
oo第一单元作业总结
一、概述
第一单元的作业主要内容为表达式解析与化简,由于寒假预习不充分,我在一开始就采用了预解析模式,所以代码结构较简单,在整个迭代开发过程中基本没有经历过大的重构;
基本思路是对预处理输入的每一行解析出操作符和操作数,并对每一行的f(n)建立一个单独的表达式对象;将计算和展开后的产生的未经化简的表达式存入这个对象,每一行的结果可以作为之后行的操作数,将最后一行生成的表达式对象化简shorten()并输出toString()即为最终的表达式。
二、程序结构分析
1、Task1
1.1 工程概述
第一次作业的因子只有常数和x,共有六种操作符:add,sub,pow,mul,pos,neg 在expr类和term类中分别通过单独的方法实现它们。
由于预解析模式在解析上提供的便利,并不需要使用大部分同学所采用的递归下降方法;结构中的Factor仅为单纯的String变量,
并在相应的展开,合并,化简操作中直接对字符串进行操作,不存在例如将系数、指数、基本因子分别存储的抽象存储结构,因此代码结构较为简单。
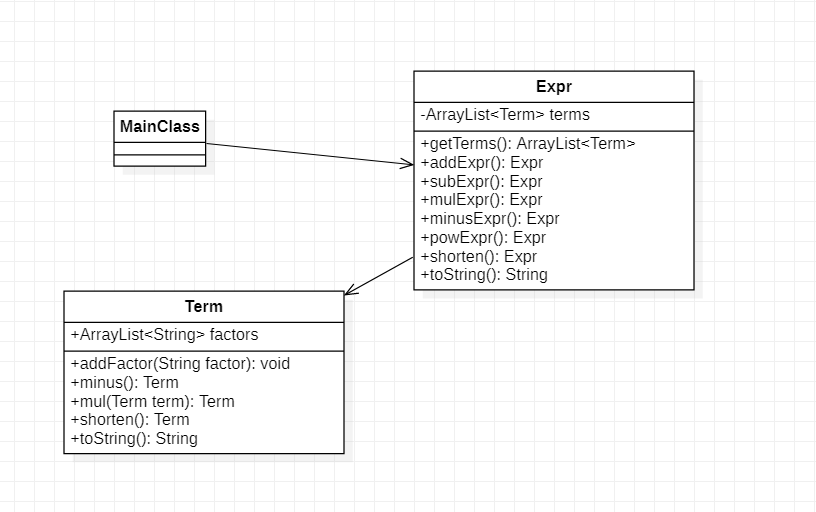
第一次作业中仅有三个类:MainClass, Expr, Term
其中MainClass负责输入时解析输入操作符和操作数,管理控制展开、合并、化简、输出的操作;Expr为表达式层级,管理Term对象,Term为项层级,管理Factor对象,
两者分别在各自层级上实现加减乘以及乘方、化简操作。
在算法设计的过程中,使用add,neg操作实现sub,使用mul操作实现pow;一定程度上避免了重复造轮子。
1.2 UML类图
1.3 代码结构度量分析
由度量分析可看出,shorten()方法由于将较复杂的化简操作全部集中于一个方法中,复杂度较高,代码量较大,甚至几乎要导致代码风格分大残;
好处是耦合度低,由于涉及到的操作几乎都是直接对字符串进行,在一个方法中实现了合并系数、统计指数、统计正负以及消去多余符号等功能。
MainClass由于兼顾了解析输入和管理操作的功能,显得有些复杂,不够精简,代码量较多,这在我的下一次作业中得到了改进。
| Method | CogC | ev(G) | iv(G) | v(G) |
| MainClass.main(String[]) | 25.0 | 1.0 | 11.0 | 11.0 |
| expr.Term.toString() | 4.0 | 2.0 | 3.0 | 3.0 |
| expr.Term.Term(String) | 2.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.Term(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.Term() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.shorten() | 19.0 | 1.0 | 11.0 | 13.0 |
| expr.Term.setFactors(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.mul(Term) | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Term.minus() | 5.0 | 1.0 | 4.0 | 4.0 |
| expr.Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.addFactor(String) | 2.0 | 1.0 | 2.0 | 2.0 |
| expr.Expr.toString() | 7.0 | 2.0 | 4.0 | 4.0 |
| expr.Expr.subExpr(Expr) | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Expr.shorten() | 23.0 | 1.0 | 12.0 | 13.0 |
| expr.Expr.powExpr(int) | 2.0 | 2.0 | 2.0 | 3.0 |
| expr.Expr.mulExpr(Expr) | 3.0 | 1.0 | 3.0 | 3.0 |
| expr.Expr.minusExpr() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expr.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.Expr(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.Expr(Expr, String) | 3.0 | 1.0 | 4.0 | 4.0 |
| expr.Expr.Expr(Expr, int, String) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expr.Expr(Expr, Expr, String) | 3.0 | 1.0 | 4.0 | 4.0 |
| expr.Expr.Expr(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.Expr() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.addExpr(Expr) | 2.0 | 1.0 | 3.0 | 3.0 |
| Total | 106.0 | 28.0 | 83.0 | 87.0 |
| Average | 4.24 | 1.12 | 3.32 | 3.48 |
| Class | OCavg | OCmax | WMC |
| MainClass | 11.0 | 11.0 | 11.0 |
| expr.Term | 3.1 | 13.0 | 31.0 |
| expr.Expr | 3.0714285714285716 | 12.0 | 43.0 |
| Total | 85.0 | ||
| Average | 3.4 | 12.0 | 28.333333333333332 |
1.4 bug分析与hack策略
由于采用了预解析模式,代码几乎没有出什么bug,在强测和互测中都没有出问题;
第一次作业可供hack的点也较少,在阅读他人代码的过程中,我主要是抱着学习的态度;并采用黑盒hack策略,随机构造边界数据进行测试,未发现他人bug。
2、Task2 & Task3
2.1 工程概述
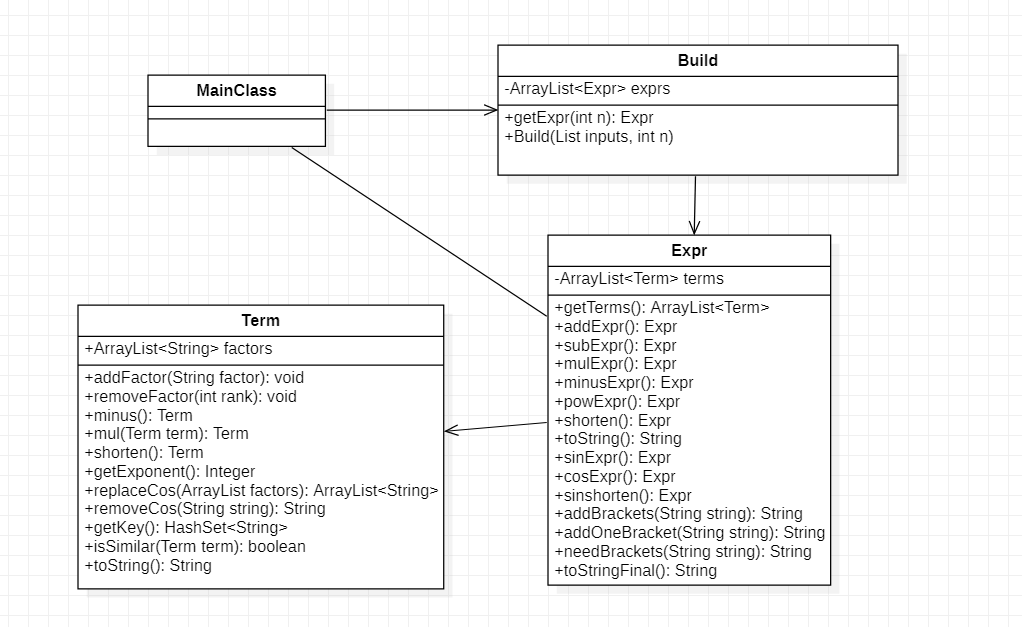
第二次作业中共有四个类:MainClass, Build, Expr, Term
与第一次作业相比,第二次主要的改动在于新增了sin() 和cos() 因子,以及相应的操作符sin, cos;这使得化简操作需要处理的内容复杂度大幅增加。
本次作业采用将sin或cos括号中内容一致的因子作为一个单独的与x地位等同的未知数来看待(当然,括号中的内容首先经过了可实现最终格式统一的化简操作),
并设计了getKey()方法来提取出每个Term的全部未知数及其指数,将其作为这个Term的特征看待;设计isSimliar()方法来判断两个Term的特征是否一致;
化简时则合并特征一致的所有Term的系数。
新增的Build类负责实现原本有由Mainclass类实现的解析功能;降低了整体功能上的耦合度。
由于在三角函数中不应有x*x这样的非因子项存在,故而为三角函数括号内的化简单独写了一个方法,属于是重复造轮子了,为了极少的一点性能分牺牲了代码整体的
美观和简洁,这一点需要检讨;另外在最终化简时将sin(0)直接替换成0,略微提升了程序性能。
由于在预解析模式下,第三次作业仅仅是新增了三角函数嵌套,只需要为sin() 和cos() 中的表达式因子添加相应的括号,改动较少,
故直接展示第三次作业的UML类图以及代码度量分析,避免重复叙述。
2.2 UML类图
2.3 代码结构度量分析
由于新增了Build类,使得主类的复杂度大幅降低;
shorten()方法复杂度依然过高,这是代码架构的问题,难以在现有框架下解决;第三次作业中新增的判断是否需要添加括号needBrackets()方法以及添加括号的addOneBracket()
方法同样如此,复杂度较高;这是由于我的工程架构缺少一个统一的抽象数据存储结构,几乎始终在对着一个或几个字符串做操作,每次添加一个新功能都需要从0开始对字符串进行
分析和操作,这样的架构可延展性实在太差。。。
希望我今后的代码设计中能始终记得这次的教训,提早准备,尽早开始设计架构,保证其可迭代性质,这在我们今后的迭代作业中也会是极其关键的一点。
shorten()代码
点击查看代码
public Expr shorten() {
ArrayList<Term> shortterms = new ArrayList<>();
HashSet<HashSet<String>> used = new HashSet<>();
ArrayList<Term> minterms = new ArrayList<>();
for (int i = 0; i < terms.size(); i = i + 1) {
Term term = terms.get(i).shorten();
shortterms.add(term);
}
for (Term item0 : shortterms) {
if (used.add(item0.getKey())) {
BigInteger bigInteger = BigInteger.valueOf(0);
for (Term item : shortterms) {
if (item0.isSimilar(item)) {
bigInteger = bigInteger.add(new BigInteger(item.getFactors().get(0)));
}
}
if (bigInteger.compareTo(BigInteger.valueOf(0)) != 0) {
String number = bigInteger.toString();
Term term;
//
if ("1".equals(number)) {
term = new Term();
} else {
term = new Term(number);
}
//
String xplus = item0.getFactors().get(1);
if ("x**1".equals(xplus)) {
term.addFactor("x");
} else if ("x**2".equals(xplus)) {
term.addFactor("x*x");
} else if (!"x**0".equals(xplus)) {
term.addFactor(xplus);
}
//
if (item0.getFactors().size() > 2) {
for (int i = 2; i < item0.getFactors().size(); i = i + 1) {
term.addFactor(item0.getFactors().get(i));
}
}
if ("1".equals(number) && (term.getFactors().size() == 0)) {
term.addFactor("1");
}
if ("-1".equals(term.getFactors().get(0)) && term.getFactors().size() > 1) {
term.removeFactor(0);
term = term.minus();
}
for (int i = 0; i < term.getFactors().size(); i = i + 1) {
if (term.getFactors().get(i).contains("sin(0)")) {
term = new Term("0");
break;
}
}
minterms.add(term);
}
}
}
if (minterms.size() == 0) {
Term term = new Term("0");
minterms.add(term);
}
return new Expr(minterms);
}
needBrackets()代码
点击查看代码
public boolean needBrackets(String string) {
Pattern pattern1 = Pattern.compile("x(\\*\\*\\d+)?");
Pattern pattern2 = Pattern.compile("\\d+");
Matcher matcher1 = pattern1.matcher(string);
Matcher matcher2 = pattern2.matcher(string);
Pattern patternIndex = Pattern.compile("(\\*\\*\\d+)?");
if (matcher1.matches() || matcher2.matches()) {
return false;
} else {
if ("(".equals(String.valueOf(string.charAt(0)))) {
int sign = 1;
for (int i = 1; i < string.length(); i = i + 1) {
if ("(".equals(String.valueOf(string.charAt(i)))) {
sign += 1;
} else if (")".equals(String.valueOf(string.charAt(i)))) {
sign -= 1;
}
if (sign == 0) {
Matcher matcher = patternIndex.matcher(string.substring(i + 1));
if (matcher.matches()) {
return false;
} else {
return true;
}
}
}
} else if (string.length() >= 6) {
if ("sin(".equals(string.substring(0, 4)) ||
"cos(".equals(string.substring(0, 4))) {
int sign = 1;
for (int i = 4; i < string.length(); i = i + 1) {
if ("(".equals(String.valueOf(string.charAt(i)))) {
sign += 1;
} else if (")".equals(String.valueOf(string.charAt(i)))) {
sign -= 1;
}
if (sign == 0) {
Matcher matcher = patternIndex.matcher(string.substring(i + 1));
if (matcher.matches()) {
return false;
} else {
return true;
}
}
}
}
}
}
return true;
}
| Method | CogC | ev(G) | iv(G) | v(G) |
| MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.toString() | 4.0 | 2.0 | 3.0 | 3.0 |
| expr.Term.Term(String) | 2.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.Term(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.Term() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.shorten() | 42.0 | 1.0 | 16.0 | 18.0 |
| expr.Term.setFactors(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.replaceCos(ArrayList) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.removeFactor(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.removeCos(String) | 2.0 | 2.0 | 1.0 | 2.0 |
| expr.Term.mul(Term) | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Term.minus() | 5.0 | 1.0 | 4.0 | 4.0 |
| expr.Term.isSimilar(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.getKey() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Term.getExponent() | 4.0 | 1.0 | 3.0 | 4.0 |
| expr.Term.addFactor(String) | 2.0 | 1.0 | 2.0 | 2.0 |
| expr.Expr.toStringFinal() | 7.0 | 1.0 | 4.0 | 4.0 |
| expr.Expr.toString() | 7.0 | 1.0 | 4.0 | 4.0 |
| expr.Expr.subExpr(Expr) | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Expr.sinshorten() | 53.0 | 6.0 | 17.0 | 19.0 |
| expr.Expr.sinExpr() | 2.0 | 1.0 | 2.0 | 2.0 |
| expr.Expr.shorten() | 54.0 | 6.0 | 18.0 | 20.0 |
| expr.Expr.powExpr(int) | 2.0 | 2.0 | 2.0 | 3.0 |
| expr.Expr.needBrackets(String) | 50.0 | 11.0 | 13.0 | 17.0 |
| expr.Expr.mulExpr(Expr) | 3.0 | 1.0 | 3.0 | 3.0 |
| expr.Expr.minusExpr() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expr.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.Expr(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.Expr(Expr, String) | 5.0 | 1.0 | 6.0 | 6.0 |
| expr.Expr.Expr(Expr, int, String) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expr.Expr(Expr, Expr, String) | 3.0 | 1.0 | 4.0 | 4.0 |
| expr.Expr.Expr(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.Expr() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.cosExpr() | 2.0 | 1.0 | 2.0 | 2.0 |
| expr.Expr.addTerm(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Expr.addOneBracket(String) | 26.0 | 7.0 | 8.0 | 10.0 |
| expr.Expr.addExpr(Expr) | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Expr.addBrackets(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| Build.getExpr(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Build.Build(List, int) | 22.0 | 1.0 | 9.0 | 9.0 |
| Total | 309.0 | 70.0 | 156.0 | 171.0 |
| Average | 7.536585365853658 | 1.7073170731707317 | 3.8048780487804876 | 4.170731707317073 |
| Class | OCavg | OCmax | WMC |
| MainClass | 2.0 | 2.0 | 2.0 |
| expr.Term | 2.8125 | 16.0 | 45.0 |
| expr.Expr | 4.681818181818182 | 18.0 | 103.0 |
| Build | 5.0 | 9.0 | 10.0 |
| Total | 160.0 | ||
| Average | 3.902439024390244 | 11.25 | 40.0 |
2.4 bug分析与hack策略
由于采用了预解析模式,代码依然几乎没有bug,第三次作业由于忘记更换第三次官方包出现了一个解析上的bug;
依然采用黑盒hack策略,随机构造边界数据进行测试;发现同学们的bug主要集中在指数和系数的边界范围、三角函数的合并化简,
三角函数内嵌套括号的添加,以及sum函数的begin、end边界条件上;以后在测试自己的代码时也得多多构建边界数据,争取赢得圣杯战争,获得万能的刚波机(doge)。
三、架构设计体验
预解析模式的代码逻辑真的很简单,感觉主要难度在第一次作业从无到有的设计上;后续迭代开发较为顺利;
尝试过写一个自己的预解析,基本思路是依次识别每一个字符串优先度最低的运算符,并依此建树对表达式内容进行管理,可惜尚未成功。。
与其他同学交流过他们写一般模式不断重构代码的体验之后,我认为自己错过了一次宝贵的学习机会,偷懒真的不可取。。
四、心得体会
熬夜肝代码,最后成功AC的体验真的很有成就感;当然,因为前期偷懒到ddl就狂肝的行为真的不可取,还是得早作谋划;
研讨课的角色扮演很有趣,大家积极讨论的氛围也不错,有时确实需要有不同个性的同学来带动整体讨论氛围,一些他人的思路也给了我很大的启发;
经过一个月的调整,稍微适应了oo课的学习节奏,下次作业我一定能做的更好。

