学会使用正则表达式
1. 用正则表达式判定邮箱是否输入正确。
import re text = "64sdfsdff942@q.q.com" if re.match(r'^[0-9a-zA-Z_]{0,19}@[0-9a-zA-Z]{1,13}\.[com,cn,net]{1,3}$', text): print('对的') else: print('错的!')

2. 用正则表达式识别出全部电话号码。
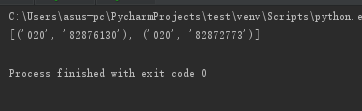
import re str = '''版权所有:广州商学院 地址:广州市黄埔区九龙大道206号学校办公室:020-82876130 招生电话:020-82872773粤公网安备44011602000060号粤ICP备15103669号''' print(re.findall('(\d{3,4})-(\d{6,8})', str))
3. 用正则表达式进行英文分词。re.split('',news)
import re news = '''Whatever is worth doing is worth doing well.''' print(re.split('[\s,.?\-]', news))

4. 使用正则表达式取得新闻编号
5. 生成点击次数的Request URL
6. 获取点击次数
7. 将456步骤定义成一个函数 def getClickCount(newsUrl):
import requests import re newsUrl = 'http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0401/9167.html' def getClickCount(newUrl): newsId = re.search('\_(.*).html', newUrl).group(1).split('/')[-1] res = requests.get('http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newsId)) return (int(res.text.split('.html')[-1].lstrip("(')").rstrip("');"))) click = getClickCount(newsUrl) print(click)

8. 将获取新闻详情的代码定义成一个函数 def getNewDetail(newsUrl):
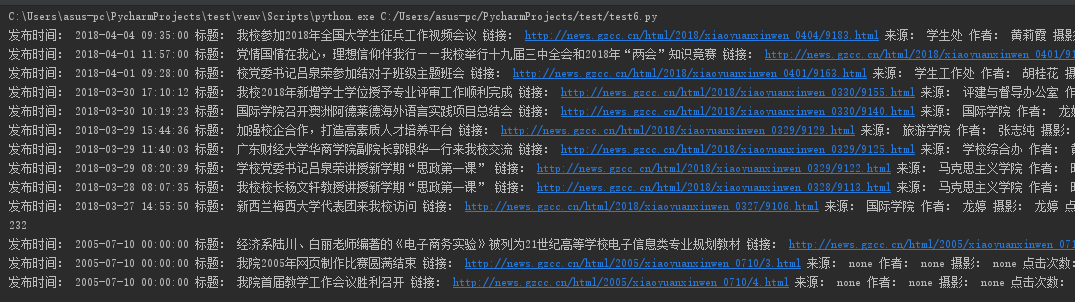
def getNewDetail(newsUrl): resd = requests.get(newsUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') title = soupd.select('.show-title')[0].text info = soupd.select('.show-info')[0].text dt = datetime.strptime(info.lstrip('发布时间:')[0:19], '%Y-%m-%d %H:%M:%S') if info.find('作者:') > 0: wr = info[info.find('作者:'):info.find('审核:')].lstrip('作者:').split()[0] else: wr = 'none' if info.find('摄影:') > 0: ph = info[info.find('摄影:'):].split()[0].lstrip('摄影:') else: ph = 'none' if info.find('来源:') > 0: source = info[info.find('来源:'):].split()[0].lstrip('来源:') else: source = 'none' content = soupd.select('.show-content')[0].text.strip() click = getClickCount(newsUrl) print('发布时间:', dt, '标题:', title, '链接:', newsUrl, '来源:', source, '作者:', wr, '摄影:', ph, '点击次数:', click) getNewDetail(newsUrl)

9. 取出一个新闻列表页的全部新闻 包装成函数def getListPage(pageUrl):
def getListPage(newsurl): res = requests.get(newsurl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') for new in soup.select('li'): if len(new.select('.news-list-title'))>0: newsUrl = new.select('a')[0].attrs['href'] getNewDetail(newsUrl) getListPage(newsUrl)

10. 获取总的新闻篇数,算出新闻总页数包装成函数def getPageN():
def getPageN(): res = requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/') res.encoding = "utf-8" soup = BeautifulSoup(res.text, 'html.parser') n = int(soup.select('#pages')[0].select('a')[0].text.rstrip('条')) return (n // 10 + 1) print(getPageN())
11. 获取全部新闻列表页的全部新闻详情。
getListPage(newsUrl) n=getPageN() for i in range(n,n+1): print(i) pageUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) getListPage(pageUrl)