
Flink| 概述| 配置安装
1. 流处理技术的演变
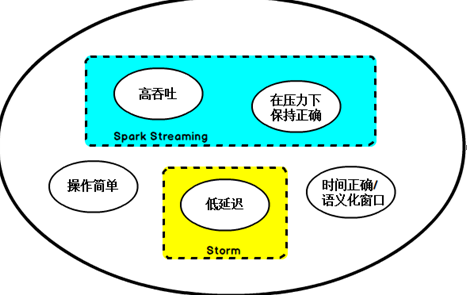
在开源世界里,Apache Storm项目是流处理的先锋。Storm提供了低延迟的流处理,但是它为实时性付出了一些代价:很难实现高吞吐,并且其正确性没能达到通常所需的水平,换句话说,它并不能保证exactly-once,即便是它能够保证的正确性级别,其开销也相当大。
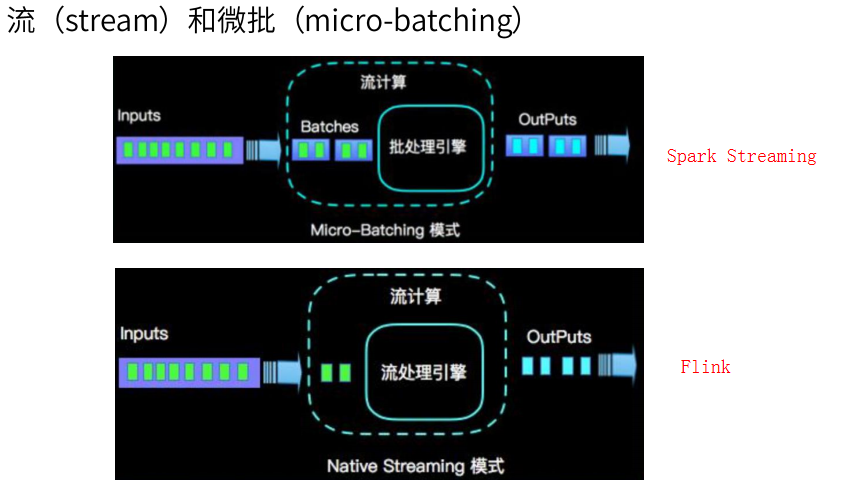
在低延迟和高吞吐的流处理系统中维持良好的容错性是非常困难的,但是为了得到有保障的准确状态,人们想到了一种替代方法:将连续时间中的流数据分割成一系列微小的批量作业。如果分割得足够小(即所谓的微批处理作业),计算就几乎可以实现真正的流处理。因为存在延迟,所以不可能做到完全实时,但是每个简单的应用程序都可以实现仅有几秒甚至几亚秒的延迟。这就是在Spark批处理引擎上运行的Spark Streaming所使用的方法。
更重要的是,使用微批处理方法,可以实现exactly-once语义,从而保障状态的一致性。如果一个微批处理失败了,它可以重新运行,这比连续的流处理方法更容易。Storm Trident是对Storm的延伸,它的底层流处理引擎就是基于微批处理方法来进行计算的,从而实现了exactly-once语义,但是在延迟性方面付出了很大的代价。
对于Storm Trident以及Spark Streaming等微批处理策略,只能根据批量作业时间的倍数进行分割,无法根据实际情况分割事件数据,并且,对于一些对延迟比较敏感的作业,往往需要开发者在写业务代码时花费大量精力来提升性能。这些灵活性和表现力方面的缺陷,使得这些微批处理策略开发速度变慢,运维成本变高。
于是,Flink出现了,这一技术框架可以避免上述弊端,并且拥有所需的诸多功能,还能按照连续事件高效地处理数据,Flink的部分特性如下图所示:
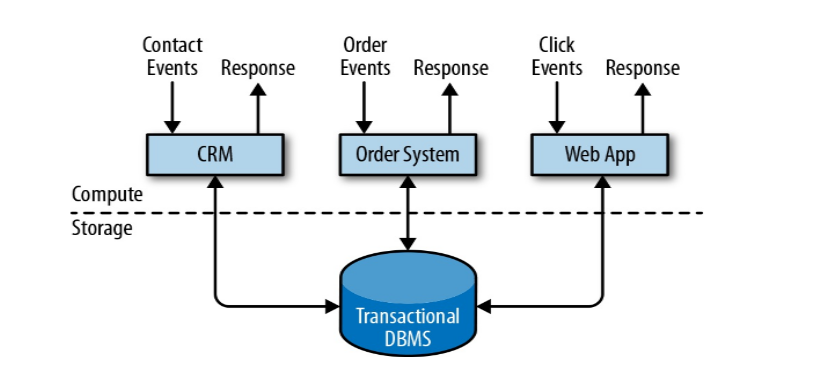
① 事务处理
数据计算和数据存储分开,CRM客户资源管理系统、订单系统、应用后台,用户会发各种事件请求,所有用户发过来的都是一个事件events,进行处理从关系型数据库中查询进行返回Response;特点实时性很好,来一个事件处理一个事件,额外数据存储在关系型数据库中;最大问题是能够同时处理的数据有限,数据库做连表查询的代价很高。
② 分析处理
将数据从业务数据库复制到数仓,再进行分析和查询。
业务数据先放关系型数据库中,需要做计算分析时先进行ETL后导入到数仓中,用数据分析计算引擎做查询,出报表、做机器学习。
特点:在mysql中不用做连表查询,将海量数据分层放到一起统一进行计算;但是慢,延迟比较高。

③ 有状态的流式处理
流数据应用于
- 电商和市场营销: 数据报表、广告投放、业务流程需要
- 物联网(IOT):传感器实时数据采集和显示、实时报警,交通运输业
- 电信业:基站流量调配
- 银行和金融业:实时结算和通知推送,实时检测异常行为
流处理
保持之前事务处理的原则,来一个处理一个,它的瓶颈在于关系型数据库做连表查询比较麻烦;把数据不放到关系型数据库中,直接放到本地内存中,存成本地状态,数据来一条结合本地状态进行判断计算,然后输出,状态有更改更新即可。 用本地内存状态代替关系型数据库。这就是有状态数据流。
高并发的扩展,集群,不同集群不同节点分配内存,各自按本地状态进行计算,最后汇总。
放内存不安全,存盘、故障恢复的机制(周期性检查点checkpoint,存储在一个远程化存储文件)。
达到了低延迟、高吞吐、良好容错故障恢复,但是一个严重问题:分布式架构下数据的顺序性如何保证,经过不同分区进行处理后,之后就可能乱序。
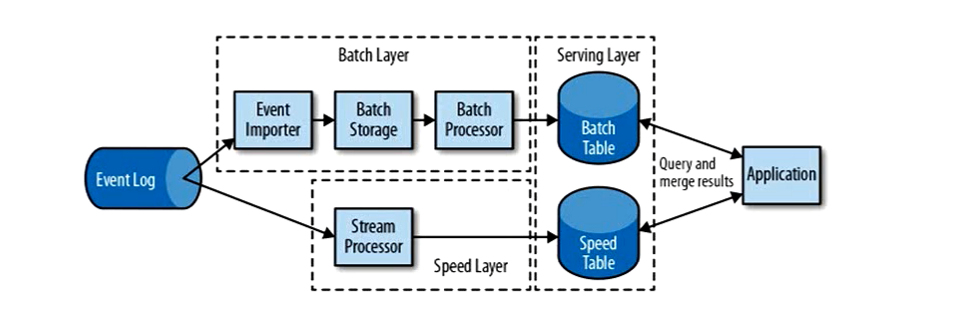
lambda 架构
用两套系统,同时保证低延迟和结果准确。
同时使用了批处理和流处理,流处理Stream Processor进行快速处理之后存到一个Speed Table中,批处理Btach Layer处理完之后存到一个Batch Table中,
最后Speed Table和Batch Table结合返回给应用程序。缺点:代价比较高,同时维护两套系统。
Storm| Spark| Flink
① Storm
其实大数据实时处理的需求早已有之,最早的时候,我们用消息队列实现大数据实时处理,如果处理起来比较复杂,那么就需要很多个消息队列,将实现不同业务逻辑的生产者和消费
者串起来。这个处理过程类似下面图里的样子。
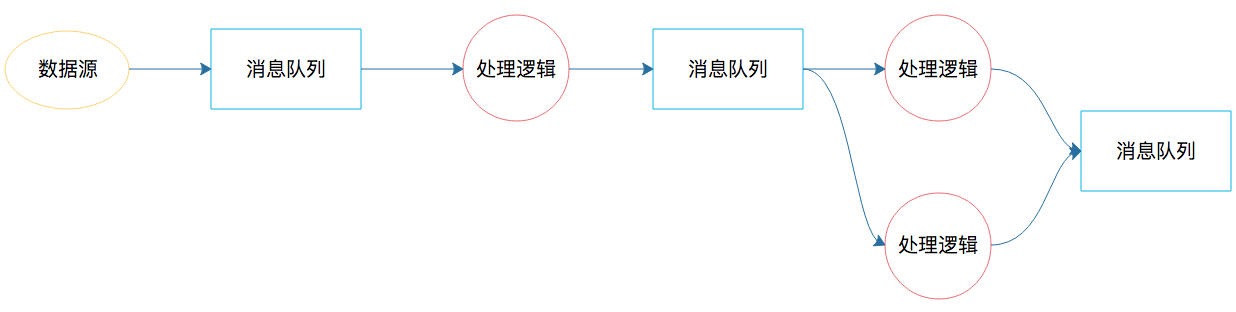
图中的消息队列负责完成数据的流转;处理逻辑既是消费者也是生产者,也就是既消费前面消息队列的数据,也为下个消息队列产生数据。这样的系统只能是根据不同需求开发出来,
并且每次新的需求都需要重新开发类似的系统。因为不同应用的生产者、消费者的处理逻辑不同,所以处理流程也不同,因此这个系统也就无法复用。
之后我们很自然地就会想到,能不能开发一个流处理计算系统,我们只要定义好处理流程和每一个节点的处理逻辑,代码部署到流处理系统后,就能按照预定义的处理流程和处理逻辑
执行呢?Storm 就是在这种背景下产生的,它也算是一个比较早期的大数据流计算框架。上面的例子如果用 Storm 来实现,过程就变得简单一些了。
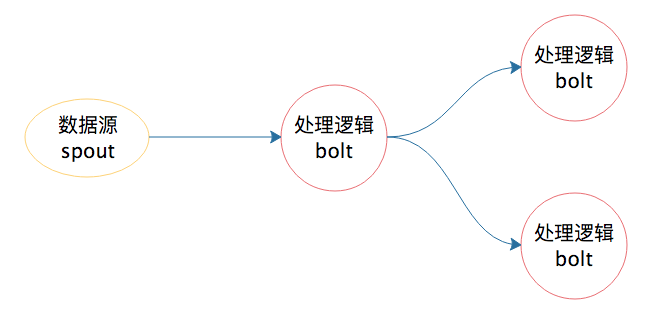
有了 Storm 后,开发者无需再关注数据的流转、消息的处理和消费,只要编程开发好数据处理的逻辑 bolt 和数据源的逻辑 spout,以及它们之间的拓扑逻辑关系 toplogy,提交到
Storm 上运行就可以了。
在了解了Storm 的运行机制后,我们来看一下它的架构。Storm跟Hadoop 一样,也是主从架构。
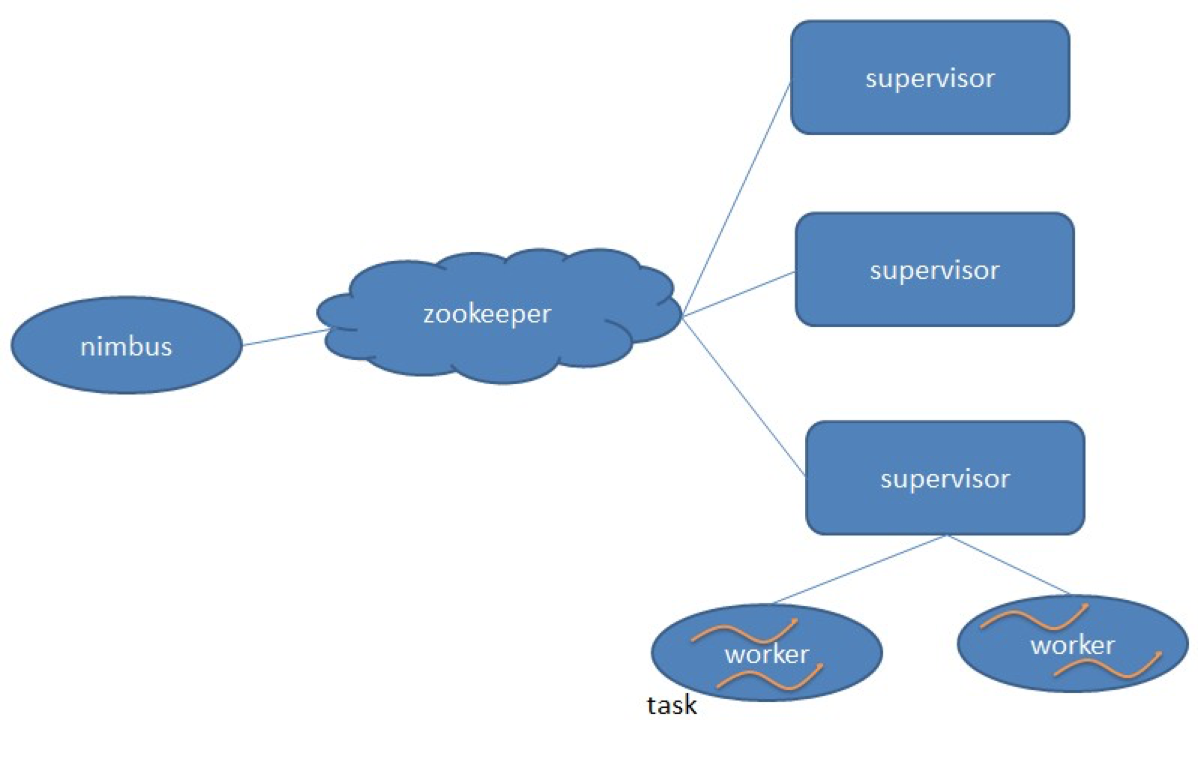
nimbus 是集群的 Master,负责集群管理、任务分配等。
supervisor是 Slave,是真正完成计算的地方,每个supervisor 启动多个worker 进程,每个 worker上运行多个 task,而task 就是 spout 或者 bolt。supervisor 和 nimbus通过
ZooKeeper 完成任务分配、心跳检测等操作。
Hadoop、Storm的设计理念,其实是一样的,就是把和具体业务逻辑无关的东西抽离出来,形成一个框架,比如大数据的分片处理、数据的流转、任务的部署与执行等,开发者只需
要按照框架的约束,开发业务逻辑代码,提交给框架执行就可以了。
而这也正是所有框架的开发理念,就是将业务逻辑和处理过程分离开来,使开发者只需关注业务开发即可,比如Java 开发者都很熟悉的 Tomcat、Spring 等框架,全部都是基于这种
理念开发出来的。
Spark Streaming
Spark 是一个批处理大数据计算引擎,主要针对大批量历史数据进行计算。Spark 是一个快速计算的大数据引擎,它将原始数据分片后装载到集群中计算,对于数据量不是很大、过程
不是很复杂的计算,可以在秒级甚至毫秒级完成处理。
Spark Streaming 巧妙地利用了 Spark 的分片和快速计算的特性,将实时传输进来的数据按照时间进行分段,把一段时间传输进来的数据合并在一起,当作一批数据,再去交给 Spark
去处理。下图这张图描述了 Spark Streaming 将数据分段、分批的过程。

如果时间段分得足够小,每一段的数据量就会比较小,再加上Spark引擎的处理速度又足够快,这样看起来好像数据是被实时处理的一样,这就是Spark Streaming实时流计算的奥妙。
这里要注意的是,在初始化 Spark Streaming实例时,需要指定分段的时间间隔。下面代码示例中间隔是 1 秒。
val ssc = new StreamingContext( conf, Seconds(1) )
也可以指定更小的时间间隔,比如 500ms,这样处理的速度就会更快。时间间隔的设定通常要考虑业务场景,如你希望统计每分钟高速公路的车流量,那么时间间隔可以设为 1min。
Spark Streaming 主要负责将流数据转换成小的批数据,剩下的就可以交给 Spark 去做了。
Flink
前面说 Spark Streaming 是将实时数据流按时间分段后,当作小的批处理数据去计算。那么 Flink 则相反,一开始就是按照流处理计算去设计的。当把从文件系统(HDFS)中读入的
数据也当做数据流看待,他就变成批处理系统了。
为什么 Flink 既可以流处理又可以批处理呢?
如果要进行流计算,Flink 会初始化一个流执行环境 StreamExecutionEnvironment,然后利用这个执行环境构建数据流 DataStream。
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());
如果要进行批处理计算,Flink 会初始化一个批处理执行环境 ExecutionEnvironment,然后利用这个环境构建数据集 DataSet。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.readTextFile("/path/to/file");
然后在DataStream或者DataSet上执行各种数据转换操作(transformation),这点很像 Spark。不管是流处理还是批处理,Flink 运行时的执行引擎是相同的,只是数据源不同而已。
Flink 处理实时数据流的方式跟 Spark Streaming 也很相似,也是将流数据分段后,一小批一小批地处理。流处理算是 Flink 里的“一等公民”,Flink 对流处理的支持也更加完善,它可
以对数据流执行 window 操作,将数据流切分到一个一个的 window 里,进而进行计算。
在数据流上执行 .timeWindow(Time.seconds(10))
可以将数据切分到一个 10 秒的时间窗口,进一步对这个窗口里的一批数据进行统计汇总。
Flink 的架构和 Hadoop 1 或者 Yarn 看起来也很像,JobManager 是 Flink 集群的管理者,Flink 程序提交给 JobManager 后,JobManager 检查集群中所有 TaskManager 的资源利用
状况,如果有空闲 TaskSlot(任务槽),就将计算任务分配给它执行。
Storm为第一代,低延迟,但是吞吐量不大,也保证不了时间准确。Spark Streaming微批次,可以做到高吞吐、保证数据正确,但是做不到低延迟,如果出现乱序数据spark也没有这样的处理概念,攒一批,在
代码中自己进行排序处理。Flink做到了所有。

2. Fink概念

Flink主页在其顶部展示了该项目的理念:“Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
流数据更真实地反映了我们的生活方式,传统的数据架构是基于有限数据集的。低延迟、高吞吐、结果的准确性和良好的容错性。
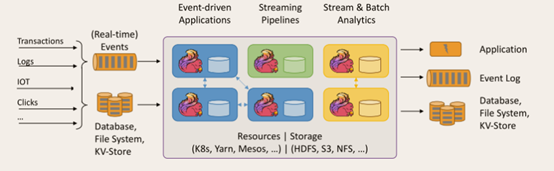
重要特点
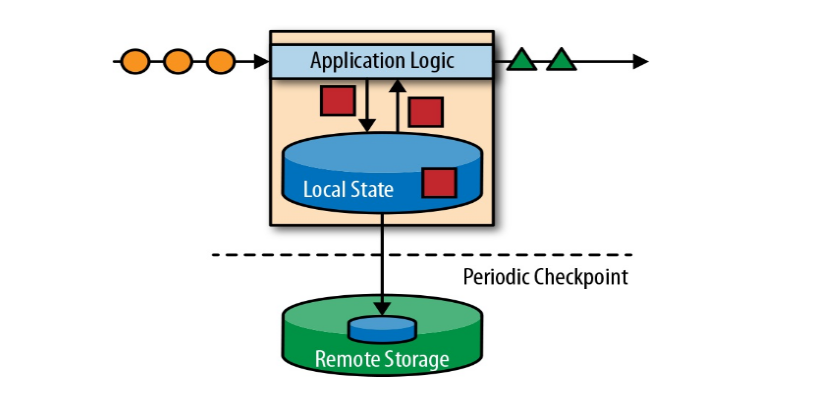
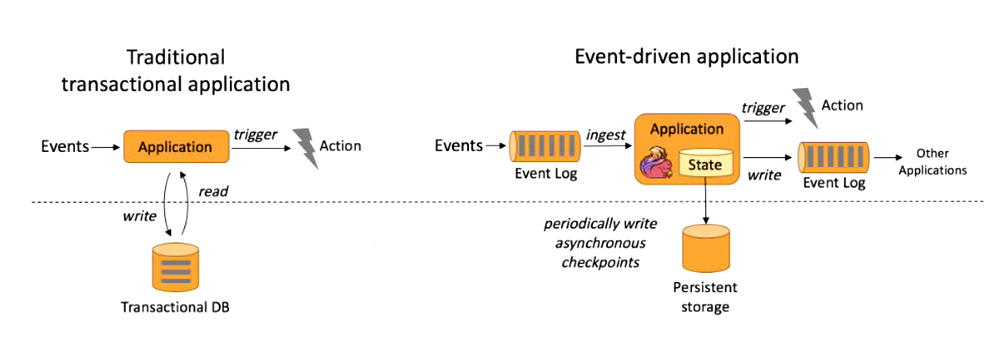
① 事件驱动型(Event-driven)
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以kafka为代表的消息队列几乎都
是事件驱动型应用。 事件驱动型如下图:
跟事务处理的架构比较相似,传统的处理方式跟关系型数据库做交互;Flink中当事件日志到来时,放到本地状态中,为了保证容错定期存盘放到远程持久化空间。通过事件日志和本地状态就可以得到一个结果,输出到结果事件日志。
与之不同的就是SparkStreaming微批次如图:

② 流与批的世界观
Flink基于流的世界观
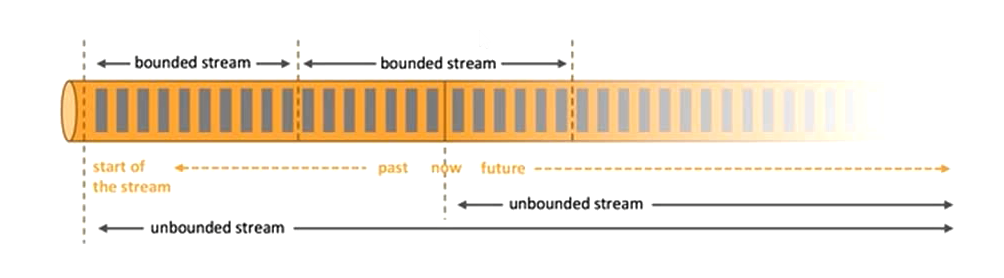
批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。
而在flink的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性。
有界数据流:有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
③ 分层API
简单的需求可以使用SQL/Table API; DataStream API 处理无界流,DataSet API处理有界流; 底层ProcessFunction API,强大灵活丰富。
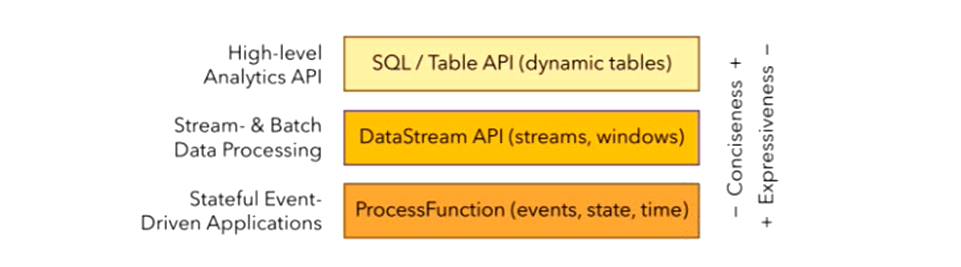
最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function)被嵌入到DataStream API中。底层过程函数(Process Function) 与 DataStream API 相集成,
使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回
调,从而使程序可以处理复杂的计算。
大多数应用并不需要上述的底层抽象,而是针对核心API(Core APIs) 进行编程,比如DataStream API(有界或无界流数据)以及DataSet API(有界数据集)。这些API为数据处
理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。
DataSet API 为有界数据集提供了额外的支持,例如循环与迭代。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。Table API遵循(扩展的)关系模型:表有二维数据结构(schema)(类似于关系数据库中的
表),同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。Table API程序声明式地定义了什么逻辑操作应该执行,而不是准确地确定这些操作代码的看
上去如何 。 尽管Table API可以通过多种类型的用户自定义函数(UDF)进行扩展,其仍不如核心API更具表达能力,但是使用起来却更加简洁(代码量更少)。除此之外,Table API
程序在执行之前会经过内置优化器进行优化。
你可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
Flink提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可
以直接在Table API定义的表上执行。
④ 其他特点
- 支持事件时间(event-time)和 处理时间(processing-time);
- 精确一次(exactly-once)的状态一致性保证;
- 低延迟,每秒处理数百万个事件,毫秒级延迟;
- 与众多常用存储系统的连接;
- 高可用,动态扩展,实现7 * 24小时全天候运行;
⑤ Spark Streaming VS Flink
Spark的延迟时间至少达到几百毫秒,一般设置为几秒的延迟--批次处理。Flink是毫秒级延迟
数据模型
- spark 采用 RDD 模型,弹性分布式数据集,spark streaming 的 DStream 实际上也就是一组 组小批数据 RDD 的集合
- flink 基本数据模型是数据流,以及事件(Event)序列,一条条数据。
运行时架构
- spark 是批计算,将 DAG 划分为不同的 stage,一个完成后才可以计算下一个。
- flink 是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理(没有stage的概念,不需要等待。)
WordCount
批处理
def main(args: Array[String]): Unit = {
//创建一个批处理的执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//从文件中读取数据
val inputPath: String = "F:\\HelloWorld.txt"
val inputDataSet: DataSet[String] = env.readTextFile(inputPath)
// 对数据进行转换处理统计,先分词,再按照word进行分组,最后进行聚合统计
val resultDataSet: AggregateDataSet[(String, Int)] = inputDataSet
.flatMap(_.split(" "))
.map((_, 1))
.groupBy(0)
.sum(1)
resultDataSet.print()
}
流式处理
def main(args: Array[String]): Unit = {
//创建流处理的执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//接收一个socket文本流
val inputDataStream: DataStream[String] = env.socketTextStream("hadoop102", 7777)
//进行转化处理统计
// flatMap 和Map 需要引用的隐式转换
import org.apache.flink.api.scala._
val resultDataStream: DataStream[(String, Int)] = inputDataStream.flatMap(_.split(" "))
.filter(_.nonEmpty)
.map((_, 1))
.keyBy(0)
.sum(1)
resultDataStream.print().setParallelism(1)
env.execute()
}
3. Flink集群搭建
Flink可以选择的部署方式有:
Local、Standalone(资源利用率低)、Yarn、Mesos、Docker、Kubernetes、AWS。
我们主要对Standalone模式和Yarn模式下的Flink集群部署进行分析。
安装配置
在官网下载1.10.0版本Flink(https://archive.apache.org/dist/flink/flink-1.10.0/)。
解压缩 flink-1.10.0-bin-scala_2.11.tgz,进入conf目录中。
1 修改安装目录下conf文件夹内的flink-conf.yaml配置文件,指定JobManager:
[kris@hadoop101 flink-1.10.0]$ vim conf/flink-conf.yaml jobmanager.rpc.address: hadoop101
2 修改安装目录下conf文件夹内的slave配置文件,指定TaskManager:
[kris@hadoop101 flink-1.10.0]$ vim conf/slaves hadoop102 hadoop103
3 将配置好的Flink目录分发给其他的两台节点:
[kris@hadoop101 module]$ xsync flink-1.10.0/
standalone模式和yarn模式这两种模式配置都一样;
① standalone模式的启动
[kris@hadoop101 flink-1.10.0]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop101.
Starting taskexecutor daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop103.
[kris@hadoop101 flink-1.10.0]$ xcall.sh jps
----------hadoop101------------
3839 Jps
3759 StandaloneSessionClusterEntrypoint
----------hadoop102------------
3573 Jps
3494 TaskManagerRunner
----------hadoop103------------
3576 Jps
3497 TaskManagerRunner
关闭集群:
[kris@hadoop101 flink-1.10.0]$ bin/stop-cluster.sh
http://hadoop101:8081 可以对flink集群和任务进行监控管理。
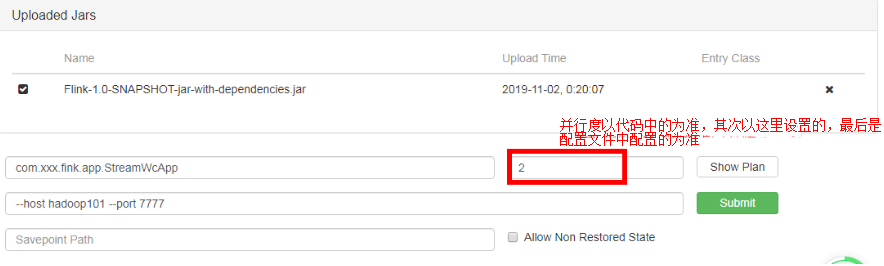
.setParallelism(1) 设置并行度的优先级,代码中算子的优先级最高、
其次是全局配置env.setParallelism(8),
最后才是Job提交时指定的 Parallelism(如果算子中和全局没有指定就以它为准);如果这里没有指定,最后的最后以集群配置文件的为准parallelism.default: 1,默认为1。
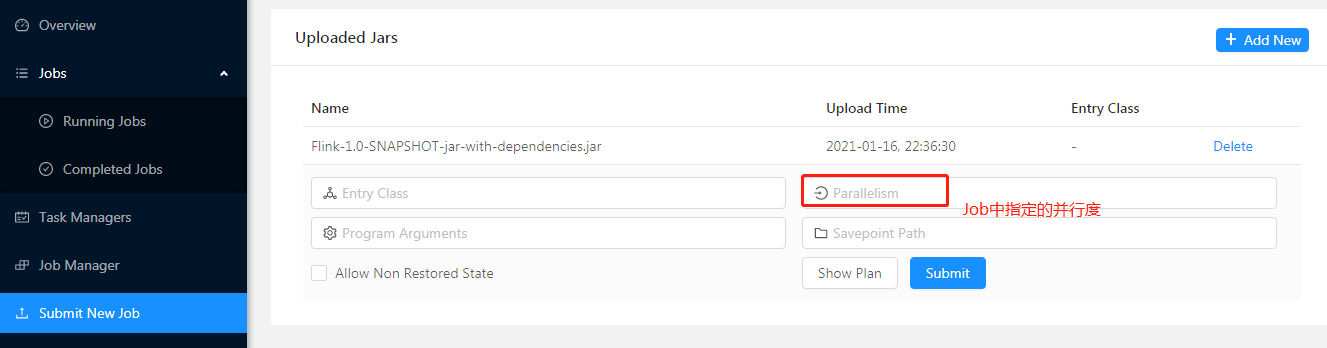

Slot,是每个Task Manager把资源划分出来后的一组小单元,一个Slot就是执行一个任务就是一个task一个最小单元,是分配资源的最小单位。
将下面代码打包在集群中测试


import org.apache.flink.api.java.utils.ParameterTool import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} object StreamWcApp { //设置并行度;输出时可以改变成一个 def main(args: Array[String]): Unit = { ////从外部命令中获取参数 val params: ParameterTool = ParameterTool.fromArgs(args) val host: String = params.get("host") val port: Int = params.getInt("port") //也可以直接设置host和port //val host: String = "hadoop101" //val port: Int = 7777 // env.setParallelism(1) 这里是全局设置并行度为1 // env.disableOperatorChaining() 不使用操作链 //创建流处理环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //接收socket文本流 val textDStream: DataStream[String] = env.socketTextStream(host, port) // flatMap和Map需要引用的隐式转换 import org.apache.flink.api.scala._ //处理 分组并且sum聚合 val dStream: DataStream[(String, Int)] = textDStream .flatMap(_.split(" ")).filter(_.nonEmpty) //.startNewChain() 开始一个新链条 .map((_, 1)).keyBy(0).sum(1) //打印输出 dStream.print().setParallelism(1) //执行任务 env.execute("stream word count job") } }
方式一页面中提交:
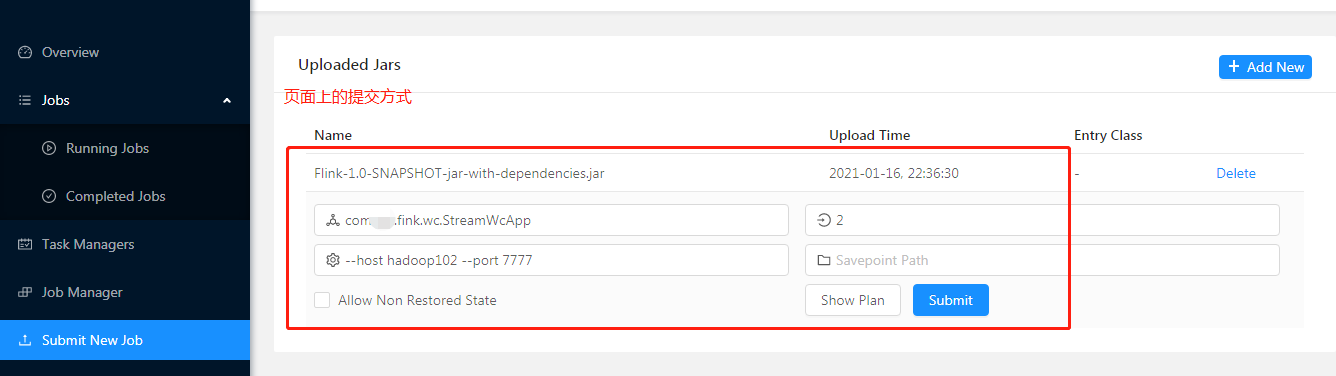
方式二:命令行的方式提交
#提交
[kris@hadoop102 flink-1.10.1]$ ./bin/flink run -c com.xxx.fink.wc.StreamWcApp \
-p 2 Flink-1.0-SNAPSHOT-jar-with-dependencies.jar \
--host hadoop102 \
--port 7777
Job has been submitted with JobID b1282d86719731a00229c57baaf25e0b
ctrl + c取消掉,但是任务还是在后台执行;
#查看正在运行的任务
[kris@hadoop102 flink-1.10.1]$ ./bin/flink list
Waiting for response...
------------------ Running/Restarting Jobs -------------------
16.01.2021 23:06:35 : b1282d86719731a00229c57baaf25e0b : stream word count job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
#取消任务
[kris@hadoop102 flink-1.10.1]$ ./bin/flink cancel b1282d86719731a00229c57baaf25e0b
Cancelling job b1282d86719731a00229c57baaf25e0b.
Cancelled job b1282d86719731a00229c57baaf25e0b.
##查看所有任务
[kris@hadoop102 flink-1.10.1]$ ./bin/flink list -a
Waiting for response...
No running jobs.
No scheduled jobs.
---------------------- Terminated Jobs -----------------------
16.01.2021 22:49:29 : ce4f52335f4d4e627fe4e746240239e3 : stream word count job (FINISHED)
16.01.2021 23:06:35 : b1282d86719731a00229c57baaf25e0b : stream word count job (CANCELED)
--------------------------------------------------------------
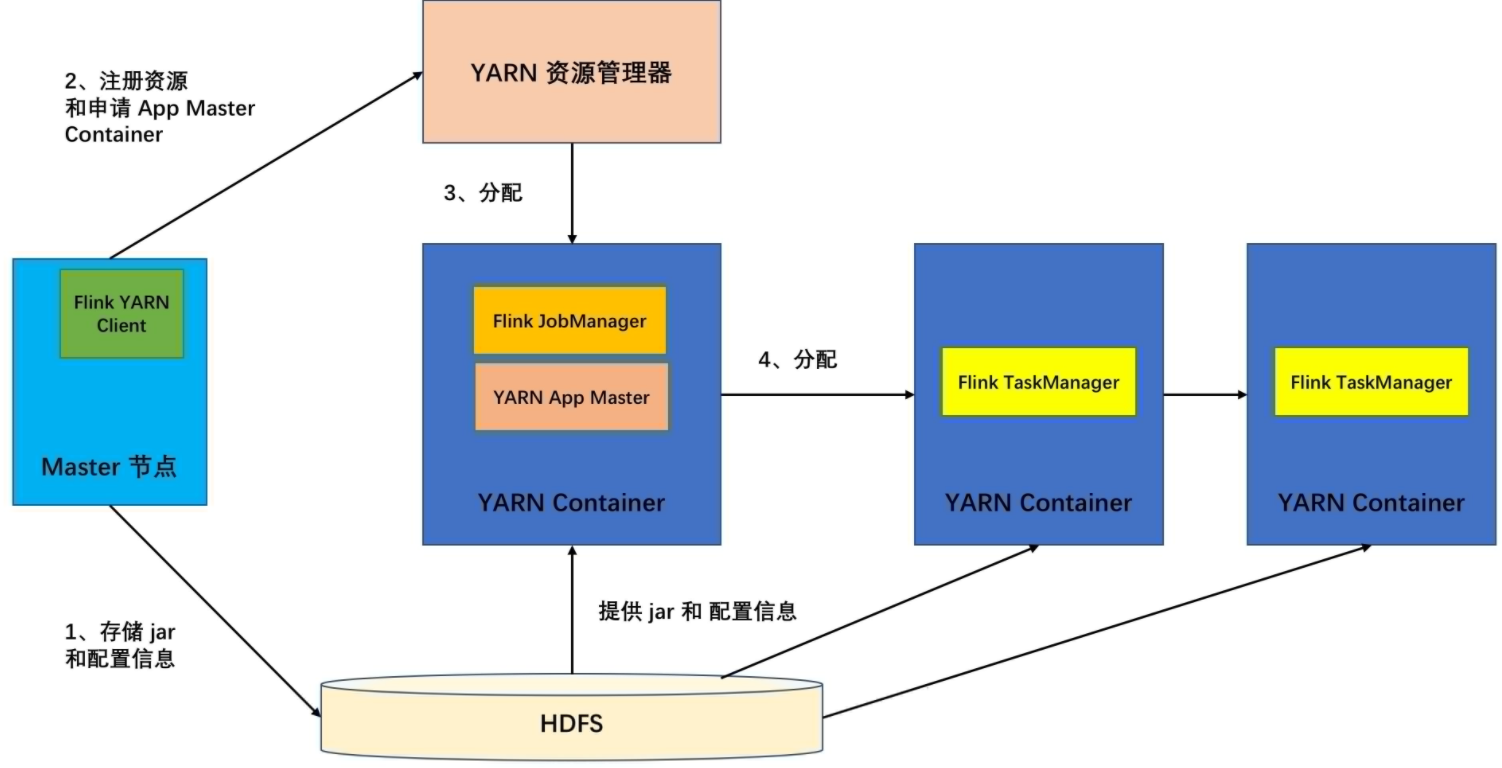
② Yarn模式的启动和运行
从官网下载支持yarn、hadoop的组件 flink-shaded-hadoop-2-uber-2.7.5-10.0.jar 放到flink-1.10.1/lib 下面。
Flink on Yarn
Flink提供了两种在yarn上运行的模式,分别为Session-Cluster(会话模式)和Per-Job-Cluster模式(Job作业模式,单独一个作业一个集群)。
1)Session-cluster 模式
先在yarn上创建一个yarn session,通过yarn session启动一个Flink集群,就在这个集群中提交作业,来一个job提交一个。 资源是已经定义好的,适用于规模比较小、作业执行时间比较短的任务,来一个任务运行完释放资源执行下一个任务,类似于standlone模式。
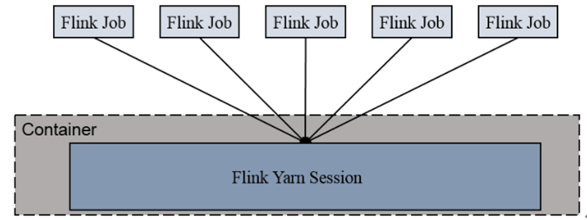
Session-Cluster模式需要先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作
业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享Dispatcher和ResourceManager;共享资源;适合规模小执行时间短的作业。
在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交。这个flink集群会常驻在yarn集群中,除非手工停止。
Yarn-Session模式的启动
- 明确虚拟机中已经设置好了环境变量HADOOP_HOME。
- 启动Hadoop集群(HDFS和Yarn)。
- 在hadoop101节点提交Yarn-Session,使用安装目录下bin目录中的yarn-session.sh脚本进行提交:
[kris@hadoop101 flink-1.10.0]$ bin/yarn-session.sh -n 2 \
-s 2 \
-jm 1024 \
-tm 1024 \
-nm test \
-d
Yarn-session模式提交就不看配置文件了,默认以命令行上的参数为准,
其中:
-n(--container):TaskManager的数量,之后的版本不再指定而是动态分配。
-s(--slots): 每个TaskManager的slot数量,默认一个slot一个core(CPU),默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。建议设置为每个机器的CPU核数,跑在slot上的一个任务即一个线程。 比如4核CPU,-s 8,则多个slot共享一个cpu;
-jm:JobManager的内存(单位MB)。
-tm:每个taskmanager的内存(单位MB) 整个容器所占的内存。
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行。
启动后查看Yarn的Web页面,可以看到刚才提交的会话:

http://hadoop101:48031 可查看页面
一旦session创建成功,就可以使用./bin/flink工具向集群提交任务。
最好写全路径:
[kris@hadoop101 flink-1.10.0]$ bin/flink run -m yarn-cluster -c com.xxx.fink.app.BatchWcApp Flink-1.0-SNAPSHOT-jar-with-dependencies.jar --input data/input.txt --output data/output-yarn.csv
INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
Starting execution of program
(am,1)
(are,1)
(fine,2)
(how,1)
(i,1)
(thank,2)
(too,1)
(you,3)
Program execution finished
Job with JobID 281d37c037a4e56dbc558ac21b8043d9 has finished.
Job Runtime: 3319 ms
================================
查看运行最后结果在hadoop103机器上面: /opt/moudle/flink1.10.0/data/output-yarn.csv
在yarn上运行一个官方 flink job的wordCount
[kris@hadoop101 flink-1.10.0]$ bin/flink run -m yarn-cluster examples/batch/WordCount.jar
(would,2)
(wrong,1)
(you,1)
Program execution finished
Job with JobID ed51d12a4992c907b9b7e4cb2a28dc05 has finished.
Job Runtime: 18291 ms
Accumulator Results:
- 55207241aa959f05f454d610997e5e51 (java.util.ArrayList) [170 elements]
去yarn控制台查看任务状态

页面提交jar包
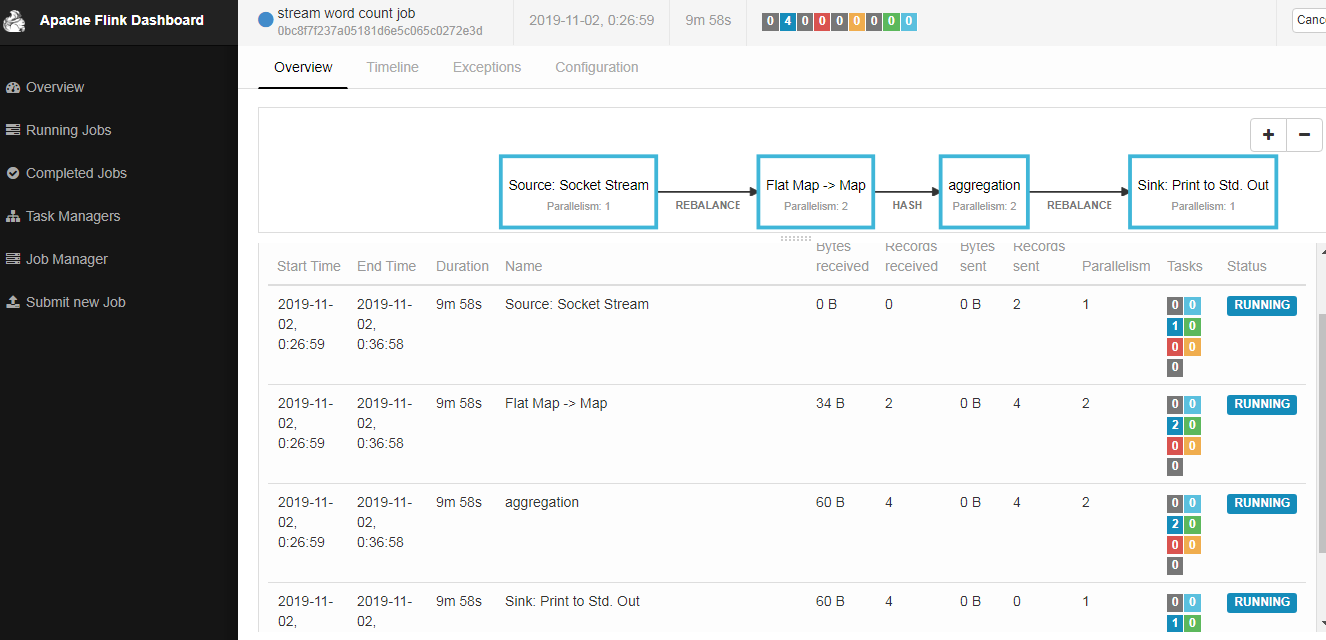
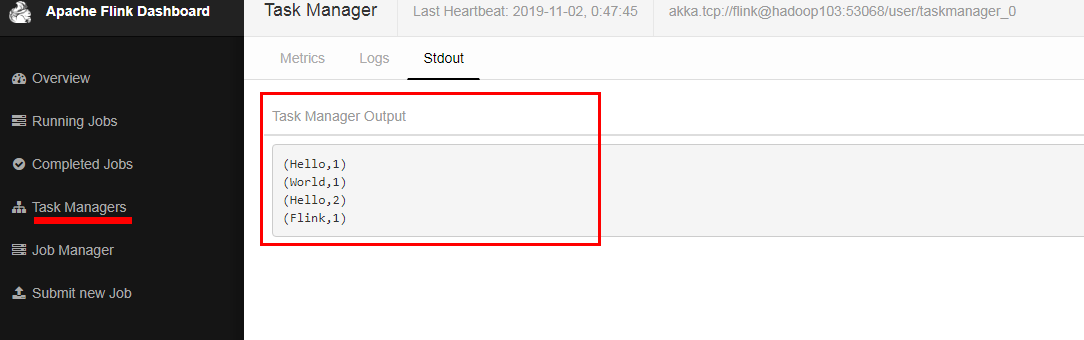
sink端,代码里边直接设置了并行度为1;前边算子的并行度,每个算子都可以单独设置并行度,(代码中没设置,以页面提交的并行度为准);
socket端不能是并行的;
命令行提交
启动yarn-session:
[kris@hadoop101 flink-1.10.0]$ bin/yarn-session.sh -n 2 -s 6 -jm 1024 -tm 1024 -nm test -d

[kris@hadoop101 flink-1.10.0]$ bin/flink run -c com.xxx.fink.app.StreamWcApp -p 2\
/opt/module/flink-1.7.2/Flink-1.0-SNAPSHOT-jar-with-dependencies.jar\
--host hadoop101\
--port 7777
INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor
Found application JobManager host name 'hadoop101' and port '48031' from supplied application id 'application_1572752436054_0001'
Starting execution of program
[kris@hadoop101 ~]$ xcall.sh jps
----------hadoop101------------
12035 CliFrontend ##是正在运行的jar包
12357 Jps
7989 NodeManager
7625 NameNode
7802 DataNode
10156 FlinkYarnSessionCli
10318 YarnSessionClusterEntrypoint #jobManager的名称
----------hadoop102------------
7344 Jps
6108 NodeManager
5853 DataNode
5951 ResourceManager
----------hadoop103------------
8150 Jps
8075 YarnTaskExecutorRunner #taskManager的名称
5964 NodeManager
5837 DataNode
6063 SecondaryNameNode

查询
[kris@hadoop101 flink-1.7.0]$ bin/flink list
INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor
Found application JobManager host name 'hadoop101' and port '33305' from supplied application id 'application_1572674361568_0001'
Waiting for response...
------------------ Running/Restarting Jobs -------------------
02.11.2019 14:04:39 : 146b2bf2349e2fbe8596433eec572c25 : stream word count job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
取消任务
[kris@hadoop101 flink-1.7.0]$ bin/flink cancel 146b2bf2349e2fbe8596433eec572c25
2) Per-Job-Cluster 模式
Job提交上之后,按照每个Job去创建一个分集群,每个Job会独占一个分集群。不同Job之间互不影响。
一个Job会对应一个集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享
Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
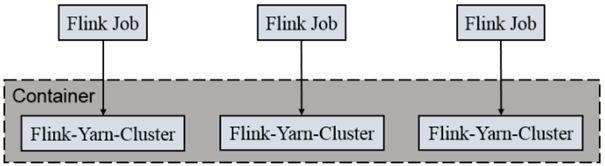
1) 启动hadoop集群
2) 不启动yarn-session,直接执行job
bin/flink run –m yarn-cluster \
-c com.xxx.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar \
--host hadoop101 \
-–port 7777
#基于flink-1.12.1
export HADOOP_CLASSPATH=`hadoop classpath`
bin/flink run -t yarn-per-job examples/streaming/SocketWindowWordCount.jar --host hadoop102 --port 7777
--------- hadoop102 ----------
4225 CliFrontend
2551 NameNode
2697 DataNode
3209 JobHistoryServer
5145 Jps
4957 YarnTaskExecutorRunner
3118 NodeManager
--------- hadoop103 ----------
2179 DataNode
2348 ResourceManager
3469 Jps
2478 NodeManager
--------- hadoop104 ----------
2258 SecondaryNameNode
3266 YarnJobClusterEntrypoint
3523 Jps
2362 NodeManager
2175 DataNode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号