
用solr做关键词检索功能
1、solr的版本
采用4.10.1的版本,目前solr已经更新到7.x的版本,且4.x版本后,solr升级较大。未采用最新版的原因是参考以前的代码(主要是调用solr-solrj-4.10.0.jar等jar包的api)和solr的core的xml文件配置。
2、solr的配置
(1) solr war包发布于jetty的webapps目录下

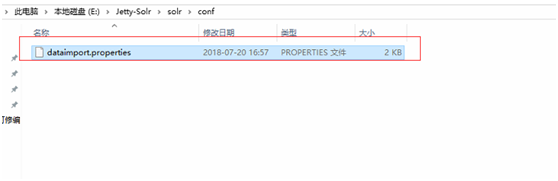
(2)solr core的配置文件放在jetty下
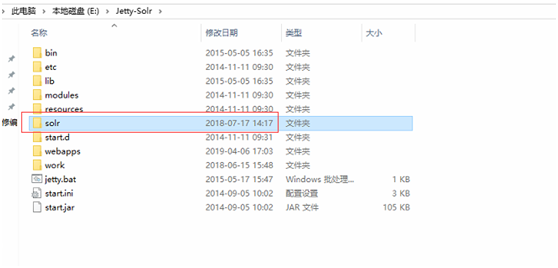
(3)core总体配置
#################################################
# #
# dataimport scheduler properties #
# #
#################################################
# to sync or not to sync
# 1 - active; anything else - inactive
syncEnabled=1
# which cores to schedule
# in a multi-core environment you can decide which cores you want syncronized
# leave empty or comment it out if using single-core deployment
syncCores=risk_source,risk_safe_activity,risk_patrol
# solr server name or IP address
# [defaults to localhost if empty]
server=localhost
# solr server port
# [defaults to 80 if empty]
port=1003
# application name/context
# [defaults to current ServletContextListener's context (app) name]
webapp=solr
# URL params [mandatory]
# remainder of URL
params=/dataimport?command=delta-import&clean=false&commit=true
# schedule interval
# number of minutes between two runs
# [defaults to 30 if empty]
# 增量索引的时间间隔,单位分钟
# 为空,为0,或者注释掉:表示永不增量索引
interval=2
# 重做索引的时间间隔,单位分钟,默认7200,即5天;
# 为空,为0,或者注释掉:表示永不重做索引
#reBuildIndexInterval=2
# 重做索引的参数
#reBuildIndexParams=/dataimport?command=full-import&clean=false&commit=true
# 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000;
# 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期
#reBuildIndexBeginTime=03:10:00
(4)从mysql导入数据类型的core配置


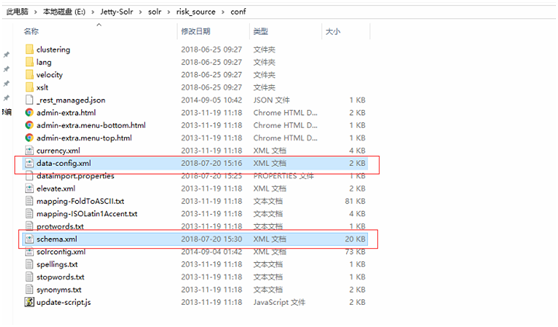

<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/risk" user="root" password="123456" />
<document>
<entity name="risk_source" query="select t.deptid,t.parentid,t.deviceid,t.devicename,t.devicetype,t.position,t.lng,t.lat,t.devicegrade,t.remark,t.importance,t.maintain,t.weight,t.picspath,t.qrcodeid,d.DEPTNAME,t.responsible_org,c.cat_name from tdevice t left join eadept d on t.deptid=d.DEPTID left JOIN risk_device_category c on t.device_category = c.uuid where t.devicetype is not null"
deltaQuery="select deviceid from tdevice where updatetime > '${dataimporter.last_index_time}'"
deltaImportQuery="select t.deptid,t.parentid,t.deviceid,t.devicename,t.devicetype,t.position,t.lng,t.lat,t.devicegrade,t.remark,t.importance,t.maintain,t.weight,t.picspath,t.qrcodeid,d.DEPTNAME,t.responsible_org,c.cat_name from tdevice t left join eadept d on t.deptid=d.DEPTID left JOIN risk_device_category c on t.device_category = c.uuid where t.devicetype is not null and t.deviceid='${dataimporter.delta.deviceid}'"
>
<field column="deptid" name="deptid" />
<field column="parentid" name="parentid" />
<field column="deviceid" name="deviceid" />
<field column="devicename" name="devicename" />
<field column="devicetype" name="devicetype" />
<field column="position" name="position" />
<field column="lng" name="lng" />
<field column="lat" name="lat" />
<field column="devicegrade" name="devicegrade" />
<field column="remark" name="remark" />
<field column="importance" name="importance" />
<field column="maintain" name="maintain" />
<field column="weight" name="weight" />
<field column="picspath" name="picspath" />
<field column="qrcodeid" name="qrcodeid" />
<field column="DEPTNAME" name="deptname" />
<field column="responsible_org" name="responsible_org" />
<field column="cat_name" name="cat_name" />
</entity>
</document>
</dataConfig>

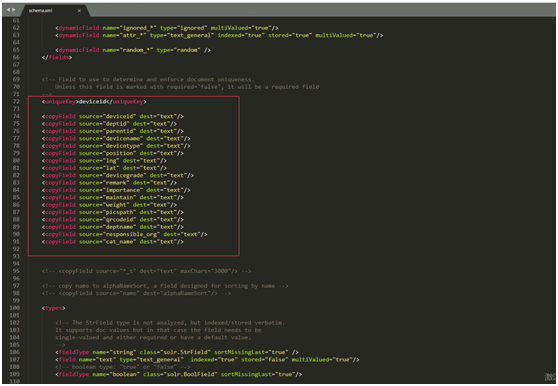
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="risk_source" version="1.5">
<fields>
<!-- _version_字段不能少 -->
<field name="_version_" type="long" indexed="true" stored="true"/>
<!-- 数据 -->
<field name="deptid" type="string" indexed="true" stored="true" multiValued="false" required="false" />
<field name="parentid" type="string" indexed="true" stored="true" multiValued="false" required="false" />
<field name="deviceid" type="string" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="devicename" type="text_ik" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="devicetype" type="string" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="position" type="text_ik" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="lng" type="double" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="lat" type="double" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="devicegrade" type="int" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="remark" type="text_ik" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="importance" type="tint" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="maintain" type="tint" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="weight" type="float" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="picspath" type="string" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="qrcodeid" type="string" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="deptname" type="text_ik" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="responsible_org" type="string" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="cat_name" type="text_ik" indexed="true" stored="true" multiValued="false" required="false"/>
<!-- text字段不能少 -->
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
<dynamicField name="*_i" type="int" indexed="true" stored="true"/>
<dynamicField name="*_is" type="int" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_ss" type="string" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_l" type="long" indexed="true" stored="true"/>
<dynamicField name="*_ls" type="long" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_t" type="text_general" indexed="true" stored="true"/>
<dynamicField name="*_txt" type="text_general" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_en" type="text_en" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_b" type="boolean" indexed="true" stored="true"/>
<dynamicField name="*_bs" type="boolean" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_f" type="float" indexed="true" stored="true"/>
<dynamicField name="*_fs" type="float" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_d" type="double" indexed="true" stored="true"/>
<dynamicField name="*_ds" type="double" indexed="true" stored="true" multiValued="true"/>
<!-- Type used to index the lat and lon components for the "location" FieldType -->
<dynamicField name="*_coordinate" type="tdouble" indexed="true" stored="false" />
<dynamicField name="*_dt" type="date" indexed="true" stored="true"/>
<dynamicField name="*_dts" type="date" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_p" type="location" indexed="true" stored="true"/>
<!-- some trie-coded dynamic fields for faster range queries -->
<dynamicField name="*_ti" type="tint" indexed="true" stored="true"/>
<dynamicField name="*_tl" type="tlong" indexed="true" stored="true"/>
<dynamicField name="*_tf" type="tfloat" indexed="true" stored="true"/>
<dynamicField name="*_td" type="tdouble" indexed="true" stored="true"/>
<dynamicField name="*_tdt" type="tdate" indexed="true" stored="true"/>
<dynamicField name="*_pi" type="pint" indexed="true" stored="true"/>
<dynamicField name="*_c" type="currency" indexed="true" stored="true"/>
<dynamicField name="ignored_*" type="ignored" multiValued="true"/>
<dynamicField name="attr_*" type="text_general" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="random_*" type="random" />
</fields>
<!-- Field to use to determine and enforce document uniqueness.
Unless this field is marked with required="false", it will be a required field
-->
<uniqueKey>deviceid</uniqueKey>
<copyField source="deviceid" dest="text"/>
<copyField source="deptid" dest="text"/>
<copyField source="parentid" dest="text"/>
<copyField source="devicename" dest="text"/>
<copyField source="devicetype" dest="text"/>
<copyField source="position" dest="text"/>
<copyField source="lng" dest="text"/>
<copyField source="lat" dest="text"/>
<copyField source="devicegrade" dest="text"/>
<copyField source="remark" dest="text"/>
<copyField source="importance" dest="text"/>
<copyField source="maintain" dest="text"/>
<copyField source="weight" dest="text"/>
<copyField source="picspath" dest="text"/>
<copyField source="qrcodeid" dest="text"/>
<copyField source="deptname" dest="text"/>
<copyField source="responsible_org" dest="text"/>
<copyField source="cat_name" dest="text"/>
<!-- <copyField source="*_t" dest="text" maxChars="3000"/> -->
<!-- copy name to alphaNameSort, a field designed for sorting by name -->
<!-- <copyField source="name" dest="alphaNameSort"/> -->
<types>
<!-- The StrField type is not analyzed, but indexed/stored verbatim.
It supports doc values but in that case the field needs to be
single-valued and either required or have a default value.
-->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
<!-- boolean type: "true" or "false" -->
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<!--
Default numeric field types. For faster range queries, consider the tint/tfloat/tlong/tdouble types.
These fields support doc values, but they require the field to be
single-valued and either be required or have a default value.
-->
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="tint" class="solr.TrieIntField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tfloat" class="solr.TrieFloatField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tlong" class="solr.TrieLongField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tdouble" class="solr.TrieDoubleField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/>
<!-- A Trie based date field for faster date range queries and date faceting. -->
<fieldType name="tdate" class="solr.TrieDateField" precisionStep="6" positionIncrementGap="0"/>
<!--Binary data type. The data should be sent/retrieved in as Base64 encoded Strings -->
<fieldtype name="binary" class="solr.BinaryField"/>
<!--
Note:
These should only be used for compatibility with existing indexes (created with lucene or older Solr versions).
Use Trie based fields instead. As of Solr 3.5 and 4.x, Trie based fields support sortMissingFirst/Last
Plain numeric field types that store and index the text
value verbatim (and hence don't correctly support range queries, since the
lexicographic ordering isn't equal to the numeric ordering)
-->
<fieldType name="pint" class="solr.IntField"/>
<fieldType name="plong" class="solr.LongField"/>
<fieldType name="pfloat" class="solr.FloatField"/>
<fieldType name="pdouble" class="solr.DoubleField"/>
<fieldType name="pdate" class="solr.DateField" sortMissingLast="true"/>
<fieldType name="random" class="solr.RandomSortField" indexed="true" />
<!-- A text field that only splits on whitespace for exact matching of words -->
<fieldType name="text_ws" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
<!-- A general text field that has reasonable, generic
cross-language defaults: it tokenizes with StandardTokenizer,
removes stop words from case-insensitive "stopwords.txt"
(empty by default), and down cases. At query time only, it
also applies synonyms. -->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- A text field with defaults appropriate for English: it
tokenizes with StandardTokenizer, removes English stop words
(lang/stopwords_en.txt), down cases, protects words from protwords.txt, and
finally applies Porter's stemming. The query time analyzer
also applies synonyms from synonyms.txt. -->
<fieldType name="text_en" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<!-- Case insensitive stop word removal.
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<!-- Optionally you may want to use this less aggressive stemmer instead of PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<!-- Optionally you may want to use this less aggressive stemmer instead of PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_en_splitting" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<!-- Case insensitive stop word removal.
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Less flexible matching, but less false matches. Probably not ideal for product names,
but may be good for SKUs. Can insert dashes in the wrong place and still match. -->
<fieldType name="text_en_splitting_tight" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1" catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<!-- this filter can remove any duplicate tokens that appear at the same position - sometimes
possible with WordDelimiterFilter in conjuncton with stemming. -->
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
<!-- 中文分词 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!-- Just like text_general except it reverses the characters of
each token, to enable more efficient leading wildcard queries. -->
<fieldType name="text_general_rev" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ReversedWildcardFilterFactory" withOriginal="true"
maxPosAsterisk="3" maxPosQuestion="2" maxFractionAsterisk="0.33"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- charFilter + WhitespaceTokenizer -->
<!--
<fieldType name="text_char_norm" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
-->
<!-- This is an example of using the KeywordTokenizer along
With various TokenFilterFactories to produce a sortable field
that does not include some properties of the source text
-->
<fieldType name="alphaOnlySort" class="solr.TextField" sortMissingLast="true" omitNorms="true">
<analyzer>
<!-- KeywordTokenizer does no actual tokenizing, so the entire
input string is preserved as a single token
-->
<tokenizer class="solr.KeywordTokenizerFactory"/>
<!-- The LowerCase TokenFilter does what you expect, which can be
when you want your sorting to be case insensitive
-->
<filter class="solr.LowerCaseFilterFactory" />
<!-- The TrimFilter removes any leading or trailing whitespace -->
<filter class="solr.TrimFilterFactory" />
<filter class="solr.PatternReplaceFilterFactory"
pattern="([^a-z])" replacement="" replace="all"
/>
</analyzer>
</fieldType>
<fieldtype name="phonetic" stored="false" indexed="true" class="solr.TextField" >
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.DoubleMetaphoneFilterFactory" inject="false"/>
</analyzer>
</fieldtype>
<fieldtype name="payloads" stored="false" indexed="true" class="solr.TextField" >
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.DelimitedPayloadTokenFilterFactory" encoder="float"/>
</analyzer>
</fieldtype>
<!-- lowercases the entire field value, keeping it as a single token. -->
<fieldType name="lowercase" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
<!--
Example of using PathHierarchyTokenizerFactory at index time, so
queries for paths match documents at that path, or in descendent paths
-->
<fieldType name="descendent_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.PathHierarchyTokenizerFactory" delimiter="/" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory" />
</analyzer>
</fieldType>
<!--
Example of using PathHierarchyTokenizerFactory at query time, so
queries for paths match documents at that path, or in ancestor paths
-->
<fieldType name="ancestor_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.PathHierarchyTokenizerFactory" delimiter="/" />
</analyzer>
</fieldType>
<!-- since fields of this type are by default not stored or indexed,
any data added to them will be ignored outright. -->
<fieldtype name="ignored" stored="false" indexed="false" multiValued="true" class="solr.StrField" />
<fieldType name="point" class="solr.PointType" dimension="2" subFieldSuffix="_d"/>
<!-- A specialized field for geospatial search. If indexed, this fieldType must not be multivalued. -->
<fieldType name="location" class="solr.LatLonType" subFieldSuffix="_coordinate"/>
<fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType"
geo="true" distErrPct="0.025" maxDistErr="0.000009" units="degrees" />
<fieldType name="currency" class="solr.CurrencyField" precisionStep="8" defaultCurrency="USD" currencyConfig="currency.xml" />
<!-- some examples for different languages (generally ordered by ISO code) -->
</types>
</schema>
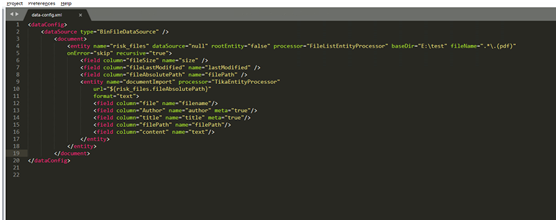
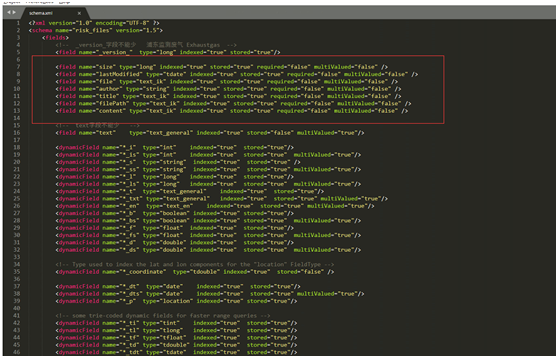
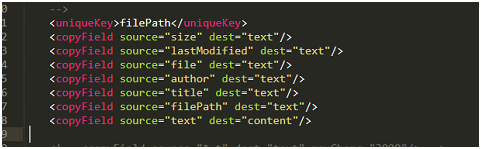
(5)从文件导入的core
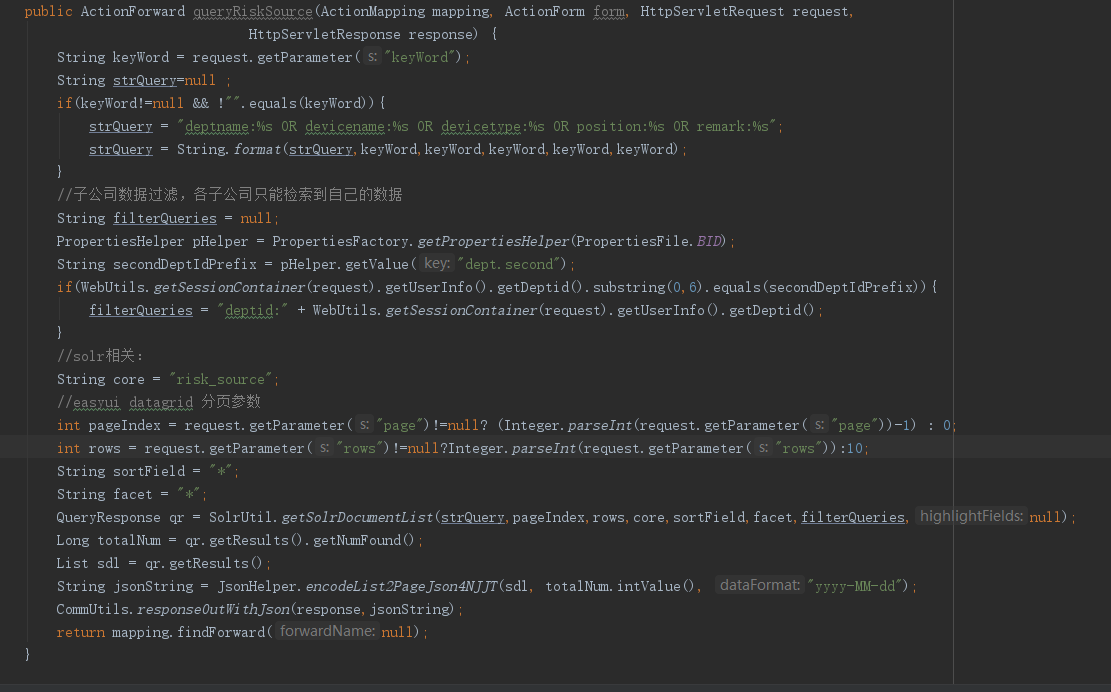
3、solr的检索语法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号