
python网络爬虫—对b站相关视频的播放量和点赞量数据分析
Python网络爬虫—对B站相关视频的播放量和点赞量数据分析
一、选题背景
目的:探索视频点赞量和播放量的关系。
预期目标:通过获取大量相关数据,得到两者之间的简单线性关系,
描述:本项目基于网络爬虫,从国内大型网站B站获取视频的播放量和点赞量
二、主题式网络爬虫的设计方案
本课程设计设计的主要研究内容是设计并实现一个网站数据爬取与分析,把哗哩哗哩网站作为例子,由于海量的视频信息错综复杂,既存在一些有价值的视频,也存在一些无用的视频。为了高效自动化地区分视频的价值,并对海量视频的播放量和点赞量进行处理,分析,挖掘出数据背后隐藏的价值和规律。
1.名称:可根据用户提供的关键词获取B站相关视频的播放量和点赞量
2.爬取内容:B站相关视频的播放量和点赞量
3.设计方案概述:构建Bilibili类,包含了__init__()初始化方法:初始化了url,headers,Page(当前页数),max(设置的爬取的页数)等相关信息。get_first_url()方法,获取当前页面视频的url。write_data()方法,获取视频的播放量和点赞量,将数据写进json文件保存到本地。Run()方法,主要通过递归的方式实现翻页功能,让获取的信息更多。
三、页面的结构特征分析
1.主页面中,目的是找到各个视频的具体url,发现它保存在arcurl节点下,使用jsonpath语法可以直接获取,到了每个具体的视频,并发起请求。
2.html页面解析:都是标签的嵌套组成,有父节点和子节点,我们不需要从最高节点找起,只需要根据某个父节点的特殊属性进行定位即可。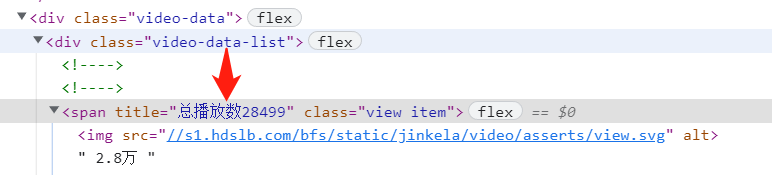

3.对于点赞数数目,直接定位到<span title="点赞(Q)">节点,再往下找到span节点,获取到点赞的文本信息。
4.对于播放数目,直接定位到<span “video-data-list”>,接着找到下一个span节点,获得标签的属性信息,就可获得播放的数目。
四、网络爬虫程序设计

1.获取数据并保存在本地,使用requests库获取信息,并解析获取的到本地,具体的功能注释具有标注。
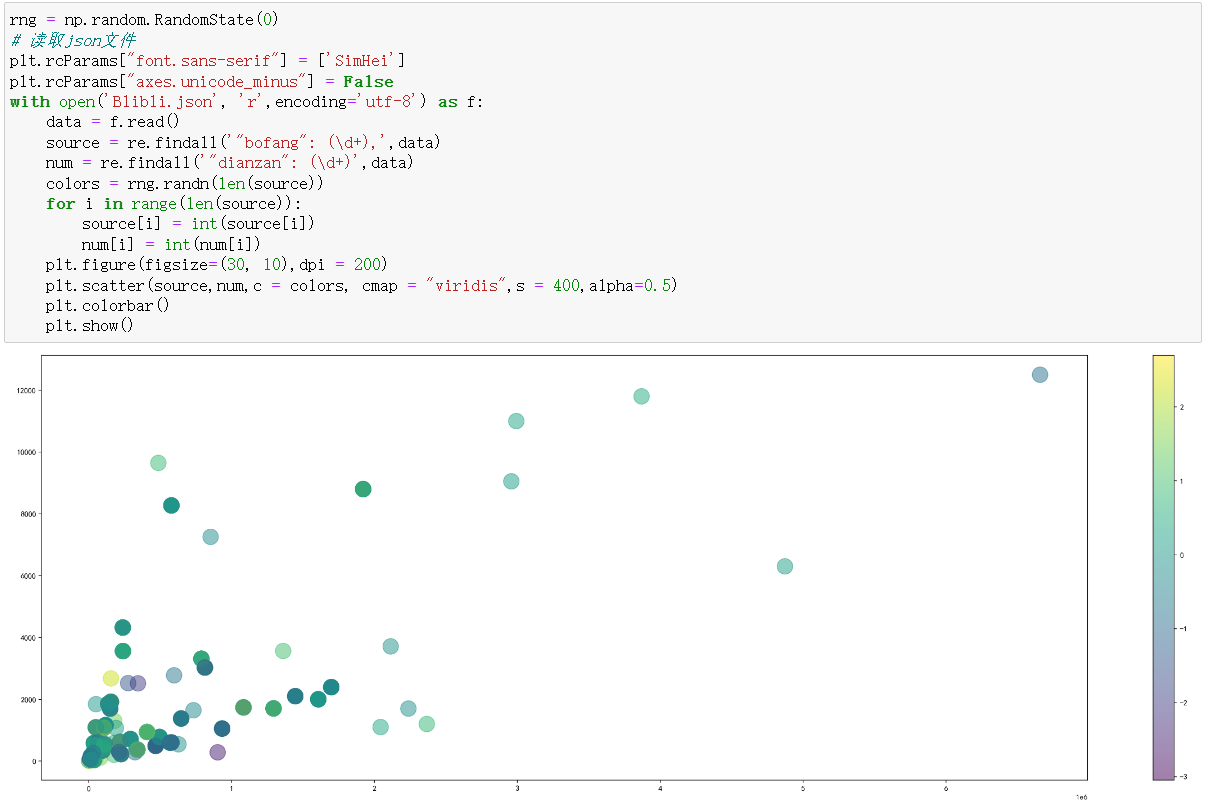
2.数据可视化,横轴为点赞数,纵轴为播放量,使用matplotlib做成散点图。
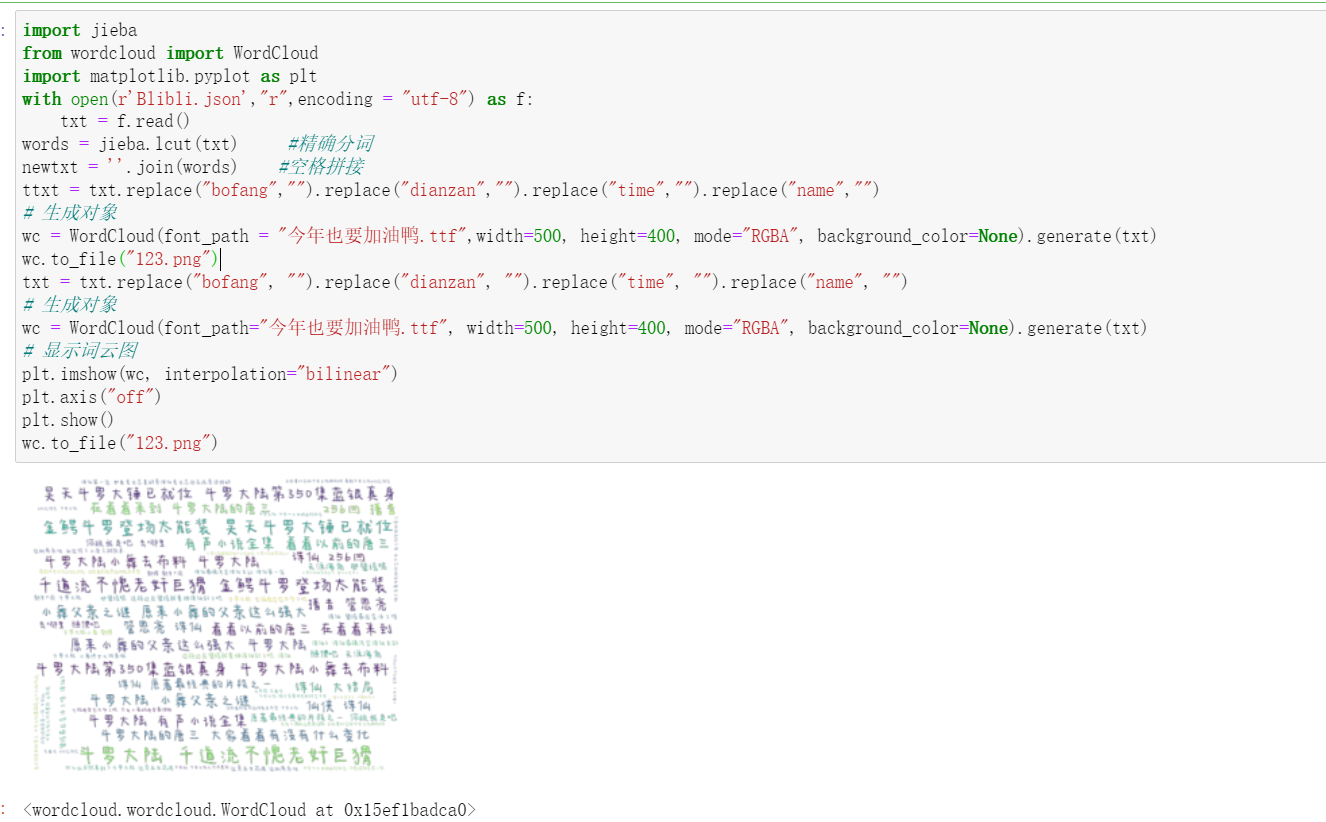
3.将json文件中的内容处理,使用jieba分词,并做成词云图
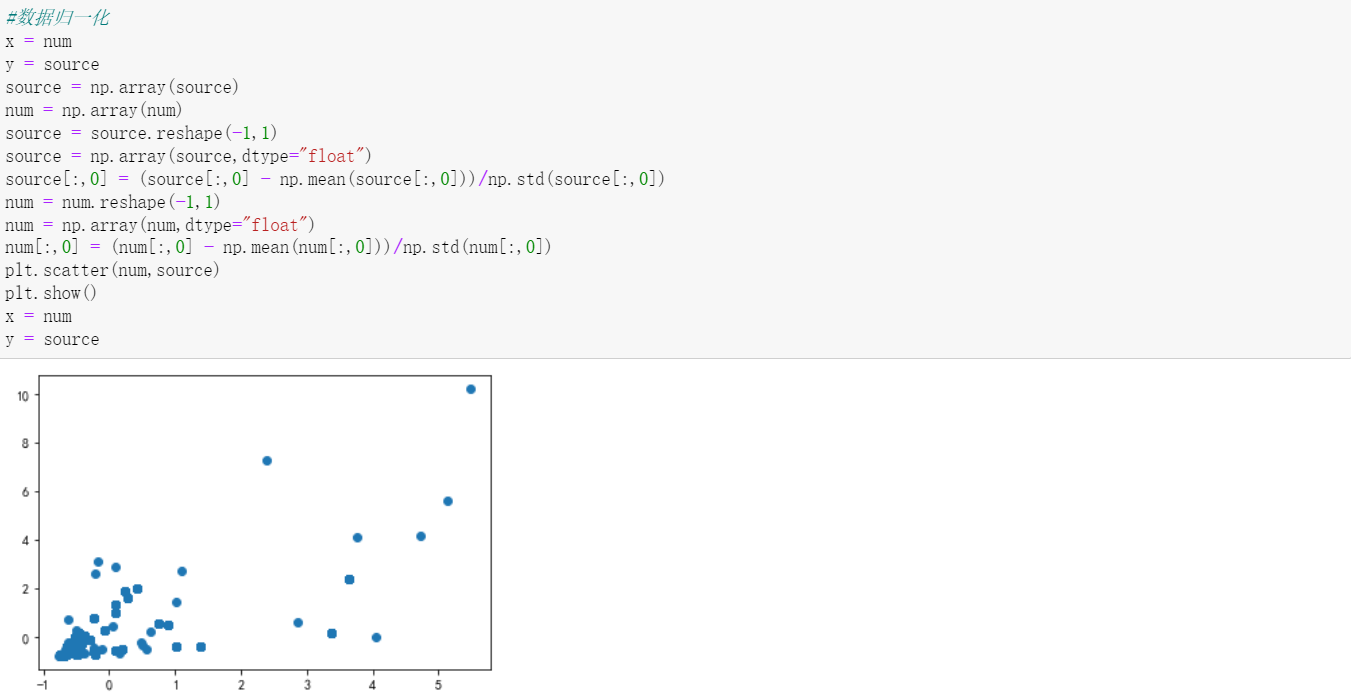
4.对数据进行均方差归一化,当数据集中不同特征项的范围相差较大时,必须要进行归一化处理,否则目标函数的图像会变“扁”,梯度下降时会走很多弯路,便于接下来进行线性回归,得到斜率和截距。
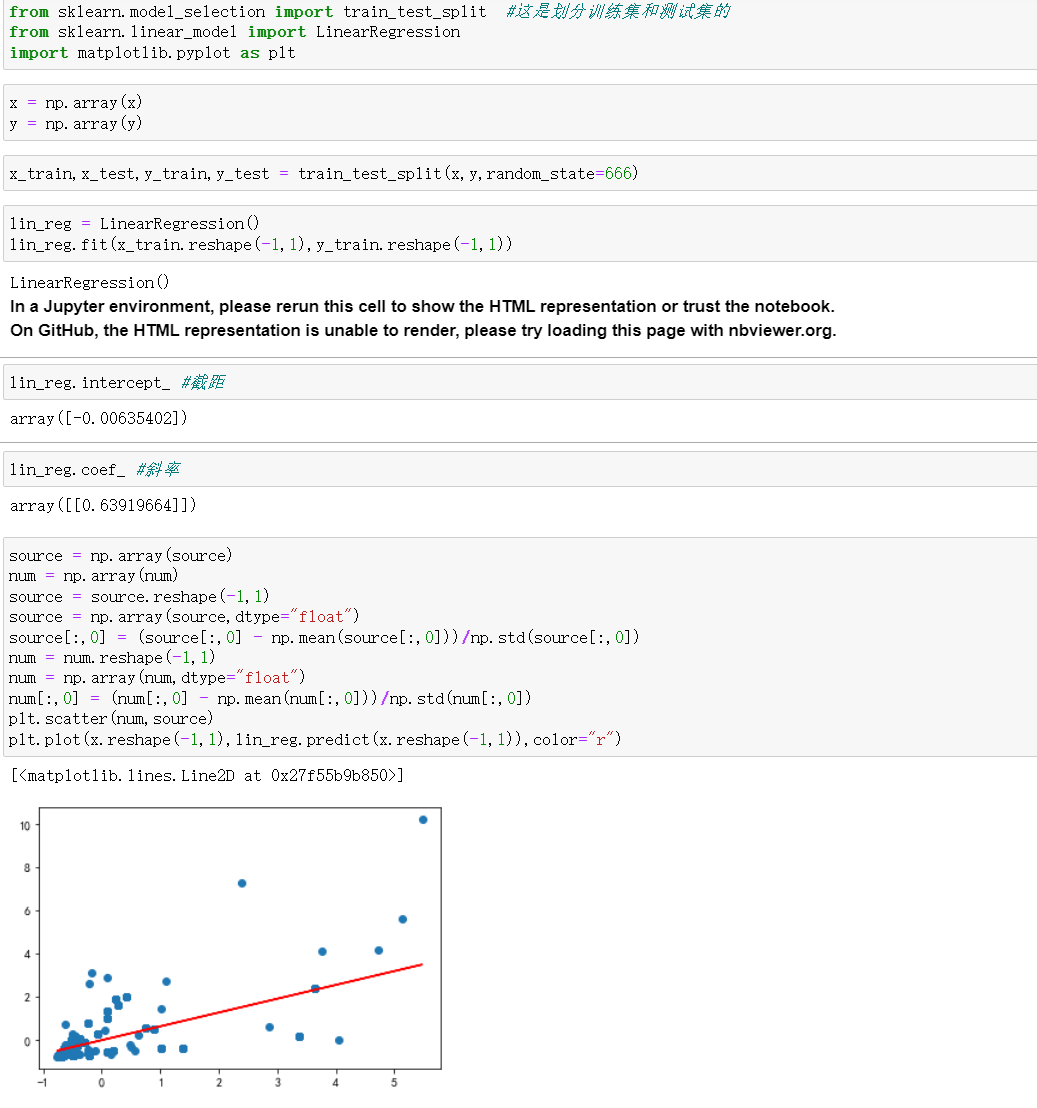
5.使用sklearn方法,将归一化的数据进行进一步分析,最终得到了二者之间的简单一元线性关系,并获得了斜率k = 0.64,截距b = 0.00635,最终将二者放在一个里面绘制,拟合效果基本符合预期。
6.分别对评论和名称进行词云图的可视化
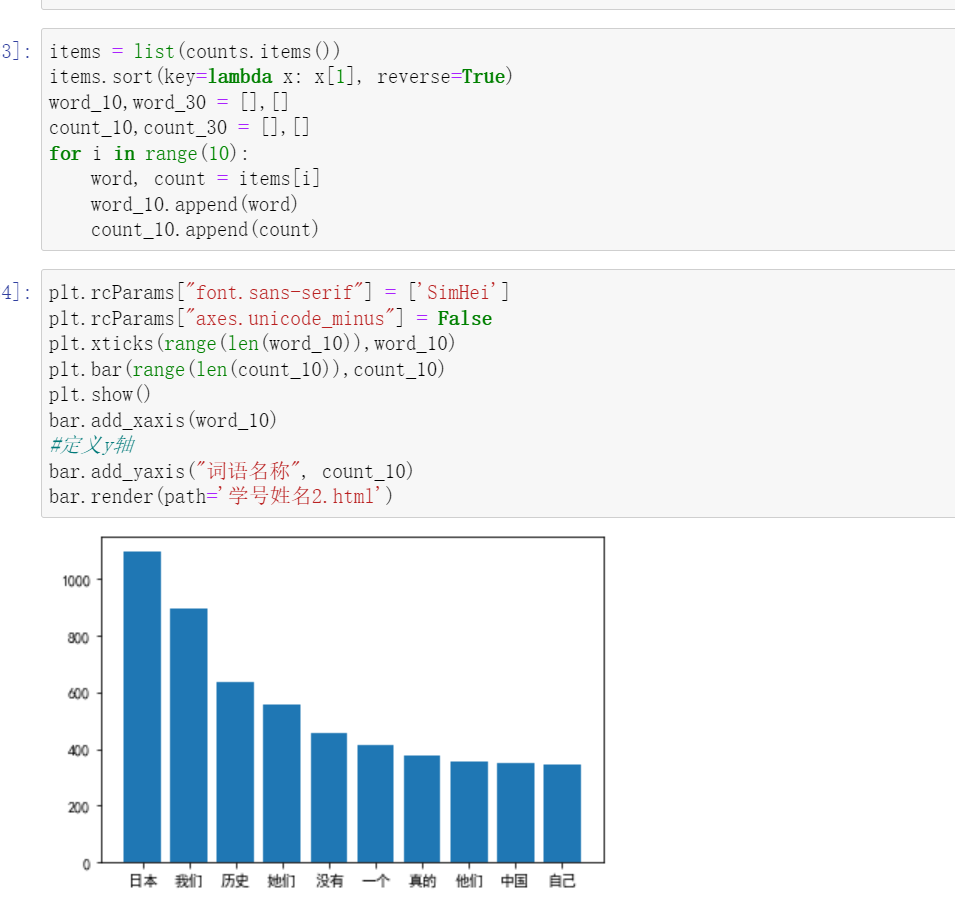
7.并对评论的词频前十进行柱状图的展示。
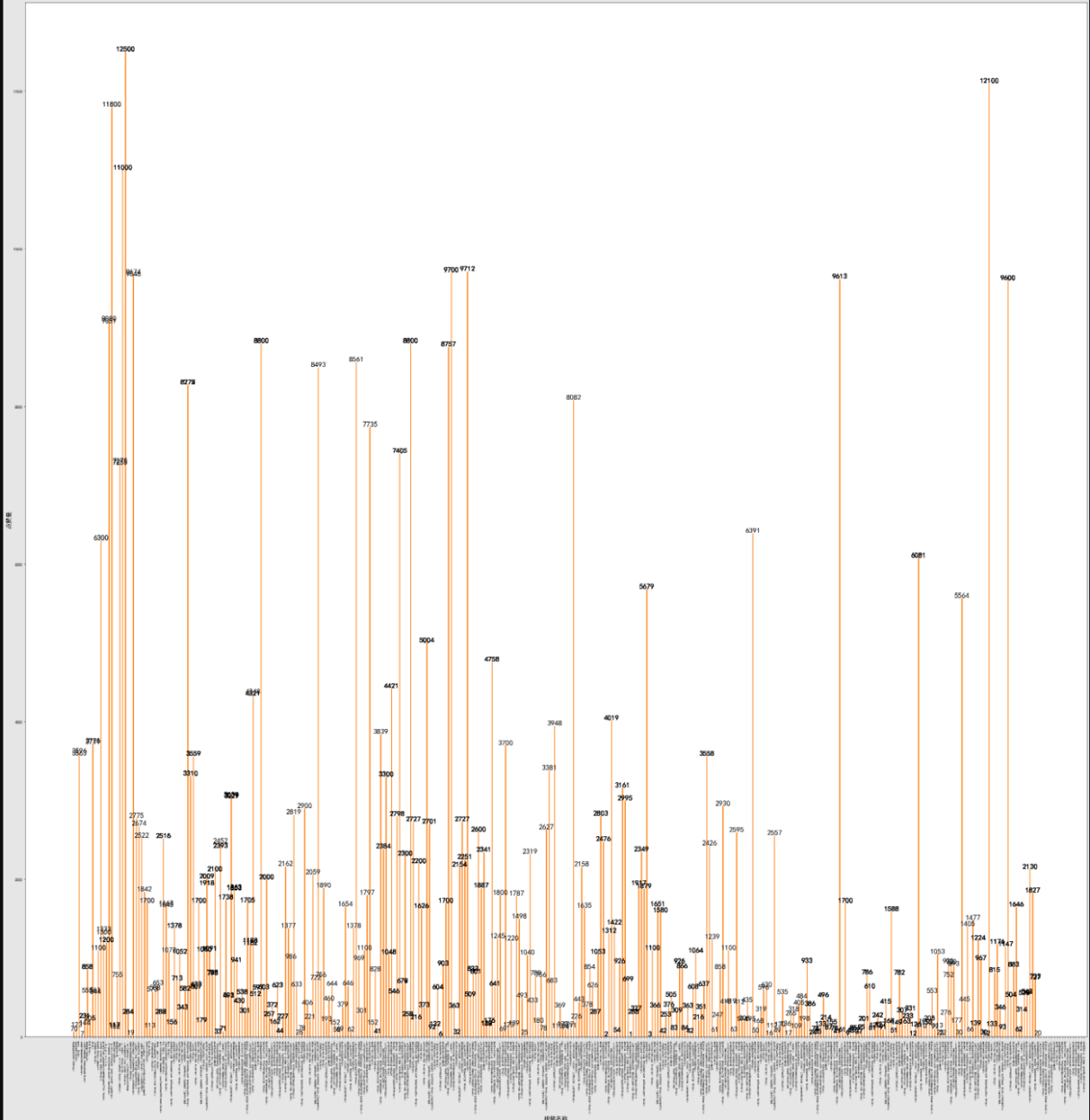
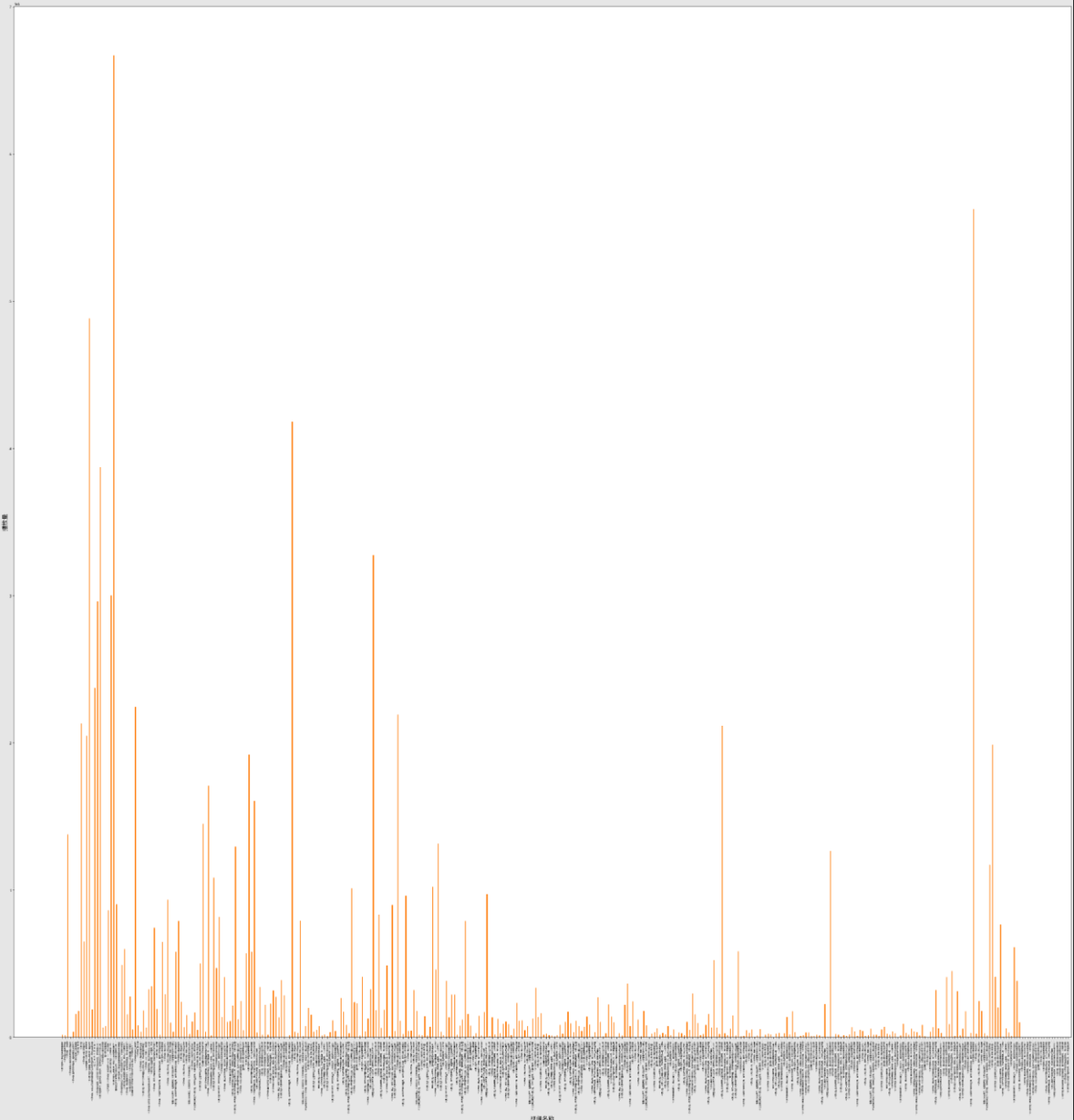
如图分别为,播放量和点赞量的柱状图示意图。
源码:
import requests, json
from jsonpath import jsonpath
from lxml import etree
import re
import matplotlib.pyplot as plt
import numpy as np
#构建Bilibili类
class Bilibili(object):
#初始化方法
def __init__(self, n, name):
#初始化url,其中控制page可以实现翻页
self.url = f"https://api.bilibili.com/x/web-interface/search/type?__refresh__=true&_extra=&context=&page=1&page_size=42&from_source=&from_spmid=333.337&platform=pc&highlight=1&single_column=0&keyword={name}&qv_id=Mzm4QviA2c0YJuRpMNd3sjAfv9ftVujq&category_id=&search_type=video&dynamic_offset=36&preload=true&com2co=true"
#初始化headers,包括了浏览器请求头,cookie,referer,可以实现简单的反爬
self.headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36",
"referer": f"https://search.bilibili.com/video?keyword=%E7%BE%8E%E5%A5%B3&from_source=webtop_search&spm_id_from=333.1007",
"cookie": "buvid3=7064307C-9CF6-82C1-034D-EB590CB30A5A46441infoc; i-wanna-go-back=-1; _uuid=5B17EDFE-648E-2877-F6F4-E8788AB43102747575infoc; buvid4=167B3873-FC8B-92B1-CF2B-F0FB1B9CE68647703-022050520-QvnVcBMEUB+AKoRH0XgeOalAaSF78eR1LZqHdZO2CsEcovaYvowCTA==; CURRENT_BLACKGAP=0; nostalgia_conf=-1; buvid_fp_plain=undefined; blackside_state=0; rpdid=0z9ZwfQnPW|PgJKIaeC|4aI|3w1NR7B7; LIVE_BUVID=AUTO3716534389974356; hit-dyn-v2=1; b_ut=5; fingerprint3=560e176ee8cbb0744ee7d459e275064a; PVID=1; b_nut=100; bp_video_offset_409770864=706477070439415800; fingerprint=af0a49dc8472197d56e7a8098f44addf; SESSDATA=bfd2f440,1678883794,99d57*91; bili_jct=2852b36404b946f84c1840d5685c8922; DedeUserID=1827433483; DedeUserID__ckMd5=6ef082dfef060715; buvid_fp=af0a49dc8472197d56e7a8098f44addf; CURRENT_QUALITY=0; bsource=search_baidu; sid=523496gl; innersign=1; CURRENT_FNVAL=4048; b_lsid=810E10543D_183D3C079A1; bp_video_offset_1827433483=716686246372442100"
}
#使用session进行请求
self.session = requests.session()
#当前页数
self.page = 1
#爬取页数
self.max = n
#获取self.url里面的各个视频的url信息
def get_first_url(self):
first_response_ = self.session.get(url=self.url, headers=self.headers)
#转化成json格式,使用jsonpath语法
first_response = first_response_.json()
#直接定位到arcul节点
url = jsonpath(first_response, "$..arcurl")
return url
#对每个视频都发送请求,得到数据
def write_data(self, url):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
'cookie': 'buvid3=7064307C-9CF6-82C1-034D-EB590CB30A5A46441infoc; i-wanna-go-back=-1; _uuid=5B17EDFE-648E-2877-F6F4-E8788AB43102747575infoc; buvid4=167B3873-FC8B-92B1-CF2B-F0FB1B9CE68647703-022050520-QvnVcBMEUB+AKoRH0XgeOalAaSF78eR1LZqHdZO2CsEcovaYvowCTA%3D%3D; CURRENT_BLACKGAP=0; nostalgia_conf=-1; buvid_fp_plain=undefined; blackside_state=0; rpdid=0z9ZwfQnPW|PgJKIaeC|4aI|3w1NR7B7; LIVE_BUVID=AUTO3716534389974356; hit-dyn-v2=1; b_ut=5; fingerprint3=560e176ee8cbb0744ee7d459e275064a; PVID=1; b_nut=100; bp_video_offset_409770864=706477070439415800; fingerprint=af0a49dc8472197d56e7a8098f44addf; SESSDATA=bfd2f440%2C1678883794%2C99d57%2A91; bili_jct=2852b36404b946f84c1840d5685c8922; DedeUserID=1827433483; DedeUserID__ckMd5=6ef082dfef060715; buvid_fp=af0a49dc8472197d56e7a8098f44addf; CURRENT_QUALITY=0; bp_video_offset_1827433483=716686246372442100; b_lsid=B7F3C9FA_183D44D7DCE; bsource=search_baidu; innersign=1; sid=5r3p0t5c; CURRENT_FNVAL=4048; theme_style=light',
":path":"/video/BV1H84y1r7Xg?spm_id_from=333.1007.tianma.1-1-1.click&vd_source=80cee37471056615c76954a3b425d26a"
}
response = requests.get(url=url, headers=headers)
#进行解码
response = response.content.decode()
# 转化成html可以解析的格式
html = etree.HTML(response)
#对数据进行解析,得到我们想要的数据
dian = html.xpath('//span[@title="点赞(Q)"]/span[@class="info-text"]/text()')
dianzan = []
#对数据进行清洗
for i in dian:
if "万" in i:
dianzan.append((float(i.replace("万","")))*1000)
else:
dianzan.append(int(i))
bo = html.xpath('//div[@class="video-data-list"]/span[1]/@title')
#播放总量
bofang = [int(i.replace('总播放数', "")) for i in bo]
##获取视频名称
name = html.xpath('//h1[@class="video-title tit"]/text()')
#获取评论
pinglun = html.xpath('//div[@class="root-reply"]/span/text()')
items = {}
#将数据保存到本地
with open("Blibli.json", "a+", encoding="utf-8") as f:
#使用zip函数
for i in zip(name, bofang, dianzan):
items["name"] = i[0]
items["bofang"] = i[1]
items["dianzan"] = i[2]
#转化成字符格式,这样才可以写入文件
data = json.dumps(items, ensure_ascii=False, indent=2)
f.write(data + "\n")
#保存进评论数据
with open("Blibli.txt","a+",encoding = "utf-8") as f:
f.write((str(pinglun)).replace("[","").replace("]",""))
#运行程序,并实现翻页功能
def run(self):
url_li = self.get_first_url()
for url in url_li:
self.write_data(url)
#page加一,然后翻页
self.page += 1
#打印获取到哪一页了
print(f"{self.page}获取完成")
if self.page < self.max:
#更改url信息,实现翻页功能
self.url = f"https://api.bilibili.com/x/web-interface/search/type?__refresh__=true&_extra=&context=&page={self.page}&page_size=42&from_source=&from_spmid=333.337&platform=pc&highlight=1&single_column=0&keyword={name}&qv_id=Mzm4QviA2c0YJuRpMNd3sjAfv9ftVujq&category_id=&search_type=video&dynamic_offset=36&preload=true&com2co=true"
#使用递归地方式
return self.run()
#主程序入口
if __name__ == '__main__':
name = input("请输入您要搜索的关键字:")
n = int(input("请输入你要的页数:"))
spider = Bilibili(n, name)
spider.run()
#随机种子,是每次的输出结果一样
rng = np.random.RandomState(0)
# 读取json文件,设置显示模式
#设置字体,可以显示中文
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams["axes.unicode_minus"] = False
with open('Blibli.json', 'r',encoding='utf-8') as f:
data = f.read()
#re模块,使用正则表达式,获取json文件里的信息
name = re.findall('"name": (.*?),', data)
bofang = re.findall('"bofang": (\d+),',data)
dianzan = re.findall('"dianzan": (\d+)',data)
colors = rng.randn(len(dianzan))
for i in range(len(bofang)):
#转换成int格式
bofang[i] = int(bofang[i])
dianzan[i] = int(dianzan[i])
plt.figure(figsize=(30, 10),dpi = 200)
plt.scatter(bofang,dianzan,c = colors, cmap = "viridis",s = 400,alpha=0.5)
plt.colorbar()
plt.show()
plt.figure(figsize=(50, 50))
plt.bar(name, dianzan, width=0.35)
plt.ylabel("点赞量")
plt.xlabel("视频名称",fontsize=70)
axes = plt.gca()
axes.xaxis.label.set_size(16)
axes.yaxis.label.set_size(16)
# 这里是调节横坐标的倾斜度,rotation是度数
plt.xticks(range(len(name)),name,rotation=90,fontsize=5)
# 显示柱坐标上边的数字
for a, b in zip(name, dianzan):
# fontsize表示柱坐标上显示字体的大小
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=20)
plt.bar(name,height = dianzan, width=0.35)
plt.show()
plt.figure(figsize=(50, 50))
plt.bar(name, bofang, width=0.35)
plt.ylabel("播放量")
plt.xlabel("视频名称",fontsize=70)
axes = plt.gca()
axes.xaxis.label.set_size(16)
axes.yaxis.label.set_size(16)
# 这里是调节横坐标的倾斜度,rotation是度数
plt.xticks(range(len(name)),name,rotation=90,fontsize=5)
plt.bar(name,height = bofang, width=0.35)
plt.show()
#数据归一化
x = dianzan
y = bofang
x1 = dianzan
y1 = bofang
source = np.array(dianzan)
num = np.array(bofang)
source = source.reshape(-1,1)
source = np.array(source,dtype="float")
#均值方差归一化
source[:,0] = (source[:,0] - np.mean(source[:,0]))/np.std(source[:,0])
num = num.reshape(-1,1)
num = np.array(num,dtype="float")
num[:,0] = (num[:,0] - np.mean(num[:,0]))/np.std(num[:,0])
plt.scatter(num,source)
plt.show()
# 这是划分训练集和测试集的
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
x = np.array(x)
y = np.array(y)
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=666)
lin_reg = LinearRegression()
lin_reg.fit(x_train.reshape(-1,1),y_train.reshape(-1,1))
lin_reg.intercept_ #截距
lin_reg.coef_ #斜率
source = np.array(dianzan)
num = np.array(bofang)
source = source.reshape(-1,1)
source = np.array(source,dtype="float")
source[:,0] = (source[:,0] - np.mean(source[:,0]))/np.std(source[:,0])
num = num.reshape(-1,1)
num = np.array(num,dtype="float")
num[:,0] = (num[:,0] - np.mean(num[:,0]))/np.std(num[:,0])
plt.scatter(num,source)
plt.plot(x.reshape(-1,1),lin_reg.predict(x.reshape(-1,1)),color="r")
plt.show()
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
with open(r'Blibli.json',"r",encoding = "utf-8") as f:
txt = f.read()
#精确分词
words = jieba.lcut(txt)
#空格拼接
newtxt = ''.join(words)
ttxt = txt.replace("bofang","").replace("dianzan","").replace("time","").replace("name","")
# 生成对象
wc = WordCloud(font_path = "今年也要加油鸭.ttf",width=500, height=400, mode="RGBA", background_color=None).generate(txt)
wc.to_file("123.png")
txt = txt.replace("bofang", "").replace("dianzan", "").replace("time", "").replace("name", "")
# 生成对象
wc = WordCloud(font_path="今年也要加油鸭.ttf", width=500, height=400, mode="RGBA", background_color=None).generate(txt)
# 显示词云图
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show()
wc.to_file("123.png")
with open(r'Blibli.txt',"r",encoding = "utf-8") as f:
txt = f.read()
words = jieba.lcut(txt)
newtxt = ''.join(words)
# 生成对象
wc =WordCloud(font_path = r"C:\Users\86188\Desktop\今年也要加油鸭 - 100font.com\今年也要加油鸭.ttf",width=500, height=400, mode="RGBA", background_color=None).generate(txt)
# 显示词云图
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
wc.to_file("456.png")
import jieba
file = open("Blibli.json", "r", encoding='utf-8')
txt = file.read()
words = jieba.lcut(txt)
count = {}
# 使用 for 循环遍历每个词语并统计个数
for word in words:
# 排除单个字的干扰,使得输出结果为词语
if len(word) < 1:
continue
else:
# 如果字典里键为 word 的值存在,则返回键的值并加一,如果不存在键word,则返回0再加上1
count[word] = count.get(word, 0) + 1
count
list_ip = []
for i in range(len(count)):
list_ip = list(count.keys())
list_ip
exclude = ["dianzan", ":", "bofang","{","}",",","\n"," ","name",","] # 建立无关词语列表
# 遍历字典的所有键,即所有word
for key in list(count.keys()):
if key in exclude:
# 删除字典中键为无关词语的键值对
del count[key]
# 将字典的所有键值对转化为列表
list_ = list(count.items())
# 对列表按照词频从大到小的顺序排序
list_.sort(key=lambda x: x[1], reverse=True)
# 此处统计排名前五的单词,所以range(5)
for i in range(5):
word, number = list_[i]
print("关键字:{:-<10}频次:{:+>8}".format(word, number))
from pyecharts.charts import Bar
bar = Bar()
txt = open("Blibli.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
counts.items()
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
word_10= []
count_10 = []
for i in range(10):
word, count = items[i]
word_10.append(word)
count_10.append(count)
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams["axes.unicode_minus"] = False
plt.xticks(range(len(word_10)),word_10)
plt.bar(range(len(count_10)),count_10)
plt.show()
bar.add_xaxis(word_10)
#定义y轴
bar.add_yaxis("词语名称", count_10)
#保存成html格式,可以在网页中看
bar.render(path='学号姓名2.html')
五总结
1.从图像可以看出二者之间具有基本的一元线性关系,基本达到了预期的目标。
收获:熟悉并熟练掌握了网络爬虫的用法,以及如何对复杂网页进行html解析,获取自己想要的数据,还有基本简单的数据可视化,利用sklearn实现一元线性回归,非常方便。
2.需要改进的地方:对噪音点的处理可能不够好,如图这几个点就是明显的噪音点,如何正确处理噪音点,可以做的更加好,得到的模型效果可能更好。


