

任务
利用这里数据: 2020新冠肺炎记忆:报道、非虚构与个人叙述(持续更新)
结合下面文章中用到的方法 [ 以虎嗅网4W+文章的文本挖掘为例,展现数据分析的一整套流程 ](http://www.woshipm.com/data-
analysis/873430.html)完成描述性分析(发文数量、发文时间、相关性分析、城市提及分析)
文本挖掘(关键词提取、lda主题模型、情绪分析、词云绘制)、知识图谱构建等任务
一、数据采集
从 2020新冠肺炎记忆:报道、非虚构与个人叙述(持续更新)
这篇文章中进行数据获取,本人采取的方法是利用爬虫,获取该文章页面,获取所列文章列表及其原文链接,进而通过链接获取文章具体内容。截至2020-2-17我获取的链接数1351个,分析知道,这些链接主要来源于:微信公众号、财经网、经济观察网、方方博客、中国经营网专题、界面网,1351个链接中来自这几个网站文章数量为1324个,其余的只有27个,不到2%,直接舍弃。于是利用爬虫分别从链接对应网站获取文章内容,并整理到excel中。

代码见附录中:t1.py
二、数据处理
1.数据清洗
将第一部分中采集的excel中的空行删除,获得可以利用的1285行数据。
2.文本分词
利用Jieba的精确模式进行文本内容的分词处理,并利用已有的停留词进行无关词过滤,最后将处理好的词存入文件中。
代码见附录中:t2.py
三、数据分析
1、描述性分析
1.1 发文数量、来源和发文日期
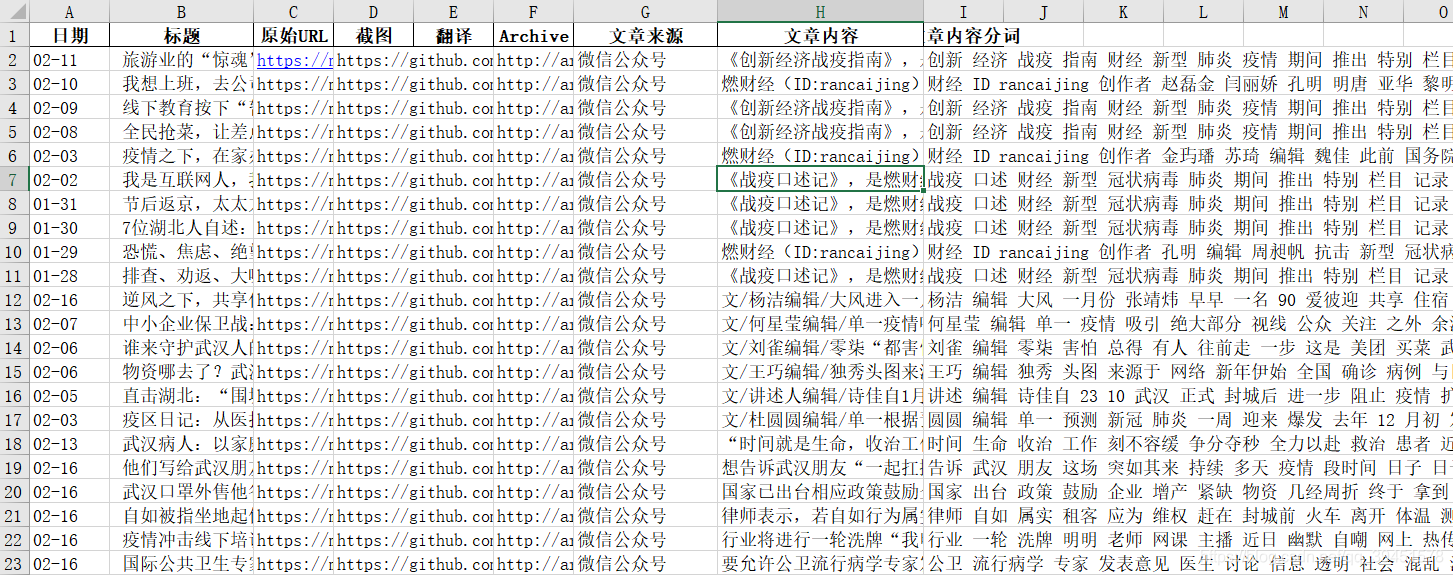
从下图可以看出,统计的文章数量从1月6号到1月28号逐步增加,之后至今保持相对稳定,均值在40篇左右。此外可以看出每日文章的来源,可以很明显的看出文章基本上都来自微信公众号,由此可以看出微信公众号在新媒体传播途径中的重要地位。
1.2 城市提及分析
首先根据全国1-5线城市利用百度接口查询其对应的经纬度,并构建单词表,根据前文整理的文章内容进行分词处理,并统计文中各个城市提及的次数,利用这些数据结合
folium
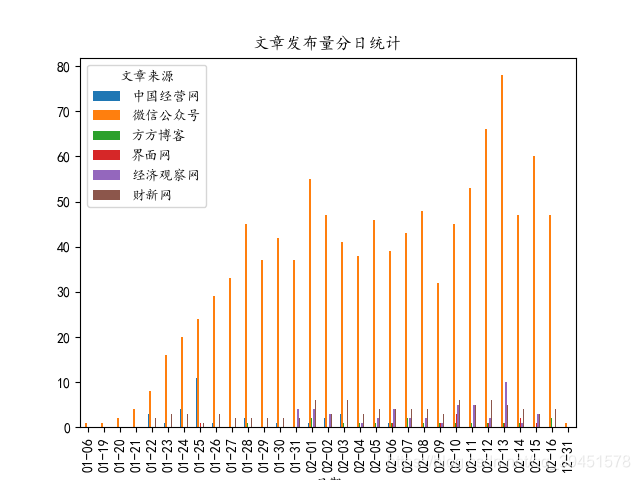
工具,绘制了城市提及频次的地理分布地图(即下图),由图可以清晰的看出祖国各大城市基本都有提及到,这也说明了此次疫情已经蔓延至全国各地,从图中还可以看出颜色最深的地方是湖北武汉市,这也印证了武汉是此次疫情的爆发中心,在各个网站的报导文章中频繁出现。
本文除了对城市进行了以上处理外,还进行了文本中城市之间共现关系的分析,通过对每篇文章中城市提及的处理,统计了每篇文章中各个城市共同出现的频率,获得了两个文件:city_node.csv和city_edge.csv文件,再利用
gephi
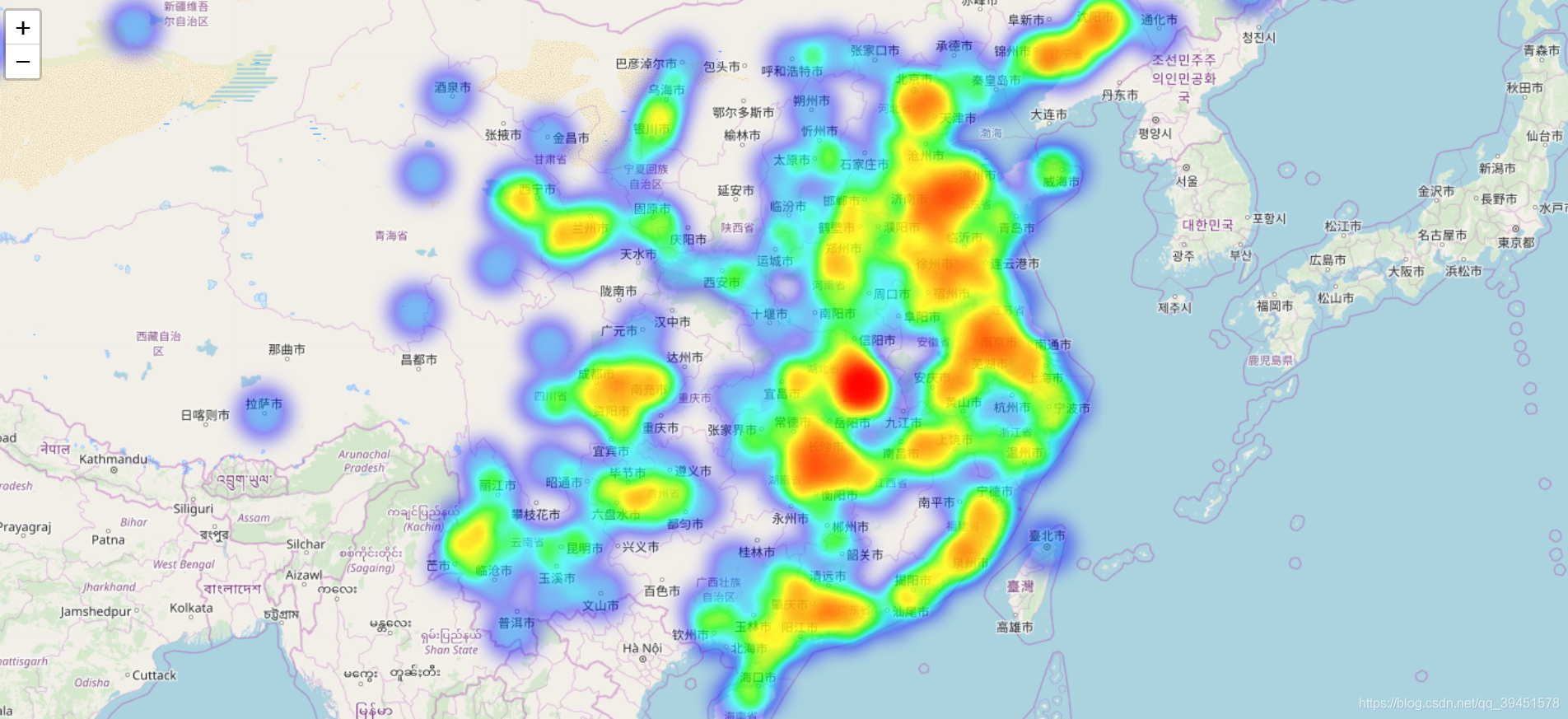
进行共现关系图的绘制,得到如下图片,通过图片可以清晰的看出,每个城市基本都与武汉市有连线,也就是说提及那些城市的同时,也提及了武汉。同时节点的大小也同时反应了城市提及的次数,再一次与上面的热力分布图呼应,武汉是提及最多的城市,依然反应了武汉是这次疫情中舆论的中心。
相关代码:dataAnalysis.py
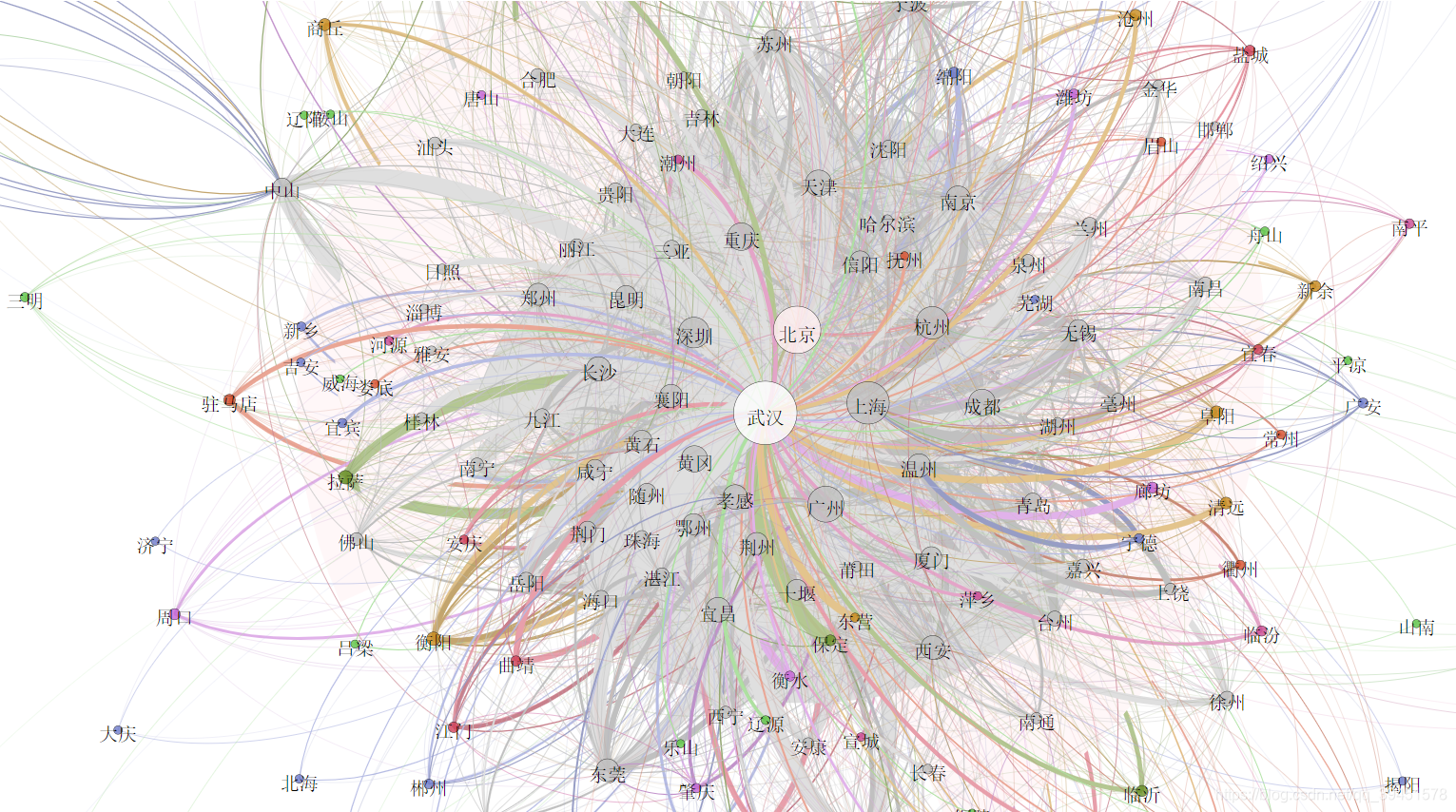
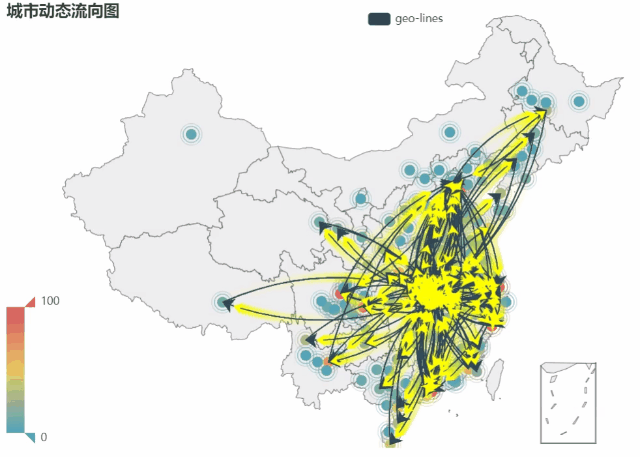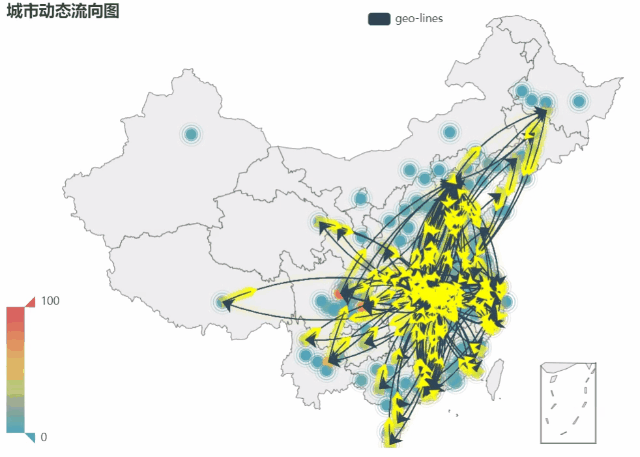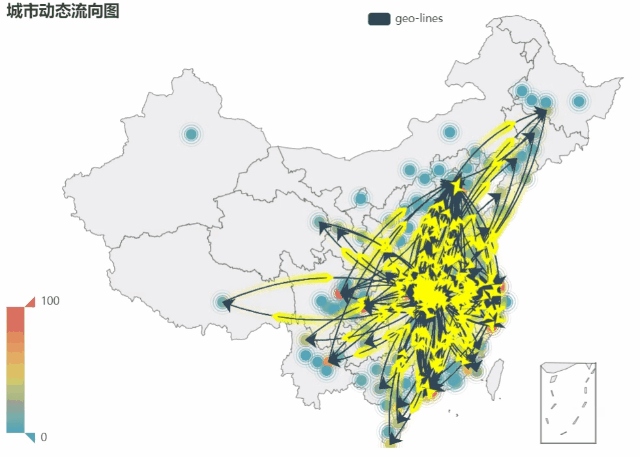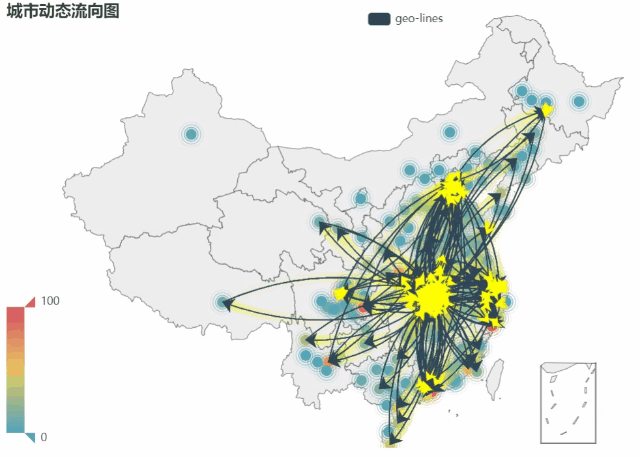
利用以上数据,绘制了城市动态流向图, 动态图(GIF)制作方法
,获得下图,可以看出大部分城市直接的相互关系,并且可以看出流动量大、交错密集的区域无疑是武汉,这样表现了武汉是这个舆论的中心。对于孤立的点,表明的是这个城市是在报道中单独出现。
绘图代码:t3.py
2、文本挖掘
2.1 关键词提取
一般关键词提取可以采用两种方法,通常采用词频较高的词作为关键词,但是词频并不一点代表该词很重要,故本人采取的是另一种方法,根据TF-
IDF(termfrequency–inverse document frequency)来提取关键词,
TF-IDF是一种 统计方法
,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在 语料库
中出现的频率成反比下降。TF-
IDF加权的各种形式常被 搜索引擎
应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-
IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
因此可以看出TF-
IDF更能体现一个词的重要性,以此作为提取关键词的依据相对而言更为合理,当然由于实际问题,直接使用会导致人名优先出现,缺乏分析的准确性,可以通过调整TfidfVectorizer函数的min_df参数(本文采用的值是0.023),对模型进行一定程度调整,最终将获取的结果按TF-
IDF值进行排序,下面展示排行前100的关键词:
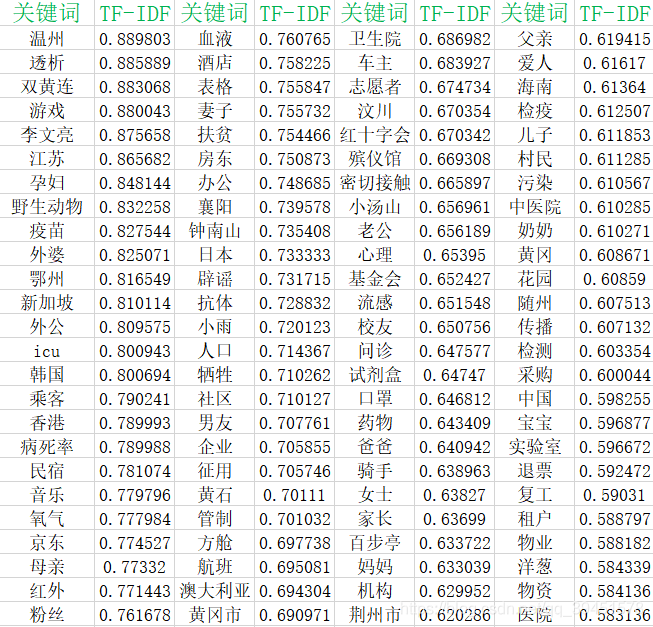
通过以上关键词可以看出内容主要分为如下几个方面:
- 城市地点类:温州、江苏、鄂州、新加坡、韩国、香港、襄阳等;
- 医疗相关类:透析、双黄连、疫苗、病死率、氧气、血液、抗体等;
- 人物相关类:李文亮、孕妇、外婆、外公、乘客、母亲、粉丝等
从中我们可以看出这些文章报道了各地疫情、治疗的现状和方法、药物等,同时由于素材包括很多病人自述,所以出现大量人物相关词汇,包括医生以及任务称呼等。
此外,笔者选取TOP500关键词来绘制关键词云。

代码见附录:TF-IDF.py
2.2 LDA主题模型分析
上面只对每篇文章进行了关键词提取,并未考虑整体文章的内容,下面将采用LDA主题模型对文章数据进行主题提取。实际操作中是利用sk-
learn中的LatentDirichletAllocation()函数进行实现的,其中指定的类别经多次尝试发现设置为4类结果较好,并提取了四个主题的权重前20的主题词,整理的结果为下图:
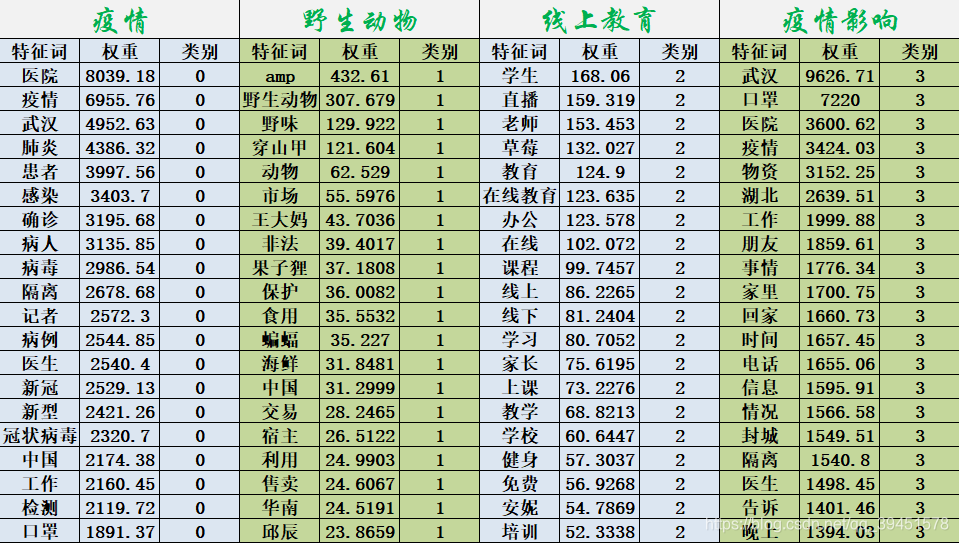
通过上面的结果可以看出1285篇文章虽然都是讲本次新冠状病毒相关的,但是可以具体分为如下四个类别:
- 疫情相关:主要介绍当前疫情的现状:包括病毒介绍、病例数量、医患人员等内容。
- 野生动物:主要介绍的是与此次疫情有密切关系的野生动物问题,目前普遍认为病毒是从野生动物传播到人体的,所以此段时间野生动物、海鲜、野生动物市场、相关交易等备受人们关注。
- 在线教育:由于受到此次疫情影响,学校、公司等大规模推迟开学、上班时间,但是在停课不停学的号召下,线上教育在此次疫情中发挥的淋漓尽致,从小学、初中、高中一直到大学,目前都已经开始在实行线上教育了,所以此次线上教育在教育事业中起到了前所未有的巨大作用,也成为了不少媒体关注的焦点。
- 疫情影响:这部分主题主要突出了疫情产生的一些相关影响,导致口罩物资等严重紧缺,湖北武汉率先封城,同时也导致许多相关接触人员收到医学观察和隔离。
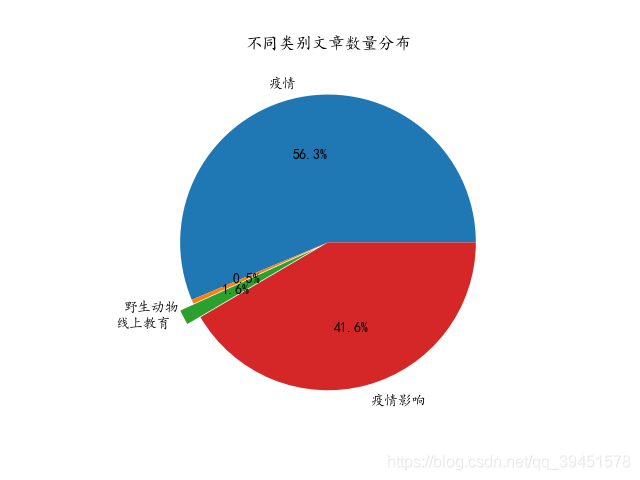
统计每个主题类别的文章占比,得到如下图,可以看到关于疫情描述的文章占比最多,达到了56.3%,其次则为疫情影响类别的文章,占比41.6%,而线上教育和野生动物相关的占比都较少,分别占1.6%和0.5%。
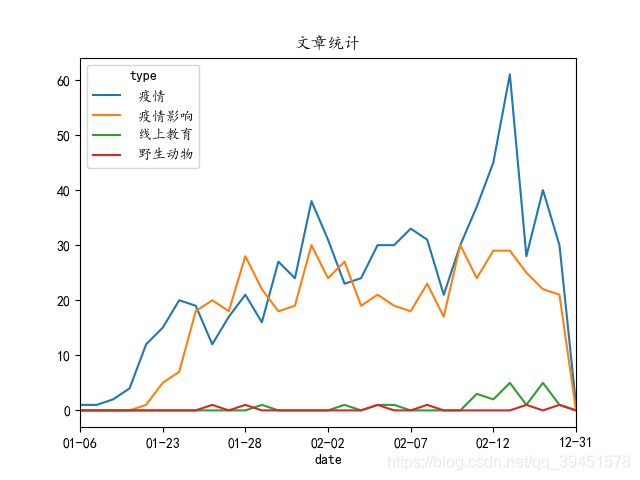
下面再结合了时间对不同类别的数据进行了统计和分析,得到下图,可以看出整体文章整体呈现先升后降趋势,与上面相同,依然是疫情类别和疫情影响类别占了文章的大部分,但是通过这个图可以看出的是,随着时间的推前和往年开学日期的到来,线上教育的文章开始逐步增加,可以预见在疫情还未完全结束前,线上教育将会使用的越来越广泛,在文章中的提及度也会提高。
代码附录:LDA_主题模型.py
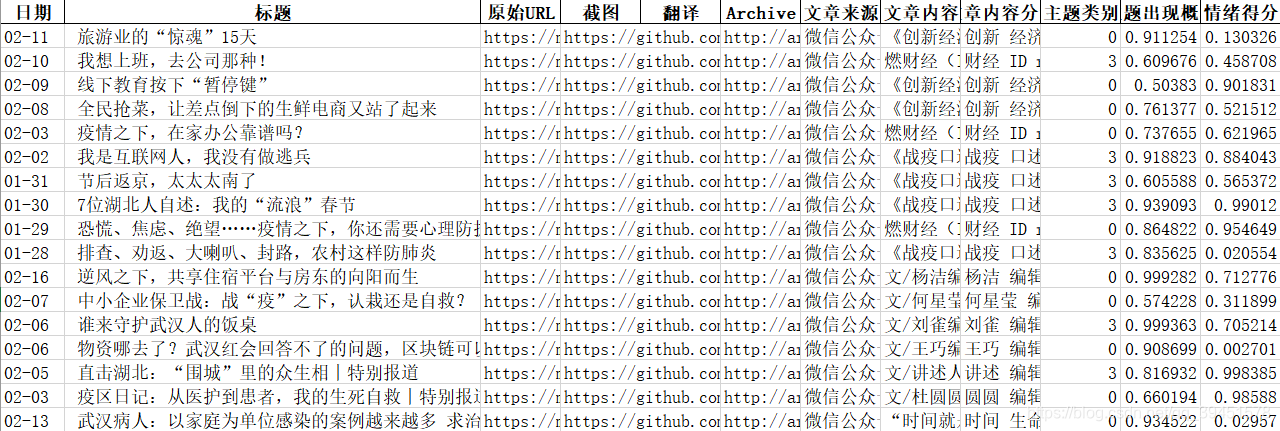
2.3 情感分析
本文接着对主题分类之后又对原有标题进行了情感打分,利用的是snownlp库进行打分,获得的分数区间为[0,1],其中分数越接近1越积极,越接近0越消极,获得结果如下图:
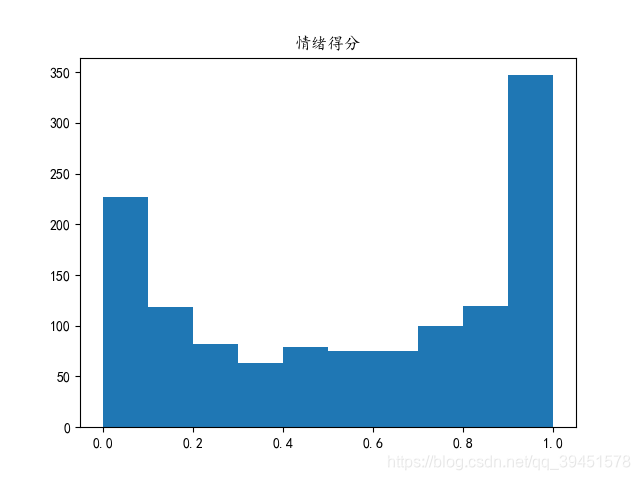
对所有文章的情感得分进行了分析,得到如下图片,有图片可以看出大部分文章标题都是比较积极的态度,然而消极的也有不少。
代码见附录:Snownlp情感分析.py
3、结束语
通过对关于这次疫情的样本文档的分析,可以看出人们对疫情的持续关注,报道文章不断增加,文章涉及的城市主要以武汉为主,并涵盖全国各地城市,主要报导的主题也是绕疫情相关的,包括疫情以及由其推动的线上教育等等,对于疫情的报导态度,大部分分章都是表达的都是比较积极的态度。
附录:
t1.py:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/12 13:02
# @Author : ystraw
# @Site :
# @File : t1.py
# @Software: PyCharm Community Edition
# @function: 从github指定链接中进行数据获取
# 获取链接后,根据链接的不同来源,进行不同网页的抓取文章内容
import requests
import time
import datetime
from bs4 import BeautifulSoup
from openpyxl import Workbook
import random
from lxml import etree
from openpyxl import load_workbook
import getIpPool
proxies = getIpPool.getproxies()
MAX_num = 15 # Ip取值范围
openFlag = 1 # 0关闭Ip代理,1开启Ip代理
outTime = 10 # 超时时间
# 写入文件:, 新建不追加:
def writeFile(filename, file):
with open(filename, 'w', encoding='utf-8') as f:
f.write(file)
print(filename, '已写入!')
f.close()
# 写入文件:, 新建追加:
def writeFile_add(filename, file):
with open(filename, 'a', encoding='utf-8') as f:
f.write(file)
print(filename, '已写入!')
f.close()
# 读入文件
def readFile(filename):
with open(filename, 'r', encoding='utf-8') as f:
str = f.read()
print(filename, '已读入!')
f.close()
return str
# 写入Excel
def write_excel_xls(path, sheet_name, value, bHead):
# 获取需要写入数据的行数
index = len(value)
# 获取需要写入数据的行数
index = len(value)
wb = Workbook()
# 激活 worksheet
ws = wb.active
# 第一行输入
ws.append(bHead)
# .cell(row=x, column=2, value=z.project)
for i in range(2, index+2):
for j in range(1, len(value[i-2]) + 1):
# ws.append(value[i])
ws.cell(row=i, column=j, value=value[i-2][j-1])
# 保存
wb.save(path)
print(path + '表格写入数据成功!')
# 采集github的文章链接
def getUrl(path, url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
html = requests.get(url, headers=headers, verify=False).text
# writeFile('data/top250.html', html)
# xpath:提取信息(标题)
text =etree.HTML(html)
trs = text.xpath('//div[@class="Box-body"]//tbody/tr/td[2]/text()')
# bs4: 提取信息:
bs = BeautifulSoup(html, 'lxml')
div = bs.findAll('div', attrs={'class': 'Box-body'})[0]
# print(div)
trList = div.findAll('tr')
# print(len(trList))
cnt = 0
# 全部数据
alldata = []
for tr in trList:
tds = tr.findAll('td')
if tds != []:
# 提取:日期,标题
tempList = [tds[0].string, trs[cnt]]
# 提取:【原始URL,截图,翻译,Archive】的链接
for i in range(2, 6):
astring = ''
aList = tds[i].findAll('a')
for a in aList:
astring += a['href'] + ','
tempList.append(astring.strip(','))
print(tempList)
alldata.append(tempList)
cnt += 1
tableHead = ['日期', '标题', '原始URL', '截图', '翻译', 'Archive']
write_excel_xls(path, 'link', alldata, tableHead)
# 提取微信文章
def getdetailContent_1(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# html = requests.get(url, timeout=10, headers=headers, verify=False).text
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@class="rich_media_content "])').replace(' ', '').replace('\n', '')
# print(context.replace(' ', '').replace('\n', ''))
return context
# 提取财经网
def getdetailContent_2(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# html = requests.get(url, timeout=10, headers=headers, verify=False).text
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@id="Main_Content_Val"])')
# print(context.replace(' ', '').replace('\n', ''))
# print('===============')
return context
# 经济观察网
def getdetailContent_3(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# 解决乱码
# html = requests.get(url, timeout=10, headers=headers, verify=False).text.encode('iso-8859-1')
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text.encode('iso-8859-1')
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text.encode('iso-8859-1')
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@class="xx_boxsing"])')
# print(context.replace(' ', '').replace('\n', ''))
# print('===============')
return context
# 方方博客
def getdetailContent_4(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# 解决乱码
# html = requests.get(url, timeout=10, headers=headers, verify=False).text
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@class="blog_content"])')
# print(context.replace(' ', '').replace('\n', ''))
# print('===============')
return context
# 中国经营网专题
def getdetailContent_5(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# 解决乱码
# html = requests.get(url, timeout=10, headers=headers, verify=False).text
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@class="contentleft auto"])')
# print(context.replace(' ', '').replace('\n', ''))
# print('===============')
return context
# 界面网
def getdetailContent_6(url):
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
]
agent = random.choice(ua_list)
headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://piaofang.maoyan.com/dashboard?movieId=1211270&date=2011-01-02",
"User-Agent": agent,
}
# url = 'https://www.amazon.com/b/ref=AE_HP_leftnav_automotive?_encoding=UTF8&ie=UTF8&node=2562090011&pf_rd_m=ATVPDKIKX0DER&pf_rd_s=merchandised-search-leftnav&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_r=PH0GKS39512064NYAJ2G&pf_rd_t=101&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_p=72757377-d3c0-4c64-a969-e12706417b85&pf_rd_i=17938598011'
print('请求地址:', url)
# 解决乱码
# html = requests.get(url, timeout=10, headers=headers, verify=False).text
global proxies
global openFlag
ip = proxies[random.randint(0, MAX_num if len(proxies) > MAX_num else len(proxies)-1)]
if openFlag == 1:
html = requests.get(url, timeout=outTime, headers=headers, proxies={ip[0]: ip[1]}, verify=False).text
# print(ip)
else:
html = requests.get(url, timeout=outTime, headers = headers, verify=False).text
# print(html)
text = etree.HTML(html)
context = text.xpath('string(//div[@class="article-content"])')
# print(context.replace(' ', '').replace('\n', ''))
# print('===============')
return context
# 从excel中获取
def getContent(path, savePath):
# 读取数据
wb = load_workbook(path)
sheet_names = wb.get_sheet_names()
table = wb.get_sheet_by_name(sheet_names[0]) # index为0为第一张表
nrows = table.max_row # 行
ncols = table.max_column # 列
print(nrows, ncols)
cnt = 0
alldata = []
for i in range(2, nrows+1):
templist = []
for j in range(1, ncols+1):
# print(table.cell(i, j).value)
templist.append(table.cell(i, j).value)
# 获取详情链接:
url = table.cell(i, 3).value.split(',')[0]
try:
if url[:24] == 'https://mp.weixin.qq.com':
# 微信公共号获取文章'
content = getdetailContent_1(url)
templist.append('微信公共号')
templist.append(content)
# print(content)
# pass
elif url[:24] == 'http://china.caixin.com/' or url[:22] == 'http://www.caixin.com/' or url[:25] == 'http://weekly.caixin.com/':
# 财新网获取文章
content = getdetailContent_2(url)
templist.append('财新网')
templist.append(content)
# print(content)
# pass
elif url[:22] == 'http://www.eeo.com.cn/':
# 经济观察网
# # print('经济观察网', table.cell(i, 3).value)
content = getdetailContent_3(url)
templist.append('经济观察网')
templist.append(content)
# print(content)
# pass
elif url[:32] == 'http://fangfang.blog.caixin.com/':
# 方方博客
content = getdetailContent_4(url)
templist.append('方方博客')
templist.append(content)
# print(content)
# pass
elif url[:21] == 'http://www.cb.com.cn/':
# # 中国经营网专题
content = getdetailContent_5(url)
templist.append('中国经营网')
templist.append(content)
# # print(content)
pass
elif url[:24] == 'https://www.jiemian.com/':
# 界面网
content = getdetailContent_6(url)
templist.append('界面网')
templist.append(content)
# print(content)
# pass
else:
# print('else', table.cell(i, 3).value, '===', table.cell(i, 2).value)
cnt += 1
# print(table.cell(i, 3).value, table.cell(i, 5).value)
alldata.append(templist)
except Exception as ex:
print('异常:', ex)
# if i >= 10:
# break
# time.sleep(random.randint(0, 2))
print('剔除的:', cnt)
tableHead = ['日期', '标题', '原始URL', '截图', '翻译', 'Archive','文章来源', '文章内容']
write_excel_xls(savePath, 'link', alldata, tableHead)
if __name__ == '__main__':
'''
第一步:获取链接
'''
# 数据地址
# url = 'https://github.com/2019ncovmemory/nCovMemory#%E7%AC%AC%E4%B8%80%E8%B4%A2%E7%BB%8Fyimagazine'
# # 保存文件路径:
# path = './data/all_text_2.xlsx'
# getUrl(path, url)
'''
第二步:通过链接提取文章内容
'''
# url = 'https://web.archive.org/web/20200204084331/http://www.caixin.com/2020-02-04/101511377.html'
# 读取链接文件地址:
path = './data/all_text_link_2.xlsx'
# 保存路径:
savePath = './data/text_0.xlsx'
getContent(path, savePath)
[/code]
t2.py:
```code
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/13 13:46
# @Author : ystraw
# @Site :
# @File : t2.py
# @Software: PyCharm Community Edition
# @function: 对t1获得的 alltext.xlsx 进行必要的处理
# 1、删除空行
import numpy
import pandas as pd
import jieba
# 读入文件
def readFile(filename):
with open(filename, 'r', encoding='utf-8') as f:
str = f.read()
print(filename, '已读入!')
f.close()
return str
# 删除空行
def dealNull(path, savepath):
data = pd.read_excel(path, sheet_name=0)
df = pd.DataFrame(data)
# print(data.head()) # 无参时默认读前五行
# print(data.tail()) # 无参时默认读后五行
print(data.shape) # 查看数据大小
print(data.columns) # 查看数据的列索引
# 数据表基本信息(维度、列名称、数据格式、所占空间等)
print(data.info())
# 每一列数据的格式
print('格式:\n', df.dtypes)
# 读取某列的某行数据
# df['文章内容'].astype('str')
# df['文章内容'] = df['文章内容'].map(str.strip)
# print(data['文章内容'].at[123])
# 读取表格数据内容(不包括标题)
# print(data.values)
# 判断每一行的文章内容是否为空
data_notnull = data['文章内容'].notnull()
# print(data_notnull)
# 删除空行
data_new = data[data_notnull]
# print(data_new)
print('删除空行之后的大小:\n', data_new.shape)
# 保存文件
data_new.to_excel(savepath, index=False, header=True)
# 分词并统计词频
def fenci(content):
# 读入停留词文件:
sword = readFile('./data/stopword.txt')
# 构建停留词词典:
sword = sword.split('\n')
worddict = {}
wordlist = []
for w in jieba.cut(content, cut_all=False): # cut_all=False为精确模式,=True为全模式
# print(w)
if (w not in sword) and w != '' and w != ' ' and w != None and w != '\n' and len(w) >= 2:
# print(w + '-')
wordlist.append(w)
try:
worddict[w] = worddict[w] + 1
except:
worddict[w] = 1
# print(worddict)
return [worddict, wordlist]
# 数据预处理
def preDeal(path, savepath):
# 读取数据
data = pd.read_excel(path, sheet_name=0)
df = pd.DataFrame(data)
# 加一列
df['文章内容分词'] = None
for i in range(df.shape[0]):
# 进行分词
rt = fenci(df['文章内容'].at[i])
df['文章内容分词'].at[i] = ' '.join(rt[1])
# 保存文件
df.to_excel(savepath, index=False, header=True)
if __name__ == '__main__':
'''
数据清洗
'''
# # 删除空行
# path = './data/text_0.xlsx'
# savepath = './data/text_1.xlsx'
# dealNull(path, savepath)
'''
数据预处理
'''
path = './data/text_1.xlsx'
savepath = './data/text_2.xlsx'
preDeal(path, savepath)
[/code]
t3.py:
```code
# 导入Geo包,注意1.x版本的导入跟0.x版本的导入差别
# 更新方法:pip install --upgrade pyecharts
from pyecharts.charts import Geo
# 导入配置项
from pyecharts import options as opts
# ChartType:图标类型,SymbolType:标记点类型
from pyecharts .globals import ChartType, SymbolType
# 读入文件
def readFile(filename):
with open(filename, 'r', encoding='utf-8') as f:
str = f.read()
print(filename, '已读入!')
f.close()
return str
geo = Geo()
# 新增坐标点,添加名称跟经纬度
# 读入城市坐标数据:
zb_city = readFile('./data/1-5LineCity_2.txt')
# geo.add_coordinate(name="China",longitude=104.195,latitude=35.675)
cityList = zb_city.split('\n')
for cy in cityList:
if cy == '' or cy == None:
continue
temp = cy.split(',')
geo.add_coordinate(name=temp[0], longitude=temp[2], latitude=temp[1])
# 地图类型,世界地图可换为world
geo.add_schema(maptype="china")
# 获取权重:
cityList = readFile('./data/city_node.csv').split('\n')
data = []
for i in range(len(cityList)):
city = cityList[i]
if i == 0 or city == '' or city == None:
continue
data.append((city.split(' ')[0], int(city.split(' ')[2])))
# print(data)
# 获取流向
cityList = readFile('./data/city_edge.csv').split('\n')
data2 = []
for i in range(len(cityList)):
city = cityList[i]
if i == 0 or city == '' or city == None:
continue
# 共现次数较少的不展示:
if int(city.split(' ')[2]) < 200:
continue
data2.append((city.split(' ')[0], city.split(' ')[1]))
# print(data2)
# 添加数据点
# geo.add("",[("北京",10),("上海",20),("广州",30),("成都",40),("哈尔滨",50)],type_=ChartType.EFFECT_SCATTER)
geo.add("", data, type_=ChartType.EFFECT_SCATTER)
# 添加流向,type_设置为LINES,涟漪配置为箭头,提供的标记类型包括 'circle', 'rect', 'roundRect', 'triangle',
#'diamond', 'pin', 'arrow', 'none'
geo.add("geo-lines",
data2,
type_=ChartType.LINES,
effect_opts=opts.EffectOpts(symbol=SymbolType.ARROW,symbol_size=10,color="yellow"),
linestyle_opts=opts.LineStyleOpts(curve=0.2),
is_large=True)
# 不显示标签
geo.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
# 设置图标标题,visualmap_opts=opts.VisualMapOpts()为左下角的视觉映射配置项
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(),title_opts=opts.TitleOpts(title="城市动态流向图"))
# 直接在notebook里显示图表
geo.render_notebook()
# 生成html文件,可传入位置参数
geo.render("城市动态流向图.html")
dataAnalysis.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/17 18:42
# @Author : ystraw
# @Site :
# @File : dataAnalysis.py
# @Software: PyCharm Community Edition
# @function: 进行数据分析
import folium
import codecs
from folium.plugins import HeatMap
from pyecharts.charts import Geo
from pyecharts.charts import Map
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 读入文件
def readFile(filename):
with open(filename, 'r', encoding='utf-8') as f:
str = f.read()
print(filename, '已读入!')
f.close()
return str
# 描述性分析
def ms_analysis(filepath):
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['font.serif'] = ['KaiTi']
# 读入数据
data = pd.read_excel(filepath)
'''
发文数量、来源和发文日期
'''
# 绘制文章发布量与日期及来源关系图:
# data.groupby('日期')['文章来源'].value_counts().unstack().fillna(value=0).plot(kind='bar', title='文章发布量分日统计')
# plt.show()
# return
'''
城市提及分析
'''
# 读入城市数据,构建城市字典:
city = readFile('./data/1-5LineCity_2.txt')
cityList = city.split('\n')
# print(cityList)
# 构建城市频率:
cityDict = {}
for cy in cityList:
if cy == '' or cy == None:
continue
temp = cy.split(',')
cityDict[temp[0][:-1]] = 0
# print(cityDict)
print(data.shape[0], data.shape[1])
# 进行统计
for i in range(data.shape[0]):
wordList = data['文章内容分词'].at[i].split(' ')
for word in wordList:
try:
cityDict[word] += 1
except:
pass
# break
print(cityDict)
# 绘制地图:
# 取字典中的值
# provice = list(cityDict.keys())
# values = list(cityDict.values())
# 填充数据
data = []
for cy in cityList:
if cy == '' or cy == None:
continue
temp = cy.split(',')
data.append([float(temp[1]), float(temp[2]), cityDict[temp[0][:-1]]])
# data=[[ 31.235929,121.480539, 1500 ]] #
print(data)
map_osm = folium.Map([33., 113.], zoom_start=12) #绘制Map,开始缩放程度是5倍
HeatMap(data).add_to(map_osm) # 将热力图添加到前面建立的map里
map_osm.save('./image/文章提及城市分布.html')#将绘制好的地图保存为html文件
# 得到城市共现矩阵文件
def city_gx_analysis(filepath):
citys = {} # 城市字典
relationships = {} # 关系字典
lineCitys = [] # 每篇城市关系
# 构建城市集合:
cityList = readFile('./data/1-5LineCity.txt').split('\n')
citySet = set()
for city in cityList:
citySet.add(city.replace('市', ''))
# 读入分词数据
data = pd.read_excel(filepath)
# 填充邻接矩阵
for i in range(data.shape[0]):
wordList = data['文章内容分词'].at[i].split(' ')
lineCitys.append([])
for word in wordList:
if word not in citySet:
continue
lineCitys[-1].append(word)
if citys.get(word) is None:
citys[word] = 0
relationships[word] = {}
# 出现次数加1
citys[word] += 1
# explore relationships
for line in lineCitys: # 对于每一段
for city1 in line:
for city2 in line: # 每段中的任意两个城市
if city1 == city2:
continue
if relationships[city1].get(city2) is None: # 若两个城市尚未同时出现则新建项
relationships[city1][city2]= 1
else:
relationships[city1][city2] = relationships[city1][city2]+ 1 # 两个城市共同出现次数加 1
# output
with codecs.open("./data/city_node.csv", "w", "utf-8") as f:
f.write("Id Label Weight\r\n")
for city, times in citys.items():
f.write(city + " " + city + " " + str(times) + "\r\n")
with codecs.open("./data/city_edge.csv", "w", "utf-8") as f:
f.write("Source Target Weight\r\n")
for city, edges in relationships.items():
for v, w in edges.items():
if w > 3:
f.write(city + " " + v + " " + str(w) + "\r\n")
if __name__ == '__main__':
filepath = './data/text_2.xlsx'
# 描述性分析
# ms_analysis(filepath)
# 分析城市间的共现关系
city_gx_analysis(filepath)
TF-IDF.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/23 22:20
# @Author : ystraw
# @Site :
# @File : TF-IDF.py
# @Software: PyCharm Community Edition
# @function: 对文本内容进行关键词提取
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
from openpyxl import Workbook
# 写入Excel
def write_excel_xls(path, sheet_name, value, bHead):
# 获取需要写入数据的行数
index = len(value)
# 获取需要写入数据的行数
index = len(value)
wb = Workbook()
# 激活 worksheet
ws = wb.active
# 第一行输入
ws.append(bHead)
# .cell(row=x, column=2, value=z.project)
for i in range(2, index+2):
for j in range(1, len(value[i-2]) + 1):
# ws.append(value[i])
ws.cell(row=i, column=j, value=value[i-2][j-1])
# 保存
wb.save(path)
print(path + '表格写入数据成功!')
def TQ():
# 读入数据
filepath = './data/text_2.xlsx'
data = pd.read_excel(filepath)
document = list(data['文章内容分词'])
# print(document)
# print(len(document))
# min_df: 当构建词汇表时,严格忽略低于给出阈值的文档频率的词条,语料指定的停用词。如果是浮点值,该参数代表文档的比例,整型绝对计数值,如果词汇表不为None,此参数被忽略。
tfidf_model = TfidfVectorizer(min_df=0.023).fit(document)
# 得到语料库所有不重复的词
feature = tfidf_model.get_feature_names()
# print(feature)
# print(len(feature))
# ['一切', '一条', '便是', '全宇宙', '天狗', '日来', '星球']
# 得到每个特征对应的id值:即上面数组的下标
# print(tfidf_model.vocabulary_)
# {'一条': 1, '天狗': 4, '日来': 5, '一切': 0, '星球': 6, '全宇宙': 3, '便是': 2}
# 每一行中的指定特征的tf-idf值:
sparse_result = tfidf_model.transform(document)
# print(sparse_result)
# 每一个语料中包含的各个特征值的tf-idf值:
# 每一行代表一个预料,每一列代表这一行代表的语料中包含这个词的tf-idf值,不包含则为空
weight = sparse_result.toarray()
# 构建词与tf-idf的字典:
feature_TFIDF = {}
for i in range(len(weight)):
for j in range(len(feature)):
# print(feature[j], weight[i][j])
if feature[j] not in feature_TFIDF:
feature_TFIDF[feature[j]] = weight[i][j]
else:
feature_TFIDF[feature[j]] = max(feature_TFIDF[feature[j]], weight[i][j])
# print(feature_TFIDF)
# 按值排序:
print('TF-IDF 排名前十的:')
alldata = []
featureList = sorted(feature_TFIDF.items(), key=lambda kv: (kv[1], kv[0]), reverse=True)
for i in range(1, 600 if len(featureList) > 600 else len(featureList)):
print(featureList[i][0], featureList[i][1])
alldata.append([featureList[i][0], featureList[i][1]])
# 写入文件:
tableHead = ['关键词', 'TF-IDF']
import datetime
filetime = str(datetime.datetime.now()).replace('-', '').replace(' ', '_').replace(':', '_')[:17]
write_excel_xls('./data/关键词_' + filetime + '.xlsx', 'link', alldata, tableHead)
def drawWordCloud():
from wordcloud import WordCloud
from scipy.misc import imread
# 读入数据
filepath = './data/text_2.xlsx'
data = pd.read_excel(filepath)
document = list(data['文章内容分词'])
# 整理文本:
# words = '一切 一条 便是 全宇宙 天狗 日来 星球' # 样例
words = ''.join(document)
# print(words)
# 设置背景图片:
b_mask = imread('./image/ciyun.webp')
# 绘制词图:
wc = WordCloud(
background_color="white", #背景颜色
max_words=2000, #显示最大词数
font_path="./image/simkai.ttf", #使用字体
# min_font_size=5,
# max_font_size=80,
# width=400, #图幅宽度
mask=b_mask
)
wc.generate(words)
# 准备一个写入的背景图片
wc.to_file("./image/beijing_2.jpg")
if __name__ == '__main__':
'''
提取关键词
'''
# TQ()
'''
绘制词云图片
'''
drawWordCloud()
[/code]
LDA_主题模型.py
```code
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/26 14:10
# @Author : ystraw
# @Site :
# @File : LDA_主题模型.py
# @Software: PyCharm Community Edition
# @function:
import pandas as pd
import numpy as np
def LDA():
# 读入数据
filepath = './data/text_2.xlsx'
data = pd.read_excel(filepath)
document = list(data['文章内容分词'])
# 获取词频向量:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
corpus = document
cntVector = CountVectorizer()
cntTf = cntVector.fit_transform(corpus)
# 输出选取词特征
vocs = cntVector.get_feature_names()
print('主题词袋:', len(vocs))
# print(vocs)
# 输出即为所有文档中各个词的词频向量
# print(cntTf)
# LDA主题模型
lda = LatentDirichletAllocation(n_components=4, # 主题个数
max_iter=5, # EM算法的最大迭代次数
learning_method='online',
learning_offset=20., # 仅仅在算法使用online时有意义,取值要大于1。用来减小前面训练样本批次对最终模型的影响
random_state=0)
docres = lda.fit_transform(cntTf)
# 类别所属概率
LDA_corpus = np.array(docres)
print('类别所属概率:\n', LDA_corpus)
# 每篇文章中对每个特征词的所属概率矩阵:list长度等于分类数量
# print('主题词所属矩阵:\n', lda.components_)
# 找到最大值所在列,确定属于的类别:
arr = pd.DataFrame(LDA_corpus)
data['主题类别'] = np.argmax(LDA_corpus, axis=1) # 求最大值所在索引
data['主题出现概率']=arr.max(axis=1) # 求行最大值
print('所属类别:\n', data.head())
data.to_excel('./data/LDA_主题分布_类别.xlsx', index=False)
# return
# 打印每个单词的主题的权重值
tt_matrix = lda.components_
# 类别id
id = 0
# 存储数据
datalist = []
for tt_m in tt_matrix:
# 元组形式
tt_dict = [(name, tt) for name, tt in zip(vocs, tt_m)]
tt_dict = sorted(tt_dict, key=lambda x: x[1], reverse=True)
# 打印权重值大于0.6的主题词:
# tt_dict = [tt_threshold for tt_threshold in tt_dict if tt_threshold[1] > 0.6]
# 打印每个类别的前20个主题词:
tt_dict = tt_dict[:20]
print('主题%d:' % id, tt_dict)
# 存储:
datalist += [[tt_dict[i][0], tt_dict[i][1], id]for i in range(len(tt_dict))]
id += 1
# 存入excel:
# df = pd.DataFrame(datalist, columns=['特征词', '权重', '类别'])
# df.to_excel('./data/LDA_主题分布3.xlsx', index=False)
if __name__ == '__main__':
'''
利用LDA主题模型进行主题提取:
'''
LDA()
[/code]
Snownlp情感分析.py
```code
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/2/27 12:54
# @Author : ystraw
# @Site :
# @File : Snownlp情感分析.py
# @Software: PyCharm Community Edition
# @function: 进行情感分析
import pandas as pd
from snownlp import SnowNLP
def qgjs():
# 读入数据
data = pd.read_excel('./data/LDA_主题分布_类别.xlsx')
# print(data.shape)
# 进行情感打分
score = []
for i in range(0, data.shape[0]):
s = SnowNLP(data['标题'].at[i])
score.append(s.sentiments)
data['情绪得分'] = score
print(data.head())
data.to_excel('./data/情绪得分.xlsx', index=False)
if __name__ == '__main__':
qgjs()
[/code]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号