Apache Hadoop YARN
一、架构与组件
YARN核心思想是将资源管理和任务调度/监控等功能拆分成两个独立的守护进程。
基于这个思想,设计了一个全局的资源管理器ResourceManager(RM)和为每个应用程序提供一个单应用程序控制器Application Master(AM)。
一个应用程序是一个单独的作业或者一组作业。
资源管理器ResourceManager(RM)和NodeManager组成了数据计算框架,资源管理器RM的主要职责是为系统中的所有应用程序仲裁资源。节点管理器NM是单机器框架的代理,主要负责负责监控容器中资源(cpu、内存、磁盘、网络)的使用,报告相关情况给资源管理/调度器。
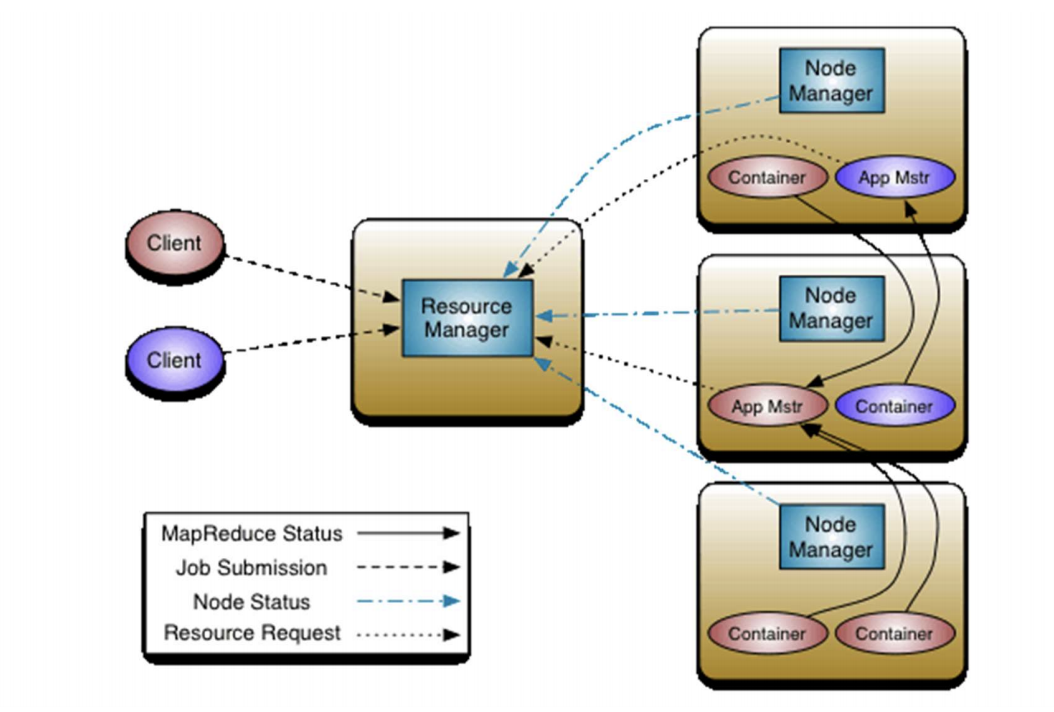
单应用程序控制器实际是一个框架类库,用来与资源管理器RM协调资源,和节点管理器NM一起执行和监控任务。
资源管理器RM有两个主要的组件:调度器和应用程序管理器。调度器主要负责为各种各样的正在运行的拥有相似约束(如:容量、队列约束等)的应用程序分配资源。
调度器仅仅是调度,并不监控、跟踪应用程序的状态。此外,它提供不可靠的重启失败任务的服务。失败任务是应用程序失败或硬件失败导致的。
调度器基于应程序的资源要求执行它的调度功能。当接收到资源容器(主要包含内存、cpu、磁盘、网络资源等)的抽象通知,它也会进行资源度。
调度器有一个插接式连接策略,主要负责给各种各样的队列、应用程序等分配集群资源。现有的调度器如CapacityScheduler 和FairScheduler都是此类插件程序的例子。
应用程序管理器主要负责接收作业的提交,为执行应用程序指定的应用程序控制器协调容器,提供了失败重启应用程序控制器的服务。应用程序控制器有从调度器请求恰当的资源容器、跟踪容器的状态、监控进度的责任。
在hadoop 2.x中,mapreduce跟之前稳定版本(hadoop 1.x)的API保持兼容性,这就意味着所有的MapReduce作业只需要再编译一次无需做任何改变就可以运行在YARN上。
YARN通过ReservationSystem来支持资源预留的概念,基于该组件,用户可以按照时间指定资源使用期限,并保留资源,以确保重要项目能够在预定时间执行。
ReservationSystem会随着时间的推移跟踪资源,执行预留资源的提交,并动态指示底层调度程序确保预留资源被用完。
为了支持大规模节点,YARN支持联邦集群概念,联邦集群就是将多个YARN集群绑定在一起,形成一个独立的更大的集群,从而服务更大规模的job
二、ResourceManager(RM)高可用
本指南提供YARN的ResourceManager的高可用综述,和如何配置和使用这个特性的细节。RM负责跟踪集群中的资源和调度应用(例如 MapReduce作业)。在Hadoop2.4之前,RM是YARN集群中的一个单点故障。这个高可用特性以活动/备用 RM对的形式增加了冗余来移除这个潜在的单点故障。
RM的高可用特性通过任何时间点的主/备架构来实现的,一个RM作为激活节点,而其他RMs进入备用模式随时等待接管出事的活动的RM。备用转活跃的触发可以通过管理员用命令行或者通过集成的故障切换控制器配置允许自动故障切换。
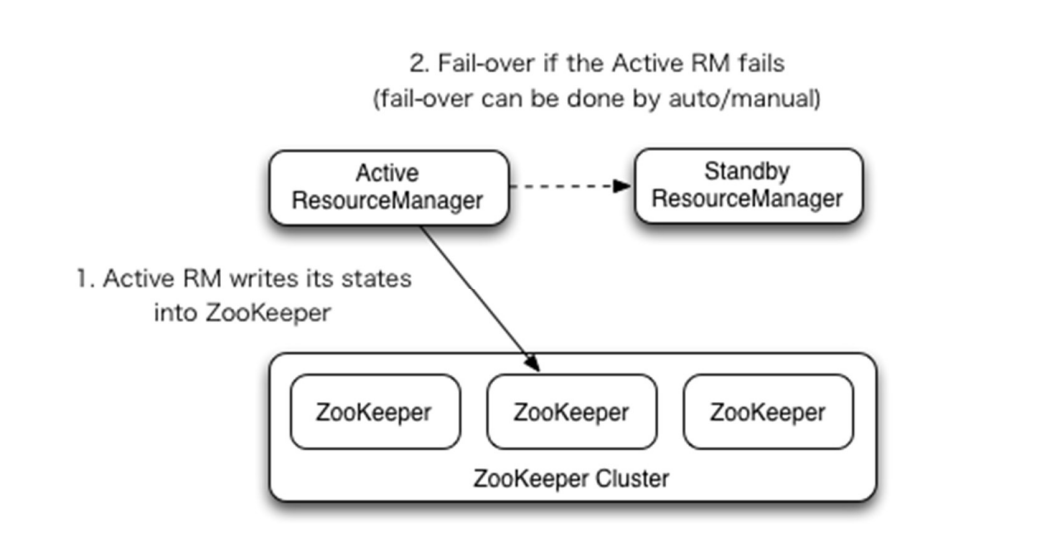
当自动故障切换没有被激活时,管理员必须手动地转换RMs中的一个为活跃。RM的故障切换时首先将活跃的RM切换为备用然后将一个备用的RM切换为活跃状态。这些都可以用“yarn rmadmin”命令行来实现。
RMa有个选项来嵌入基于Zookeepper的主备选举机制来决定哪个RM是活跃的。当活跃的RM失效或者反应迟钝,另一个RM会被自动选举为主用然后接管工作。需要注意的是,没必要为HDFS运行一个单独的ZKFC进程因为主备选举机制内嵌到RMs作为一个失效检查器和选举器来替代一个单独的ZKFC进程。
当有多个RM,客户端和节点可以通过配置(yarn-site.xml)来获得RM的列表。客户端、应用控制器和节点管理器采用循环的方式来试图连上RM直到他们连上活跃RM。如果活跃的RM失效了,它们重新开始以循环的方式去连接RM直到他们连上新的活跃RM。这个默认的重试逻辑是org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider实现的。你可以通过实现 org.apache.hadoop.yarn.client.RMFailoverProxyProvider 来覆盖这个逻辑并将yarn.client.failover-proxy-provider的值设为该类名。
如果RM重启是被激活可用的,依靠RM的重启特性一个RM被提升为活跃RM状态时加载前面那个活跃RM留下尽可能多的RM的内部状态和操作。应用可以周期的检查来避免丢失任何工作。状态仓库对主用/备用RM都是可见的。目前,有两个实现的持久化RM状态仓库- FileSystemRMStateStore和ZKRMStateStore。ZKRMStateStore允许在任何一个时间点只对一个RM可写,因此推荐在HA集群中使用这个仓库。当使用ZKRMStateStore作为状态仓库,建议不要在Zookepper集群中设置zookeeper.DigestAuthenticationProvider.superDigest属性确保zookepper管理员没有进入YARN 应用和用户的权限信息。
三、The YARN Timeline Server
以通用方式存储和检索应用程序的当前和历史信息是通过时间轴服务器在 YARN 中实现的。它有两项责任:
1、存储应用程序特定的信息
完全特定于应用程序或框架的信息的收集和检索。例如,Hadoop MapReduce 框架可以包含一些信息,比如 map 任务的数量、reduce 任务、计数器等等。应用程序开发人员可以通过应用程序主容器和/或应用程序容器中的 TimelineClient 将特定信息发布到时间轴服务器。然后,可以通过 REST api 查询此信息,以供特定于应用程序/框架的ui呈现。
2、保存关于已完成应用程序的通用信息
在此之前,应用程序历史服务器只支持 MapReduce 作业。随着时间轴服务器的引入,应用程序历史服务器成为时间轴服务器的一种用途。
一般信息包括应用程序级别的数据,如:
- 队列名称
- 用户信息和类似的设置在 ApplicationSubmissionContext 中
- 为应用程序运行的应用程序尝试列表
- 关于每个应用程序尝试的信息
- 在每次应用程序尝试下运行的容器列表
- 关于每个容器的信息
YARN 资源管理器将通用数据发布到时间轴存储区,并使用其 web-UI 显示有关已完成应用程序的信息。
Current status
- 时间轴服务器的核心功能已经完成。
- 它可以在安全集群和非安全集群中工作。
- 通用历史服务是在时间轴存储上构建的。
- 历史记录可以存储在内存或 leveldb 数据库存储中;后者确保在时间轴服务器重新启动时保留历史记录。
- 不支持在纱线中安装特定于框架的 ui。
- 特定于应用程序的信息只能通过使用 JSON 类型内容的 RESTful api 获得。
- “时间轴服务器v1” REST API 已经被声明为 REST API 之一,其兼容性将在未来的版本中维护。
- 时间轴服务器的单服务器实现限制了服务的可伸缩性;它还可以防止服务成为 YARN 基础设施的高可用性组件。
Future Plans
- 未来的版本将引入一个可扩展且可靠的下一代时间轴服务,即“时间轴服务v2”。
- 此服务的扩展特性可能不适用于使用时间轴服务器 v1 REST API 的应用程序。这包括扩展的数据结构以及客户端在时间轴服务器实例之间进行故障转移的能力。
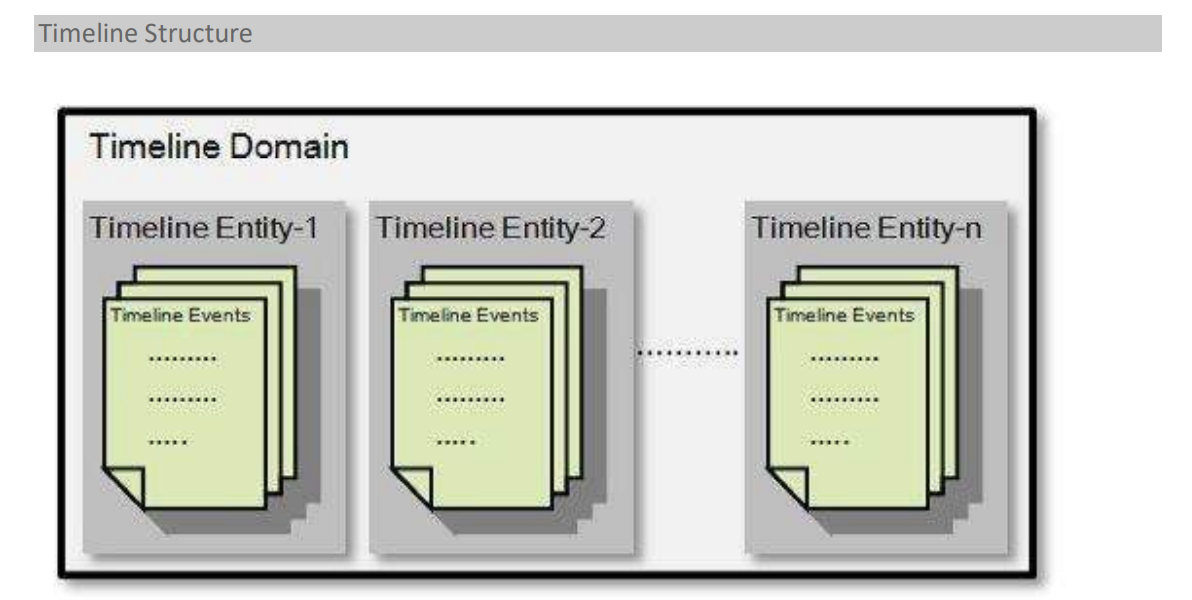
Timeline Domain
时间轴域为时间轴服务器提供了一个名称空间,允许用户托管多个实体,将它们与其他用户和应用程序隔离开来。时间轴服务器安全性在此级别定义。
“域”主要存储所有者信息、读写 ACL 信息、创建和修改时间戳信息。每个域由一个 ID 标识,该 ID 必须在纱线集群中的所有用户中是唯一的。
Timeline Entity
时间线实体包含概念实体及其相关事件的元信息。
实体可以是应用程序、应用程序尝试、容器或任何用户定义的对象。
它包含主过滤器,用于索引时间轴存储中的实体。因此,用户/应用程序应该谨慎地选择他们想要作为主要过滤器存储的信息。
其余的数据可以存储为非索引信息。每个实体都由 EntityId 和 EntityType 唯一标识。
Timeline Events
时间线事件描述与应用程序的特定时间线实体相关的事件。
用户可以自由定义事件的含义 -- 例如启动应用程序、分配容器、操作失败或其他与用户和集群操作员相关的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号