

读书报告
1、Numpy
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
- 一个强大的N维数组对象 ndarray。
- 广播功能函数。
- 整合 C/C++/Fortran 代码的工具。
- 线性代数、傅里叶变换、随机数生成等功能。
Numpy的安装
-
使用已有的发行版本
-
使用 pip 安装
Numpy基本函数
.ndim :维度
.shape :各维度的尺度 (2,5)
.size :元素的个数 10
.dtype :元素的类型 dtype(‘int32’)
.itemsize :每个元素的大小,以字节为单位 ,每个元素占4个字节
ndarray数组的创建
np.arange(n) ; 元素从0到n-1的ndarray类型
np.ones(shape): 生成全1
np.zeros((shape), ddtype = np.int32) : 生成int32型的全0
np.full(shape, val): 生成全为val
np.eye(n) : 生成单位矩阵
np.ones_like(a) : 按数组a的形状生成全1的数组
np.zeros_like(a): 同理
np.full_like (a, val) : 同理
np.linspace(1,10,4): 根据起止数据等间距地生成数组
np.linspace(1,10,4, endpoint = False):endpoint 表示10是否作为生成的元素
np.concatenate():
numpy.empty
numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
numpy.empty(shape, dtype = float, order = 'C')
实例:
|
1
2
3
|
import numpy as npx = np.empty([3,2], dtype = int)print (x) |
numpy.asarray
numpy.asarray 类似 numpy.array,但 numpy.asarray 参数只有三个,比 numpy.array 少两个。
实例:
|
1
2
3
4
|
import numpy as np x = [1,2,3]a = np.asarray(x, dtype = float) print (a) |
NumPy 从数值范围创建数组
numpy.arange
numpy 包中的使用 arange 函数创建数值范围并返回 ndarray 对象,函数格式如下:
numpy.arange(start, stop, step, dtype)
NumPy 切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
NumPy 统计函数
NumPy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等。 函数说明如下:
numpy.amin() 用于计算数组中的元素沿指定轴的最小值。
numpy.amax() 用于计算数组中的元素沿指定轴的最大值。
numpy.ptp()函数计算数组中元素最大值与最小值的差(最大值 - 最小值)。
numpy.median() 函数用于计算数组 a 中元素的中位数(中值)
numpy.mean() 函数返回数组中元素的算术平均值。
numpy.average() 函数根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值。
Numpy矩阵库
|
1
2
3
4
5
6
7
8
9
10
|
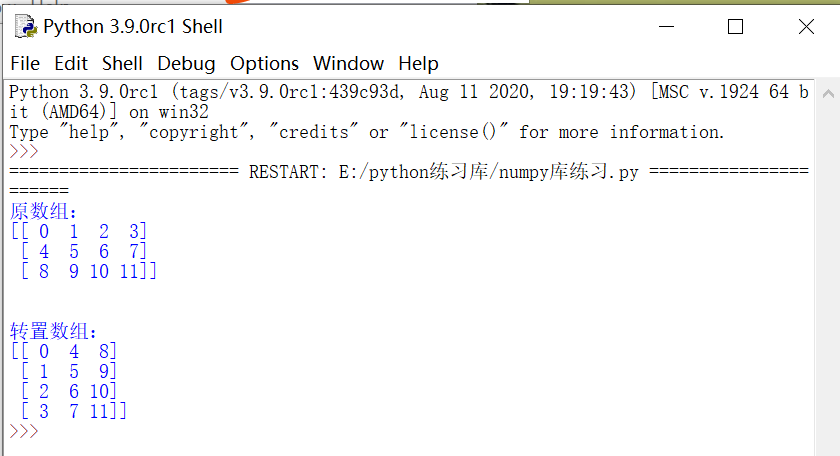
import numpy as np a = np.arange(12).reshape(3,4) print ('原数组:')print (a)print ('\n') print ('转置数组:')print (a.T) |
输出结果:
2、scipy
SciPy是一个用于数学、科学、工程领域的常见软件包,可以处理插值、积分、优化、图像处理、常微分方程数值解的求解,信号处理等问题,它用于有效计算Numpy矩阵,使Numpy和SciPy协同工作,高效解决问题。
SciPy常见的函数:
实例分析:
|
1
2
3
|
from scipy import integratex2=lambda x:x**2integrate.quad(x2,0,4) |
结果:

3、pandas
pandas是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
数据对象的创建
实例分析:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
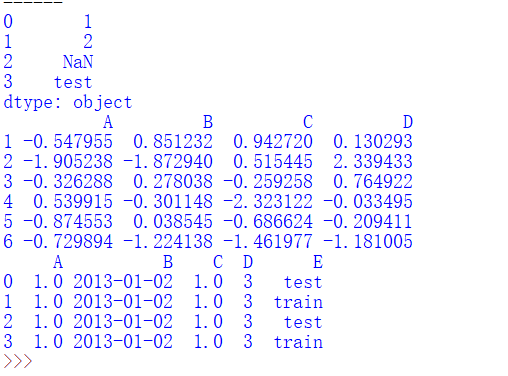
import pandas as pdimport numpy as np # 通过一维数组初始化Seriess = pd.Series([1, 2.0, np.nan, 'test'])print(s) # 通过二维数组初始化DataFramearr = np.random.randn(6, 4)arr_df = pd.DataFrame(arr, index=np.arange(1, 7), columns=list('ABCD'))print(arr_df)# 通过字典dict初始化DataFramedic = {'A': 1., 'B': pd.Timestamp('20130102'), 'C': pd.Series(1, index=list(range(4)), dtype='float32'), 'D': np.array([3] * 4, dtype='int32'), 'E': pd.Categorical(["test", "train", "test", "train"]) }dic_df = pd.DataFrame(dic)print(dic_df) |
- Pandas数据类型操作
重新索引
reindex(index=None, columns=None,…)方法 可改变或重排Series和DataFrame索引
reindex(index=None, columns=None,…)
index, colums 新的行列自定义索引
fill_value 在重新索引,用于填充缺失位置的值
method 填充方法,ffill当前值向前填充, bfill向后填充
limit 最大填充量
copy 默认为True,生成新的对象,False时,新旧相等,但不复制
d.reindex(index = [‘d’, ‘c’, ‘b’, ‘a’ ])
d.reindex(colums = [‘two’, ‘one’])

newc = d.colums.insert( 4, ‘新增’) newc为一个colums

 浙公网安备 33010602011771号
浙公网安备 33010602011771号