


参考学习:
RT-DETR 详解之 Efficient Hybrid Encoder_hybridencoder-CSDN博客
RT-DETR | 3、AIFI_哔哩哔哩_bilibili
RT- DETR | 4、CCFM_哔哩哔哩_bilibili
本文用于剖析HybridEncoder结构,加强学习记忆。
HybridEncoder结构
下图为HybridEncoder结构图
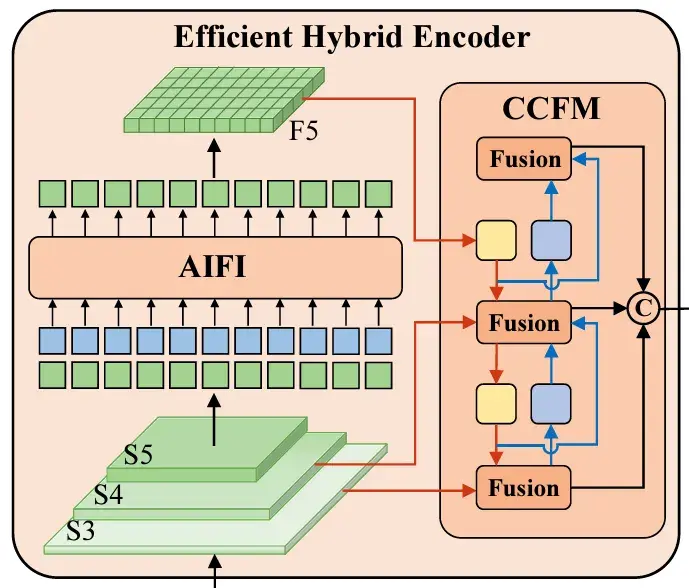
从结构图上看,可以看见HybridEncoder主要是两部分,AIFI和CCFM那就寻找这两部分的代码就好了。
处理这两大组件前先处理一些其他组件。
self.input_proj
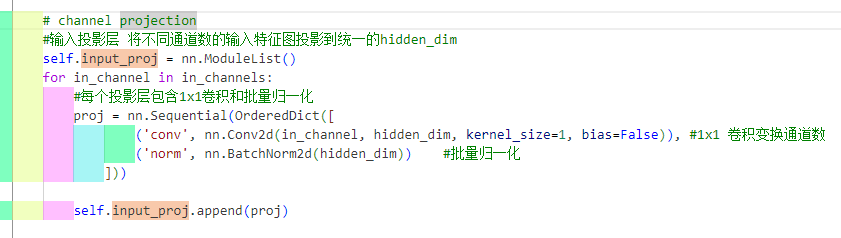
这个组件的作用就是有点像下采样,主要目的是对其通道深度进行统一,为了后续变成token做准备。
下面这个就是属于AIFI的代码逻辑,其实就是把S5层的特征转换为token进行编码,编码后的token再还原为特征块为后续进行处理。
1 #《AIFI》 2 # encoder编码器部分 3 if self.num_encoder_layers > 0: #设置为1,只有一个只执行一次 4 for i, enc_ind in enumerate(self.use_encoder_idx): #根据use_encoder_idx提取要使用的特征图层数 5 h, w = proj_feats[enc_ind].shape[2:] #读取索引的特征图后两个维度h,w 6 # flatten [B, C, H, W] to [B, HxW, C] 7 src_flatten = proj_feats[enc_ind].flatten(2).permute(0, 2, 1) #将维度碾平从[B, C, H, W]到[B, C, H×W]最后到[B, HxW, C], H×W就是Token的数量, C就是Token的长度 8 #生成位置编码 9 if self.training or self.eval_spatial_size is None: 10 pos_embed = self.build_2d_sincos_position_embedding( 11 w, h, self.hidden_dim, self.pe_temperature).to(src_flatten.device) 12 else: 13 pos_embed = getattr(self, f'pos_embed{enc_ind}', None).to(src_flatten.device) 14 15 #上述步骤就准备好了输入的Token(src_flatten)还有Token的位置编码(pos_embed) 16 17 #执行编码器 18 memory :torch.Tensor = self.encoder[i](src_flatten, pos_embed=pos_embed) #进入Transformer的编码器部分,执行后输入输出相同 19 proj_feats[enc_ind] = memory.permute(0, 2, 1).reshape(-1, self.hidden_dim, h, w).contiguous() #再将碾平的尺寸还原回碾平之前[B, HxW, C]到[B, C, H×W]再到[B, C, H, W],将模型骨干网络中被索引的位置特征图替换成通过编码的 20 #《/AIFI》
下面是CCFM的代码
1 #《CCFM》 2 # broadcasting and fusion 3 #先从上到下 4 inner_outs = [proj_feats[-1]]#这个inner_outs存储的是最后一层经过Transformer编码器处理过后的特征,与此同时从backbone提取的前两层都没有被处理过 5 for idx in range(len(self.in_channels) - 1, 0, -1): #idx = 2, 1(不包括0),初始为2,range(start, stop, step):开始下标,结束下标,步长 6 feat_heigh = inner_outs[0] #提取高层特征图,就是inner_outs[0]的特征图,为最高层特征图,在inner_outs刚开始也只有它一个 7 feat_low = proj_feats[idx - 1]#idx-1=1,idx为1,对应着S4层特征,倒数第二层特征图 8 feat_heigh = self.lateral_convs[len(self.in_channels) - 1 - idx](feat_heigh) #len(self.in_channels)-1-idx=0,1初始为0,过一个1*1卷积(laterral_convs中全是1*1的带bn的卷积块),对高层特征进行维度调整(通常是 1×1 卷积),使其通道数与低层特征一致,便于后续融合。 9 inner_outs[0] = feat_heigh #把feat_high存回去,这算是高层通过卷积处理后的特征图 10 upsample_feat = F.interpolate(feat_heigh, scale_factor=2., mode='nearest') #上采样,输出特征尺寸乘2,通道深度不变 #feat_high[B,C,H,W]——>feat_high[B,C,2H,2W] 11 inner_out = self.fpn_blocks[len(self.in_channels)-1-idx](torch.concat([upsample_feat, feat_low], dim=1)) #len(self.in_channels)-1-idx:0,1,初始为0,初始将上采样的S5和S4特征在特征维度拼接起来送入CSP进行融合,得到所谓的Fusion 12 inner_outs.insert(0, inner_out) #将融合后的特征inner_out插入到列表的开头(索引 0 的位置),注意这里不是覆盖,是插入 13 #该循环循环两遍 14 #在第二次进行该循环的时候 feat_high是上一次循环融合好的特征 feat_low是S3的特征,将feat_high进行卷积上采样与feats_low进行融合,将结果再次插入到inner_outs中 15 #经过两次循环之后 inner_outs中将包含三个元素 [0]是三层融合后的结果(没经过1*1卷积) [1]是S4和S5融合后又经过1*1卷积的结果 [2]是S5经过1*1卷积后的结果 16 17 18 #再从下到上 19 outs = [inner_outs[0]] #取的是三层从上到下融合后的结果(未经过1*1卷积)再加一个维度(多套了一层[]) 20 for idx in range(len(self.in_channels) - 1): #len(self.in_channels)-1=2,idx=0,1 21 feat_low = outs[-1] #取出三层从上到下融合后的特征 22 feat_height = inner_outs[idx + 1] #idx+1=1,2;第一次循环取出S4和S5的融合结果 23 downsample_feat = self.downsample_convs[idx](feat_low) #idx=0,1 采用卷积对低级特征进行下采样 24 out = self.pan_blocks[idx](torch.concat([downsample_feat, feat_height], dim=1)) #将下采样后的低级特征与高级特征在第通道维度上进行拼接,采用CSP进行融合 25 outs.append(out) #将融合后的特征out拼接到outs的尾部 26 #该循环会循环两边 27 #在第二次进行该循环的时候 feat_low是S3和S4(经过从上到下处理)融合后结果,feats_high是S5的特征,将feat_low进行下采样与feat_high融合,将结果再次拼接到outs的末尾 28 #经过两次循环时候 outs中包含三个元素 [0]是三个层自上而下融合后的结果 [1]是三个层自上而下融合后的结果再与上两层自上而下融合后的结果相容和的结果 29 # [2]是五个层融合后的结果在和S5的初代卷积融合后的结果,称为六个层融合后的结果,也是S3,S4,S5自上而下再自下而上融合后的结果,也是S3,S4,S5各自被融合两次的结果 30 31 return outs #最终返回outs数组
