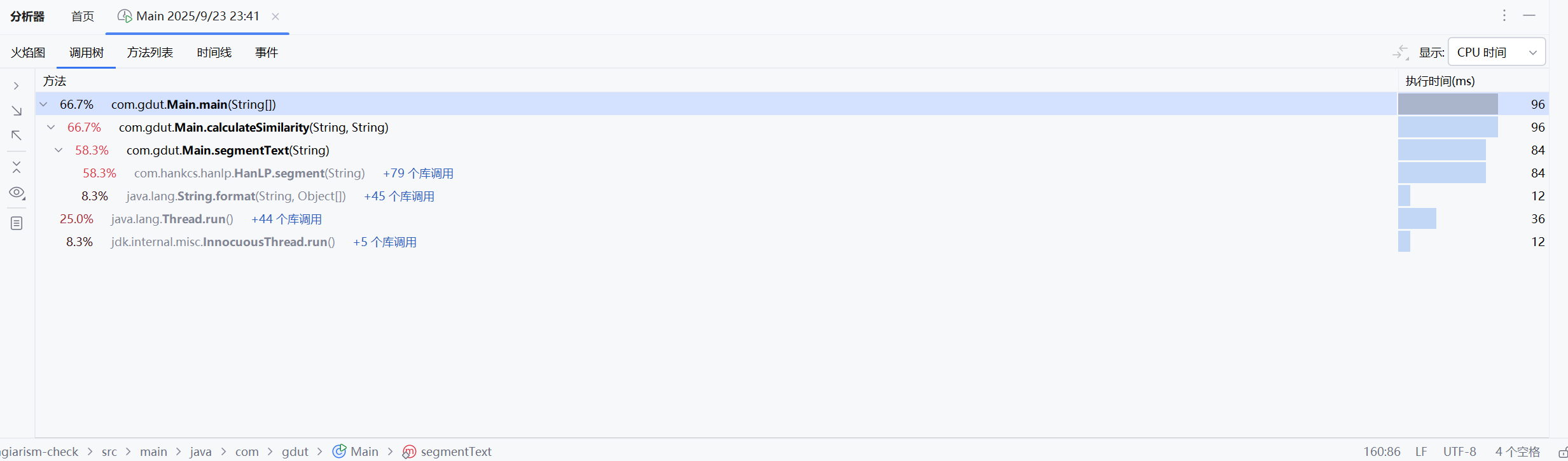
计算模块设计与实现
代码组织
- 类结构:
Main类:主类,包含程序入口(main方法)和核心逻辑。Logger内部类:用于打印日志,记录文件读取、分词、TF-IDF 和相似度计算过程。
- 主要函数:
main(String[] args):处理命令行参数,读取文件,调用相似度计算,写入结果。readFile(String path):读取文件内容为字符串。calculateSimilarity(String text1, String text2):计算两文本的相似度。segmentText(String text):使用 HanLP 分词,过滤标点。calculateTfIdf(List<String> docWords, List<List<String>> allDocs):计算 TF-IDF 值。cosineSimilarity(double[] vec1, double[] vec2):计算余弦相似度。writeResult(String path, double similarity):将相似度写入文件。
- 关系:
main调用readFile获取文本,调用calculateSimilarity计算相似度,最后通过writeResult输出。calculateSimilarity依赖segmentText进行分词,calculateTfIdf生成向量,cosineSimilarity计算相似度。Logger在每个步骤打印详细日志,便于调试。
算法关键
- 算法:使用 TF-IDF(词频-逆文档频率)结合余弦相似度计算文本相似度。
- 步骤:
- 分词:使用 HanLP 分词工具,将文本拆分为单词,过滤标点(正则表达式
[\\u4e00-\\u9fa5a-zA-Z0-9]+只保留中文、字母、数字)。 - TF-IDF 计算:
- TF(词频):单词在文档中的出现次数除以文档总词数。
- IDF(逆文档频率):
log((numDocs + 1) / (docCount + 1)),确保非负。 - TF-IDF = TF * IDF,为每个单词生成权重。
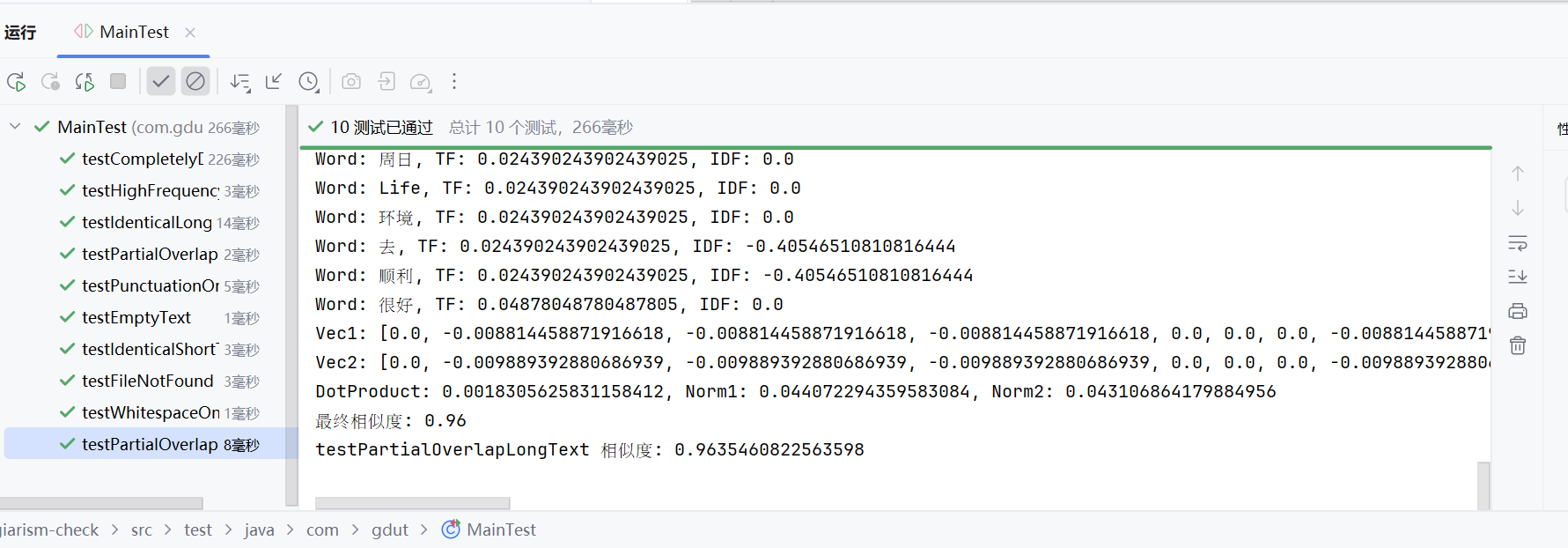
- 余弦相似度:将 TF-IDF 值转换为向量,计算点积除以模的乘积,得到相似度(0.0 到 1.0)。
- 独到之处:
- 标点过滤:通过正则表达式有效移除标点,避免干扰相似度计算。
- 缓存优化:在
calculateTfIdf中缓存文档单词集合(docWordSets),减少重复计算,提高性能。 - 详细日志:通过
Logger类记录每一步(文件读取、分词、TF-IDF、向量等),便于调试和验证。 - 异常处理:对空文件、分词后无有效单词等情况进行明确处理,确保程序鲁棒性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号