

CNN目标检测系列算法发展脉络——学习笔记(一):AlexNet
最近准备大致将CNN目标检测的发展脉络理一理(暂时只讲CNN系列部分,YOLO和SSD,后面会抽空整理)。
目标检测的发展大致起始于2000年前后(具体我也没去深究,如果有误还请大佬们指正 ●ˇ∀ˇ● ),早期受限于算力,大多使用的是机器学习/图像处理(边缘检测等)的方法,目标检测发展的不温不火,直到半导体技术的进步 & GPU加速技术的使用,以及Hinton团队的榜样作用,图像的目标检测开始有了爆发式的发展。
接下来的几篇博客会按照 AlexNet --> R-CNN -->FastRCNN -->FasterRCNN --> MaskRCNN 的顺序来整理,今天的内容是ALexNet,因为我的目的在于简析目标检测发展脉络,把握算法的改进路线,所以不会特别详细的讲解算法原理(好吧,我就是懒的写怎么滴~( ̄▽ ̄)~*),只挑与“改进/发展”相关的部分内容简析,以作为我对目标检测领域的综述性学习笔记。
AlexNet
AlexNet是基于有着十多年历史的LeNet,是在LeNet基础之上结合了许多技术和新的Trick实现的CNN网络模型。其在2012年一举夺得了ImageNet和ILSVRC竞赛双冠,并且在ILSVRC中的top-5测试的error rate为15.3%, 远远甩开第二名的26.2%(此处应有掌声,啪啪啪~(* ̄3 ̄)╭),如此压倒性优势的胜利给工业界带来了不小的冲击,同时也使得深度神经网络再次进入业界的视线。
因为本文是以综述为主,所以就不详细讲架构了,感兴趣的可以网上搜索一下,很多大佬们讲解的都很到位,这里主要提一下该模型的特点/改进。
子曾经曰过:“没图说个xx”。。。所以这里先上图,以下就是AlexNet的网络架构
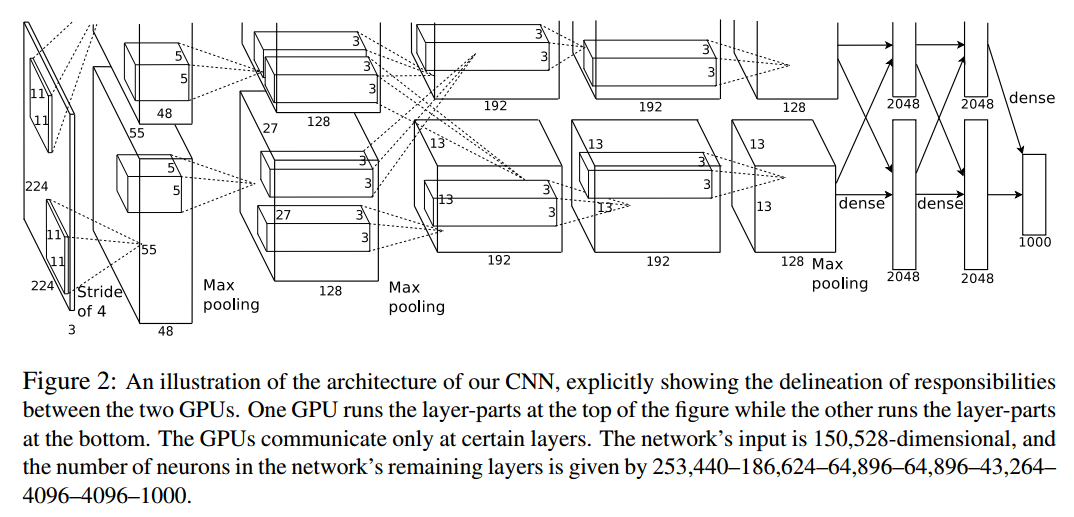
结合对论文的阅读,小弟总结了该模型的四个主要特点:
(一)该模型在全连接层使用了Dropout进行正则化
我在查资料时发现网上有人说Dropout是Hinton在2014年提出的理论,但实际上在2012年的AlexNet中就已经用到了该技术。
当时提出该方法的起因就在于,AlexNet在输出层使用了两个的Dense层,分析如下。
根据上面的模型图,第六层采用了(6*6*256)的Filter,在不考虑卷积和线性回归偏置值的情况下,最后两个Dense层的参数的数量 = 4096*4096+6*6*256*4096,大致为5400万个参数,而论文中提到过,整个模型的参数量在6000万作用,也就是说,最后两个Dense层的参数占整个模型参数量的90%以上,因此只要对这两层的参数量加以限制,就可以大大降低整个模型的复杂度,从而降低过拟合,同时也提高了训练速度。而Hinton对参数量的限制手段,就是Dropout,现如今,该方法也成为当前深度学习领域的常客。
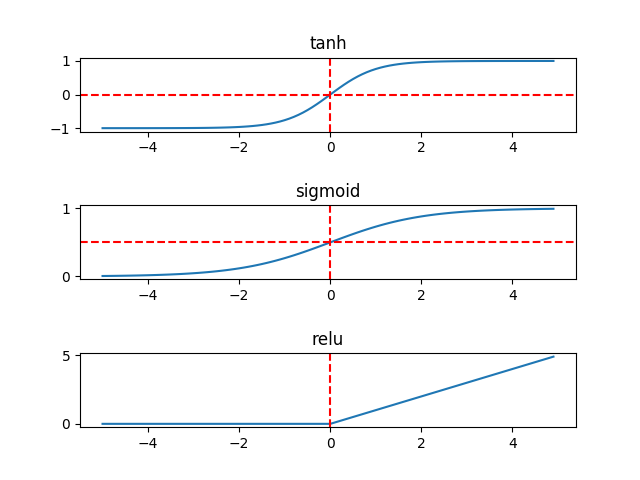
(二)使用ReLU作为激活函数
在Hinton之前,常用的激活函数是tanh或者sigmoid(如下图),但是二者在BP神经网络层数较深时,会产生梯度消失的现象,而使用ReLU则可以有效的避免此问题(实际上ReLU也有可能会出现梯度消失,但比较少见)。话说回来,ReLU还可以解决梯度爆炸问题,堪称激活函数中的完美女神有木有(咳咳,因为小弟是男生,所以ReLU是女神嘿嘿~)。
(三)局部响应归一化(LRN)
本来想好好夸一夸LRN,但是我在查阅了资料后发现这玩意儿的作用极其有限,很鸡肋,现在大家基本都用BN,但是原论文里面为LRN单独划出一节,强调了其可以降低错误率(莫非Hinton大佬为了水论文的字数???狗头保命🙃),所以这里稍微提一嘴,就不细说了。
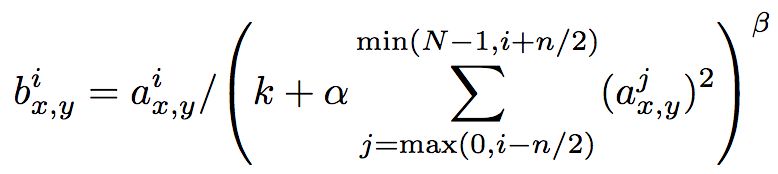
(四)重叠池化
相较于LeNet中的非重叠池化,AlexNet中使用了部分重叠的池化操作,在一定程度上降低了模型过拟合的可能。
对于重叠池化,我的理解是,重叠池化后的特征图的相邻元素之间具有一定的关联性,因为相邻元素之间的感受野有重叠,所以可以避免对某一特定区域的过拟合(小弟拙见,如果大佬们有更合适的解释,还请在评论里给出)。
当然,除了以上较为突破性的架构特点,AlexNet还使用了许多Tricks,例如创造性的使用了双GPU并行计算技术、使用数据增强技术扩充训练集等。虽然AlexNet的诸多架构和技巧上的亮点在当前工业界看来可能已经有些落后,但在当时产生了极大的轰动,可以说是21世纪深度学习热潮的导火索。

