1.大数据概述
大数据应该具备如下特征:
1. 数据量(Volume)
2. 多样性(Variety)
3. 价值(Value)
4. 速度(Velocity)
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
具有可靠、高效、可伸缩的特点。
核心组件有:Hdfs、Yarn、MapReduce;
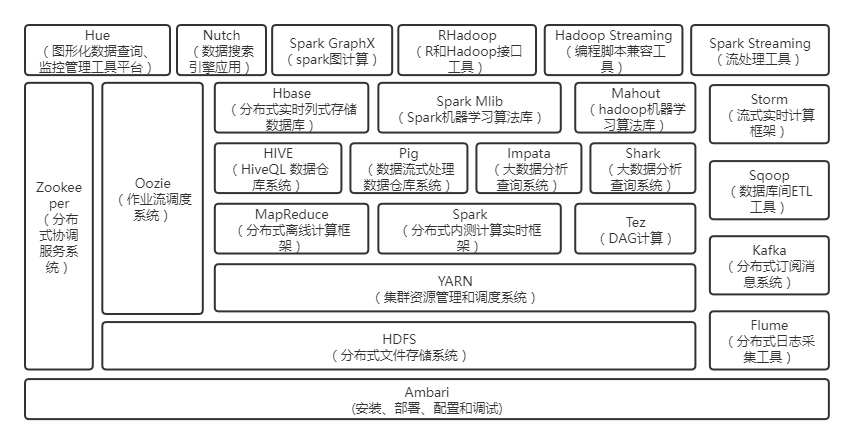
广义上指一个生态圈,泛指大数据技术相关的开源组件或产品,如hdfs、yarn、hbase、hive、spark、pig、zookeeper、kafka、flume、phoenix、sqoop
HDFS:Hadoop中的重要组件之一,用来做分布式存储,具有高容错,高吞吐等特性,是常用的分布式文件存储
MR(MapReduce简称):Hadoop中的重要组件之一,作为分布式计算模型,程序人员只需在Mapper、Reducer中编写业务逻辑,然后直接交由框架进行分布式计算即可。
Yarn:Yarn是Hadoop中的重要组件之一,负责海量数据运算时的资源调度
Flume: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,用来做数据采集。
Kafka:分布式的消息发布/订阅系统,通过与Spark Streaming整合,完成实时业务计算。由Java+scala开发。
Hive/Pig:hive是基于Hadoop的一个数据仓库工具,通过将结构化的数据文件(通常为HDFS文件)映射为一张数据表,提供简单的sql查询功能,将sql语句转换为MapReduce任务运行。
pig可以看做hadoop的客户端软件,可以连接到hadoop集群进行数据分析工作,企业中很少用了。
Hbase:HBase是建立在Hadoop文件系统之上的面向列的分布式数据库。不同于一般的关系数据库,适合于存储非结构化的数据,HBase基于列而不是基于行。
Redis:Redis 可基于内存也可以持久化的日志型、Key-Value数据库。往往用来缓存key-value类型的小表数据。
Sqoop:负责数据在 HIVE---HDFS---DB之间进行导入导出
Standalone:是Spark提供的资源管理器,
Mesos:也是Apache下的开源分布式资源管理器。
Spark:Spark是大规模数据快速处理通用的计算引擎,其提供大量的库:Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX 。(只是计算,不作存储)
Spark相对Hadoop的优越性
(1)Spark基于RDD,数据并不存放在RDD中,只是通过RDD进行转换,通过装饰者设计模式,数据之间形成血缘关系和类型转换;(2)Spark用scala语言编写,相比java语言编写的Hadoop程序更加简洁;
(3)相比Hadoop中对于数据计算只提供了Map和Reduce两个操作,Spark提供了丰富的算子,可以通过RDD转换算子和RDD行动算子,实现很多复杂算法操作,这些在复杂的算法在Hadoop中需要自己编写,而在Spark中直接通过scala语言封装好了,直接用就ok;
(4)Hadoop中对于数据的计算,一个Job只有一个Map和Reduce阶段,对于复杂的计算,需要使用多次MR,这样涉及到落盘和磁盘IO,效率不高;而在Spark中,一个Job可以包含多个RDD的转换算子,在调度时可以生成多个Stage,实现更复杂的功能;
(5)Hadoop中中间结果存放在HDFS中,每次MR都需要刷写-调用,而Spark中间结果存放优先存放在内存中,内存不够再存放在磁盘中,不放入HDFS,避免了大量的IO和刷写读取操作;
(6)Hadoop适合处理静态数据,对于迭代式流式数据的处理能力差;Spark通过在内存中缓存处理的数据,提高了处理流式数据和迭代式数据的性能;
如何实现Spark和Hadoop的统一部署?
由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的,比如,Storm可以实现毫秒级响应的流计算,但是,Spark则无法做到毫秒级响应。另一方面,企业中已经有许多现有的应用,都是基于现有的Hadoop组件开发的,完全转移到Spark上需要一定的成本。因此,在许多企业实际应用中,Hadoop和Spark的统一部署是一种比较现实合理的选择。
由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署。这些不同的计算框架统一运行在YARN中,可以带来如下好处:
1.计算资源按需伸缩;
2.不用负载应用混搭,集群利用率高;
3.共享底层存储,避免数据跨集群迁移。