
个人项目作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目作业 |
| 这个作业的目标 | 设计一个论文查重算法,通过练习进行学习 |
1.本次作业github链接:点击此处跳转至Github
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 40 |
| Estimate | 估计这个任务需要多少时间 | 30 | 35 |
| Development | 开发 | 260 | 390 |
| Analysis | 需求分析(包括学习新技术) | 90 | 160 |
| Design Spec | 生成设计文档 | 60 | 130 |
| Design Review | 设计复审 | 35 | 50 |
| Coding Standard | 代码规范(为目前的开发指定合适的规范) | 30 | 65 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 120 | 320 |
| Code Review | 代码复审 | 45 | 110 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 300 |
| Reporting | 报告 | 60 | 140 |
| Test Report | 测试报告 | 40 | 55 |
| Size Measurement | 计算工作量 | 40 | 20 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 30 | 30 |
| 合计 | 1060 | 1925 |
3.写在前面
- 编程语言:JAVA
- IDEA版本:IntelliJ IDEA Community Edition 2020.2.4
- 项目构建工具:maven
- 单元测试工具:JUnitGenerator V2.0
- 性能分析工具:JProfiler
4.计算模块接口部分的设计与实现过程
1.设计
-
1.1 整体设计

-
1.2 类
Main:main 方法所在的类
TxtIO:读写 txt 文件的工具类
SimHash:计算 SimHash 值的类
Hamming:计算海明距离的类
ShortStringException:处理文本内容过短的异常类 -
1.3 各类使用的方法
-
1.3.1 TxtIO
包含了两个静态方法:
1、readTxt:读取txt文件
2、writeTxt:写入txt文件 -
1.3.2 SimHash
包含了两个静态方法:
1、getHash:传入String,计算出它的hash值,并以字符串形式输出,(使用了MD5获得hash值)
2、getSimHash:传入String,计算出它的simHash值,并以字符串形式输出,(需要调用 getHash 方法) -
1.3.3 Hamming
包含了两个静态方法:
1、getHammingDistance:输入两个 simHash 值,计算出其海明距离 distance
2、getSimilarity:输入两个 simHash 值,调用 getHammingDistance 方法得出海明距离 distance,再由 distance 计算出相似度。
2.关键算法:
①Simhash算法
- 该算法主要原理:
simhash是由 Charikar 在2002年提出来的,参考 《Similarity estimation techniques from rounding algorithms》 。
介绍下这个算法主要原理,为了便于理解尽量不使用数学公式,分为这几步:
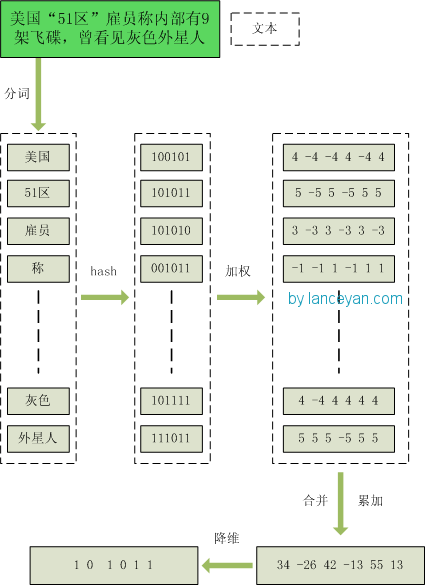
1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
整个过程图为:
- 该算法的优势:
SimHash是一种局部敏感hash,它也是Google公司进行海量网页去重使用的主要算法。
传统的Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。传统的hash算法产生的两个签名,如果原始内容在一定概率下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别很大。所以传统的Hash是无法在签名的维度上来衡量原内容的相似度,而SimHash本身属于一种局部敏感哈希算法,它产生的hash签名在一定程度上可以表征原内容的相似度。
我们主要解决的是文本相似度计算,要比较的是两个文章是否相似,当然我们降维生成了hash签名也是用于这个目的。看到这里估计大家就明白了,我们使用的simhash就算把文章中的字符串变成 01 串也还是可以用于计算相似度的,而传统的hash却不行。
我们可以来做个测试,两个相差只有一个字符的文本串,“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通过传统hash计算为:
0001000001100110100111011011110
1010010001111111110010110011101
通过上面的例子我们可以很清晰的发现simhash的局部敏感性,相似文本只有部分01变化,而hash值很明显,即使变化很小一部分,也会相差很大。
参照文章:NLP点滴——文本相似度
②Hamming distance算法
两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。对于二进制字符串的a和b,海明距离为等于在a XOR b运算结果中1的个数(普遍算法)。
因此,我们通过海明距离(Hamming distance)就可以计算出两个simhash到底相似不相似。
5.计算模块接口部分的性能改进
- 性能分析如下:
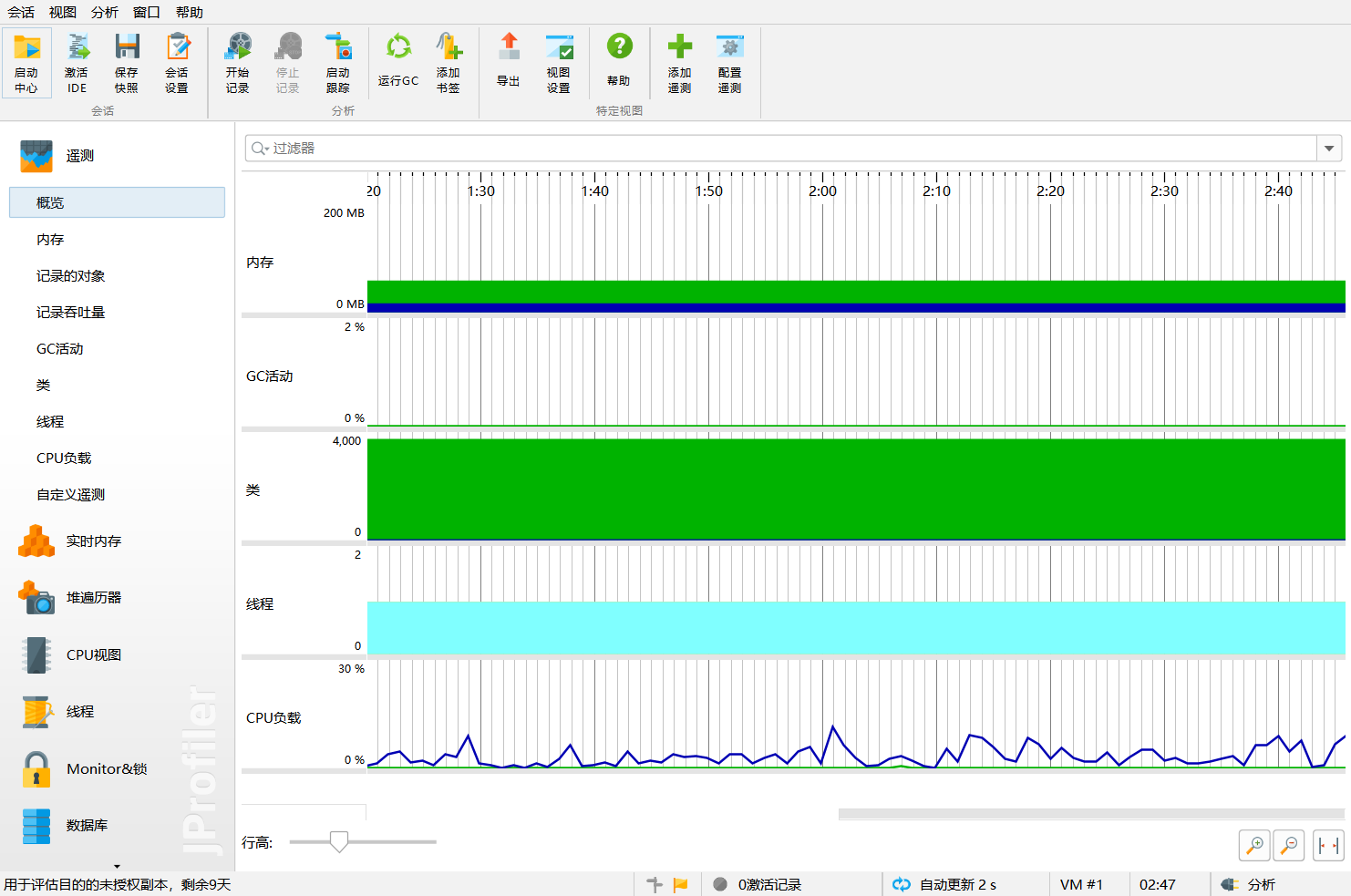
- 实时内存为:
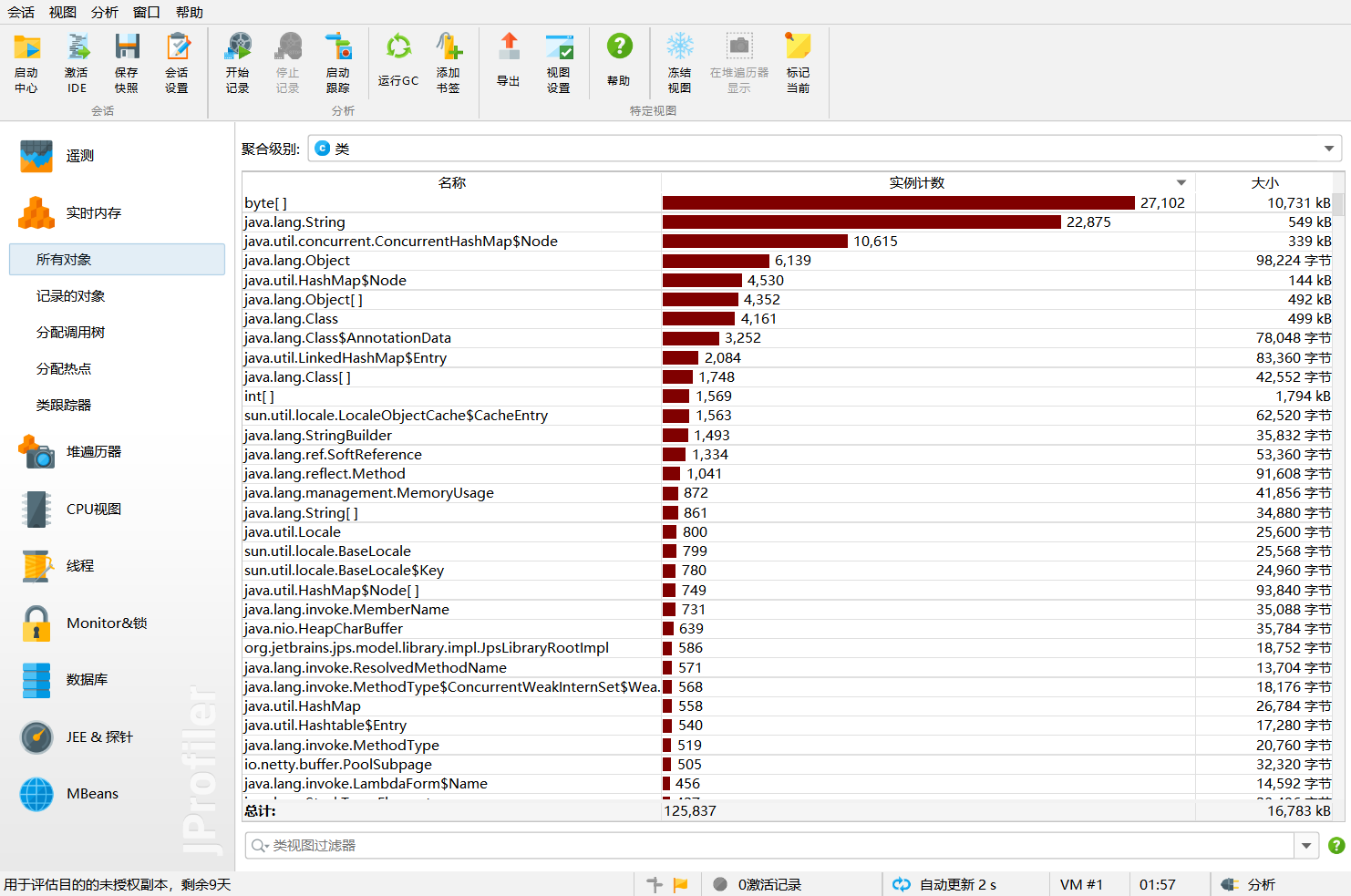
- 从分析图可看出:
调用次数最多的是com.hankcs.hanlp包提供的接口, 即分词、取关键词与计算词频花费了最多的时间。
很遗憾,目前我能力有限,无法改进。
6.计算模块部分单元测试展示
-
mainTest:

-
TxtIOTest:

-
HammingTest:

-
SimHashTest:

-
ShortStringExceptionTest:

7.计算模块部分异常处理说明
待补充。
8.总结
1.实现设计的过程比预想更加艰难,也在实现的过程中发现了设计时存在的问题,导致不断更改。
2.由于一开始建工程时忘记选择maven导致做了很多无用功。
3.当出现无法解决但不应出现的问题时,应从头溯源,是否遗漏某些信息或操作失误。

